







介绍
本项目跟踪了某晶体硅太阳能电池车间在2020年3月18日某生产车间一天内所有产生的电池,共计29323个产品的性能测试情况的汇总。可以看到电池效率控制在较好的状态,而影响效率的最主要因素的串联电阻Rs。如果能有办法下降电池片的Rs,就能稳定提高电池片的转换效率。
查看数据的基本情况
import pandas as pd
import matplotlib.pyplot as plt
from dateutil.parser import parse
from pandas.plotting import scatter_matrix
path = r"D:\python\course\Kaikeba\project\XeLamp\dataXe\solarCellData02.xlsx"
data = pd.read_excel(path)
print(data.head())

5 rows × 25 columns
print(data.shape)(29323, 25)
可以看到该数据由29323行,25列构成。
我们观察到这个数据的第三列"TestTimeDate"相当于第一列和第二列字符串的拼接,因此,这里出现重复信息,我们决定把第一列和第二列删除。接着我们发现最后两列"CellArea"和"Comment"提供的都是始终相同的信息,电池面积和工艺代号。于是我们决定将这2列也删除。
# 删除数据集中对统计无意义的列
data.drop(["TestDate", "TestTime", "CellArea", "Comment"], axis=1, inplace=True)
data.head() 这样数据集中这4列就没有了。
print(data.info())
我们可以看到数据集中没有NULL值。可是打开原始文件Excel表格后,我们却发现大量0值。我们先统计一下这个情况。
# 统计列中零值的个数
print((data==0).astype(int).sum(axis=0))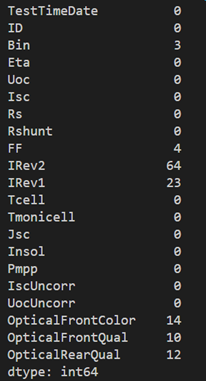
我们知道这些等于0的统计条目代表了测试异常。这些值是可以删除的。我们用如下代码删除这些行。
data = data[(data["Bin"] != 0) & (data["IRev2"] != 0) & (data["FF"] != 0)
(data["IRev1"] != 0) & (data["OpticalFrontColor"] != 0) &
(data["OpticalFrontQual"] != 0) & (data["OpticalRearQual"] != 0)]
# 统计列中零值的个数
print((data==0).astype(int).sum(axis=0))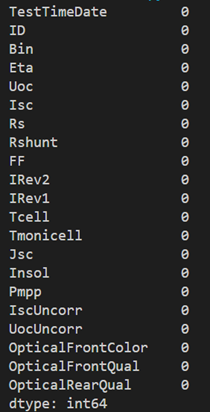
# 可以看到有89条数据记录被删除
print(data.shape)可以看到89条没有意义的数据已经被删除了。
data[["Eta", "Uoc", "Isc", "Rs", "Rshunt", "FF", "Insol", "Pmpp", "Tmonicell"]].hist(bins=50, figsize=(20,15))
plt.show() 然后我们将和太阳能电池性能高度相关的9个参数绘制成直方图,bin的数量选择50.

可以看到大部分图的横轴都跨度很大,这导致无法细致看清楚直方图内部的细节。这是测试过程中极少量的离群值(outlier)造成的。根据正态分布理论,我们写一个函数,过滤掉3倍标准差以上的离群值。
我们在同一个文件夹下新建一个python文件,取名outlierFilter.py. 然后输入如下代码。
import pandas as pd
# 根据正态分布的特性,可以将3*STD之外的数据视为异常值。
def outlierFilter(data, col):
mean,< 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2807
2807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









