







Spark之三大数据结构
文章目录
三大数据结构
Spark 计算框架为了能够进行高并发和高吞吐的数据处理,封装了三大数据结构,用于
处理不同的应用场景。三大数据结构分别是
- RDD : 弹性分布式数据集
- 累加器:分布式共享只写变量
- 广播变量:分布式共享只读变量
RDD
spark最小计算单元
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
弹性
- 存储的弹性:内存与磁盘的自动切换
- 容错的弹性:数据丢失可以自动恢复
- 计算的弹性:计算出错重试机制
- 分片的弹性:可根据需要重新分片
分布式
数据存储在大数据集群不同节点上
数据集
RDD 封装了计算逻辑,并不保存数据
数据抽象
RDD 是一个抽象类,需要子类具体实现
不可变
RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的RDD 里面封装计算逻辑
以WordCount为例
def main(args: Array[String]): Unit = {
//Application
//Spark框架
//建立和Spark框架的连接
//JDBC:Connection
val sparConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparConf)
val lines: RDD[String] = sc.textFile("datas")
val words: RDD[String] = lines.flatMap(_.split(" "))
val wordToOne: RDD[(String, Int)] = words.map(
word => (word, 1)
)
//Spark框架提供了跟多功能,可以将分组和聚合使用一个方法实现
/**
* reduceByKey:相同的key的数据,可以对value进行reduce聚合
*/
// wordToOne.reduceByKey((x,y)=>{x+y})
val wordToCount: RDD[(String, Int)] = wordToOne.reduceByKey(_ + _)
//5.将转换结果采集到控制台来
val array: Array[(String, Int)] = wordToCount.collect()
array.foreach(println)
//关闭连接
sc.stop()
}
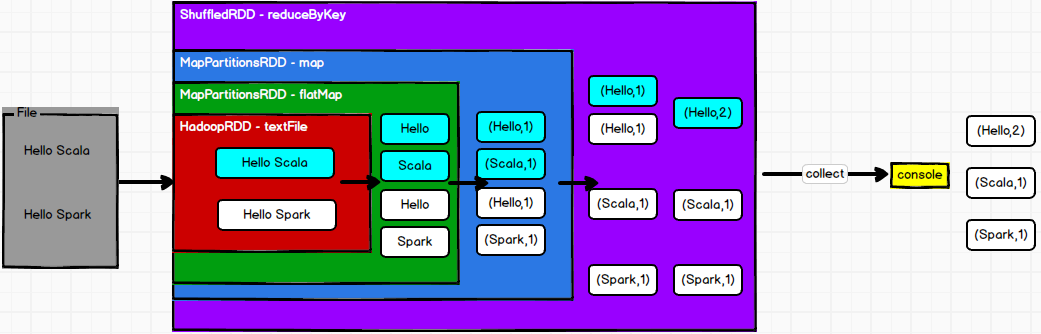
- RDD的数据处理方式类似于IO流,也有装饰者设计模式
- RDD的数据只有在调用collect方法时,才会真正执行业务逻辑操作。之前的封装全部都是功能的扩展
- RDD是不保存数据的,但是IO可以临时保存一部分数据
五大配置
1.分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性

