







电力窃漏电用户自动识别
数据预处理
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
利用拉格朗日插值法填补缺失值
删除是这一种缺失值的记录是最有效的方法。然而这种方法有很大局限性,他是以减少历史数据来换取数据的完备,这样会造成大量资源浪费。尤其是数据集本身包含记录很少,即使删除少量记录也会影响到分析结果的客观性和正确性。
一些模型可以将缺失值作为特殊值,对缺失值不敏感,允许直接在有缺失值的数据上建模。
函数插值法是一种填补缺失值的方法,包括拉格朗日插值法、牛顿插值法、Hermite插值,分段插值,样条插值法等等。


示例数据
| Value | Value | Value |
|---|---|---|
| 235.8333 | 324.0343 | 478.3231 |
| 236.2708 | 325.6379 | 515.4564 |
| 238.0521 | 328.0897 | 517.0909 |
| 235.9063 | 514.89 | |
| 236.7604 | 268.8324 | |
| 404.048 | 486.0912 | |
| 237.4167 | 391.2652 | 516.233 |
| 238.6563 | 380.8241 | |
| 237.6042 | 388.023 | 435.3508 |
| 238.0313 | 206.4349 | 487.675 |
| 235.0729 | ||
| 235.5313 | 400.0787 | 660.2347 |
| 411.2069 | 621.2346 | |
| 234.4688 | 395.2343 | 611.3408 |
| 235.5 | 344.8221 | 643.0863 |
| 235.6354 | 385.6432 | 642.3482 |
| 234.5521 | 401.6234 | |
| 236 | 409.6489 | 602.9347 |
| 235.2396 | 416.8795 | 589.3457 |
| 235.4896 | 556.3452 | |
| 236.9688 | 538.347 |
拉格朗日插值代码【Python】
#拉格朗日插值代码
import pandas as pd
from scipy.interpolate import lagrange #导入拉格朗日插值函数
inputfile = '../data/missing_data.xls'
outputfile = '../tmp/missing_data_processed.xls'
data = pd.read_excel(inputfile, header=None)
#自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
line = list(range(n-k, n)) + list(range(n+1, n+1+k))#取数列表,超出s索引值部分舍掉
newline =[]
for i in line:
if 0<=i<=len(s)-1:
newline.append(i)
y = s[newline] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果
#逐个元素判断是否需要插值
for i in data.columns:#遍历每一列数据
for j in range(len(data)):#遍历每一行
if (data[i].isnull())[j]: #如果为空即插值。
data[i][j] = ployinterp_column(data[i], j)
data.to_excel(outputfile, header=None, index=False) #输出结果
结果展示
| Value | Value | Value |
|---|---|---|
| 235.8333 | 324.0343 | 478.3231 |
| 236.2708 | 325.6379 | 515.4564 |
| 238.0521 | 328.0897 | 517.0909 |
| 235.9063 | 203.4621161 | 514.89 |
| 236.7604 | 268.8324 | 493.3525913 |
| 404.048 | 486.0912 | 486.0912 |
| 237.4167 | 391.2652 | 516.233 |
| 238.6563 | 380.8241 | 493.3423818 |
| 237.6042 | 388.023 | 435.3508 |
| 238.0313 | 206.4349 | 487.675 |
| 235.0729 | 237.3480723 | 609.1935644 |
| 235.5313 | 400.0787 | 660.2347 |
| 411.2069 | 621.2346 | 621.2346 |
| 234.4688 | 395.2343 | 611.3408 |
| 235.5 | 344.8221 | 643.0863 |
| 235.6354 | 385.6432 | 642.3482 |
| 234.5521 | 401.6234 | 618.1971982 |
| 236 | 409.6489 | 602.9347 |
| 235.2396 | 416.8795 | 589.3457 |
| 235.4896 | 420.7486 | 556.3452 |
| 236.9688 | 408.9632 | 538.347 |
专家样本
指标解释
电量趋势下降指标 线损指标 告警类指标 是否窃漏电
4 1 1 1
4 0 4 1
2 1 1 1
9 0 0 0
3 1 0 0
......
- 电量下降趋势:表明11天内的电量下降趋势,以5天为1个统计窗口期,取值范围0-11。
- 线损指标:考虑前后几天线损率的平均值,如果增长大于1%记作1,否则为0,取值范围0,1
- 告警类指标:与窃电相关的终端报警主要有电压缺相、电压断向、电流反极性等告警,计算发生终端报警次数的总和
简单可视化
电量下降趋势指标
data_3 = data.groupby(['电量趋势下降指标','是否窃漏电']).size()
data_3 = pd.DataFrame(data_3)
data_3 = data_3.reset_index()
sns.barplot(x = '电量趋势下降指标',y = data_3[0],data=data_3,hue = '是否窃漏电')

