







文章目录
1.Cache buffer chain介绍
经常看到会话等待事件“latch:cache buffers chain”。 如果想知道意味着什么以及如何减少花在这上面的时间,这篇文章记录缓冲区高速缓存、Oracle multi-version control如何工作、buffer如何分配和释放、什么是哈希链以及buffer如何与其链接、cache buffer chain latch的作用是什么以及会话为何等待它,如何找到导致争用的对象以及如何减少在该事件上花费的时间。
在查找数据库会话缓慢的原因时,检查等待界面并看到以下输出:
SQL> select state, event from v$session where sid = 123;
STATE EVENT
------- ---------------------------
WAITING latch: cache buffers chains
此事件更为常见,尤其是在执行几个数据块扫描的应用程序中。 要解决此问题,应该了解cache buffer chain latch是什么以及会话必须等待它的原因。 要了解这一点,必须了解 Oracle cache buffer的工作原理。 这里将进行探讨,并以减少cache buffer chain latch等待的解决方案。
2.Buffer cache的工作原理
缓冲区高速缓存 (buffer cache) 驻留在 Oracle 实例的 SGA 内,用来保存来自数据库的块。 当用户发出如下语句时:
update EMP set NAME = 'ROB' where EMPNO = 1
分配给会话的 Oracle 服务器进程执行以下操作:
- 定位包含 EMPNO = 1 的记录的块
- 将块从数据库文件加载到buffer cache中的空buffer
3)如果没有立即找到空buffer,则定位一个空buffer或强制DBWn进程写入一些脏buffer以腾出空间 - 将buffer中的NAME列更新为ROB
在步骤 1 中,假设存在索引,因此服务器进程可以立即找到单个块。 如果索引不存在,Oracle需要将EMP表的所有块加载到buffer cache中,并一一检查匹配的记录。
上面的描述有两个非常重要的概念:
1)块(block),数据库中最小的存储单位
2)缓冲区(buffer),buffer cache中用于保存block的占位符(placeholder)。
buffer只是占位符,可能被占用也可能未被占用。 他们一次只能持有一个block。 因此,对于block大小设置为 8KB 的数据库,buffer的size也为 8KB。 如果使用多个block大小,例如 4KB 或 16KB,必须定义与其他块大小相对应的多个buffer cache。 在这种情况下,buffer大小将与这些block对应的块大小相匹配。
当buffer到达buffer cache后(从硬盘读入缓冲区),服务器进程必须扫描他们以获取所需的值。 在上面所示的示例中,服务器进程必须找到 EMPNO=1 的记录。 为此,它必须知道buffers中block的位置。 该进程按顺序扫描缓冲区。 因此,理想情况下buffer应该按顺序放置,例如 10,然后是 20,然后是 30,依此类推。 然而这会产生一个问题。 在仔细放置buffer之后,当buffer #25 出现时会发生什么? 由于它介于 20 和 30 之间,因此必须将其插入中间,即 Oracle 必须将 20 之后的所有buffer向右移动一步,以便为新buffer #25 腾出空间。 移动内存中的内存区域并不是一个好主意。 它会消耗昂贵的 CPU 时间,需要buffer上的所有操作(甚至读取)在一段时间内停止,并且容易出错。
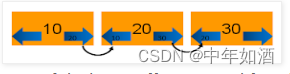
因此,更好的方法是将它们放在类似链接列表(linked list)的东西中,而不是四处移动buffer。 图 1 显示了这是如何完成的。 每个buffer都有两个指针:哪一个在后面,哪一个在前面。 在该图中,buffer20显示10在前面,30在后面。 无论buffer的实际位置如何,情况都会如此。 当 25 进来时,我们要做的就是更新 20 的“后面指针”和 30 的“前面指针”指向 25。同样,25 的“前面指针”和“后面指针”更新指向 分别为 30 和 20。 这种简单的更新速度要快得多,不需要在除正在更新的buffer之外的所有buffer上停止活动,并且不易出错。
