






二分查找
二分查找(又称折半查找),仅适用于顺序表,且不适用于链表,只适用于数组、List等数组容器,因为二分查找要根据数组下标索引进行查找。
时间复杂度:, 空间复杂度:
(用于存储原始数组,并未开辟新的内存空间)
算法基本思想:
确定待查找数组中的左边界与右边界(通常为i = 0,j = 数组.length - 1),将待查找元素的值与数组中间元素(a[(i + j)/2])的值进行比较比较,若成功,则返回元素在数组中的下标(mid);若不等,则判断所查找元素与中间元素的大小关系,若待查比中间元素大,则更新查找范围的左边界i变为i = mid + 1,继续进行比较;若待查比中间元素小,则更新查找范围的右边界j为j = mid - 1,继续进行比较;如此反复,直至查找成功返回元素下标(mid),或未找到,退出while循环,返回-1.
实现代码:
在实现二分查找的代码之前,先看一下API(Arrays.binarySearch)是如何实现二分查找的!
Arrays.binarySearch源码如下:
public static int binarySearch(int[] a, int key) {
return binarySearch0(a, 0, a.length, key);
}
private static int binarySearch0(int[] a, int fromIndex, int toIndex,int key) {
int high = toIndex - 1;
int low = fromIndex;
while (low <= high) {
int mid = (low + high) >>> 1;
int midVal = a[mid];
if (midVal < key)
low = mid + 1;
else if (midVal > key)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found.
}值得注意的是在阅读源码后会发现Arrays.binarySearch在未找到的情况下返回值为-(low+1),并非大家经常看到的-1,这是为什么呢?
笔者认为这是Java API的健壮性,它不仅考虑到了未找到的情况,还考虑到了如果没找到则该值应该是在数组中的哪个位置,即将该元素插入到哪个位置使得原数组仍为有序状态,所以Arrays.binarySearch在未找到的情况下返回的时该元素应该在数组中的插入索引+1再取负数,即为:return -(low + 1),这样知道了索引后若后续有需要进行插入的情况,则直接执行数组插入操作即可。
问题又来了,直接返回待插入位置的负数就行,也能和查找成功的情况分开,为什么还要加1呢?其实这也是考虑到了一种特殊情况:“待插入位置为0”,若待插入位置为0,在不加1的情况下return -0(== return 0),会与查找到该元素并且索引为0的情况形成歧义,无法区分到底是找到该元素在数组中的位置并返回索引为0还是没有找到其应插入的位置为0,而先+1后再取负的情况则完美的解决了该情况。
测试代码如下:Arrays中二分查找应用(利用二分查找返回的待插入位置进行更新数组)
public static void binarySearch4() {
int[] a = {2, 7, 9};
int key = 5;
int i = Arrays.binarySearch(a, key);
System.out.println(i);
//-2 = - 插入点 - 1
//-2+1 = -插入点
//i<0:未找到,插入到应该插入的位置
if (i < 0) {
/*
* insertIndex为待查找元素在数组中的下标索引(若找到),或待查找元素在数组中按升序应
插入的位置+1取负即未-(low + 1)(若未找到)
* */
int insertIndex = Math.abs(i + 1);
int[] b = new int[a.length + 1]; //b为插入元素后新的数组
System.arraycopy(a, 0, b, 0, insertIndex);//将a[]中insertIndex之前的元素插入到b[]
中
System.out.print("将a[]中insertIndex之前的元素插入到b[]中:");
System.out.println(Arrays.toString(b));//b:[2,0,0,0]
b[insertIndex] = key;//将未找到的元素key插入到应插入到的位置中
System.out.print("将未找到的元素key插入到应插入a[]的位置中:");
System.out.println(Arrays.toString(b));//b:[2,5,0,0]
//将a[]中insertIndex之后的元素插入到b[]中
System.arraycopy(a, insertIndex, b, insertIndex + 1, a.length - insertIndex);
System.out.print("将a[]中insertIndex之后的元素插入到b[]中:");