- 由上图可以看出,电量趋势下降指标,从4-5是分水岭,5以后是少数用户的表现,但窃漏电概率超过50%;
- 指标10,表示11天内用户用电逐天下降11天,基本可以确定是窃漏电;
- 11天内只有1天用电下降的用户不存在窃漏电。
线损指标
data_3 = data.groupby(['线损指标','是否窃漏电']).size()
data_3 = pd.DataFrame(data_3)
data_3 = data_3.reset_index()
sns.barplot(x = '线损指标',y = data_3[0],data=data_3,hue = '是否窃漏电')

- 线损指标为1的用户出现窃漏电的比例会明显高一些
告警类指标
data_3 = data.groupby(['告警类指标','是否窃漏电']).size()
data_3 = pd.DataFrame(data_3)
data_3 = data_3.reset_index()
sns.barplot(x = '告警类指标',y = data_3[0],data=data_3,hue = '是否窃漏电')

构建LM神经网络模型
from random import shuffle
datafile = '../data/model.xls'
data = pd.read_excel(datafile)
data = data.values
shuffle(data)
p = 0.8 #设置训练数据比例
train = data[:int(len(data)*p),:]
test = data[int(len(data)*p):,:]
#构建LM神经网络模型
from keras.models import Sequential #导入神经网络初始化函数
from keras.layers.core import Dense, Activation #导入神经网络层函数、激活函数
netfile = '../tmp/net.model' #构建的神经网络模型存储路径
net = Sequential() #建立神经网络
net.add(Dense(10,input_dim = 3)) #添加输入层(3节点)到隐藏层(10节点)的连接
net.add(Activation('relu')) #隐藏层使用relu激活函数
net.add(Dense(1,input_dim = 10)) #添加隐藏层(10节点)到输出层(1节点)的连接
net.add(Activation('sigmoid')) #输出层使用sigmoid激活函数
net.compile(loss = 'binary_crossentropy', optimizer = 'adam') #编译模型,使用adam方法求解
net.fit(train[:,:3], train[:,3], epochs=1000, batch_size=1) #训练模型,循环1000次
net.save_weights(netfile) #保存模型
predict_result = net.predict_classes(train[:,:3]).reshape(len(train)) #预测结果变形
#定义混淆矩阵绘图函数
def cm_plot(y, yp):
cm = confusion_matrix(y, yp) #混淆矩阵
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图,配色风格使用cm.Greens,更多风格请参考官网。
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt
cm_plot(train[:,3], predict_result).show() #显示混淆矩阵可视化结果
from sklearn.metrics import roc_curve #导入ROC曲线函数
predict_result = net.predict(test[:,:3]).reshape(len(test))
fpr, tpr, thresholds = roc_curve(test[:,3], predict_result, pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label = 'ROC of LM') #作出ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0,1.05) #边界范围
plt.xlim(0,1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果
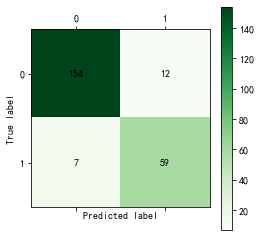

