







RepSum: Unsupervised Dialogue Summarization based on Replacement Strategy
基于替换策略的无监督对话摘要
SummaRuNNer: A Recurrent Neural Network Based Sequence Model for Extractive Summarization of Documen抽取式摘要
Abstract
主要研究的是对话摘要的领域。一般传统的方法采用的是监督摘要生成方法,但是需要大量的训练数据。在文档摘要任务中,有一些工作是利用语义信息去无监督的生成摘要,但是不适用于对话摘要,因为对话摘要原文本身含有的单词数量较少,与文档摘要任务差距很大。
本文作者提出一种新的无监督策略来解决这个挑战。
本文的思想是一个很好的摘要可以完全代替一个对话,大致上可以理解成一个辅助(自监督的)任务。例如对话生成。
在对话话语的生成和分类任务的指导下,作者的策略被提出抽取生成抽象摘要。
Introduction
简单的概括对话摘要任务的定义:
对话摘要从对话上下文中提取关键信息,并将其概括为简介的摘要。
抬一手对话摘要,这是一个新主题,为许多场景都提供了强大的潜力。
对话摘要的传统方法:
(1)基于模板提取对话摘要,从对话上下文中提取关键信息并将其填入到学习的模板。(模板限制了模型的应用范围,不能适应更广泛的对话数据,应为输入结构是预定义的,学习的模板是特定领域的)
(2)利用对话行为等另外一些额外信息辅助对话摘要任务的生成
(3)恰当的捕捉话语之间的关系,来提高对话摘要的性能(但是需要的数据需要标注,成本过高)
(4)目前为了减轻注释数据的依赖性将文本摘要任务中的无监督方法应用于对话场景中去。
然而这些方法只要依靠语义信息,没有任何监督信号,结果效果参差不齐。
