







目录
以下摘自leetcode Top100精选题目-链表篇
相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal- 相交的起始节点的值。如果不存在相交节点,这一值为0listA- 第一个链表listB- 第二个链表skipA- 在listA中(从头节点开始)跳到交叉节点的节点数skipB- 在listB中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例: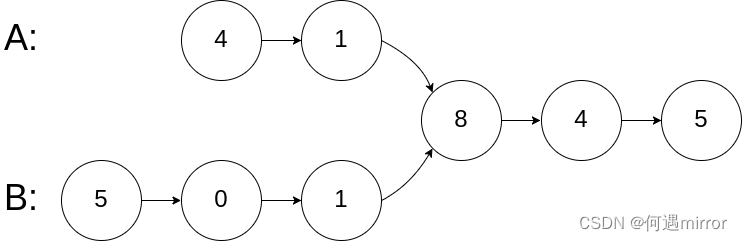
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。Solution:
计算两个链表的长度,然后将较长链表的头节点向后移动,使两个链表的尾部对齐。同时遍历两个链表,第一个相同的节点即为相交节点。
public class Solution {
public ListNode getIntersectionNode(ListNode headA, ListNode headB) {
if (headA == null || headB == null) {
return null;
}
ListNode pointerA = headA;
ListNode pointerB = headB;
// 计算两个链表的长度
int lengthA = getLength(pointerA);
int lengthB = getLength(pointerB);
// 调整两个指针,使它们从长度较长的链表的头部开始,且最终同时到达交点或同时到达null
if (lengthA > lengthB) {
for (int i = 0; i < lengthA - lengthB; i++) {
pointerA = pointerA.next;
}
} else {
for (int i = 0; i < lengthB - lengthA; i++) {
pointerB = pointerB.next;
}
}
// 同时遍历两个链表
while (pointerA != null && pointerB != null) {
if (pointerA == pointerB) {
return pointerA;
}
pointerA = pointerA.next;
pointerB = pointerB.next;
}
return null; // 没有相交
}
private int getLength(ListNode node) {
int length = 0;
while (node != null) {
length++;
node = node.next;
}
return length;
}
}先定义了两个指针pointerA和pointerB分别指向两个链表的头部。通过辅助方法getLength计算两个链表的长度,然后调整两个指针,从长度较长的链表的头部开始遍历,直到两个指针的距离(基于长度差异)被消除。同步移动两个指针,当相遇时即为相交节点,如果遍历结束都没有相遇,则说明两个链表不相交,返回null。
反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例:
输入:head = [1,2,3,4,5]
输出:[5,4,3,2,1]Solution:
public class ListNode {
int val;
ListNode next;
ListNode(int x) { val = x; }
}
public ListNode reverseList(ListNode head) {
ListNode prev = null; // 前一个节点
ListNode curr = head; // 当前节点
while (curr != null) {
ListNode nextTemp = curr.next; // 临时存储当前节点的下一个节点
curr.next = prev; // 将当前节点的next指向前一个节点,实现反转
prev = curr; // 前一个节点向后移动
curr = nextTemp; // 当前节点向后移动
}
return prev; // 当循环结束时,prev指向新的头节点
}先定义了链表节点类ListNode。reverseList函数接受链表的头节点head作为参数。在函数内部,使用三个指针prev、curr和nextTemp来帮助反转链表。prev初始时为null,curr初始化为head。在循环中,每次迭代都将curr的next指针指向前一个节点(即prev),然后将curr和prev向后移动一位。当curr走到末尾时,prev将成为新的头节点并被返回。
回文链表
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
示例:
输入:head = [1,2,2,1]
输出:trueSolution:
判断一个链表是否为回文链表,可以采用多种策略,如快慢指针找到中点、反转后半部分链表然后进行对比,或者利用栈等数据结构。这里提供一种较为直观且常用的方法:找到链表中点后,反转后半部分链表,然后逐个比较前后两部分的节点值。
public class ListNode {
int val;
ListNode next;
ListNode(int x) { val = x; }
}
public boolean isPalindrome(ListNode head) {
if (head == null || head.next == null) {
return true;
}
// 快慢指针找到中点
ListNode slow = head, fast = head;
while (fast.next != null && fast.next.next != null) {
slow = slow.next;
fast = fast.next.next;
}
// 反转后半部分链表
ListNode secondHalfHead = slow.next;
slow.next = null; // 断开前后两部分
ListNode prev = null;
while (secondHalfHead != null) {
ListNode nextTemp = secondHalfHead.next;
secondHalfHead.next = prev;
prev = secondHalfHead;
