







本教程的所有内容仅供学习和参考之用. 任何人或组织不得将本教程的内容用于非法用途或侵犯他人合法权益。本教程所涉及的爬虫技术仅用于学习和研究,不得用于对其他平台进行大规模爬虫或其他非法行为。
微博整体爬虫比较简单,不涉及接口签名,我们只需要找出帖子搜索和评论接口的请求参数即可
成果展示

抓包接口
本次我们分析的是微博H5页面,链接:https://m.weibo.cn/,至于为什么不是PC端呢,因为PC端如果要获取关键词搜索的结果,我们需要解析搜索结果页面HTML,相较于H5端有现成的关键词搜索API,肯定选择后者比较方便一些。
使用浏览器打开H5页面地址
需要提前在浏览器按F12进入控制台并选择打开手机模式

搜索任意关键词
以
python这个关键词为例

在浏览器控制台右侧选择 Fetch/XHR 过滤请求,我们还可以在右侧过滤特定关键词的请求,比如我们这个例子使用了python,那么搜索python 很轻松就看见具体的搜索接口了: https://m.weibo.cn/api/container/getIndex
分析搜索接口传递的参数

从搜索接口的Payload可以看到我们第一次搜索python关键词时,传递了两个参数:
- containerid: 100103type=1&q=python
- page_type: searchall
从containerid参数中有一个字眼q=python大致能猜出关键词是如何传递的。
现在关键词参数有了,接下来看看如何找出分页参数,在现代的web app架构中,大多数应用都是前后端分离的,像微博这样的大公司肯定也是,而在H5端实现分页的技术方案也比较统一,基本都是滚动加载触发分页请求,轻轻滑动你的鼠标,在右侧的控制台中就能看见发起了第二次加载请求,同样的方式点开请求的 Payload,这一次明显的发现相较于第一次多了一个 page 参数了,那么分页的参数就很明显了。

