







一直疑惑的是redis在单线程环境下,怎么做到如此快的速度处理多个请求。查阅了很多资料,看到了大牛的一篇关于redis的I/O多路复用的博客,写的非常好,对I/O多路复用有了一定的了解。
redis的线程模型
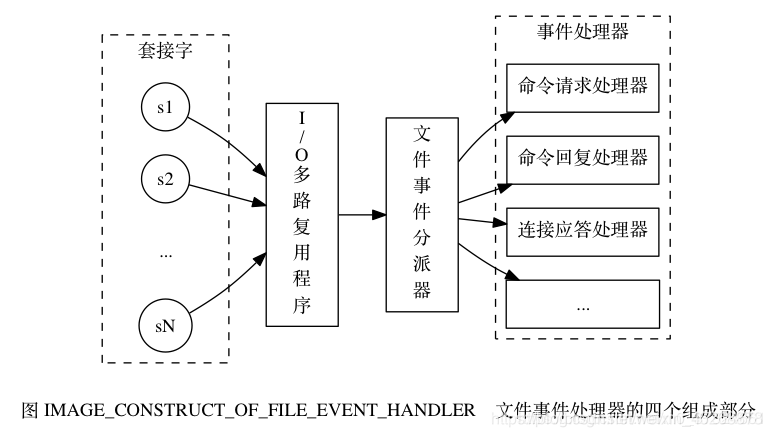
redis基于reactor模式开发了网络事件处理器,这个处理器叫做文件事件处理器,底层逻辑不是很了解。
redis采用epoll实现了非阻塞的I/O多路复用机制,相比与select的轮询次数的局限和无法定位出现数据的socket,以及poll的线程不安全性,epoll具有线程安全和快速定位socke的优点。
redis基于reactor模式开发了网络事件处理器,这个处理器叫做文件事件处理器
redis的持久化
redis的持久化有两种:
-
RDB快照模式。存储过去一个时刻数据的快照,以dump.rdb文件的形式保存在磁盘中。RDB模式可能丢失一段时间内的数据,但是在RDB在文件大小和重启恢复数据的速度上都优于AOF,是redis的默认持久化策略。RDB的两种save方式,一种是直接执行save,这时主线程是阻塞的,一直等待数据持久化完成;另外一种是bgsave,主线程Fock出一个子线程,子线程完成对数据的持久化。
-
AOF。可以通过设置appendfsync参数配置为always记录每一条写入操作,可以达到宕机下情况下数据一致性。但是AOF文件存在大小无限增长的可能性,因为命令的记录是增量的。AOF有一种优化机制rewrite,可对文件优化重压缩,去掉一些无用的命令。
redis的淘汰策略And删除机制
删除机制
- 定时删除 设置固定时间段扫描所有key,将过期的key删除,对cpu消耗比较大,不建议在高并发任务下使用
- 惰性删除 访问key的时候去检查key是否过期,过期删除,可能导致过期时间已到,内存还是居高不下
- 定时删除+惰性删除,定时检查一批key,不是全部的,删除过期key,同时检查被访问的key是否过期
淘汰策略
redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。redis 提供 6种数据淘汰策略通过maxmemory-policy设置策略:
- volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
- volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
- volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
- allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰
- allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
- no-enviction(驱逐):禁止驱逐数据
redis 确定驱逐某个键值对后,会删除这个数据并将这个数据变更消息发布到本地(AOF 持久化)和从机(主从连接)
淘汰策略使用场景:
- allkeys-lru: 如果我们的应用对缓存的访问符合幂律分布(也就是存在相对热点数据),或者我们不太清楚我们应用的缓存访问分布状况,我们可以选择allkeys-lru策略。
- allkeys-random: 如果我们的应用对于缓存key的访问概率相等,则可以使用这个策略。
- volatile-ttl: 这种策略使得我们可以向Redis提示哪些key更适合被eviction。
redis的通信协议RESP
- 请求
一条简单的set hello word经resp协议转化为:
*3
$3
get
$5
hello
$5
world
转为字符串为:*3\r\n$3\r\nge\r\nt$5\r\nhello\r\n$5\r\nworld - 响应
单行回复:回复的第一个字节是 “+”
错误信息:回复的第一个字节是 “-”
整形数字:回复的第一个字节是 “:”
多行字符串:回复的第一个字节是 “$”
数组:回复的第一个字节是 “*”
下面是一个基于socket实现的redis客户端:
public String call() throws IOException {
String formart = formart(command);
//close方法关闭Socket连接后,Socket对象所绑定的端口并不一定马上释放
//系统有时在Socket连接关闭才会再确认一下是否有因为延迟面未到达的数据包
//避免重启时,有时候的port already bind
Socket socket = new Socket();
socket.setReuseAddress(true);
socket.setKeepAlive(true);//保持TCP连接,不释放资源
socket.setTcpNoDelay(true);//立即发送数据,不合并数据包
socket.setSoLinger(true, 0);//强制关闭连接,不阻塞close(阻塞0s)
socket.connect(new InetSocketAddress(ip, port), 2000);
socket.setSoTimeout(2000);//读取数据阻塞超时时间2s(0是一直阻塞)
