






什么是成本
MySQL中一条SQL语句的执行成本包含两个部分:
- I/O成本:从磁盘中加载数据(页)到内存的的过程中消耗的时间称为I/O成本。
- CPU成本:读取记录以及检测记录是否满足搜索条件、对结果集进行排序等操作,消耗的时间称为CPU成本。
MySQL默认规定读取一个页面的I/O成本是1.0,读取及检测一条记录的CPU成本是0.2。
单表查询的成本
MySQL Server接收到客户端发过来的SQL语句后,经历过查找缓存(如有)和语法解析后,MySQL的优化器会找出所有可能用来执行这条语句的方案,并对比这些方案后选择一条成本最低的方案,这个成本最低的方案就是执行计划,在此期间会访问少量的数据。然后才会跳用存储引擎的结构真正地执行查询。这个过程总结一下:
- 根据搜索条件,找出所有可能使用的索引。
- 计算全表扫描的代价。
- 计算使用不同索引执行查询的代价。
- 对比各种执行方案的代价,找出成本最低的方案。
SELECT
*
FROM
single_table
WHERE
key1 IN ('a', 'b', 'c')
AND key2 > 10
AND key2 < 1000
AND key3 > key2
AND key_part1 LIKE '%a%'
AND common_field LIKE 'a%';
找出所有可能使用的索引possible keys
根据搜索条件,只要索引列和常数使用=、<=>、IN、NOT IN、IS NULL、IS NOT NULL、>、<、>=、<=、BETWEEN、!=、<>或者LIKE,就会形成扫描区间,这些搜索条件都可能使用到索引,一个查询中可能使用到的索引统称为possible keys。
- key1 IN (‘a’, ‘b’, ‘c’)使用了二级索引idx_key1。
- key2 > 10 AND key2 < 1000使用了唯一二级索引uk_key2。
- key3 > key2未与常数进行比较,无法形成合适的扫描区间。
- key_part1 LIKE '%a%'使用LIKE时无法匹配开头,无法形成合适的扫描区间。
- common_field列未建立索引。
这条语句的possible keys为idx_key1、uk_key2。
计算全表扫描的代价
全表扫描的成本需要两个参数:
- 聚簇索引占用的页面数
- 该表中的记录数
通过SHOW TABLE STATUS语句查看表的统计信息
SHOW TABLE STATUS LIKE 'single_table';
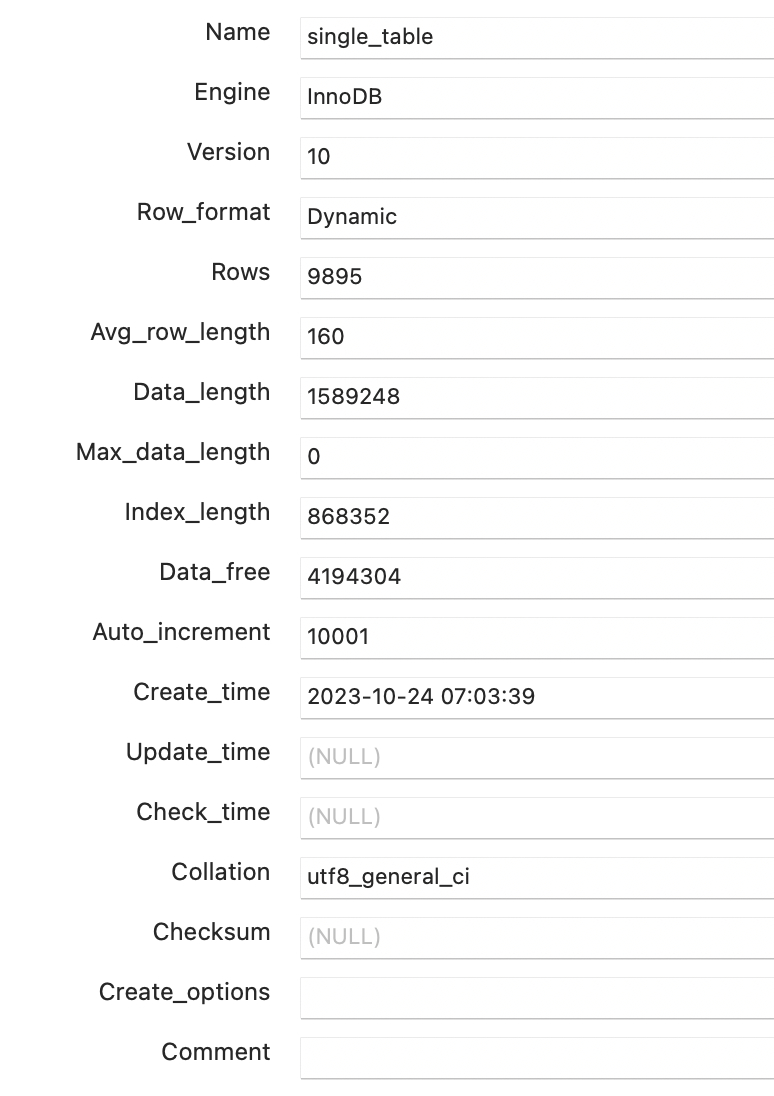
- Rows:对于InnoDB存储引擎,这个值表示表中记录条数的估值。
- Data_length:表示表占用的存储空间字节数,对于InnoDB来说,相当于聚簇索引占用的存储空间大小。
表的默认大小为16KB,可以推导出聚簇索引的页面数量:
I/O成本:页面数量为97,没加载一个页的成本为1.0,总共97 ✖️ 1.0 + 1.1 = 98.1,其中1.1为内部微调值。
CPU成本:读取一条记录的成本为0.2,总共9895 ✖️ 0.2 + 1.0 = 1939.6,其中1.0为内部微调值。
聚簇索引包含记录和目录项,只有叶子节点才是记录,但是计算成本时,直接将所有页面都计算进入。