总结一下,微博H5端搜索API请求信息:
API:https://m.weibo.cn/api/container/getIndex
方法:GET
参数:
- containerid: 包含搜索参数和搜索类型 示例值:100103type=1&q=python
- page_type: 搜索范围,示例值:searchall
- page: 分页参数,示例值:1
分析接口返回的响应
点击Payload右侧的 Preview按钮,就能看见本次请求的响应信息
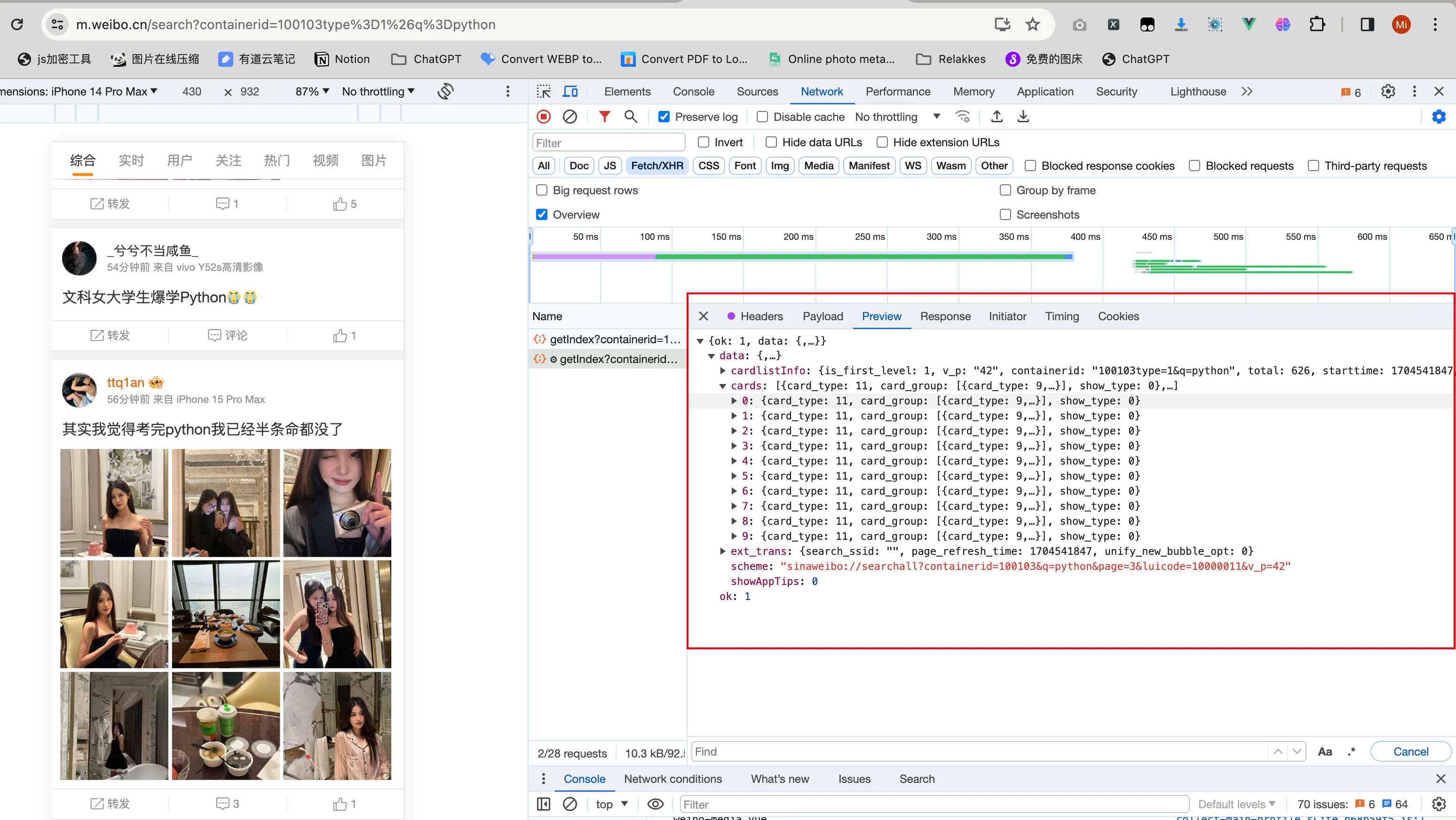
其中 data.cards 就是我们需要的微博关键词搜索结果列表,随便点开一个cards中的信息,找到微博帖子具体存放的属性值即可,剩下的工作就是解析这些json数据就可以了。
评论接口的分析同上