一般采用的是AE自动编码其,将对话上下文编码成隐向量,再使用此隐向量生成对话上下文的摘要。但是它们受限于输入文本和目标摘要之间的小间隙(例如,句子压缩),而无法重建长输入文本(例如,对话)
本文中提出新的无监督策略,可以应用提取和抽象摘要。
作者灵感来自于一篇论文,它主要解释摘要用于不同的任务中的有效性,所以作者认为对话摘要也是对话上下文的一个压缩表示,这个压缩表示也可以作为对话生成任务的辅助任务来提供有效信息。

简单的介绍一下上图,也就是论文作者提出的方法,作者认为摘要为原始对话的压缩表示,即在对话话语生成任务中可以直接使用对话摘要来生成下一轮对话话语。此时使用对话话语生成的下一轮话语和对话摘要生成的下一轮话语之间做KL散度使得两个生成之间的相似度尽量减小,以往的对话上下文生成下一轮话语时采用下一轮的话语监督生成。
论文的贡献如下:
(1)提出一个无监督的对话摘要的策略。
(2)将这个策略应用于对话生成任务,来提取和抽象摘要
(3)当前的无监督策略优于其他无监督策略
RepSum Model
Mechanism
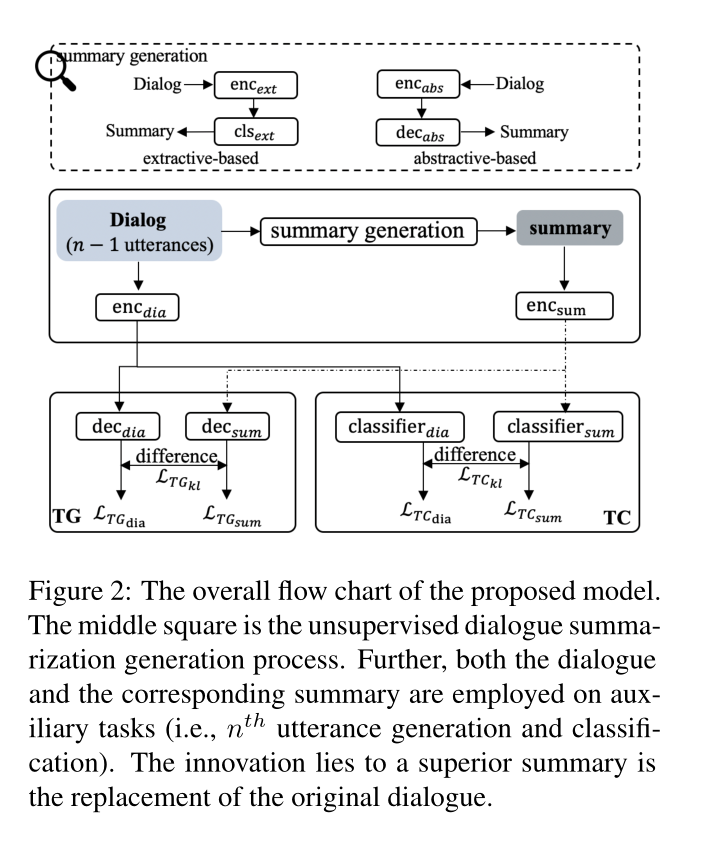
生成的摘要采用两种方式:(1)抽取方式(2)抽象方式
将生成的摘要和原始对话上下文分别去做两个任务:预测第n轮对话话语、分类第n轮话语
因为作者的假设对话摘要可以代替对话上下文,即对话上下文做的任务和对话摘要做的任务之间的相差不会很多。
采用这两个辅助任务,去训练模型生成更高级的摘要
鉴于摘要是对原始对话的替换,输入对话和生成的摘要有望分别在这些任务上取得相似的结果。
Auxiliary Tasks
为了使对话上下文和对话摘要生成的结果相似,我们采用KL散度使得两个结果更加接近。
Task1:Generation(TG)
此任务主要是生成第n轮对话。
采用的传统的encoder-decoder结构。