计算使用不同索引的执行查询的代价
MySQL优化器优先分析使用唯一二级索引的成本,再分析使用普通二级索引的成本。
分析步骤:
- 扫描区间数量
- 需要回表的记录数
无论扫描区间的二级索引占用了多少页面,优化器都认为读取索引的一个扫描区间的I/O成本与读取一个页面的I/O成本是相同的,也就是几个扫描区间,就有几个1.0。
优化器需要计算二级索引的某个扫描区间包含多少条记录,才能知道有多少条记录需要执行回表。1️⃣根据其中一个访问条件找到满足条件的第一条记录,也称为区间最左记录;2️⃣根据条件从索引中找到最后一条记录,也称为区间最右记录;3️⃣如果去见最左记录和区间最右记录相隔不是很远(不大于10个页),就可以精确统计出满足条件的二级索引记录的条数。
如果这些页面相隔不太远,可以通过INDEX页中Page Header部分的PAGE_N_RECS属性知道该页有多少记录,遍历这些页,将PAGE_N_RECS相加即可。如果页面很多,就从区间最左记录向右读10个页面,计算每个页平均记录数量,然后乘以区间页数得出估算数值。父节点中每一个目录项记录对应的是一页,只需要找出多少个目录项,就知道区间有多少的页。此时可以知道区间有多少条记录,读取这些记录所需CPU成本为记录数✖️0.2。
根据这些记录的主键到聚簇索引进行回表,每次回表操作相当于访问一个页,也就是说二级索引扫描区间中有多少条记录,就需要进行多少次回表,也就是需要进行多少次页面I/O。I/O成本为二级索引得到的记录数✖️1.0。
回表后,再读取并判断其他条件,需要消耗CPU成本记录数量✖️0.2。
注意,实际运行的时候,第一次计算成本时,没有加上回表后聚簇索引记录的CPU成本,如果这个方案的执行成本较低,会重新计算一遍这个方案的成本,并把回表后聚簇索引的CPU成本加上。
当多个索引列使用AND连接,如果为单点区间可以使用索引Intersection合并;当使用OR连接,单点区间可以使用Union合并,若不是,可以使用Sort-Unino合并。
根据统计数据计算成本
当查询语句使用IN形成很多很多单点扫描区间
SELECT * FROM single_table WHERE key1 IN ('aaa', 'aab', 'aac', 'aad'...'zzz');
由于搜索条件涉及key1列,可以使用idx_key1索引,但是idx_key1不是唯一二级索引,没法确定一个单点区域有多少条索引记录。只能通过区间最左记录和区间最右记录之间的页面估算记录数量,这种通过直接访问索引对应的B+树来计算某个扫描区间内对应的索引记录条数的方式称为index dive。这也是为什么说在查询真正执行前,可能少量访问B+树中的数据。
但是如果IN语句中的参数非常多,这种index dive带来的性能消耗非常大。这时候可以使用索引统计数据(idnex statistics)来进行估算。MySQL提供系统变量eq_range_index_dive_limit,如果IN语句中的参数数量小于eq_range_index_dive_limit值,则使用index dive,若不小于eq_range_index_dive_limit,则使用索引统计数据。
SHOW VARIABLES LIKE 'eq_range_index_dive_limit'

