









读取原始数据
首先导入pandas库
接着使用pandas库里面的read_csv方法来读取我们的文件,由于数据文件和程序文件是在统一目录下,因此无需使用绝对路径
import pandas as pd
data1 = pd.read_csv("data1.csv")
读取数据的前20行数据
这里我们使用的是read_csv方法中的nrows参数来获取原数据中的前多少行数据
df = pd.read_csv("data1.csv",nrows=20)
有些人就说了我记得使用header函数更好一些,我说一下header参数是负责定标题行的,而且header是read_csv方法中的一个参数,并不能用来获取指定数据的行数据,这部分人就属于记东西没记住然后张嘴就喷那种的,head方法是可以读取数据的前多少行数据的方法,倘若你这里不使用nrow参数,也可以用head方法,如下所示:
import pandas as pd
data1 = pd.read_csv("data1.csv")
data1.head(20)
所以说学东西一定要学准,header和head一个是参数负责标题的,一个是读取数据前多少行的方法,大家要区别开啊。
相对应的如果你想读取数据的后多少行数据的方法,即是tail方法
import pandas as pd
data1 = pd.read_csv("data1.csv")
data1.tail(20)
读取数据跳过前多少行
df1 = pd.read_csv("data1.csv",skiprows = 20)
这里有一个问题,因为首行是标题行,所以这里跳过的20行是包含标题行的,如图所示:
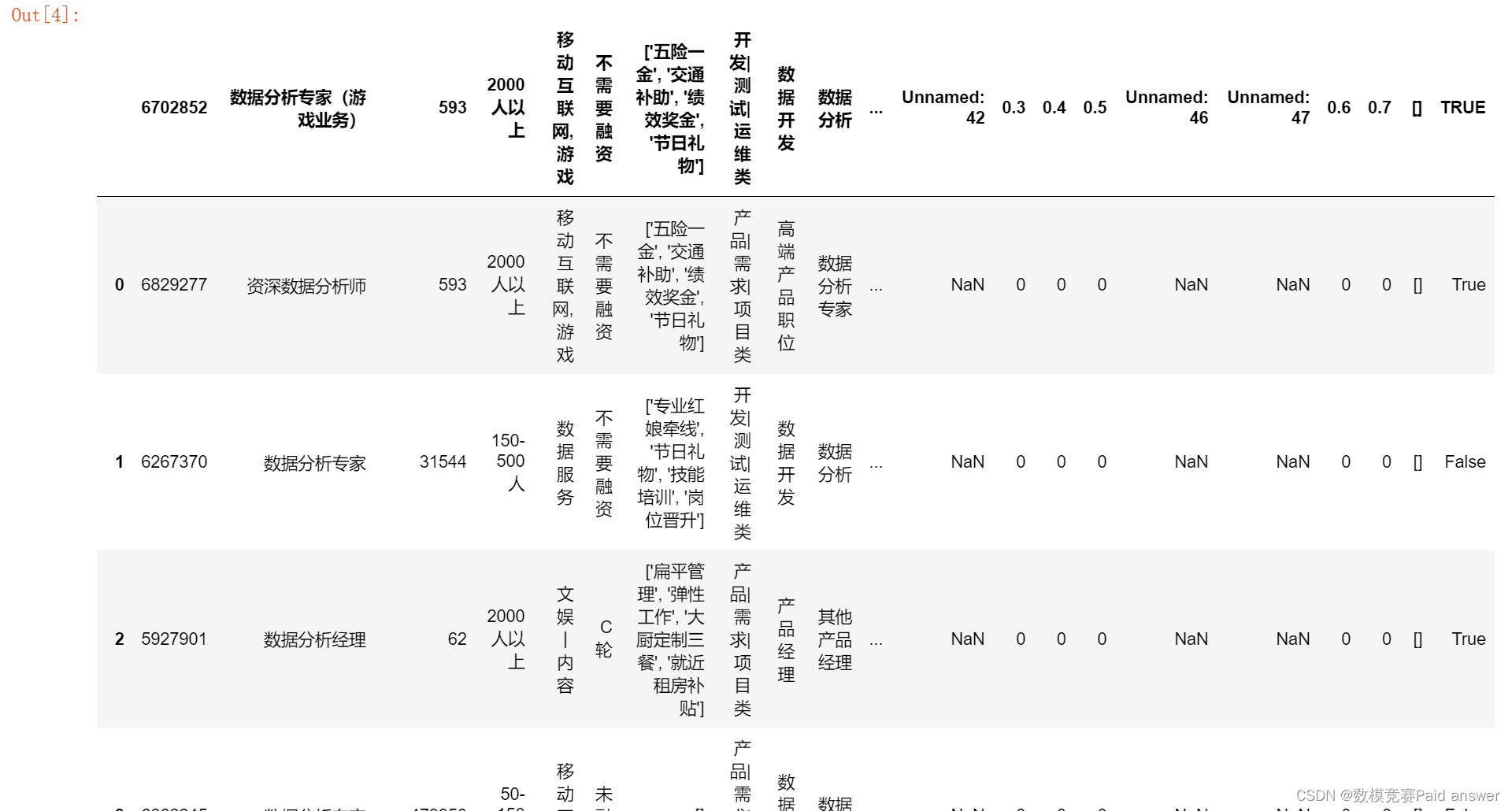
那么如何跳行是不含标题行的呢?我们知道,python读取是从0开始读取的,第一行不叫第一行叫第0行,也就是说我们这里需要跳过第0行从实际数据的第一行不含标题行开始读取,读取方式如下所示:
df2 = pd.read_csv("data1.csv",skiprows = [i for i in range(1,21)])
那有些大聪明就来了啊,说我不会用这个for循环,那怎么办呢?