将n轮之前的对话上下文全部连接起来使用双向LSTM对其进行编码,每个单词的表示是前向和后向的串联。
解码时采用非双向LSTM加attention机制生成第n轮的对话话语,预测是预测出词汇表中每一个词的概率,去概率最高的那个词。
这里产生三个loss
生成对话话语的loss(这里的标签就是对话上下文中的第0轮对话),这里的L指的是生成的话语的token
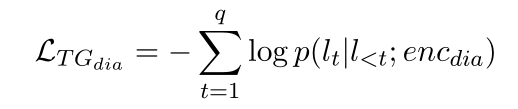
对话上下文生成的对话话语和对话摘要生成的对话话语之间的loss
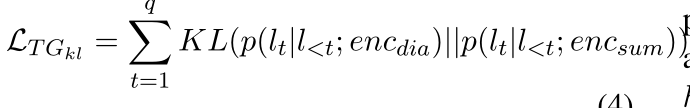
TG的总loss
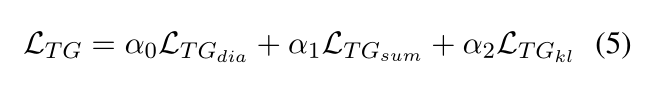
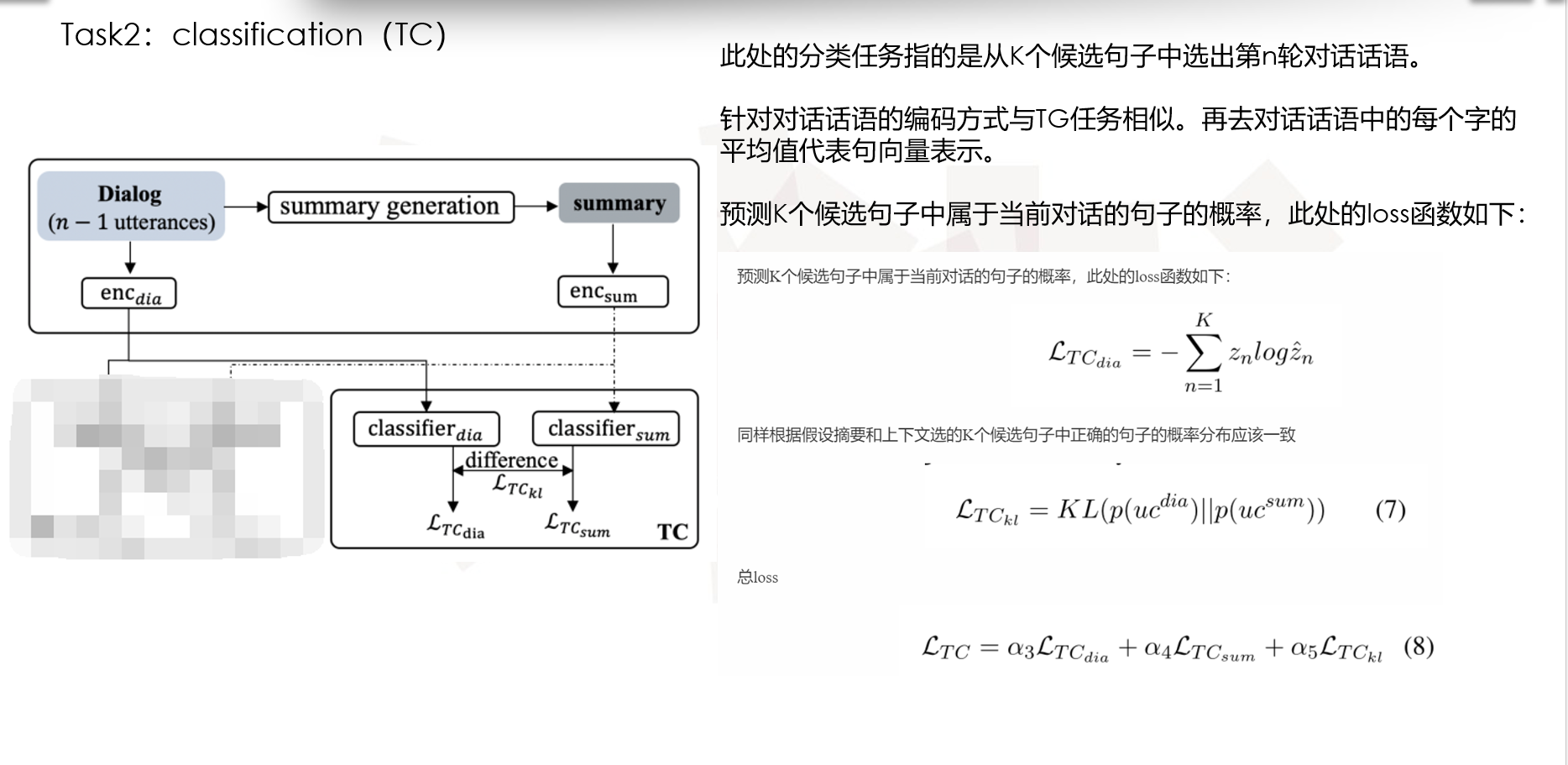
Task2:classification(TC):