OutputStream outputStream = socket.getOutputStream();
InputStream inputStream = socket.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(inputStream, "utf-8"));
//认证
if (auth != null) {
String authFormat = formart(auth);
outputStream.write(authFormat.getBytes());
br.readLine();
}
outputStream.write(formart.getBytes());
//字符串返回,解析首行不能直接使用readline,会导致socket超时
int startChar = inputStream.read();
if (startChar == 36) {
String s = br.readLine();
long i = 0L;
try {
i = Long.parseLong(s);
} catch (NumberFormatException e) {
e.printStackTrace();
}
if (i > 0) {
return br.readLine();
}
//多行返回
} else if (startChar == 42) {
char read = (char) inputStream.read();
//读取一个字符,然后读取当前行所有字符,不能直接读取一行
int i = Integer.parseInt(read + "");
String s = br.readLine();
i = Integer.parseInt(i + s);
StringBuilder stringBuilder = new StringBuilder();
for (int j = 0; j < i * 2; j++) {
if (j % 2 == 1) {
stringBuilder.append(br.readLine() + "\r\n");
} else {
String s1 = br.readLine();
}
}
return stringBuilder.toString();
//整数返回
} else {
String s = br.readLine();
return s;
}
return null;
}
//解析redis协议
public static String formart(String command) {
String delSpaceString = command.replaceAll("\\s{1,}", " ");
StringBuilder stringBuilder = new StringBuilder();
String[] split = delSpaceString.split(" ");
stringBuilder.append("*" + split.length + "\r\n");
for (int i = 0; i < split.length; i++) {
stringBuilder.append("$" + split[i].length() + "\r\n");
stringBuilder.append(split[i] + "\r\n");
}
return stringBuilder.toString();
}
redis的几种数据类型
1、string
string类型的数据k,v最大长度为512M,取单个key的时间复杂度为O(1),取或删多个元素的复杂度为0(n)。
- 项目中用到做响应时间比较长的接口的缓存,分布式缓存的架构可以参考我的另一篇博客。
- 集群部署下的全局session
- 利用 incr 或者decr命令自增自检,做秒杀库存的余量把控。或者是全局性id
- setnx命令实现分布式锁。
2、list
list是一种基于链表的数据结构。list对首尾数据的操作时间复杂度为O(1);因为链表是有序的,所有list可以操作指定索引的值。
最近使用的N条记录:
- 第一步,通过lrem(key,count,value)删除key中所有与value相同的记录。
- lpush将记录推进首部。
- 设置key允许保留的长度ltrim保存N条记录
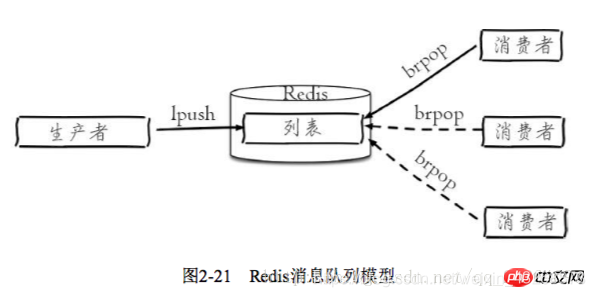
阻塞队列:
- brpop是阻塞的,会一直等待有数据
3、hash
Hash即哈希表,Redis的Hash和传统的哈希表一样,是一种field-value型的数据结构,可以理解成将HashMap搬入Redis。
Hash非常适合用于表现对象类型的数据,用Hash中的field对应对象的field即可。
Hash的优点包括:
- 可以实现二元查找,如"查找ID为1000的用户的年龄"
- 比起将整个对象序列化后作为String存储的方法,Hash能够有效地减少网络传输的消耗
- 当使用Hash维护一个集合时,提供了比List效率高得多的随机访问命令
与Hash相关的常用命令:
-
HSET:将key对应的Hash中的field设置为value。如果该Hash不存在,会自动创建一个。时间复杂度O(1)
-
HGET:返回指定Hash中field字段的值,时间复杂度O(1)
-