这里就不展开分析了,直接给出评论API请求信息:
API:https://m.weibo.cn/comments/hotflow
方法:GET
参数:
- id: 微博ID,示例值:4961967981462456
- mid: 微博ID,示例值:4961967981462456
- max_id: 分页ID,示例值:138871510152499
- max_id_type: 评论类型,默认0
代码实现
本教程用的是python异步请求库httpx,用法基本和requests一样,只不过是写法用的是异步的,关于Python异步编程后续也考虑出一些教程
请求客户端简单封装
class WeiboClient:
def __init__(
self,
timeout=10,
proxies=None,
*,
headers: Dict[str, str],
cookie_dict: Dict[str, str],
):
pass
async def request(self, method, url, **kwargs) -> Any:
async with httpx.AsyncClient(proxies=self.proxies) as client:
response = await client.request(
method, url, timeout=self.timeout,
**kwargs
)
data: Dict = response.json()
if data.get("ok") != 1:
utils.logger.error(f"[WeiboClient.request] request {method}:{url} err, res:{data}")
raise DataFetchError(data.get("msg", "unkonw error"))
else:
return data.get("data", {})
async def get(self, uri: str, params=None, headers=None) -> Dict:
final_uri = uri
if isinstance(params, dict):
final_uri = (f"{uri}?"
f"{urlencode(params)}")
if headers is None:
headers = self.headers
return await self.request(method="GET", url=f"{self._host}{final_uri}", headers=headers)
async def post(self, uri: str, data: dict) -> Dict:
json_str = json.dumps(data, separators=(',', ':'), ensure_ascii=False)
return await self.request(method="POST", url=f"{self._host}{uri}",
data=json_str, headers=self.headers)
搜索接口封装
async def get_note_by_keyword(
self,
keyword: str,
page: int = 1,
search_type: SearchType = SearchType.DEFAULT
) -> Dict:
"""
search note by keyword
:param keyword: 微博搜搜的关键词
:param page: 分页参数 -当前页码
:param search_type: 搜索的类型,见 weibo/filed.py 中的枚举SearchType
:return:
"""
uri = "/api/container/getIndex"
containerid = f"100103type={search_type.value}&q={keyword}"
params = {
"containerid": containerid,
"page_type": "searchall",
"page": page,
}
return await self.get(uri, params)
评论接口封装
async def get_note_comments(self, mid_id: str, max_id: int) -> Dict:
"""get notes comments
:param mid_id: 微博ID
:param max_id: 分页参数ID
:return:
"""
uri = "/comments/hotflow"
params = {
"id": mid_id,
"mid": mid_id,
"max_id_type": 0,
}
if max_id > 0:
params.update({"max_id": max_id})
referer_url = f"https://m.weibo.cn/detail/{mid_id}"
headers = copy.copy(self.headers)
headers["Referer"] = referer_url
return await self.get(uri, params, headers=headers)
async def get_note_all_comments(self, note_id: str, crawl_interval: float = 1.0, is_fetch_sub_comments=False,
callback: Optional[Callable] = None, ):
"""
get note all comments include sub comments
:param note_id:
:param crawl_interval:
:param is_fetch_sub_comments:
:param callback:
:return:
"""
result = []
is_end = False
max_id = -1
while not is_end:
comments_res = await self.get_note_comments(note_id, max_id)
max_id: int = comments_res.get("max_id")
comment_list: List[Dict] = comments_res.get("data", [])
is_end = max_id == 0
if callback: # 如果有回调函数,就执行回调函数
await callback(note_id, comment_list)
await asyncio.sleep(crawl_interval)
if not is_fetch_sub_comments:
result.extend(comment_list)
continue
# todo handle get sub comments
return result
请求客户端的代码结构基本就是上面这些了,当然有些依赖啥的这里没有全部贴进来,文章末尾会直接给提供源码地址,有需要的直接去查看接口
登录实现
由于我们选择的爬去的是微博H5端的请求,所以如果选择cookies登录的方式,对应也要去H5端完成登录,保存Cookies,如果是选择二维码的话,不需要考虑这个问题,程序会自动去完成。
登录类实现了两种方式登录:
- 二维码扫码登录,该功能会自动打开页面找到登录二维码并调用系统显示图片功能展示
- Cookies,手动在页面上登录成功后填写
登录源码如下:
# -*- coding: utf-8 -*-
# @Author : relakkes@gmail.com
# @Time : 2023/12/23 15:42
# @Desc : 微博登录实现
import asyncio
import functools
import sys
from typing import Optional
from playwright.async_api import BrowserContext, Page
from tenacity import (RetryError, retry, retry_if_result, stop_after_attempt,
wait_fixed)
from base.base_crawler import AbstractLogin
from tools import utils
class WeiboLogin(AbstractLogin):
def __init__(self,
login_type: str,
browser_context: BrowserContext,
context_page: Page,
login_phone: Optional[str] = "",
cookie_str: str = ""
):
self.login_type = login_type
self.browser_context = browser_context
self.context_page = context_page
self.login_phone = login_phone
self.cookie_str = cookie_str
async def begin(self):
"""Start login weibo"""