System.out.println(Arrays.toString(b));//b:[2,5,7,9]
}
} 在了解了Java中自带的二分查找的源码及其应用后我们来看一下具体应该怎么自己写二分查找算法,共分为三个版本:
在了解了Java中自带的二分查找的源码及其应用后我们来看一下具体应该怎么自己写二分查找算法,共分为三个版本:
版本1:基础经典版(左闭右闭:查找范围包括左和右边界,边界元素也参与比较)
说明:该版本为平时大家所说的二分查找的示例经典代码,值得注意的地方是修改了mid=(i+j)/2表示范围超过Integer类的最大值导致变为负数问题,改为:mid = (i + j)>>> 1,通过无符号右移进行除二运算(自动向下取整),既能实现除二取中间下标的操作,也解决了整数值越界导致的变为负数的问题。
/*
* 二分查找基础版:左闭右闭版(左边界参与比较,右边界也参与比较)
* */
public static int binarySearch1(int a[], int key) { //a[]数组内元素必须为升序且不重复,key为待查找元素
int i = 0, j = a.length - 1; //设置初始头尾边界
while (i <= j) { //i<=j,区间内有未比较的元素
int mid = (i + j) / 2; //数组中当前待查找目标
//int mid = (i + j) >>> 1; //为了避免i+j存储的范围超过整数的最大值,导致mid变为负数,
//故采用无符号右移一位进行除二运算(自动向下取整)
if (key > a[mid]) { //实际查找目标在右边
i = mid + 1;
} else if (key < a[mid]) { //实际查找目标在左边
j = mid - 1;
} else { //找到
return mid;
}
}
//i>j退出循环,未找到
return -1;
}
/*
问题1:为什么是i<=j意味着区间内有未比较的元素,而不是i<j
答: i<=j则i,j它们指向的元素也会参与比较,没有等号判断条件则会只比较mid指向的元素
*/
/*
问题2:int mid = (i + j) / 2有没有问题?
答:有问题,当i = Interger.MaxValue/2,j = Interger.MaxValue时, (i + j) / 2会超过
Interger的表示范围导致mid变为负数,解决方案:mid = (i + j) >>> 1
*/版本2:基础经典版本的另一种实现方式(左闭右开:查找范围只包括左边界i,右边界j只是用来表明待查找的元素范围,无实际比较用途)
代码说明:在此代码中,j只是用来表示确定比较范围,每次指向的索引元素要么是不存在的元素(a[length])要么是指向已经比较过的元素(a[mid]),因此要将j = mid - 1改为j = mid。此外循环条件也要改为i < j,因为若写成i <= j会在查找不存在的元素时陷入死循环(因为j指向的索引元素不参与比较)。
/*
* 二分查找改动版:左闭右开版(左边界参与比较,右边界不参与比较)
* */
public static int binarySearch2(int[] a, int key) { //a[]数组内元素必须为升序且不重复,key为待查找元素
int i = 0, j = a.length; //改动1:j = a.length
while (i < j) { //改动2:i < j
int mid = (i + j) >>> 1;
if (key > a[mid]) {
i = mid + 1;
} else if (key < a[mid]) {
j = mid; //改动3:j = mid
} else {
return mid;
}
}
//i>=j退出循环,未找到
return -1;
}
/*
改动版代码说明:在此代码中,j只是用来表示确定比较范围,每次指向的索引元素要么是不存在的元素(a[length])
要么是指向已经比较过的元素(a[mid]),因此要将j = mid - 1改为j = mid。
此外循环条件也要改为i < j,因为若写成i <= j会在查找不存在的元素时陷入死循环(因为j指向
的索引元素不参与比较)
*/版本3:平衡版(语句执行频率平衡)(左开右开:左右边界只表示查找范围,实际不参与比较)
代码说明:i为搜索范围左边界,实际参与比较,j为搜索范围右边界,实际不参与比较。循环判断条件j - i > 1指搜索范围内的元素个数若大于1个则继续执行循环,直至搜索范围内元素只剩一个,此时退出循环,判断该元素是否为待查找元素key。
之所以称该版本是二分查找平衡版是因为当搜索右边不存在的元素时,即会执行if语句,也会执行else if语句,而搜索左边不存在的元素时,只会执行if语句,存在执行语句不平衡的问题,故进行了修改,将判断条件改为if和else,将key大于等于a[mid]的情况统一放在else中。
需要注意的地方:当key大于等于a[mid]时,i = mid而非i = mid + 1,因为若将i置为mid + 1则会越过待查找元素!