构建CART决策树模型
datafile = '../data/model.xls' #数据名
data = pd.read_excel(datafile) #读取数据,数据的前三列是特征,第四列是标签
data = data.values #将表格转换为矩阵
shuffle(data) #随机打乱数据
p = 0.8 #设置训练数据比例
train = data[:int(len(data)*p),:] #前80%为训练集
test = data[int(len(data)*p):,:] #后20%为测试集
#构建CART决策树模型
from sklearn.tree import DecisionTreeClassifier #导入决策树模型
treefile = '../tmp/tree.pkl' #模型输出名字
tree = DecisionTreeClassifier() #建立决策树模型
tree.fit(train[:,:3], train[:,3]) #训练
#保存模型
import joblib
joblib.dump(tree, treefile)
cm_plot(train[:,3], tree.predict(train[:,:3])).show() #显示混淆矩阵可视化结果
#注意到Scikit-Learn使用predict方法直接给出预测结果。
from sklearn.metrics import roc_curve #导入ROC曲线函数
fpr, tpr, thresholds = roc_curve(test[:,3], tree.predict_proba(test[:,:3])[:,1], pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label = 'ROC of CART', color = 'green') #作出ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0,1.05) #边界范围
plt.xlim(0,1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果


【汽车税务异常识别】
| 销售类型 | 销售模式 | 汽车销售平均毛利 | 维修毛利 | 企业维修收入占销售收入比重 | 增值税税负 | 存货周转率 | 成本费用利润率 | 整体理论税负 | 整体税负 | 控制数 | 办牌率 | 单台办牌手续费收入 | 代办保险率 | 保费返还率 | 输出 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 国产轿车 | 4S店 | 0.0635 | 0.3241 | 0.0879 | 0.0084 | 8.5241 | 0.0018 | 0.0166 | 0.0147 | 0.4000 | 0.02 | 0.7155 | 0.1500 | 正常 |
| 2 | 国产轿车 | 4S店 | 0.0520 | 0.2577 | 0.1394 | 0.0298 | 5.2782 | -0.0013 | 0.0032 | 0.0137 | 0.3307 | 0.02 | 0.2697 | 0.1367 | 正常 |
| 3 | 国产轿车 | 4S店 | 0.0173 | 0.1965 | 0.1025 | 0.0067 | 19.8356 | 0.0014 | 0.0080 | 0.0061 | 0.2256 | 0.02 | 0.2445 | 0.1301 | 正常 |
| 4 | 国产轿车 | 一级代理商 | 0.0501 | 0.0000 | 0.0000 | 0.0000 | 1.0673 | -0.3596 | -0.1673 | 0.0000 | 0.0000 | 0.00 | 0.0000 | 0.0000 | 异常 |
| 5 | 进口轿车 | 4S店 | 0.0564 | 0.0034 | 0.0066 | 0.0017 | 12.8470 | -0.0014 | 0.0123 | 0.0095 | 0.0039 | 0.08 | 0.0117 | 0.1872 | 正常 |
描述


- 没有缺失值

可视化
a = ['汽车销售平均毛利','维修毛利','企业维修收入占销售收入比重','增值税税负','存货周转率','成本费用利润率','整体理论税负','办牌率','单台办牌手续费收入','代办保险率','保费返还率']
f, axes = plt.subplots(nrows=11, ncols=1, figsize=(14, 31))
for i,j in zip(a,range(len(a))) :
sns.lineplot(y=i,x=data.index,data = data,hue='输出',ax=axes[j])
- 简单观察数据指标和税务异常的关系

import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_curve
data_3 = data.groupby(['销售类型','输出']).size()
data_3 = pd.DataFrame(data_3)
data_3 = data_3.reset_index()
sns.barplot(x = '销售类型',y = data_3[0],data=data_3,hue = '输出')

- 国产轿车、大客车、进口轿车是数量级比较大的异常车型
- 大客车、卡车及轻卡、商用货车是税务异常比例最大的3各车型
data_3 = data.groupby(['销售模式','输出']).size()
data_3 = pd.DataFrame(data_3)
data_3 = data_3.reset_index()
sns.barplot(x = '销售模式',y = data_3[0],data=data_3,hue = '输出')