utils.logger.info("[WeiboLogin.begin] Begin login weibo ...")
if self.login_type == "qrcode":
await self.login_by_qrcode()
elif self.login_type == "phone":
await self.login_by_mobile()
elif self.login_type == "cookie":
await self.login_by_cookies()
else:
raise ValueError(
"[WeiboLogin.begin] Invalid Login Type Currently only supported qrcode or phone or cookie ...")
@retry(stop=stop_after_attempt(20), wait=wait_fixed(1), retry=retry_if_result(lambda value: value is False))
async def check_login_state(self, no_logged_in_session: str) -> bool:
"""
Check if the current login status is successful and return True otherwise return False
retry decorator will retry 20 times if the return value is False, and the retry interval is 1 second
if max retry times reached, raise RetryError
"""
current_cookie = await self.browser_context.cookies()
_, cookie_dict = utils.convert_cookies(current_cookie)
current_web_session = cookie_dict.get("WBPSESS")
if current_web_session != no_logged_in_session:
return True
return False
async def popup_login_dialog(self):
"""If the login dialog box does not pop up automatically, we will manually click the login button"""
dialog_selector = "xpath=//div[@class='woo-modal-main']"
try:
# check dialog box is auto popup and wait for 4 seconds
await self.context_page.wait_for_selector(dialog_selector, timeout=1000 * 4)
except Exception as e:
utils.logger.error(
f"[WeiboLogin.popup_login_dialog] login dialog box does not pop up automatically, error: {e}")
utils.logger.info(
"[WeiboLogin.popup_login_dialog] login dialog box does not pop up automatically, we will manually click the login button")
# 向下滚动1000像素
await self.context_page.mouse.wheel(0,500)
await asyncio.sleep(0.5)
try:
# click login button
login_button_ele = self.context_page.locator(
"xpath=//a[text()='登录']",
)
await login_button_ele.click()
await asyncio.sleep(0.5)
except Exception as e:
utils.logger.info(f"[WeiboLogin.popup_login_dialog] manually click the login button faield maybe login dialog Appear:{e}")
async def login_by_qrcode(self):
"""login weibo website and keep webdriver login state"""
utils.logger.info("[WeiboLogin.login_by_qrcode] Begin login weibo by qrcode ...")
await self.popup_login_dialog()
# find login qrcode
qrcode_img_selector = "//div[@class='woo-modal-main']//img"
base64_qrcode_img = await utils.find_login_qrcode(
self.context_page,
selector=qrcode_img_selector
)
if not base64_qrcode_img:
utils.logger.info("[WeiboLogin.login_by_qrcode] login failed , have not found qrcode please check ....")
sys.exit()
# show login qrcode
partial_show_qrcode = functools.partial(utils.show_qrcode, base64_qrcode_img)
asyncio.get_running_loop().run_in_executor(executor=None, func=partial_show_qrcode)
utils.logger.info(f"[WeiboLogin.login_by_qrcode] Waiting for scan code login, remaining time is 20s")
# get not logged session
current_cookie = await self.browser_context.cookies()
_, cookie_dict = utils.convert_cookies(current_cookie)
no_logged_in_session = cookie_dict.get("WBPSESS")
try:
await self.check_login_state(no_logged_in_session)
except RetryError:
utils.logger.info("[WeiboLogin.login_by_qrcode] Login weibo failed by qrcode login method ...")
sys.exit()
wait_redirect_seconds = 5
utils.logger.info(
f"[WeiboLogin.login_by_qrcode] Login successful then wait for {wait_redirect_seconds} seconds redirect ...")
await asyncio.sleep(wait_redirect_seconds)
async def login_by_mobile(self):
pass
async def login_by_cookies(self):
utils.logger.info("[WeiboLogin.login_by_qrcode] Begin login weibo by cookie ...")
for key, value in utils.convert_str_cookie_to_dict(self.cookie_str).items():
await self.browser_context.add_cookies([{
'name': key,
'value': value,
'domain': ".weibo.cn",
'path': "/"
}])
源代码安装和使用教程
微博爬虫的源代码代码上传到github和gitee上,上面除了微博平台的爬虫实现,也包含了抖音爬虫、小红书爬虫、快手爬虫等等
Github: MediaCrawler 微博爬虫源代码Github链接 :https://github.com/NanmiCoder/MediaCrawler
Gitee: MediaCrawler 微博爬虫源代码Gitee链接:https://gitee.com/NanmiCoder/MediaCrawler















 1446
1446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











