








什么是数据库
数据库就是存储数据的仓库,平时所用到的电脑上的资料等都可以看作是数据。
对数据库的操作,我们可以通过SQL语句进行操作,也可以通过可视化界面操作。
数据库的几个概念
- 数据库服务器 —>对应计算机
- 数据库管理系统 —>对应操作系统
- 库 —>文件夹
- 表 —>文件
- 记录 —>文件中的表头
- 数据 —>文件中的数据
MySQL的下载以及安装可以参考网上的例子,Windows MySQL下载地址。
数据库图形化界面工具使用的是Navicat Premium。
zip压缩包安装的数据库在安装好之后,会有一个root用户,密码默认是没有的。
修改时区
-
查看MySQL当前时区
show variables like "%time_zone%";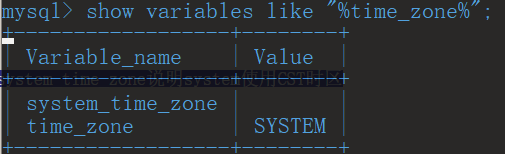
上面的time_zone如果显示的是SYSTEM说明是系统时间,我们需要把他改成东8区时间。 -
修改时区
set global time_zone = '+8:00';##修改mysql全局时区为北京时间,即我们所在的东8区 set time_zone = '+8:00';##修改当前会话时区 flush privileges; ##立即生效
修改密码
方法一:使用mysqladmin命令
打开cmd中,直接输入
mysqladmin -u 用户名 -p password “新密码”
例如:mysqladmin -u root -p password “123456”
这里的新密码必须要用双引号引起来
回车之后,就会让输入密码,输入原密码就可以了
方法二:使用sql语句(记得用户的密码情况下)
set password for ‘用户名’@‘IP地址’ = password(‘新密码’)
忘记管理员密码怎么办??
1、在管理员cmd中先关闭mysql服务
net stop mysql
2、跳过授权
mysqld --skip-grant-tables
3、保持第一个cmd存在,重新打开一个cmd出入mysql -u 用户名 -p
4、不用输入密码就可以进入
5、使用update sql语句更改密码
update mysql.user set authentication_string =password(‘’) where User=‘root’;
6、刷新权限
flush privileges;
7、退出mysql
8、使用管理员cmd查看mysql进程,并删除该进程
tasklist |findstr mysql
taskkill /F /PID ****
9、在管理员cmd中重启mysql
net start mysql
10、重新尝试登陆
查看当前数据库配置
先在cmd中进行登录,输入\s

用户权限
-
创建用户
-- 创建用户 create user '用户名'@'IP地址' identified by '密码’; -- 删除用户 drop user '用户名'@'IP地址'; -- 修改用户 rename user '用户名'@'IP地址'; to '新用户名'@'IP地址'; -
查看已有用户
SELECT DISTINCT CONCAT('User: ''',user,'''@''',host,''';') AS query FROM mysql.user; -
删除已有用户
drop user 'username'@'host'; -
授权管理
show grants for '用户名'@'IP地址'; -- 查看权限 grant 权限 on 数据库.表 to '用户名'@'IP地址'; -- 授权 grant all privileges on *.* to '用户名'@'IP地址';-- 授权所有权限 revoke 权限 on 数据库.表 from '用户名'@'IP地址'; -- 取消权限 revoke all privileges on *.* from '用户名'@'IP地址'; -- 取消所有权限 -
开放外部访问权限
create user '用户名'@'IP地址' identified by '密码';
grant all privileges on *.* to '用户名'@'IP地址';
flush privileges;
数据类型
二进制数据:TinyBlob、Blob、MediumBlob、LongBlob
-
bit[(M)]
二进制位(101001),m表示二进制位的长度(1-64),默认m=1 -
tinyint[(m)] [unsigned] [zerofill]
小整数,数据类型用于保存一些范围的整数数值范围:默认有符号
有符号:
-128 ~ 127.