- 一级代理商和二级及二级代理商出现税务异常的比例远高于其它渠道
LM神经网络
#定义混淆矩阵函数
def cm_plot(y, yp):
cm = confusion_matrix(y, yp) #混淆矩阵
plt.matshow(cm, cmap=plt.cm.Greens) #画混淆矩阵图
plt.colorbar() #颜色标签
for x in range(len(cm)): #数据标签
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
plt.ylabel('True label') #坐标轴标签
plt.xlabel('Predicted label') #坐标轴标签
return plt
data[u'销售类型'] = data[u'销售类型'].map({u'国产轿车': 1, u'进口轿车': 2, u'大客车': 3,u'卡车及轻卡': 4, u'微型面包车': 5, u'商用货车': 6,u'工程车': 7, u'其它': 8})
data[u'销售模式'] = data[u'销售模式'].map({u'4S店': 1, u'一级代理商': 2, u'二级及二级以下代理商': 3,u'多品牌经营店': 4, u'其它': 5})#将分类转化为数值
data = data.values#矩阵化
p = 0.8#训练比例
train_x, test_x, train_y, test_y = train_test_split(data[:, :14], data[:, 14], test_size=p) # 设置20%的数据为测试集,其余的为训练集
#LM神经网络
from keras.models import Sequential
from keras.layers.core import Dense,Activation
net = Sequential()
net.add(Dense(100,input_dim = 14)) #添加输入层(14节点)到隐藏层(100节点)的连接
net.add(Activation('relu')) #隐藏层使用relu激活函数
net.add(Dense(1,input_dim = 100)) #添加隐藏层(100节点)到输出层(1节点)的连接
net.add(Activation('sigmoid')) #输出层使用sigmoid激活函数
net.compile(loss = 'binary_crossentropy', optimizer = 'adam') #编译模型,使用adam方法求解
net.fit(train_x, train_y, epochs=1000, batch_size=10) #训练模型,循环1000次
net.save_weights('tmp/car_5.model') #保存模型
predict_result_train = net.predict_classes(train_x).reshape(len(train_x)) # 预测结果
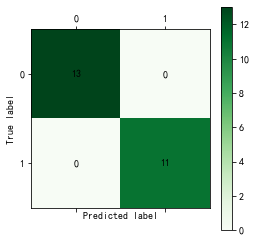
cm_plot(train_y, predict_result_train).show() # 显示混淆矩阵可视化图
#LM模型评估
predict_result = net.predict(test_x).reshape(len(test_x)) # 预测结果
fpr, tpr, thresholds = roc_curve(test_y, predict_result, pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label='ROC of LM') # 绘制ROC曲线
plt.xlabel('False Positive Rate') # 坐标轴标签
plt.ylabel('True POstive Rate')
plt.xlim(0, 1.05) # 设定边界范围
plt.ylim(0, 1.05)
plt.legend(loc=4) # 设定图例位置
plt.show() # 显示绘图结果
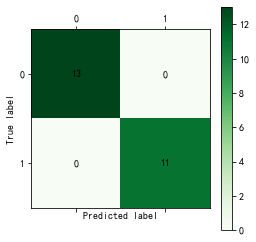

CART决策树
from sklearn.tree import DecisionTreeClassifier # 导入决策树模型
import joblib
tree = DecisionTreeClassifier(criterion='entropy', max_depth=3) # 建立决策树模型
tree.fit(train_x, train_y) # 训练模型
joblib.dump(tree, 'car_tree.pkl') # 保存模型
cm_plot(train_y, tree.predict(train_x)).show() # 显示混淆矩阵可视化图
# 绘制决策树模型的ROC曲线
fpr, tpr, thresholds = roc_curve(test_y, tree.predict_proba(test_x)[:,1], pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label='ROC of CHAR') # 绘制ROC曲线
plt.xlabel('False Positve Rate') # 坐标轴标签
plt.ylabel('True Postive Rate')
plt.xlim(0, 1.05) # 设定边界范围
plt.ylim(0, 1.05)
plt.legend(loc=4) # 设定图例位置
plt.show() # 显示绘图结果

数据下载
链接:https://pan.baidu.com/s/1Ikve1bRBt8w_7BtLBW2yzQ
提取码:u0jl
















 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