MySQL除了为每个表维护一份统计数据,还会为 表中的每一个索引维护一份统计数据。
SHOW INDEX FROM single_table;

| 属性名 | 描述 |
|---|---|
| Table | 索引所属表名 |
| Non_unique | 是否唯一。0:是。1:否 |
| Key_name | 索引名称,其中聚簇索引的Key_name为PRIMARY |
| Seq_in_index | 该列在索引包含的列中的位置,从1开始计数。 |
| Column_name | 该列的名称 |
| Cardinality | 该列不重复值的数量。联合索引表示从索引列的第一个列开始,到当前列为止的组合不重复的数量。 |
| Sub_part | 表示该列为字符串或字节串类型的列建立索引的前缀字符或字节数,若对完整的列建立索引,则为NULL。 |
| Packed | 该列的压缩方式,NULL表示未压缩。 |
| Null | 是否允许存储NULL值 |
| Index_type | 该列所属的索引的类型,一般最常见的是BTREE。 |
在InnoDB存储引擎中,索引统计数据中的Cardinality是一个估值,并不精确。表统计数据的Rows也是。
根据索引统计数据中的Cardinality和表统计数据的Rows,可以计算出列中一个值平均重复多少次:
就可以估算出所有的单点扫描区间有多少记录了:
这种方法相对来说比index dive简单多了,但是不精确,适用于单点区间非常多的情况。
连接查询的成本
什么是条件过滤
查询驱动表后得到的记录条数称为驱动表的扇出,连接查询的成本分为两个部分:
- 单词查询驱动表的成本
- 多次查询被驱动表的成本(次数与驱动表的扇出决定)
显然, 驱动表的扇出越少,连查查询的成本越低。驱动表的扇出越多,成本成倍增加。
-
当驱动表使用全表查询时,扇出值就是驱动表中的记录数量,查询优化器根据表统计数据得到表的记录数量,并作为扇出值。
-
当驱动表使用二级索引查询的[计算方法](#index fanout),可以得出扫描区间内的记录数量,这个就是扇出值。
-
当驱动表无法使用索引时,只能姑且认为扇出值是全表记录数量。
-
当驱动表可以使用二级索引生成合适的扫描区间,但是搜索条件中包含不可以使用索引的列,那就需要在索引列形成的扫描区间的记录数量中,猜测有多少记录符合条件。
这个猜测过程称为条件过滤(Condition Filtering)。猜测过程可能会使用到索引,也可能会使用到统计数据。
两表连接成本分析
外连接的驱动表是固定的,只需要分别为驱动表和被驱动表选择成本最低的访问方法,就可以得到最好的方案。
内连接驱动表和被驱动可以互换,优化器需要分别考虑两种连接顺序的成本,然后选取成本更低的连接顺序,以及各个表最优访问方法作为最终的执行计划。
在连接查询中,最影响成本的是驱动表扇出值✖️单词访问被驱动表的成本,如果这两个值较高,成本则是成倍增长。优化重点就是:
- 尽量减少驱动表的扇出;
- 访问被驱动表的成本尽量低,尽量在被驱动表的连接列上建立索引,这样可以使用ref访问方法。如果是主键或唯一二级索引那就最好了。
多表连接成本分析
分析多表连接的成本,首先要考虑多表不同的连接顺序。MySQL在计算各种连接顺序的成本之前,会维护一个全局变量,就是当前最小的连接查询成本。在分析不同连接顺序的成本时,将保存当前已经分析连接顺序的成本最小值,如果在分析某个连接顺序的成本时,该成本已经超过当前最小的连接查询成本,那就停止分析该连接顺序了,如果分析得出该连接顺序的成本小于当前最小的连接查询成本,则将覆盖新的值。
MySQL还提供optimizer_search_depth系统变量,表示依次分析不同连接顺序成本的最大表的数量。如果连接表的个数小于该值,就会分析每一种连接顺序的成本;若大于,也只分析该值数量的表。该值越大,成本分析越精确,越容易生成好的执行计划,但是消耗的时间越长;否则得到的就不是很好的执行计划,但是节省了分析时间。
SHOW VARIABLES LIKE 'optimizer_search_depth';