这里教大聪明一个方法,比如说你要读取的是数据的除前20行以外的数据,就可以先删除掉前20行的数据然后进行常规读取数据。
data1.drop(data1.index[0:20],inplace=True)
还有就是那种喝完三鹿奶粉张嘴就来问,那那个index是什么意思呢?这种大聪明你连查都不查的,你这样,我再教你一个方法,你先手动在excel里删除前20行数据,怎么删呢?先张开双手,打开电脑,左键双击目标excel,然后鼠标左键摁住选择excel的前20行数据,如下图所示:
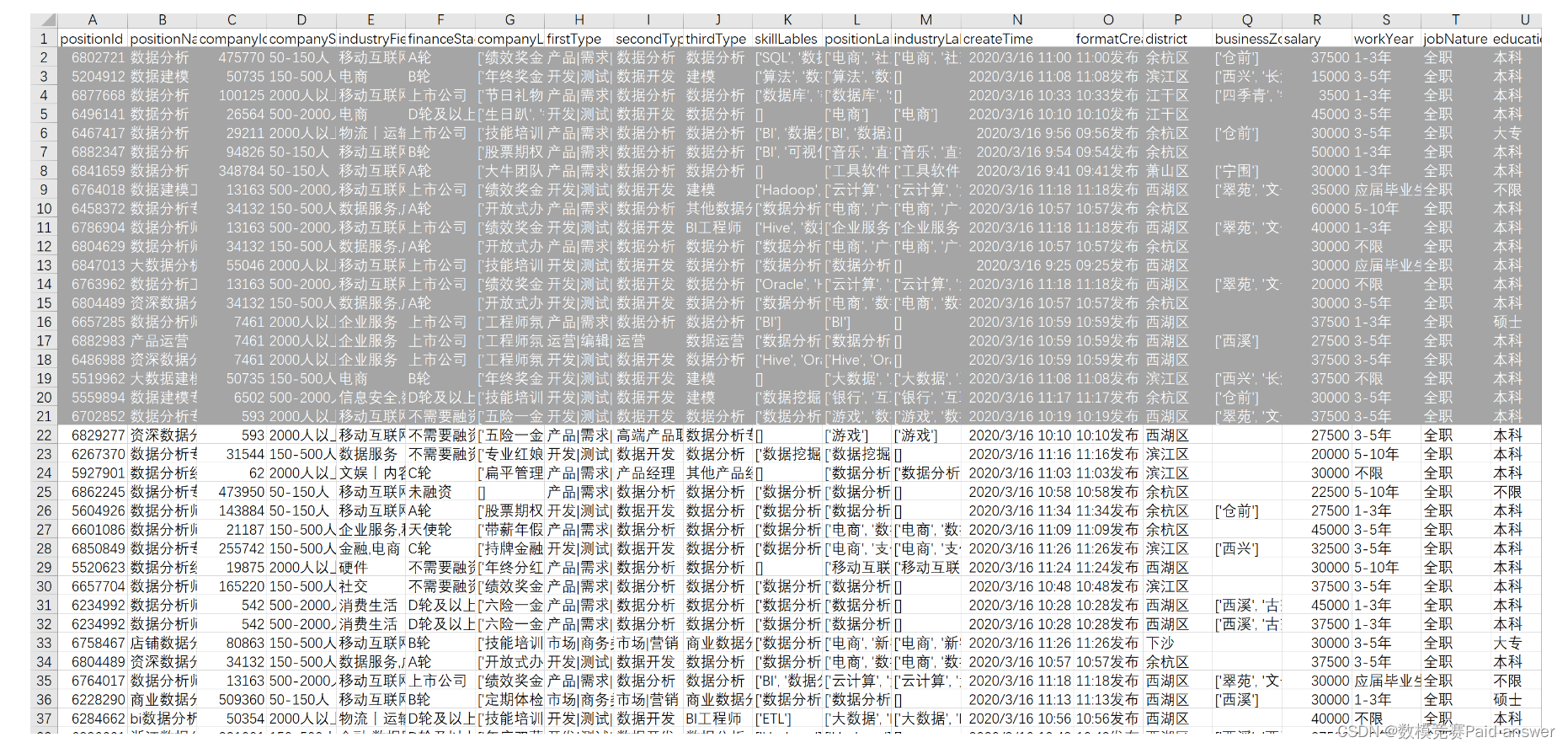
选中之后接下来右键点击删除,最后再使用最初的方式( data1=pd.read_csv(“data1.csv”) )读取数据就ok了。
这时候有大聪明不知道在哪弄的需求,又说了,那这个我要是只需要读取偶数行和奇数行怎么做啊
df3 = pd.read_csv('data1.csv', skiprows=lambda x: (x != 0) and not x % 2)
df4 = pd.read_csv('data1.csv', skiprows=lambda x: x % 2)
至此,常见excel数据使用python以行的方式按需读取简单操作我们暂时告一段落接下来我们来说常见excel数据使用python以列的方式按需读取。















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