/*
* 二分查找平衡版(语句执行频率平衡)(左开右开:i和j只表示查找范围):解决了改进版本中因if-else if而导致的若待查找元素在右侧,会执行if和else if,而待查找元素在左侧,只执行if
* 的语句执行频率不均衡问题
* */
public static int binarySearch3(int a[], int key) { //a[]数组内元素必须为升序且不重复,key为待查找元素
int i = 0, j = a.length;
while (j - i > 1) { //j - i > 1表明待查找范围内的元素个数大于1
int mid = (i + j) >>> 1;
if (key < a[mid]) {
j = mid;
} else { //同时包含ket大于和等于a[mid]的情况
i = mid;
}
}
if (a[i] == key) { //判断范围内仅剩的一个元素是否为待查找元素
return i;
}
return -1;
}以上三个版本的二分查找由易到难,其中必须要掌握的是基础经典版,其他两个版本是在其基础上进行的健壮性代码完善,考虑了未找到时返回值如何处理及判断执行语句不平衡的问题。当然,这三个版本的代码也存在弊端,那就是其适用范围必须是数组内不能含有重复的元素,那么当在查找有序且元素有重复的数组时,如何找到查找到的第一个元素和最后一个元素呢?因此还需对上述代码进行修改,考虑在查找成功且元素有重复的情况下如何找到其第一次出现的位置和最后一次出现的位置。
情况一:查找成功且该元素有重复,返回其第一次出现最靠近左侧的索引
代码说明:查找有重复元素的数组与没有重复元素的数组的代码最大的不同在于当查找成功时,并非直接return mid,而是使用临时变量candiateIndex索引来暂时记录找到的元素位置,然后为了要找到重复元素第一次出现的位置,修改右边界j的值:j=mid-1,使其继续在左侧查找,直到找到最左侧的元素,返回其索引candiateIndex。candiateIndex初始值为-1,当未找到时,返回-1表明未找到。
/*
* 二分查找LeftMost基础版:在数组内查找待查询元素,若找到,则返回该元素第一次出现的索引位置;若未找到,则返回-1
* 数组内元素可重复!
*/
public static int binarySearchLeftMost(int a[], int key) {
int i = 0, j = a.length - 1;
int candiateIndex = -1; //候选索引,用于更新记录查找元素的索引位置
while (i <= j) {
int mid = (i + j) >>> 1;
//未找到情况下处理方法与基础版一样:更新左右查找边界
if (key > a[mid]) {
i = mid + 1;
} else if (key < a[mid]) {
j = mid - 1;
} else {
candiateIndex = mid; //查找成功,更新索引位置
j = mid - 1; //继续向左查找,直至找到该元素第一次出现的索引位置
}
}
return candiateIndex; //未找到则返回-1,找到则返回第一次出现的下标索引
}情况二:查找成功且该元素有重复,返回其最后一次出现最靠近右侧的索引
代码说明:整体思路与查找重复元素第一次出现的位置相同,不同点在于要查找最后一次出现最靠近右侧的索引,在查找成功时,不会更新右边界j的值,而是更新左边界i的值,使i=mid+1,继续在其右侧查找,并用candiateIndex记录重复元素的索引下标,返回其最后一次出现的位置。candiateIndex初始值为-1,当未找到时,返回-1表明未找到。
/*
* 二分查找LeftMost基础版:在数组内查找待查询元素,若找到,则返回该元素最后一次出现的索引位置;若未找到,则返回-1
* 数组内元素可重复!