无符号:
255注意: MySQL中无布尔值,使用tinyint(1)构造。
构造无符号的tinyint类型数据:create table t1(id tinyint unsigned); -
int[(m)][unsigned][zerofill]
整数,数据类型用于保存一些范围的整数数值范围:默认有符号
有符号:
-2147483648 ~ 2147483647
无符号:
4294967295注意:整数类型中的m仅用于显示,对存储范围无限制。例如: int(5),当插入数据2时,select 时数据显示为: 00002
-
bigint[(m)][unsigned][zerofill]
大整数,数据类型用于保存一些范围的整数数值范围:
有符号:
-9223372036854775808 ~ 9223372036854775807
无符号:
18446744073709551615 -
decimal[(m,d)][unsigned][zerofill]
准确的小数值,m是数字总个数(负号不算),d是小数点后个数。 m最大值为65,d最大值为30。注意:对于精确数值计算时需要用此类型,decaimal能够存储精确值的原因在于其内部按照字符串存储。
-
float[(m,d)][unsigned][zerofill]
单精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
无符号:
-3.402823466E+38 to -1.175494351E-38,
1.175494351E-38 to 3.402823466E+38
有符号:
1.175494351E-38 to 3.402823466E+38注意: FLOATDE 数值越大,越不准确。
-
double[(m,d)][unsigned][zerofill]
双精度浮点数(非准确小数值),m是数字总个数,d是小数点后个数。
无符号:
-1.7976931348623157E+308 to -2.2250738585072014E-308
2.2250738585072014E-308 to 1.7976931348623157E+308
有符号:
2.2250738585072014E-308 to 1.7976931348623157E+308注意: double 数值越大,越不准确。
-
char (m)
char数据类型用于表示固定长度的字符串,可以包含最多达255个字符。其中m代表字符串的长度。注意:即使数据小于m长度,也会占用m长度
-
varchar(m)
varchars数据类型用于变长的字符串,可以包含最多达255个字符。其中m代表该数据类型所允许保存的字符串的最大长度,只要长度小于该最大值的字符串都可以被保存在该数据类型中。注意:虽然varchar使用起来较为灵活,但是从整个系统的性能角度来说,char数据类型的处理速度更快,有时甚至可以超出varchar处理速度的50%。因此,用户在设计数据库时应当综合考虑各方面的因素,以求达到最佳的平衡
-
text
text数据类型用于保存变长的大字符串,可以组多到65535 (2**16 − 1)个字符。 -
mediumtext
A TEXT column with a maximum length of 16,777,215 (2**24 − 1) characters. -
longtext
A TEXT column with a maximum length of 4,294,967,295 or 4GB (2**32 − 1) characters. -
enum
枚举类型,
An ENUM column can have a maximum of 65,535 distinct elements. (The practical limit is less than 3000.)
示例:create table shirts ( name varchar(40), size enum('x-small', 'small', 'medium', 'large', 'x-large') ); insert into shirts (name, size) values ('dress shirt','large'), ('t-shirt','medium'),('polo shirt','small'); -
set
集合类型
A SET column can have a maximum of 64 distinct members.
示例:create table myset (col SET('a', 'b', 'c', 'd')); insert into myset (col) VALUES ('a,d'), ('d,a'), ('a,d,a'), ('a,d,d'), ('d,a,d'); -
DATE
YYYY-MM-DD(1000-01-01/9999-12-31) -
TIME
HH:MM:SS(‘-838:59:59’/‘838:59:59’) -
YEAR
YYYY(1901/2155) -
DATETIME
YYYY-MM-DD HH:MM:SS(1000-01-01 00:00:00/9999-12-31 23:59:59 Y) -
TIMESTAMP
YYYYMMDD HHMMSS(1970-01-01 00:00:00/2037 年某时)
库操作(不能修改,只能删除重新创建)
MySQL不支持事务,所以可以在创建SQL语句的后面加上
engine = innodb,当数据出现问题是,支持回滚操作。创建数据库或者表的时候,还要注意编码的问题,当数据库名称或者表的数据由中文的时候,需要在创建sql语句的最后加上一句话default charset=utf8,同时
注意使用的语句中由空格分隔开。
-
创建
create database 数据库名字 engine = innodb default charset=utf8; -
删除
drop database 数据库名字; -
使用
use 数据库名称; -
查看库
show databases;(查看当前用户下所有的库名)
select database();(查看当前使用的数据库)
show create database 数据库名称;(查看创建库的信息)
表操作的SQL语句(不区分大小写)
-
创建表(每个字段要以逗号结尾,还要注意编码问题)