还有另一个问题。 这只是其中之一。 buffer也可用于其他目的。 例如,LRU 算法需要按 LRU 顺序排列的buffer列表,DBWn 进程需要用于写入磁盘的buffer列表等。因此,将buffer物理移动到特定列表不仅不切实际,而且也是不可能的。 Oracle 采用一种更简单的技术来克服这个障碍。 Oracle 没有将实际buffer放置在链表中,而是创建了一个更简单、更轻量的结构,称为缓冲区头(buffer header),作为指向实际buffer的指针。 该buffer cache会四处移动,但实际的buffer位置保持不变。 这样,buffer header就可以同时列在多种类型的列表中。 这些buffer header位于share pool中,而不是buffer cache中。 这就是为什么会在share pool中找到对buffer的引用。
3 Buffer chains
这些buffer被放置在链中。将其与停车场的车位行进行比较。汽车驶入一排中的空位。如果找不到空位,它们就去下一排,依此类推。类似地,缓冲区在buffer cache中被定位为行。然而,与物理上相邻的停车位不同,这些buffer在逻辑上以链表的形式排列,如上节所述。每个buffer链表被称为buffer链,如图2所示。
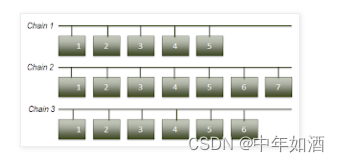
注意三条链中的每一条都有不同数量的buffer。这是相当正常的。buffer只有在某个服务器进程将它们从块中提取出来时才被占用。 否则buffer是空闲的并且不与任何东西链接在一起。 当buffer被释放时,可能是因为某些进程(例如 DBWn)将其内容写入磁盘,它们就会从列表中删除,该过程称为从链中取消链接(unlink)。 因此,在正常的数据库中,buffer将不断地链接到链或从链上断开链接——根据任一活动的频率使链变长或变小。 buffer链的数量由隐藏的数据库参数_db_block_hash_buckets决定,该参数是根据buffer cache的大小自动计算的。
当服务器进程想要访问buffer cache中的特定buffer时,它从链的头部开始,然后继续按顺序检查每个buffer,直到找到它需要的内容。 这称为遍历链。 这里有一个棘手的问题:当buffer进入缓存时,谁决定它应该链接到三个链中的哪一个以及如何链接? 随之而来的必然结果是服务器进程在尝试在buffer cache中查找特定buffer时提出的挑战。 进程如何知道要走哪条链? 如果它总是从链 1 开始,那么将花费大量时间来定位该块。 典型的buffer cache非常巨大,因此链的数量也可能达到数十数千。 因此,搜索所有链是不切实际的。 另一方面,如果 Oracle 维护一个内存表来显示哪些块位于哪些buffer也是不切实际的,因为维护该内存表将非常耗时并且会使过序列化。 那么多个进程就无法并行读取链。
Oracle 以巧妙的方式解决了这个问题。 考虑前面的停车场例子。 如果忘记把车停在哪里怎么办? 假设你走出商场后,发现所有的汽车都被埋在厚厚的雪堆下,无法识别任何汽车。 因此,必须从第一排的第一辆车开始,掸去车牌上的积雪,检查一辆汽车,然后转到下一辆车,依此类推。 工作量会很大, 因此,为了帮助健忘的司机,商场用字母代码标记一排车位,并要求司机将车停在与其姓氏的第一个字母匹配的行中。 如果 需要将车停在 S 排,并且仅停在 S 排,即使 T 排或 R 排完全空着。 在这种情况下,当寻找车辆并忘记它在哪里时,一定会在 S 排找到它。这将是他的搜索范围 - 比搜索整个停车场要好得多。
同样地,Oracle确定了一个buffer应该链接到哪个具体链。每个块都由data block address(DBA)唯一标识。当块进入buffer时,Oracle应用哈希函数来确定buffer链的编号,并将该块放入该链中的一个buffer中。同样地,在查找特定buffer时,Oracle对DBA应用相同的哈希函数,立即知道buffer位于哪个链,并且只遍历该特定buffer。这使得访问一个buffer相比搜索整个buffer cache更容易。
要找到数据块地址,首先需要获取相对的file#和block#。假如想找出名为 CBCTEST 的表的所有块。
SQL> select
2 col1,
3 dbms_rowid.rowid_relative_fno(rowid) rfile#,
4 dbms_rowid.rowid_block_number(rowid) block#
5 from cbctest;
COL1 RFILE# BLOCK#
---------- ---------- ----------
1 6 220
2 6 220
3 6 220
4 6 221
5 6 221
6 6 221
6 rows selected.