2.分区计算函数
Spark 在计算时,是使用分区函数对每一个分区进行计算

3.RDD 之间的依赖关系
RDD 是计算模型的封装,当需求中需要将多个计算模型进行组合时,就需要将多个 RDD 建立依赖关系

4.分区器
当数据为 KV 类型数据时,可以通过设定分区器自定义数据的分区

5.首选位置
计算数据时,可以根据计算节点的状态选择不同的节点位置进行计算

执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
启动 Yarn 集群环境
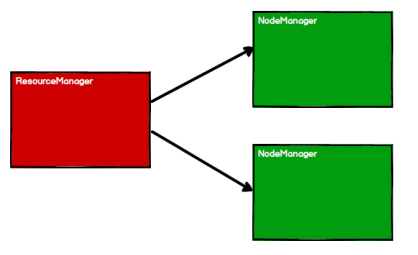
Spark 通过申请资源创建调度节点和计算节点
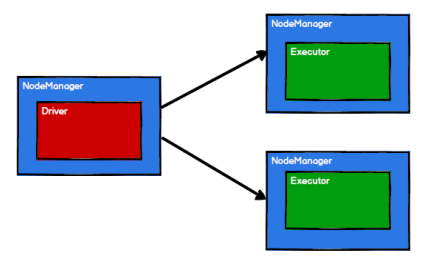
Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
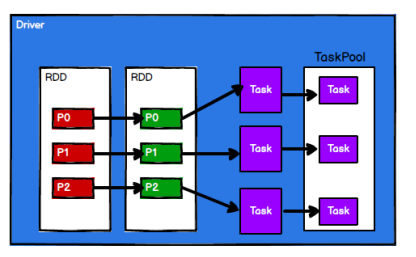
调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
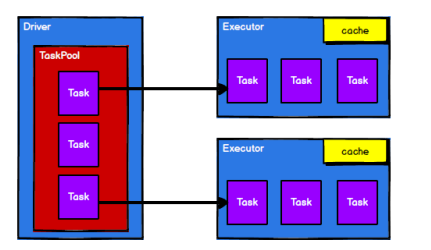
累加器
累加器用来把 Executor 端变量信息聚合到 Driver 端。在 Driver 程序中定义的变量,在Executor 端的每个 Task 都会得到这个变量的一份新的副本,每个 task 更新这些副本的值后,传回 Driver 端进行 merge。
val sparkconf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
val sc = new SparkContext(sparkconf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//两两聚合
/**
* 分区内的计算
* 分区间的计算
*/
/* val i: Int = rdd.reduce(_ + _)
println(i)*/
var sum =0
rdd.foreach(
num =>{
sum += num
}
)
println("sum="+sum)
sc.stop()
}

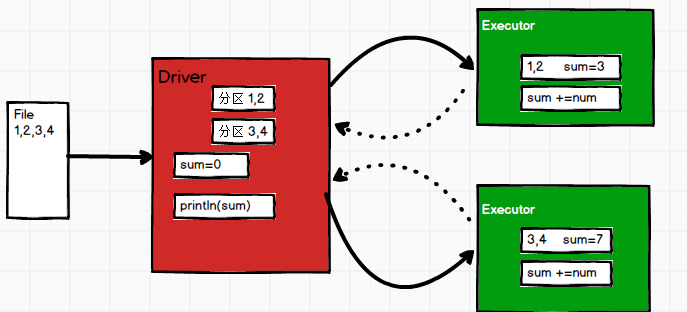
以上代码用foreach做了一个简单的两两聚合的计算,但是计算结果为0
因为在Executor的计算结果不会返回到Driver 端进行 merge
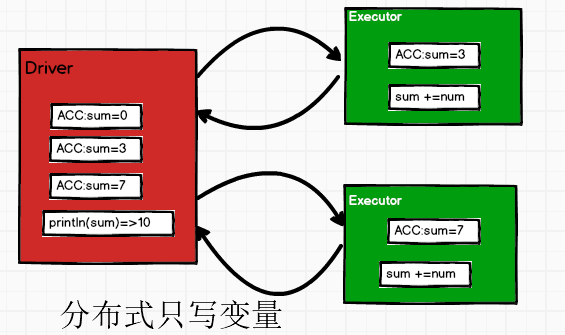
系统累加器
def main(args: Array[String]): Unit = {
val sparkconf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
val sc = new SparkContext(sparkconf)
val rdd: RDD[Int] = sc.makeRDD(List(1, 2, 3, 4))
//获取系统的累加器
//Spark默认就是提供了简单数据聚合的累加器
val sumAcc: LongAccumulator = sc.longAccumulator("sum")
rdd.foreach(
num =>{
//使用累加器
sumAcc.add(num)
}
)
//获取累加器的值
println(sumAcc.value)
sc.stop()
}