create table student_info1( 列名 类型 null, -- null 表示可以为空 列名 类型 not null, -- not null 表示不能为空 列名 类型 not null auto_increment primary key -- auto_increment表示可以自增,同时必须是key。primary key表示主键,来进行约束(不能重复且不能为空),加速查找。 )engine = innodb default charset = utf8; -
查看表(每行要以分号结尾)
SELECT * FROM student_info; -- 查看表中的所有数据 DESC student_info; -- 查看表的结构信息 show create table student_info; -- 查看表的创建信息 show create table student_info \G; -- 表的创建信息旋转一下查看 -
删除表
drop table teacher_info; -- 删除表 -
清空表
-- 当不再需要该表时, 用 drop; -- 当仍要保留该表,但要删除所有记录时, 用 truncate; -- 当要删除部分记录时(always with a WHERE clause), 用 delete. delete from 表名; truncate table 表名; -- Truncate是一个能够快速清空资料表内所有资料的SQL语法。并且能针对具有自动递增值的字段,做计数重置归零重新计算的作用。 -
修改表
添加列:alter table 表名 add 列名 类型; 删除列:alter table 表名 drop column 列名; 修改列:alter table 表名 modify column 列名 类型; -- 只能修改类型,不能添加约束 alter table 表名 change 原列名 新列名 类型; -- 列名,类型(只能修改类型,不能添加约束) 添加主键:alter table 表名 add primary key(列名); 删除主键:alter table 表名 drop primary key; alter table 表名 modify 列名 drop primary key; 添加外键:alter table 从表 add constraint 外键名称(形如:FK_从表_主表) foreign key 从表(外键字段) references 主表(主键字段); 删除外键:alter table 表名 drop foreign key 外键名称; 修改默认值:alter table 表名 alter 列名 set default 1000; 删除默认值:alter table 表名 alter 列名 drop default;
完整性约束
约束条件与数据类型的宽度一样,都是可选参数,约束用来保证数据的完整性和一致性,主要的约束条件有一下几个:
-
primary key 主键
一个表中只有唯一的一个主键,不能有多列主键,但可以有复合主键。
一个表中可以单列做主键,也可以多列做主键(复合主键),其中主键的约束要不能为空且唯一,存储引擎默认是innodb,对于innodb来说,一张表必须有一个主键。
1、单列主键create table t14( id int primary key, name char(16) );not null + unique的化学反应,相当于给id设置primary key
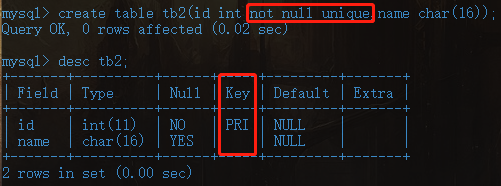
2、复合主键
create table t16( ip char(15), port int, primary key(ip,port) ); insert into t16 values('1.1.1.2',80),('1.1.1.2',81);应用举例:比如’选课’系统(学生号,课程号,分数),每个学生可以选修多门课程,每门课程可以有多名学生选修。
-
not null和null 是否为空
-
default 设置默认值
默认值,创建列时可以指定默认值,当插入数据时如果未主动设置,则自动添加默认值create table tb1( nid int not null default 2, num int nut null ); -
unique 表示该字段是唯一的,不能有重复
unique又可以分为单列唯一和联合唯一
1、单列唯一create table department( id int, name char(10) unique );2、联合唯一
只要两列记录,有一列不同,就不能添加create table services( id int, ip char(15), port int, unique(ip,port) ); -
auto_increment
约束:约束的字段为自动增长,约束的字段必须同时被key约束,对于自增的字段,在用delete删除后,再插入值,该字段仍按照删除前的位置继续增长
delete from t1 where id = *;如果有自增id,新增的数据,仍然是以删除前的最后一样作为起始。
truncate table t1;删除数据量大的数据库,删除速度比上一条快,同时保留表结构,且使得id可以直接从零开始,后面不能跟条件。 -
unsigned 无符号
-
zerofill 用0填充
-
foreign key 外键
数据操作
增加数据
insert into info values(字段1,字段2,字段3);
insert into info(字段1,字段2) values(值1,值2);
insert into tb11(字段1,字段2) values('值',值2),('值3',值4); -- 可以同时添加两行数据
删除表中数据
delete from info where id = '1'; -- 删除id为1的那一行数据
delete from info; --删除表中的数据,结构不变
truncate info;-- 清空整张表
修改数据
update info set sex = '男',name = 'zhangsan' where id = 1; -- 更新多个字段的时候,用逗号隔开。
查看数据
基本查询语句
select *|<字段列表>
from <表1>,<表2>...