从输出中我们看到这个表中有6行,它们都位于相对文件#6的文件中的两个块中。块是220和221。使用它,我们可以获得数据块地址。 要获取块 220 的 DBA:
SQL> select dbms_utility.make_data_block_address(6,220) from dual;
DBMS_UTILITY.MAKE_DATA_BLOCK_ADDRESS(6,220)
-------------------------------------------
25166044
输出显示该块的 DBA 是 25166044。如果有三个链,我们可以应用一个模函数,该函数将输入除以 3 后返回:
SQL> select mod(25166044,3) from dual;
MOD(25166044,3)
---------------
1
因此,我们将其放入链 #1 中(假设有三个链,并且第一个链以 0 开头)。 该表的另一个块,块#221将最终出现在链#2中:
SQL> select dbms_utility.make_data_block_address(6,221) from dual;
DBMS_UTILITY.MAKE_DATA_BLOCK_ADDRESS(6,221)
-------------------------------------------
25166045
SQL> select mod(25166045,3) from dual;
MOD(25166045,3)
---------------
2
Oracle 中如果我们获得 DBA,我们可以应用 mod() 函数,输出显示可以找到它的链。 Oracle 并不使用此处所示的确切 mod() 函数; 而是更复杂的哈希函数。 该功能的具体机制并不重要;重要的是。 这个概念是相似的。 Oracle 可以通过对buffer的 DBA 应用哈希函数来精准识别buffer需要进入的链。
4.Multi-versioning of Buffers
考虑本文开头所示的update 语句。 当Oracle更中已经存在的buffer时,它不会直接更新它。 相反,它创建buffer的副本并更新该副本。 当查询从某个 SCN 号的块中select数据时,Oracle 创建截至该scn对应时间点的buffer的副本,并从该副本返回数据。 正如所看到的,buffer cache中可能存在多个同一个块的副本。 在搜索buffer时,服务器进程还需要搜索buffer的版本。 这使得buffer链更长。
要找出块的具体buffer,您可以检查视图 V$BH(缓冲区头)。 OBJD 列是 object_id。 (实际上它是 DATA_OBJECT_ID。在大多情况下两者是相同的;但可能并非在所有情况下都相同)。 以下是该视图的一些有用的字段:
• FILE# - the file_id
• BLOCK# - the block number
• CLASS# - the type of the block, e.g. data block, segment header, etc. Shown as a code
• STATUS - the status of the buffer, Exclusive Current, Current, etc.
为了更容易理解,我们将在 class# 字段上使用decode() 来显示块的类型。 这样,我们将在sess1中作如下查询:
Sess1>select file#, block#,
decode(class#,
1,'data block',
2,'sort block',
3,'save undo block',
4,'segment header',
5,'save undo header',
6,'free list',
7,'extent map',
8,'1st level bmb',
9,'2nd level bmb',
10,'3rd level bmb',
11,'bitmap block',
12,'bitmap index block',
13,'file header block',
14,'unused',
15,'system undo header',
16,'system undo block',
17,'undo header',
18,'undo block') class_type,status
from v$bh
where objd = 99360
order by 1,2,3
/
FILE# BLOCK# CLASS_TYPE STATUS
---------- ---------- ----------------- ----------
6 219 segment header cr
6 221 segment header xcur
6 222 data block xcur
6 220 data block xcur
4 rows selected.
有4个buffer。 在此示例中,我们没有重新启动buffer cache。 所以段头有两个buffer。 每个数据块有一个buffer-220 和 221。状态为“xcur”,代表 Exclusive Current。 这意味着buffer是为了被修改而获取(或被块填充)的。 如果目的只是select,那么状态将显示 CR(一致性读取)。 在这种情况下,由于插入的行修改了buffer,因此块是在 xcur 模式下获取的。 从不同的会话更新一行。 为了更容易识别,我使用 Sess2> :
Sess2> update cbctest set col2 = 'Y' where col1 = 1;
1 row updated.
执行sess1中,检查buffer状态:
FILE# BLOCK# CLASS_TYPE STATUS
---------- ---------- ----------------- ----------
6 219 segment header cr
6 220 segment header xcur
6 220 data block xcur
6 220 data block cr
6 221 data block xcur
现在有 5 个buffer,比之前的 4 个增加了 1 个。 请注意,块 ID 220 有两个buffer。一个 CR 和一个 xcur。 为什么是两个?
这是因为当发出更新语句时,它会修改该块。 Oracle 不会修改现有buffer,而是创建buffer的“副本”并对其进行修改。 该副本现在处于 XCUR 状态,因为获取它的目的是为了进行修改。 该块的前一个buffer(以前是 xcur)被转换为“CR”。 某一特定块不能有多个 XCUR buffer,这就是它是排他性的原因。 如果有人想找出最近更新的buffer,只需查找具有 XCUR 状态的副本即可。 所有其他都标记为 CR。
假设从第三个会话更新同一块中的不同行。
Sess3> update cbctest set col2 = 'Y' where col1 = 2;
1 row updated.