启发式规则简介
根据以往经验指定的一些规则,凡事不满足这些规则的连接顺序压根就不分析。好处是减少分析不同连接顺序的数量,从而减少时间;不好是不能得到最好的执行计划。系统变量optimizer_prune_level控制是否使用启发式规则。
SHOW VARIABLES LIKE 'optimizer_prune_level';

成本常数
MySQL中一条语句在server层进行操作的成本对应的成本常数存储在mysql.server_cost表中,存储引起的操作对应的成本常数存储在mysql.engine_cost表中。
SELECT * FROM mysql.server_cost;
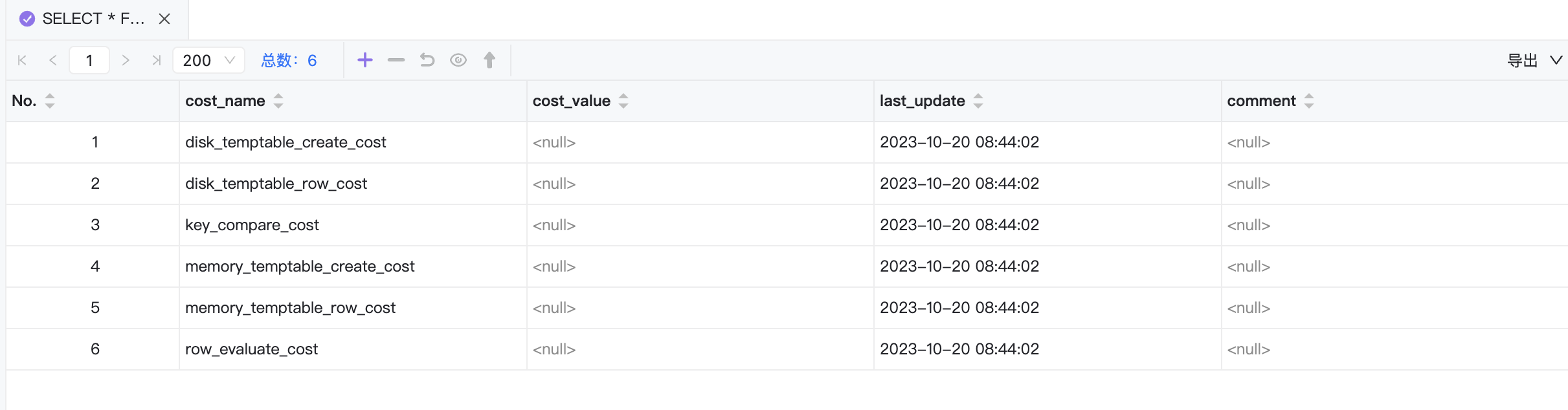
SELECT * FROM mysql.engine_cost;

阅读自《MySQL是怎样运行的》小孩子4919.















 953
953











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