secondHalfHead = nextTemp;
}
// 比较前半部分和反转后的后半部分
ListNode p1 = head, p2 = prev;
while (p1 != null && p2 != null) {
if (p1.val != p2.val) {
return false;
}
p1 = p1.next;
p2 = p2.next;
}
return true;
} 先定义链表节点类ListNode。isPalindrome函数接收链表的头节点head作为输入。通过快慢指针技巧找到链表的中点,然后将链表从中点分成两部分,对后半部分进行反转。从前半部分和反转后的后半部分同时开始遍历,逐个比较节点值,如果所有对应节点值都相同,则链表是回文链表。
环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例:

输入:head = [3,2,0,-4], pos = 1
输出:true
解释:链表中有一个环,其尾部连接到第二个节点。Solution:
检测链表中是否存在环的经典方法是使用“快慢指针”(也称作“龟兔赛跑”算法)。快指针每次移动两个节点,慢指针每次移动一个节点。如果链表中存在环,快慢指针最终会在环中的某个节点相遇;如果链表中不存在环,快指针会先到达链表尾部。
public class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
next = null;
}
}
public class Solution {
public boolean hasCycle(ListNode head) {
if (head == null || head.next == null) {
return false;
}
ListNode slow = head;
ListNode fast = head.next;
while (slow != fast) {
// 快指针走到末尾或与慢指针相遇
if (fast == null || fast.next == null) {
return false;
}
slow = slow.next; // 慢指针走一步
fast = fast.next.next; // 快指针走两步
}
return true; // 快慢指针相遇,说明有环
}
}先定义了链表节点类ListNode,在Solution类中定义了hasCycle方法来检测链表中是否存在环。通过初始化两个指针,一个慢指针(slow)和一个快指针(fast),开始时分别指向链表的头节点和头节点的下一个节点。在循环中,如果快指针走到链表的末尾(即fast或fast.next为null),说明链表中没有环,直接返回false;否则,慢指针向前移动一步,快指针向前移动两步。当快慢指针相遇时,说明链表中存在环,返回true。
环形链表II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例:
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。Solution:
确认链表中是否存在环,然后计算环的长度,并找到环的入口。
示例:
输入:head = [3,2,0,-4], pos = 1
输出:返回索引为 1 的链表节点
解释:链表中有一个环,其尾部连接到第二个节点。Solution:
public class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
next = null;
}
}
public class Solution {
public ListNode detectCycle(ListNode head) {
if (head == null || head.next == null) {
return null;
}
ListNode slow = head;
ListNode fast = head;
// 第一步:判断链表是否有环
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
if (slow == fast) {
break;
}
}
// 如果没有环,直接返回null
if (slow != fast) {
return null;
}
// 第二步:计算环的长度
ListNode ptr = fast;
int cycleLength = 0;
do {
ptr = ptr.next;
cycleLength++;
} while (ptr != fast);
// 第三步:找到环的入口
slow = head;
fast = head;
for (int i = 0; i < cycleLength; i++) {
fast = fast.next;
}
while (slow != fast) {
slow = slow.next;
fast = fast.next;
}
return slow;
}
} 先定义链表节点类ListNode,在Solution类中定义了detectCycle方法来找出环的入口节点。使用快慢指针判断链表中是否存在环,如果快慢指针相遇,则说明有环。如果没有环,直接返回null。接着,计算环的长度,通过让快指针继续走一圈回到相遇点,计数循环次数。将一个指针置于链表头部,另一个指针在环内前进到与之相距环长度的位置,两个指针以相同速度前进,当相遇时,即为环的入口节点。
合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
输入:l1 = [1,2,4], l2 = [1,3,4]
输出:[1,1,2,3,4,4]Solution:
通过创建一个新的虚拟头节点,遍历两个链表,比较每个链表当前节点的值,将值较小的节点接到新链表上,移动相应的指针。这个过程一直持续到至少有一个链表被完全遍历完。如果还有剩余的链表未遍历完,直接将剩余的链表接到新链表的末尾即可。
public class ListNode {
int val;
ListNode next;
ListNode(int x) {
val = x;
next = null;
}
}
public class Solution {
public ListNode mergeTwoLists(ListNode l1, ListNode l2) {
ListNode dummy = new ListNode(-1); // 创建虚拟头节点
ListNode current = dummy; // 用于指向新链表的当前节点
