






ThreadLocal:
ThreadLocal,很多地方叫做线程本地变量,也有些地方叫做线程本地存储,其实意思差不多。可能很多朋友都知道ThreadLocal为变量在每个线程中都创建了一个副本,那么每个线程可以访问自己内部的副本变量。
每一个ThreadLocal能够放一个线程级别的变量,可是它本身能够被多个线程共享使用,并且又能够达到线程安全的目的,且绝对线程安全。
ThreadLocal是用来维护本线程的变量的,并不能解决共享变量的并发问题。ThreadLocal是各线程将值存入该线程的map中,以ThreadLocal自身作为key,需要用时获得的是该线程之前存入的值。如果存入的是共享变量,那取出的也是共享变量,并发问题还是存在的。
ThreadLocal的主要用途是为了保持线程自身对象和避免参数传递,主要适用场景是按线程多实例(每个线程对应一个实例)的对象的访问,并且这个对象很多地方都要用到。
ThreadLocal 原理:
public T get() { }
public void set(T value) { }
public void remove() { }
protected T initialValue() { }
get()方法是用来获取ThreadLocal在当前线程中保存的变量副本,set()用来设置当前线程中变量的副本,remove()用来移除当前线程中变量的副本,initialValue()是一个protected方法,一般是用来在使用时进行重写的,它是一个延迟加载方法,下面会详细说明。
首先我们来看一下ThreadLocal类是如何为每个线程创建一个变量的副本的。
先看下get方法的实现:

第一句是取得当前线程,然后通过getMap(t)方法获取到一个map,map的类型为ThreadLocalMap。然后接着下面获取到<key,value>键值对,注意这里获取键值对传进去的是 this,而不是当前线程t。
如果获取成功,则返回value值。
如果map为空,则调用setInitialValue方法返回value。
我们上面的每一句来仔细分析:
首先看一下getMap方法中做了什么:

可能大家没有想到的是,在getMap中,是调用当期线程t,返回当前线程t中的一个成员变量threadLocals。
那么我们继续取Thread类中取看一下成员变量threadLocals是什么:

实际上就是一个ThreadLocalMap,这个类型是ThreadLocal类的一个内部类,我们继续取看ThreadLocalMap的实现:

可以看到ThreadLocalMap的Entry继承了WeakReference,并且使用ThreadLocal作为键值。
然后再继续看setInitialValue方法的具体实现:

很容易了解,就是如果map不为空,就设置键值对,为空,再创建Map,看一下createMap的实现:

至此,可能大部分朋友已经明白了ThreadLocal是如何为每个线程创建变量的副本的:
首先,在每个线程Thread内部有一个ThreadLocal.ThreadLocalMap类型的成员变量threadLocals,这个threadLocals就是用来存储实际的变量副本的,键值为当前ThreadLocal变量,value为变量副本(即T类型的变量)。
初始时,在Thread里面,threadLocals为空,当通过ThreadLocal变量调用get()方法或者set()方法,就会对Thread类中的threadLocals进行初始化,并且以当前ThreadLocal变量为键值,以ThreadLocal要保存的副本变量为value,存到threadLocals。
然后在当前线程里面,如果要使用副本变量,就可以通过get方法在threadLocals里面查找。
总结一下:
1)实际的通过ThreadLocal创建的副本是存储在每个线程自己的threadLocals中的;
2)为何threadLocals的类型ThreadLocalMap的键值为ThreadLocal对象,因为每个线程中可有多个threadLocal变量,就像上面代码中的longLocal和stringLocal;
3)在进行get之前,必须先set,否则会报空指针异常;
如果想在get之前不需要调用set就能正常访问的话,必须重写initialValue()方法。
因为在上面的代码分析过程中,我们发现如果没有先set的话,即在map中查找不到对应的存储,则会通过调用setInitialValue方法返回i,而在setInitialValue方法中,有一个语句是T value = initialValue(), 而默认情况下,initialValue方法返回的是null。
ThreadLocal的应用场景
用来解决 数据库连接、Session管理等。
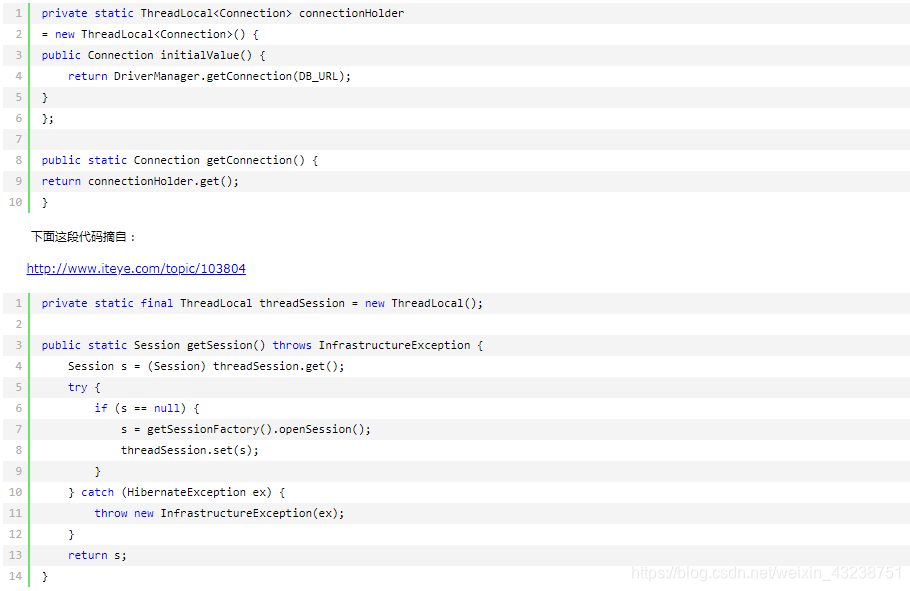
参考资料:
https://www.cnblogs.com/dolphin0520/p/3920407.html
https://blog.csdn.net/lhqj1992/article/details/52451136
https://www.zhihu.com/question/23089780
volitile关键字:
一旦一个共享变量(类的成员变量、类的静态成员变量)被volatile修饰之后,那么就具备了两层语义:
1)保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
2)禁止进行指令重排序。
先看一段代码,假如线程1先执行,线程2后执行:

下面解释一下这段代码为何有可能导致无法中断线程。在前面已经解释过,每个线程在运行过程中都有自己的工作内存,那么线程1在运行的时候,会将stop变量的值拷贝一份放在自己的工作内存当中。
那么当线程2更改了stop变量的值之后,但是还没来得及写入主存当中,线程2转去做其他事情了,那么线程1由于不知道线程2对stop变量的更改,因此还会一直循环下去。
但是用volatile修饰之后就变得不一样了:
第一:使用volatile关键字会强制将修改的值立即写入主存;
第二:使用volatile关键字的话,当线程2进行修改时,会导致线程1的工作内存中缓存变量stop的缓存行无效(反映到硬件层的话,就是CPU的L1或者L2缓存中对应的缓存行无效);
第三:由于线程1的工作内存中缓存变量stop的缓存行无效,所以线程1再次读取变量stop的值时会去主存读取。
参考文章:
https://www.cnblogs.com/dolphin0520/p/3920373.html
lock synchronized
如果一个代码块被synchronized修饰了,当一个线程获取了对应的锁,并执行该代码块时,其他线程便只能一直等待,等待获取锁的线程释放锁,而这里获取锁的线程释放锁只会有两种情况:
1)获取锁的线程执行完了该代码块,然后线程释放对锁的占有;
2)线程执行发生异常,此时JVM会让线程自动释放锁。
如果多个线程都只是进行读操作,所以当一个线程在进行读操作时,其他线程只能等待无法进行读操作。
Lock详解
讲述Lock接口中每个方法的使用,lock()、tryLock()、tryLock(long time, TimeUnit unit)和lockInterruptibly()是用来获取锁的。unLock()方法是用来释放锁的。newCondition()这个方法暂且不在此讲述,会在后面的线程协作一文中讲述。
在Lock中声明了四个方法来获取锁,那么这四个方法有何区别呢?
首先lock()方法是平常使用得最多的一个方法,就是用来获取锁。如果锁已被其他线程获取,则进行等待。
由于在前面讲到如果采用Lock,必须主动去释放锁,并且在发生异常时,不会自动释放锁。因此一般来说,使用Lock必须在try{}catch{}块中进行,并且将释放锁的操作放在finally块中进行,以保证锁一定被被释放,防止死锁的发生。通常使用Lock来进行同步的话,是以下面这种形式去使用的:
ryLock()方法是有返回值的,它表示用来尝试获取锁,如果获取成功,则返回true,如果获取失败(即锁已被其他线程获取),则返回false,也就说这个方法无论如何都会立即返回。在拿不到锁时不会一直在那等待。
tryLock(long time, TimeUnit unit)方法和tryLock()方法是类似的,只不过区别在于这个方法在拿不到锁时会等待一定的时间,在时间期限之内如果还拿不到锁,就返回false。如果如果一开始拿到锁或者在等待期间内拿到了锁,则返回true。
lockInterruptibly()方法比较特殊,当通过这个方法去获取锁时,如果线程正在等待获取锁,则这个线程能够响应中断,即中断线程的等待状态。也就使说,当两个线程同时通过lock.lockInterruptibly()想获取某个锁时,假若此时线程A获取到了锁,而线程B只有在等待,那么对线程B调用threadB.interrupt()方法能够中断线程B的等待过程。
由于lockInterruptibly()的声明中抛出了异常,所以lock.lockInterruptibly()必须放在try块中或者在调用lockInterruptibly()的方法外声明抛出InterruptedException。
注意,当一个线程获取了锁之后,是不会被interrupt()方法中断的。因为本身在前面的文章中讲过单独调用interrupt()方法不能中断正在运行过程中的线程,只能中断阻塞过程中的线程。
因此当通过lockInterruptibly()方法获取某个锁时,如果不能获取到,只有进行等待的情况下,是可以响应中断的。
而用synchronized修饰的话,当一个线程处于等待某个锁的状态,是无法被中断的,只有一直等待下去。
2.ReentrantLock
ReentrantLock,意思是“可重入锁”,关于可重入锁的概念在下一节讲述。ReentrantLock是唯一实现了Lock接口的类,并且ReentrantLock提供了更多的方法。下面通过一些实例看具体看一下如何使用ReentrantLock。
总结来说,Lock和synchronized有以下几点不同:
1)Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现;
2)synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁;
3)Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断;
4)通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。
5)Lock可以提高多个线程进行读操作的效率。
在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
设计模式:














 1784
1784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