[where<表达式>]
[group by <group by definition>]
[having<expression>[{<operator><expression>}...]]
[order by <order by definition>]
[limit[offset,] <row count>];
或者:
select 字段1,字段2,...,字段n
from [表或视图]
where [查询条件];
单表查询
-
查询所有字段
select * from 表名; -
查询指定字段
select 字段名1,字段名2,...,字段名n from 表名; -
查询指定记录
在select语句中,通过where子句可以对数据进行过滤。select 字段名1,字段名2,...,字段名n from 表名 where 查询条件; -
带
in关键字的查询
in操作符用来查询满足指定范围内的条件的记录,使用in操作符,将所有检索条件用括号括起来,检索条件之间用逗号隔开,只要满足条件范围内的一个值即为匹配项。create table tb1(id int not null, name char(12) not null); insert into tb1 values(1,'zhangsan'),(2,'lisi'),(3,'wangwu'),(4,'qw'),(5,'er'); select * from tb1 where name in ('zhangsan','lisi');在
in关键字前面加上not即可使得查询的结果正好相反。 -
带
between and的范围查询
between and用来查询某个范围内的值,该操作符需要有两个参数,即范围的开始值和结束。如果字段值满足指定的范围查询条件,则这些记录被返回。create table tb1(id int not null, name char(12) not null); insert into tb1 values(1,'zhangsan'),(2,'lisi'),(3,'wangwu'),(4,'qw'),(5,'er'); select * from tb1 where id between 2 and 5;同样,在
between and关键字前面加上not即可使得查询的结果正好相反。 -
带
like的字符匹配查询
like关键字即是使用通配符来进行匹配查找。 -
通配符
通配符是一种在SQL的where条件子句中拥有特殊意思的字符,可以和like一起使用的通配符有%和_。
百分号通配符%,匹配任意长度的字符,甚至包括零字符。
下划线通配符_,一次只能匹配任意一个字符。select * from 表 where name like 'ale%' - ale开头的所有(多个字符串) select * from 表 where name like 'ale_' - ale开头的所有(一个字符) -
查询空值
空值不同于0,也不同于空字符串。空值一般表示数据未知、不适用或将在以后添加数据。
在select语句中使用is null子句,可以查询某字段内容为空记录。 -
带
and的多条件查询
and主要用于where子句中,用来链接两个甚至多个查询条件,表示所有的条件都需要满足才会返回值。 -
带
or的多条件查询
or也主要用于where子句中,用来链接两个甚至多个查询条件,表示所有的条件仅需满足其中之一项便会返回值。 -
查询结果不重复
在select语句中,使用distinct关键字来指示MySQL消除重复的记录。select distinct 字段名 from表名; -
对查询结果排序
用order by语句来对查询的结果进行排序。select * from 表 order by 列 asc - 根据 “列” 从小到大排列 select * from 表 order by 列 desc - 根据 “列” 从大到小排列 select * from 表 order by 列1 desc,列2 asc - 根据 “列1” 从大到小排列,如果相同则按列2从小到大排序 -
分组查询
在MySQL中使用group by来对数据进行分组,分组之后可以使用内置函数group_contact(字段),来把组内的字段内容进行拼接select num from 表 group by num select num,nid from 表 group by num,nid select num,nid from 表 where nid > 10 group by num,nid order by nid desc select num,nid,count(*),sum(score),max(score),min(score) from 表 group by num,nid select num from 表 group by num having max(id) > 10 --group by 必须在where之后,order by之前having关键字用来过滤数据,因为where不能和group by混用
with rollup关键字是在所有查询出的记录之后增加一条记录,该记录计算查询出的所有记录的总和,即统计记录数量。但是rollup和能够与group by同时使用,与order by不能同时使用。where 与having的区别
执行优先级从高到低:whrer > group by > having
where 发生在分组group by之前,因而where中可以有任意字段,但绝对不能使用聚合函数
having发生在分组group by之后,因而having中可以使用分组的字段,无法直接取到其他字段,可以使用聚合函数。 -
使用
limit限制查询结果的数量(网页分页)select * from 表 limit 5; -- 前5行 select * from 表 limit 4,5; -- 4表示起始位置,5表示步长 select * from 表 limit 5 offset 4 -- 从第4行开始的5行SQL语句关键字的执行顺序
from>where>group by>having>select>order by>limit
多表联合查询
- 连表