* */
public static int binarySearchRightMost(int a[], int key) {
int i = 0, j = a.length - 1;
int candiateIndex = -1; //候选索引,用于更新记录查找元素的索引位置
while (i <= j) {
int mid = (i + j) >>> 1;
//未找到情况下处理方法与基础版一样:更新左右查找边界
if (key > a[mid]) {
i = mid + 1;
} else if (key < a[mid]) {
j = mid - 1;
} else {
candiateIndex = mid; //查找成功,更新索引位置
i = mid + 1; //继续向右查找,直至找到该元素最后一次出现的索引位置
}
}
return candiateIndex; //未找到则返回-1,找到则返回最后一次出现下标索引
}现在问题又来了:当未查找成功的时候,能否不直接返回-1,而是和前面的代码一样返回应该插入的位置,提高其健壮性。因此对上述情况一和二的代码再次进行修改,返回值不再用candiateIndex,而是直接返回i和i-1,返回i表明在查找有重复元素key第一次出现的位置时,若未找到,则返回大于该元素最靠左的元素下标;返回i-1表明在查找有重复元素key最后一次出现的位置时,若未找到,则返回小于该元素最靠近右侧的元素下标,解决了当未找到时只返回-1的情况。

情况一改进:在数组内查找待查询元素,若找到,则返回第一次最靠左侧出现的索引位置;若未找到,则返回大于该元素的最靠左边的元素索引位置,即返回>=key的最靠左索引。
/*
* 二分查找LeftMost进阶版:在数组内查找待查询元素,若找到,则返回第一次最靠左侧出现的索引位置;若未找到,则返回大于该元素的最靠左边的元素索引位置
* 数组内元素可重复!
* 返回>=key的最靠左索引
* */
public static int binarySearchLeftMost1(int a[], int key) {
int i = 0, j = a.length - 1;
while (i <= j) {
int mid = (i + j) >>> 1;
if (key > a[mid]) {
i = mid + 1;
} else { //key<=a[mid]时继续向左查找
j = mid - 1;
}
}
return i; //未找到则返回大于该元素最靠左元素下标索引,找到则返回第一次出现的下标索引
}情况二改进:在数组内查找待查询元素,若找到,则返回最后一次最靠右侧出现的索引位置;若未找到,则返回大于该元素的最靠右边的元素索引位置,即返回<=key的最靠右索引。
/*
* 二分查找LeftMost进阶版:在数组内查找待查询元素,若找到,则返回第一次最靠左侧出现的索引位置;若未找到,则返回大于该元素的最靠左边的元素索引位置
* 数组内元素可重复!
* 返回<=key的最靠右索引
* */
public static int binarySearchRightMost1(int a[], int key) {
int i = 0, j = a.length - 1;
while (i <= j) {
int mid = (i + j) >>> 1;
if (key < a[mid]) {
j = mid - 1;
} else { //key>=a[mid]时继续向右查找
i = mid + 1;
}
}
return i - 1; //未找到则返回小于该元素最靠右的元素下标索引,找到则返回最后一次出现的下标索引
}以上,在考虑了查找重复元素的情况及未找到时应返回的索引位置时,便对二分查找有了更深入的理解,便可进行应用,如查找排名、前任、后任、范围查找等情况。
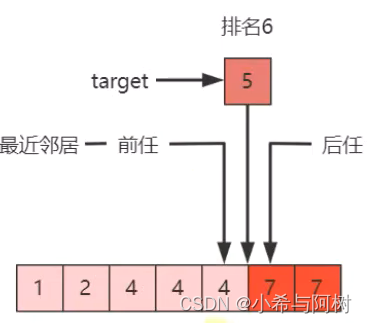
//进阶版二分查找的应用:找排名、前任、后任的位置
public void binarySearchLeftRightMostTest() {
int[] a = {1, 2, 4, 4, 4, 7, 7};
System.out.println("a[]数组内的元素为:" + Arrays.toString(a));
/*
查找排名:
LeftMost1(key)+1
*/
System.out.println("5的排名为:" + (binarySearchLeftMost1(a, 5) + 1));
System.out.println("4的排名为:" + (binarySearchLeftMost1(a, 4) + 1));
/*
查找前任索引:
LeftMost1(key)-1
*/
System.out.println("5的前任索引为:" + (binarySearchLeftMost1(a, 5) - 1));
/*
查找后任索引:
RightMost1(key)+1
*/
System.out.println("5的后任索引为:" + (binarySearchRightMost1(a, 5) + 1));
} 















 936
936











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