自定义累加器
def main(args: Array[String]): Unit = {
val sparkconf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
val sc = new SparkContext(sparkconf)
val rdd: RDD[String] = sc.makeRDD(List("hello", "scala", "hello"))
/**
* 使用累加器实现WordCount
* 避免shuffle 提高性能
* 创建累加器对象
* 向spark进行注册
*/
val wcAcc = new MyAcc
sc.register(wcAcc,"wordcountAcc")
rdd.foreach(
word =>{
//数据的累加
wcAcc.add(word)
}
)
//获取累加器的结果
println(wcAcc.value)
sc.stop()
}
/**
- 自定义数据累加器
- 1.继承AccumulatorV2 定义泛型
- IN:累加器输入的数据类型---String
- OUT:累加器返回的数据类型---Long
*/
class MyAcc extends AccumulatorV2[String,mutable.Map[String,Long]]{
private var wcMap=mutable.Map[String,Long]()
//判断是否为初始状态
override def isZero: Boolean = {
wcMap.isEmpty
}
override def copy(): AccumulatorV2[String, mutable.Map[String, Long]] = {
new MyAcc
}
//重置累加器
override def reset(): Unit = {
wcMap.clear()
}
//获取累加器计算的值
override def add(word: String): Unit = {
// 查询 map 中是否存在相同的单词
// 如果有相同的单词,那么单词的数量加 1
// 如果没有相同的单词,那么在 map 中增加这个单词
val newCnt: Long = wcMap.getOrElse(word, 0L) + 1
wcMap.update(word,newCnt)
}
//Driver合并多个累加器
override def merge(other: AccumulatorV2[String, mutable.Map[String, Long]]): Unit = {
val map1 = this.wcMap
val map2 = other.value
//两个Map的合并
map2.foreach{
case (word,count) =>{
val newCount: Long = map1.getOrElse(word,0L)+count
map1.update(word,newCount)
}
}
}
//累加器结果(out)
override def value: mutable.Map[String, Long] = {
wcMap
}
}

广播变量
广播变量用来高效分发较大的对象。向所有工作节点发送一个较大的只读值,以供一个或多个 Spark 操作使用。比如,如果你的应用需要向所有节点发送一个较大的只读查询表,广播变量用起来都很顺手。在多个并行操作中使用同一个变量,但是 Spark 会为每个任务分别发送
def main(args: Array[String]): Unit = {
val sparkconf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc = new SparkContext(sparkconf)
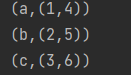
val rdd1: RDD[(String, Int)] = sc.makeRDD(List(
("a", 1), ("b", 2), ("c", 3)
))
val map: mutable.Map[String, Int] = mutable.Map(("a", 4), ("b", 5), ("c", 6))
//封装广播变量
val bc: Broadcast[mutable.Map[String, Int]] = sc.broadcast(map)
rdd1.map{
case(w,c)=>{
//访问广播变量
val l: Int = bc.value.getOrElse(w, 0)
(w,(c,l))
}
}.collect().foreach(println)
sc.stop()
}
这种方法可以用join实现,但是join会导致数据的几何增长(笛卡尔积),并且会影响shuffle的性能,不推荐使用
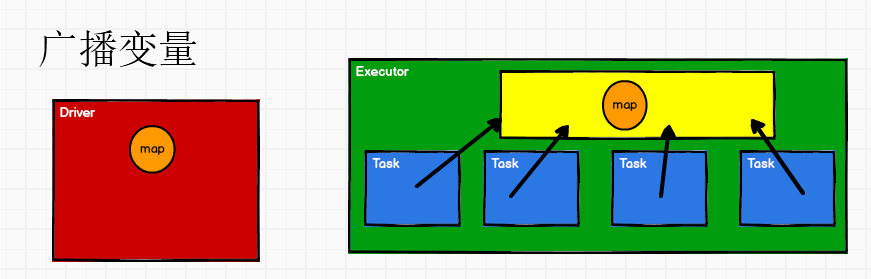
- 闭包数据,都是以Task为单位发送的,每个任务中包含闭包数据。这样可能会导致,一个Executor中含有大量重复的数据,并且占用大量的内存
- Executor其实就一个JVM,所以在启动时,会自动分配内存。完全可以将任务中的闭包数据放置在Executor的内存中,达到共享的目的
- Spark中的广播变量就可以将闭包的数据保存到Executor的内存中
- Spark中的广播变量不能够更改 : 分布式共享只读变量















 1578
1578











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