-- 无对应关系则不显示 select A.num, A.name, B.name from A,B Where A.nid = B.nid -- 内连接 产生笛卡尔积,无对应关系则不显示,注意条件语句要用‘on’ select A.num, A.name, B.name from A inner join B on A.nid = B.nid -- 左连接 A表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A left join B on A.nid = B.nid -- 右链接 B表所有显示,如果B中无对应关系,则值为null select A.num, A.name, B.name from A right join B on A.nid = B.nid - 组合
-- 组合,自动处理重合 select nickname from A union select name from B -- 组合,不处理重合 select nickname from A union all select name from B
子语句查询
子查询(嵌套查询):查多次,多个select
注意第一次的查询结果可以作为第二次查询的条件或者表名使用。
子查询中可以包含:IN、NOT IN、ANY、EXISTS和NOT EXSTS等关键字。还可以包含比较运算符:=、!=、>、<等。
-- 作为表名的使用
select * from (select * from person) as 表名;
外键
步长自增列
- MySQL:自增步长
-
基于会话级的。
在打开两个cmd时,两个cmd操作对互不影响。show session variables like 'auto_inc%'; -- 查看全局变量 set session auto_increment_increment = 2 -- 设置会话步长为2 set session auto_increment_offset = 2 -- 设置起始值 -
基于全局级别:已经改变,就全部都会改变
show globalvariables like 'auto_inc%'; -- 查看全局变量 set global auto_increment_increment = 2 -- 设置会话步长为2 set global auto_increment_offset = 2 -- 设置起始值 -
SQL server:自增步长是基于表级别的。
create table t5( nid int not null auto_increment, pid int not null, num int default null, primary key (nid,pid) )engine = innodb auto_increment = 4,步长 = 2 default charset = utf8 create table t6( nid int not null auto_increment, pid int not null, num int default null, primary key (nid,pid) )engine = innodb auto_increment = 4,步长 = 20 default charset = utf8
外键
基本概念
MySQL中“键”和“索引”的定义相同,所以外键和主键一样也是索引的一种。不同的是MySQL会自动为所有表的主键进行索引,但是外键字段必须由用户进行明确的索引。用于外键关系的字段必须在所有的参照表中进行明确地索引。 外键所在的表要在对应表创建之后再创建。
外键:foregin key在从表(子表)中指向主表(父表)主键的字段
从表(子表)含有外键的表
主表(父表)外键指向的表
外键的好处:可以使得两张表关联,保证数据的一致性和实现一些级联操作。
外键的定义语法:
[CONSTRAINT symbol] FOREIGN KEY [id] (index_col_name, …)
REFERENCES tbl_name (index_col_name, …)
[ON DELETE {RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT}]
[ON UPDATE {RESTRICT | CASCADE | SET NULL | NO ACTION | SET DEFAULT}]
该语法可以在 CREATE TABLE 和 ALTER TABLE 时使用,如果不指定CONSTRAINT symbol,MYSQL会自动生成一个名字。
例子:
create table department(
id bigint auto_increment primary key,
title char(15)
)engine = innodb default charset = utf8;
create table userinfo(
uid bigint auto_increment primary key,
name varchar(32),
department_id int,
constraint fk_user_depar foreign key("department_id") references department('id')
)engine = innodb default charset = utf8;
上述中,constraint关键字是设置外键的。设置外键的格式为
constraint 外键名 foreign key ('外键所在表的名字') references 对应表的名字('字段');
参考链接:https://blog.csdn.net/qq_34306360/article/details/79717682
索引
无索引: 从前往后一条一条查询
有索引:创建索引的本质,就是创建额外的文件(某种格式存储,查询的时候,先去格外的文件找,定好位置,然后再去原始表中直接查询。但是创建索引越多,会对硬盘也是有损耗。建立索引的目的: a.额外的文件保存特殊的数据结构 b.查询快,但是插入更新删除依然慢 c.创建索引之后,必须命中索引才能有效
hash索引和BTree索引
(1)hash类型的索引:查询单条快,范围查询慢
(2)btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它)
约束以及加速查询,使用:select * from 表名 where 索引条件;
-
普通索引