执行上面sess1会话中的sql,检查buffer状态:
FILE# BLOCK# CLASS_TYPE STATUS
------ ------ ------------------ ----------
6 219 segment header xcur
6 219 segment header cr
6 221 data block xcur
6 220 data block xcur
6 220 data block cr
6 220 data block cr
6 220 data block cr
6 220 data block cr
6 220 data block cr
9 rows selected.
现在有 9 个缓冲区。 块 220 现在有 6 个buffer- 之前有 4 个。 这只是一条 select 语句,根据定义,它不会更改数据。 Oracle 为什么要为此创建一个buffer?
同样,答案是 CR 处理。 CR 处理创建buffer的副本,并将它们回滚或前滚以创建截至正确 SCN 号的 CR 副本。 这创建了 2 个额外的 CR 副本。 从一个块开始,现在有 6 个buffer,并且一些buffer是由于 select 语句而创建的。 这就是 Oracle 在buffer cache中创建同一块的多个版本的方式。
5.Latches
既然知道可以创建多少个buffer以及它们如何位于buffer cache中的链上,考虑检查另一个问题。 当两个会话想要访问buffer cache时会发生什么? 可能有几种可能性:
- Both processes could be after the same buffer
- The processes are after different buffers but the buffers are on the same chain
- The buffers are on different chains
3# 不是问题; 但2#将会是。 我们不允许两个进程同时遍历这条链。 因此,需要某种机制来防止其他进程在另一个进程正在执行某个操作时执行该操作。 这是通过一种称为latch的机制来实现的。 latch是进程竞争获取的内存结构。 谁拿到了,就被称为“hold latch”; 所有其他人必须等待,直到latch可用。 在许多方面,它听起来像一把锁。 目的是相同的——提供对资源的独占访问——但锁有队列。
当锁被释放时,等候它的几个进程将按照他们启动等待时的顺序获得它。 另一方面,lock不是顺序的。 每当latch可用时,每个感兴趣的进程都会加入战斗以捕获它。 再说一次,只有一个人能得到它; 其他人必须等待。 进程首先执行循环 2000 次(由隐含参数_spin_count决定),以主动寻找latch的可用性。 这称为自旋(spin) 之后该进程会休眠 1 毫秒,然后重试。 如果不成功,它会尝试 1 ms、2 ms、2 ms、4 ms、4 ms 等,直到获得latch。 该过程在其间被称为睡眠(sleep)状态。
因此,latch是确保没有两个进程访问同一链的机制。 该latch称为"latch:cache buffers chain"(CBC)。 有一个父 CBC latch和多个子 CBC latch。 然而,latch会消耗内存和CPU; 因此 Oracle 不会创建与链一样多的子latch。 相反,单个latch可以用于两个或多个链,如图 3 所示。子锁存器的数量由隐藏参数 _db_block_hash_latches 确定。
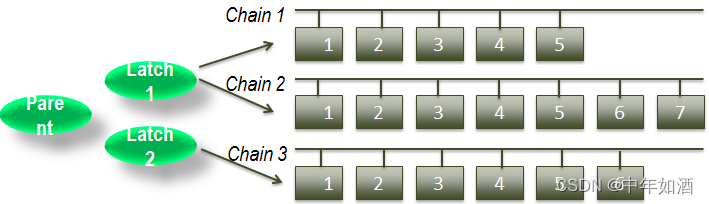
latch由latch# 和child# 标识(如果是子latch)。 所使用的latch的特定实例由其在内存中的地址(latch address)来标识。 要找出保护特定buffer的latch,获取前面所示的file#和block#,发出以下 SQL:
select hladdr
from x$bh
where dbarfil = 6
and dbablk = 220;
回到 CBC latch,让我们看看如何找出链和latch之间的相关性。 首先,找到 CBC latch的 Latch#。 Latch# 可能因版本或跨平台而异。
select latch# from v$latch
where name = 'cache buffers chains';
LATCH#
------
203
这是父latch。 要找出子latch(保护链的latch),应该查看另一个视图 - V$LATCH_CHILDREN。 要查明有多少个子latch:
SQL> select count(1) cnt from v$latch_children where latch# = 203;
CNT
-------
16384
如果检查前面解释的两个隐藏参数的值,将看到:
_db_block_hash_buckets 524288
_db_block_hash_latches 16384
参数_db_block_hash_buckets决定有多少个cache buffer chain,参数,db_block_hash_latches决定CBC latch的数量。 注意到这个值:16384, 它决定了 CBC latch的数量,我们确认它实际上就是 CBC latch的数量。
6.诊断CBC latch等待
现在开始尝试解决 CBC latch问题。 遭受 CBC latch等待的会话将显示在 V S E S S I O N 中。假设一个会话是 S I D 366 。要找出 C B C l a t c h , 需要检查 V SESSION 中。 假设一个会话是 SID 366。要找出 CBC latch,需要检查 V SESSION中。假设一个会话是SID366。要找出CBClatch,需要检查VSESSION 中的 P1、P1RAW 和 P1TEXT 值,如下所示:
select p1, p1raw, p1text
from v$session where sid = 366;
P1 P1RAW P1TEXT
---------- ---------------- -------
5553027696 000000014AFC7A70 address
P1TEXT清楚地显示了P1列的描述,即latch的地址。 在本例中,地址为 000000014AFC7A70。 我们可以检查latch的名称,并检查会话请求该latch但miss的次数。
SQL> select gets, misses, sleeps, name
2 from v$latch where addr = '000000014AFC7A70';
GETS MISSES SLEEPS NAME
----- ------ ------ --------------------
49081 14 10 cache buffers chains
从输出中确认这是一个 CBC latch。 它已get 49,081 次,14 次miss,10 次进程已进入sleep状态等待它。
接下来,识别其buffer中的热点对象。 从buffer cache中获取 File# 、 Block#以及obj(data_object_id),其中 CBC latch是我们确定存在问题的latch address:
select dbarfil, dbablk, obj,tch
from x$bh
where hladdr = '000000014AFC7A70';
DBARFIL DBABLK OBJ TCH
------- ------ ------ -----
6 220 93587 34523
TCH 列显示了touch计数,即buffer被访问了多少次,这是对其受欢迎程度的衡量标准,从而衡量了buffer受到 CBC latch等待的可能性。 从file#和block#我们可以获得OBJECT_ID
select segment_name from dba_extents where file_id=6 and 220 between block_id and block_id+blocks
SEGMENT_NAME
----------------------------------------
CBCTEST
或者直接:
select * from dba_objects where data_object_id=93587
OBJECT_NAME
----------------------------------------
CBCTEST
7.解决 CBC Latch等待
从上面可以看出一个重要的观察结果:CBC latch等待是由不同进程访问同一块或者链而导致的热点块(hot block)引起的。 如果降低热度,就会减少两个进程等待同一buffer的机会。 注意:无法完全消除等待; 只能减少它。 要减少等待,就减少逻辑I/O(logical read)。 例如,嵌套循环多次重新访问同一对象,导致buffer被多次访问。 如果重写查询以避免 NL,则将显著减少一个进程等待 CBC latch的机会。
同样,如果编写一个查询多次访问表中的块,也会发现这些块也变成热点块:
for i in 1..100000 loop
select …
into l_var
from tablea
where …;
exit when sql%notfound;
end loop;
可以重写代码,通过使用BULK COLLECT将数据从表中select到一个集合中,然后从该集合而不是从表中进行select。V$SESSION的SQL_ID列将显示导致CBC latch等待的SQL语句,而获取到Object将显示导致问题的查询中的具体对象,从而能够制定更好的解决方案。
还可以主动在活动会话历史(Active Session History)中查找导致CBC latch等待的对象,如下所示:
select p1raw, count(*)
from v$active_session_history
where sample_time < sysdate – 1/24
and event = 'latch: cache buffers chain'
group by event, p1
order by 3 desc;
P1RAW值显示latch address,使用它可以轻松找到file#和block#:
select o.name, bh.dbarfil, bh.dbablk, bh.tch
from x$bh bh, sys.obj$ o
where tch > 0
and hladdr= ''
and o.obj#=bh.obj
order by tch;
通过前面所示的方法,现在可以从 file# 和 block# 获取对象信息。 一旦知道导致 CBC latch等待的对象,就可以通过减少latch request的次数来减少等待。 可以通过降低table上的热点块(hot block)来做到这一点。 块中的行数越少,该块的热度就会降低。 可以通过增加 PCTFREE 或使用如下语句来减少块中的行数
ALTER TABLE … MINIMIZE RECORDS_PER_BLOCK 。
也可以对表进行分区。 这迫使为每个分区重新计算数据块地址(dba),使得buffer更有可能最终位于不同的cache buffer chain中,因此对同一链的竞争将会减少。


















 4972
4972

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