HMSET/HMGET:同HSET和HGET,可以批量操作同一个key下的多个field,时间复杂度:O(N),N为一次操作的field数量
-
HSETNX:同HSET,但如field已经存在,HSETNX不会进行任何操作,时间复杂度O(1)
-
HEXISTS:判断指定Hash中field是否存在,存在返回1,不存在返回0,时间复杂度O(1)
-
HDEL:删除指定Hash中的field(1个或多个),时间复杂度:O(N),N为操作的field数量
-
HINCRBY:同INCRBY命令,对指定Hash中的一个field进行INCRBY,时间复杂度O(1)
应谨慎使用的Hash相关命令: -
HGETALL:返回指定Hash中所有的field-value对。返回结果为数组,数组中field和value交替出现。时间复杂度O(N)
-
HKEYS/HVALS:返回指定Hash中所有的field/value,时间复杂度O(N)
上述几个命令都会对Hash进行完整遍历,Hash中的field数量与命令的耗时线性相关,对于尺寸不可预知的Hash,应严格避免使用上面三个命令,而改为使用HSCAN命令进行游标式的遍历,具体请见 https://redis.io/commands/scan
4、set
无序集合,且value不可重复。类似于java的set集合
- 可以用作全局去重
5、zset
有序且不重复集合,有序是因为每个对应的key有一个权重值
Sorted Set非常适合用于实现排名。
Sorted Set的主要命令:
- ZADD:向指定Sorted Set中添加1个或多个member,时间复杂度O(Mlog(N)),M为添加的member数量,N为Sorted Set中的member数量
- ZREM:从指定Sorted Set中删除1个或多个member,时间复杂度O(Mlog(N)),M为删除的member数量,N为Sorted Set中的member数量
- ZCOUNT:返回指定Sorted Set中指定score范围内的member数量,时间复杂度:O(log(N))
- ZCARD:返回指定Sorted Set中的member数量,时间复杂度O(1)
- ZSCORE:返回指定Sorted Set中指定member的score,时间复杂度O(1)
- ZRANK/ZREVRANK:返回指定member在Sorted Set中的排名,ZRANK返回按升序排序的排名,ZREVRANK则返回按降序排序的排名。时间复杂度O(log(N))
- ZINCRBY:同INCRBY,对指定Sorted Set中的指定member的score进行自增,时间复杂度O(log(N))
慎用的Sorted Set相关命令:
- ZRANGE/ZREVRANGE:返回指定Sorted Set中指定排名范围内的所有member,ZRANGE为按score升序排序,ZREVRANGE为按score降序排序,时间复杂度O(log(N)+M),M为本次返回的member数
- ZRANGEBYSCORE/ZREVRANGEBYSCORE:返回指定Sorted Set中指定score范围内的所有member,返回结果以升序/降序排序,min和max可以指定为-inf和+inf,代表返回所有的member。时间复杂度O(log(N)+M)
- ZREMRANGEBYRANK/ZREMRANGEBYSCORE:移除Sorted Set中指定排名范围/指定score范围内的所有member。时间复杂度O(log(N)+M)
上述几个命令,应尽量避免传递[0 -1]或[-inf +inf]这样的参数,来对Sorted Set做一次性的完整遍历,特别是在Sorted Set的尺寸不可预知的情况下。可以通过ZSCAN命令来进行游标式的遍历(具体请见 https://redis.io/commands/scan ),或通过LIMIT参数来限制返回member的数量(适用于ZRANGEBYSCORE和ZREVRANGEBYSCORE命令),以实现游标式的遍历。
redis的事务
redis支持事务,但是不支持事务的回滚。redis可以通过MULTI命令开启事务,本质是提交多个命令,顺序执行。通过EXEC命令执行。
利用WATCH和事务实现CAS:
watch key
if(exec(get key)==0){
exec(multi)
exec(incr key)
exec(exec)
}
- watch原理:当被监控的key发生修改时,事务被中断。
redis的一些常见问题
缓存穿透:
请求查询缓存为空,再查询数据库也为空。在高并发场景下,会产生大量的请求直接击中数据库,导致数据库故障。
解决方案:
- 请求到数据库也为空时,可以向数据库中写入一个为null的kv,并设置一个过期时间
- 第二种是通过布隆过滤器,将可能存在的访问先放在一个集合中,然后判断请求是否在允许的范围内,不存在的可以选择直接丢弃。
缓存雪崩:
缓存中的key同时过期,导致大量的请求直接击中数据库
解决方案:
- 可以设置key的随机过期时间
并发竞争
- 如果对顺序没有要求,且修改是简单的自增或自减可以使用incr命令
- 如果有顺序要求可以使用队列
- 使用乐观锁cas,使用watch监控,开启事务,当watch修改时,事务不执行,重试以上














 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