此处的分类任务指的是从K个候选句子中选出第n轮对话话语。
针对对话话语的编码方式与TG任务相似。再去对话话语中的每个字的平均值代表句向量表示。
预测K个候选句子中属于当前对话的句子的概率,此处的loss函数如下:
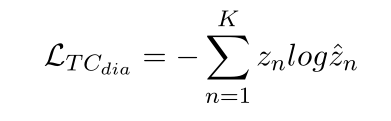
同样根据假设摘要和上下文选的K个候选句子中正确的句子的概率分布应该一致

总loss
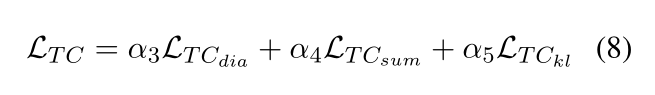
Unsupervised Summarization
本文雇佣了两种摘要生成方式:抽取生成和抽象生成
Extractive Summarization
当前抽取式摘要指的是查看当前的对话话语中的上下文,哪一句属于接下来的摘要。
注意这里的抽取式摘要主要靠辅助任务优化
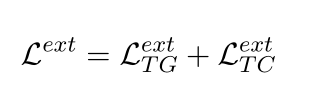
Abstractive Summarization
即采用传统的seq2seq去生成摘要,同时为了无监督,所以又使用了一个生成摘要的预训练模型,缩小s2s生成的摘要和预训练模型生成的摘要之间的KL散度。
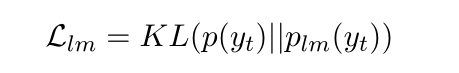
总loss
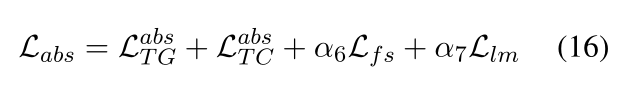
Lfs = 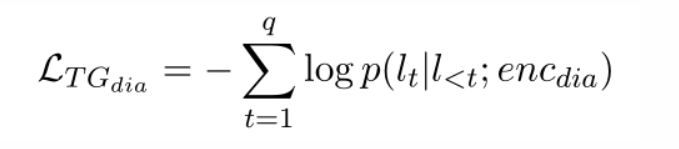
Experimental Setup
Dataset
使用两个数据集
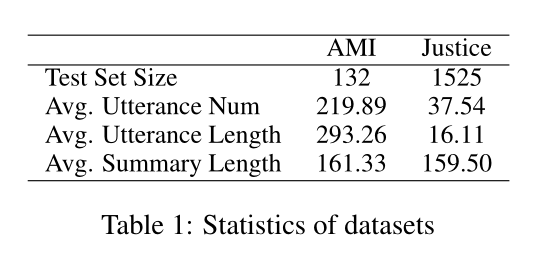
Justice:中国的法庭辩论记录
AMI:英文会议语料
Baselines
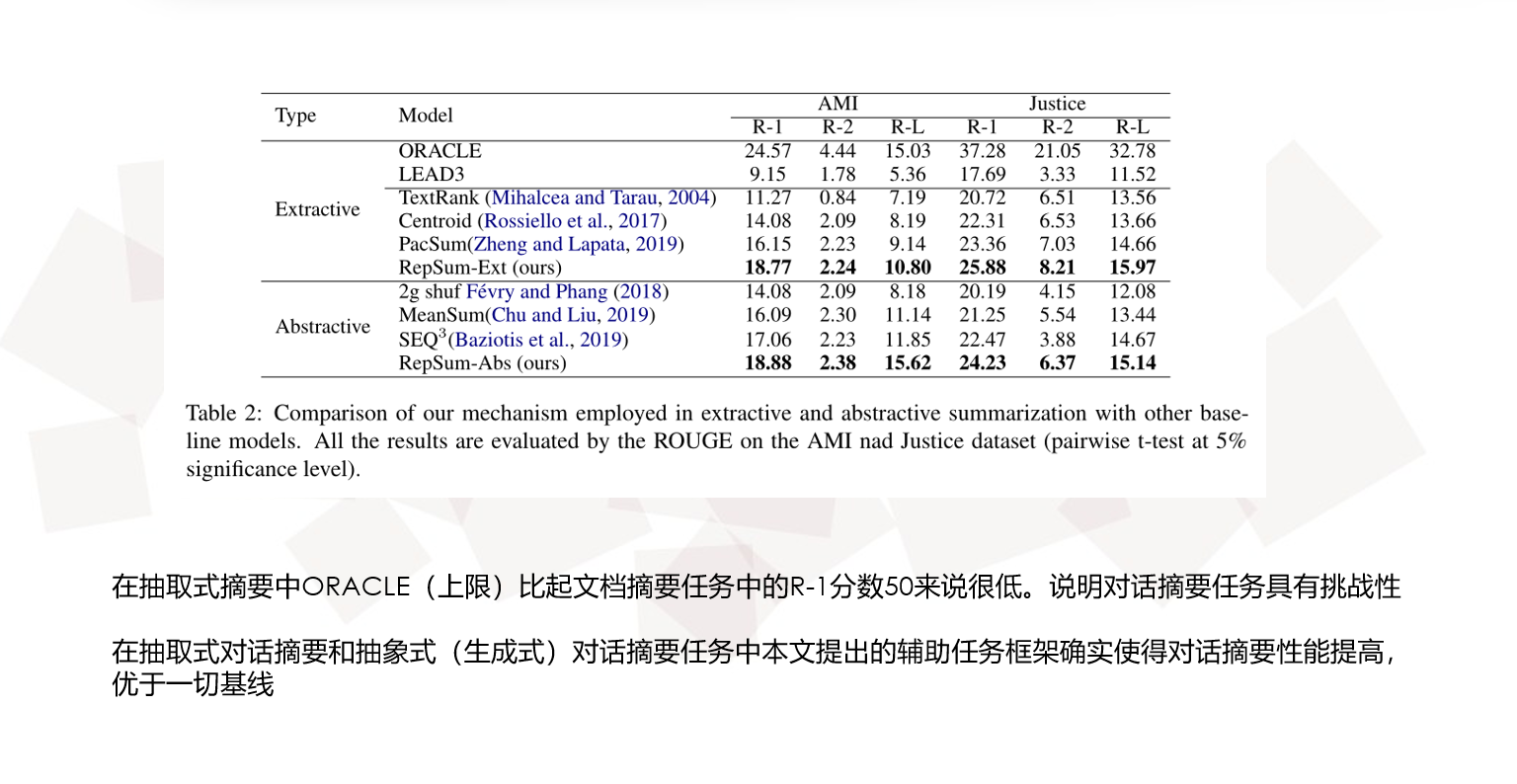