只能加速查询-- 第一种创建方式 create table userinfo( nid int not null auto_increment primary key, name varchar(32) not null, email varchar(32) not null index ix_name(name) -- 创建普通索引 ) -- 第二种创建方式(在创建表之后,向表中添加索引) create index 索引名字 on 表名(列名) -- 删除索引 drop index 索引名称 on 表名 -- 查看索引 show index from 表名 -
唯一索引
唯一索引会约束不能重复,加速查找 。主键不能重复,不能为空。create table userinfo( id int not null auto_increment primary key, name varchar(32) not null, email varchar(64) not null, unique index ix_name(name) ); -
组合索引
组合索引是将n个列组合成为一个索引,一般在频繁的同时使用n列来进行查询,如‘where name =‘zhangsan’ and email = ‘123@qq.com’’.
create index 索引名 on 表明(列名1,列名2);
- 覆盖索引
在索引文件中直接获取数据
例如:select name from t_data where name = ‘zhangsan’; - 索引合并
把多个单列索引一起使用
例如:select* from t_datawhere name=‘lisi’ and id = 123; - 联合索引
select * from t_data where name = ‘zhangsan’ and id = 123;
最左前缀匹配:
create index ix_name_email on userinfo(name,email); select * from userinfo where name = 'alex'; select * from userinfo where name = 'alex' and email='alex@oldBody'; select * from userinfo where email='alex@oldBody'; -- 会很慢,因为会先查询name字段如果使用组合索引如上,name和email组合索引之后,查询
(1)name和email —使用索引
(2)name —使用索引
(3)email —不使用索引
对于同时搜索n个条件时,组合索引的性能好于多个单列索引
******组合索引的性能>索引合并的性能*********
外键变种
-
一对多
用户表和部门表
用户:
1 张三 1
2 李四 1
3 王五 2
4 钱八 3部门:
1 服务
2 保安
3 公关create table department( id int not null auto_increment primary key, job varchar(50) not null )engine = innodb default charset = utf8; create table user_info( id int not null auto_increment primary key, name char(10) not null, job_id int not null, constraint fk_user_info_department foreign key (job_id) references department(id) )engine = innodb default charset = utf8; -
一对一
用户表和博客表
用户表:
1 张三
2 李四
3 王五
4 钱八
博客表:
FK() + 唯一
1 zhangsan 4
2 lisi 1
3 wangwu 3
4 qianba 2create table userinfo1( id int auto_increment primary key, name char(10), gender char(10), email varchar(64) )engine=innodb default charset=utf8; create table admin( id int not null auto_increment primary key, username varchar(64) not null, password VARCHAR(64) not null, user_id int not null, unique uq_u1 (user_id), CONSTRAINT fk_admin_u1 FOREIGN key (user_id) REFERENCES userinfo1(id) )engine=innodb default charset=utf8; -
多对多
示例:
用户表
主机表
用户主机关系表create table userinfo2( id int auto_increment primary key, name char(10), gender char(10), email varchar(64) )engine=innodb default charset=utf8; create table host( id int auto_increment primary key, hostname char(64) )engine=innodb default charset=utf8; create table user2host( id int auto_increment primary key, userid int not null, hostid int not null, unique uq_user_host (userid,hostid), CONSTRAINT fk_u2h_user FOREIGN key (userid) REFERENCES userinfo2(id), CONSTRAINT fk_u2h_host FOREIGN key (hostid) REFERENCES host(id) )engine=innodb default charset=utf8;














 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