ORACLE指的是使用贪心算法得到最接近真实摘要的性能,即性能上限
LEAD3指的是使用对话话语中的前三句作为对话摘要,即性能下限
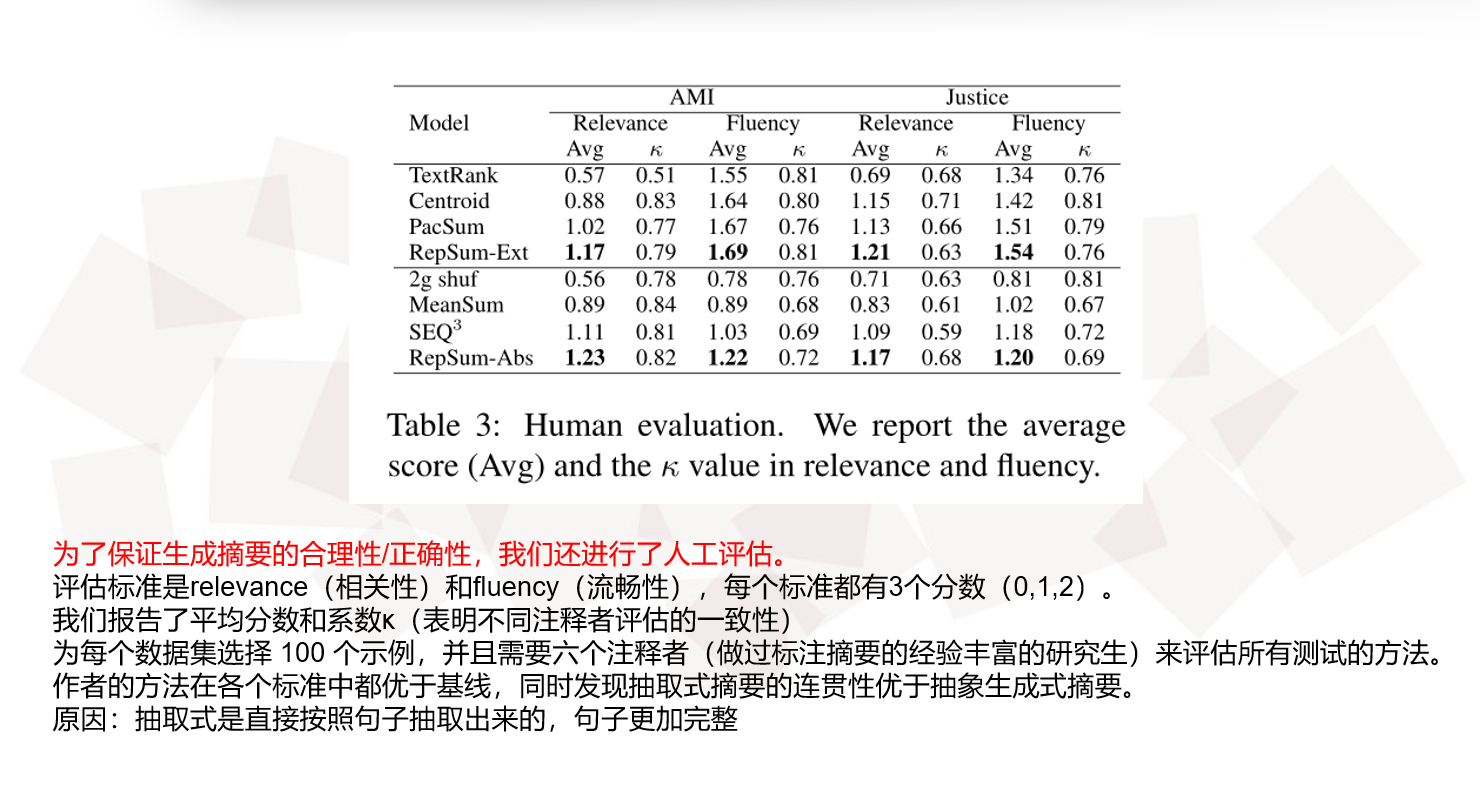
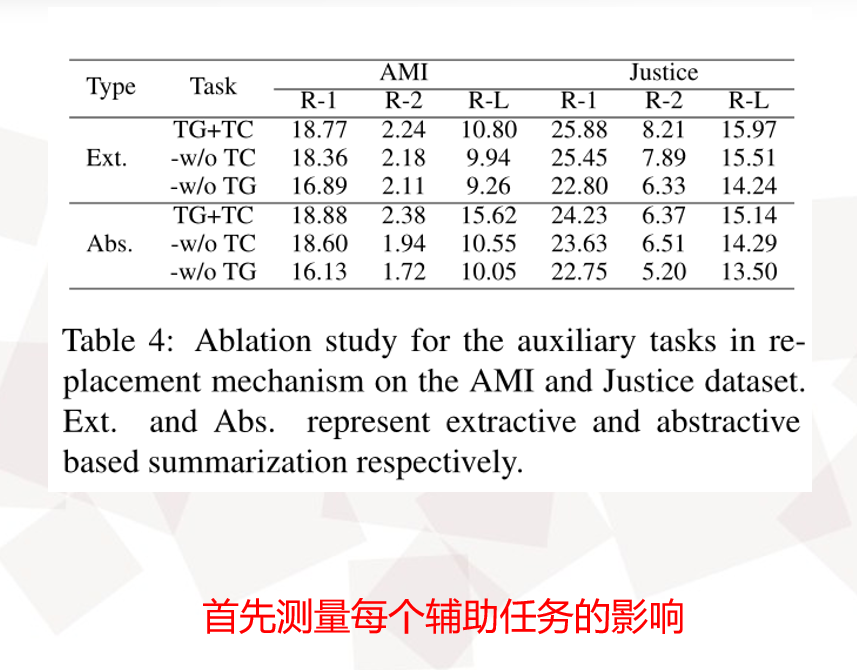
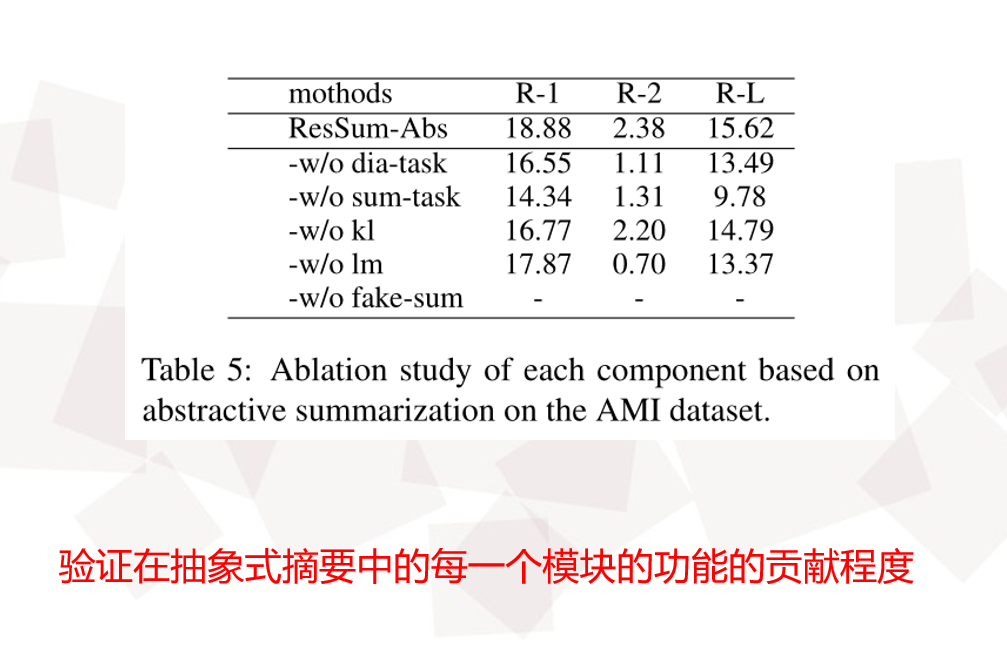
Experimental Results
Quantitative Analysis





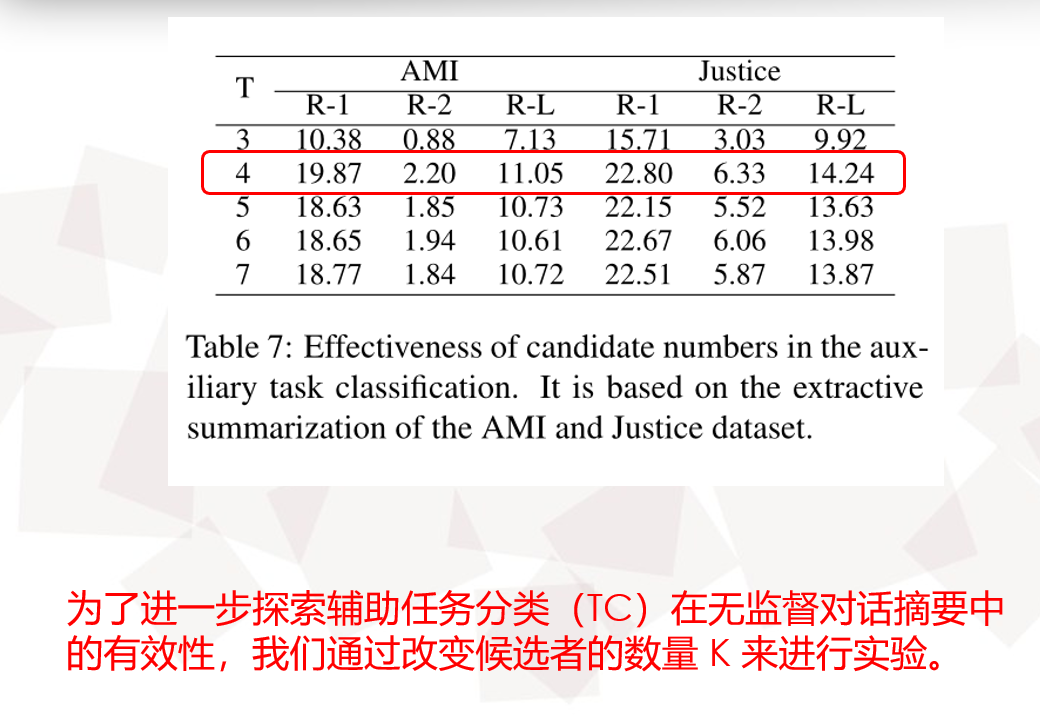
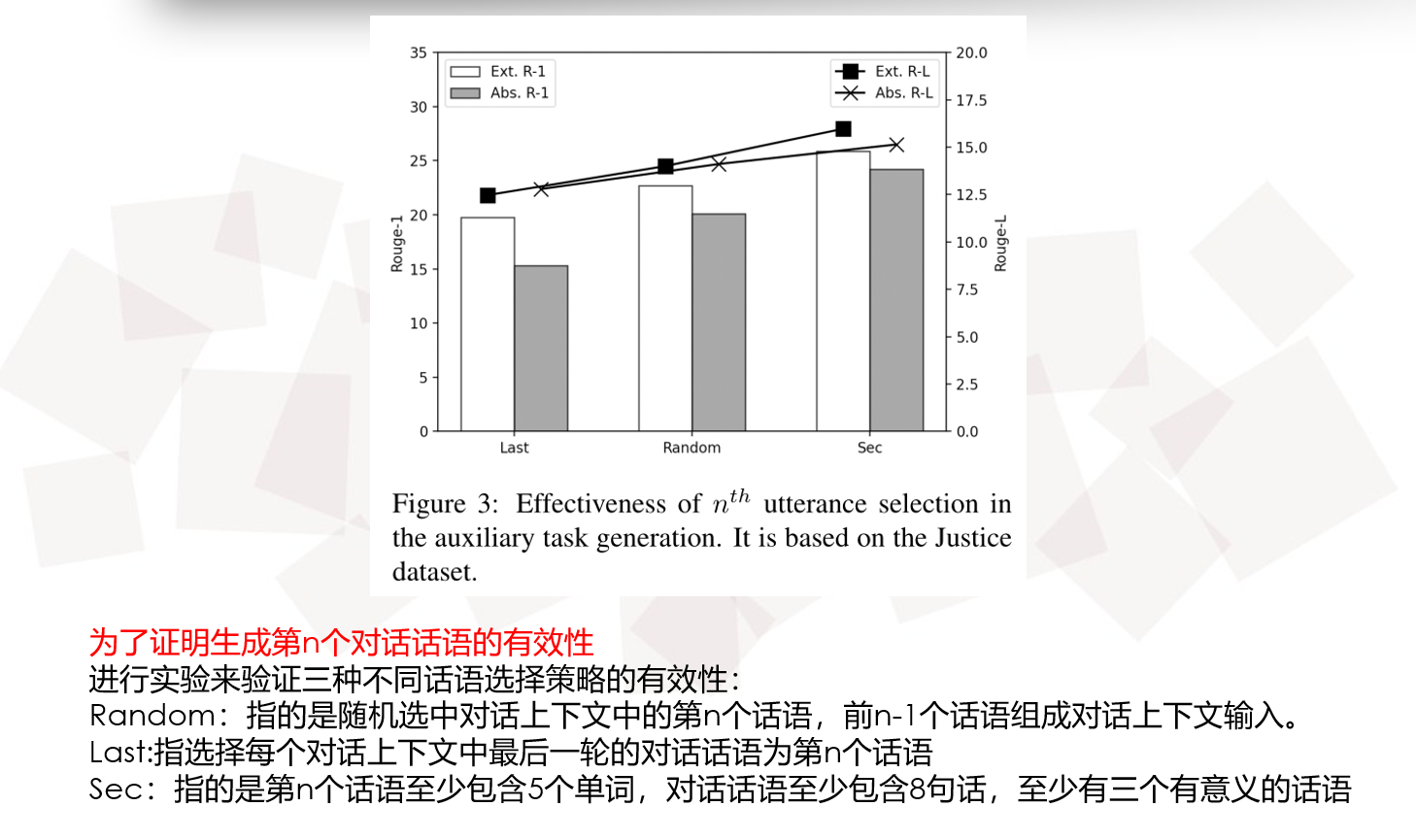
















 1151
1151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