while (l1 != null && l2 != null) {
if (l1.val < l2.val) {
current.next = l1;
l1 = l1.next;
} else {
current.next = l2;
l2 = l2.next;
}
current = current.next; // 移动当前节点指针
}
// 如果有一个链表已经遍历完,将另一个链表的剩余部分接到新链表的末尾
if (l1 != null) {
current.next = l1;
} else {
current.next = l2;
}
return dummy.next; // 返回新链表的头节点,跳过虚拟头节点
}
}先定义链表节点类ListNode,在Solution类中定义了mergeTwoLists方法来合并两个升序链表。通过使用虚拟头节点dummy,可以简化合并过程中的边界处理,返回dummy.next作为新链表的头节点。
两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例:
输入:l1 = [2,4,3], l2 = [5,6,4]
输出:[7,0,8]
解释:342 + 465 = 807.Solution:
遍历两个链表,逐位相加,并考虑进位。
public class ListNode {
int val;
ListNode next;
ListNode() {}
ListNode(int val) { this.val = val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}
public class Solution {
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
// 创建一个哑节点作为新链表的起点
ListNode dummy = new ListNode(0);
ListNode current = dummy; // 用于追踪新链表的当前节点
int carry = 0; // 进位标志
while (l1 != null || l2 != null || carry != 0) {
int sum = (l1 != null ? l1.val : 0) + (l2 != null ? l2.val : 0) + carry;
carry = sum / 10; // 计算进位
current.next = new ListNode(sum % 10); // 创建新节点并将其添加到链表中
current = current.next; // 移动到新链表的下一个位置
if (l1 != null) l1 = l1.next;
if (l2 != null) l2 = l2.next;
}
return dummy.next; // 返回新链表的头节点,跳过哑节点
}
}删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例:
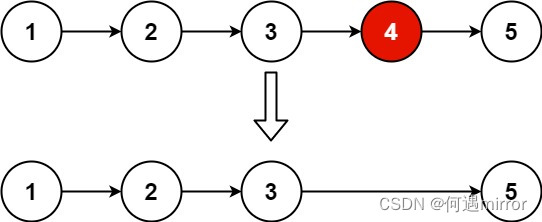
输入:head = [1,2,3,4,5], n = 2
输出:[1,2,3,5]Solution:
public class ListNode {
int val;
ListNode next;
ListNode() {}
ListNode(int val) { this.val = val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}
public class Solution {
public ListNode removeNthFromEnd(ListNode head, int n) {
ListNode dummy = new ListNode(0, head); // 创建一个哑节点,以便于处理头节点被删除的情况
ListNode first = dummy;
ListNode second = dummy;
// first指针先向前移动n+1步
for (int i = 0; i <= n; i++) {
first = first.next;
}
// 两个指针同时移动,直到first到达链表尾部
while (first != null) {
first = first.next;
second = second.next;
}
// 此时second指向了要删除节点的前一个节点
second.next = second.next.next;
return dummy.next; // 返回真正的头节点,跳过哑节点
}
}定义一个ListNode类来表示链表节点,并提供一个Solution类包含removeNthFromEnd方法来实现删除操作。通过使用哑节点,可以统一处理各种边界情况,包括删除头节点的情况。
两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例:
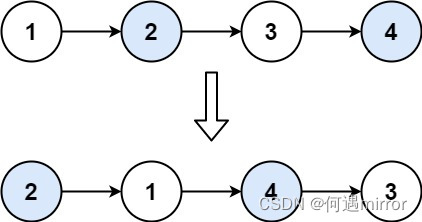
输入:head = [1,2,3,4]
输出:[2,1,4,3]Solution:
public class ListNode {
int val;
ListNode next;
ListNode() {}
ListNode(int val) { this.val = val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}
public class Solution {
public ListNode swapPairs(ListNode head) {
ListNode dummy = new ListNode(0, head); // 创建哑节点简化边界处理
ListNode prev = dummy; // 用于追踪当前待交换节点的前一个节点
while (prev.next != null && prev.next.next != null) {
ListNode first = prev.next; // 第一个待交换的节点
ListNode second = first.next; // 第二个待交换的节点
// 交换节点
first.next = second.next;
second.next = first;
prev.next = second;
// 移动prev指针,准备下一轮交换
prev = first;
}
return dummy.next; // 返回真正的头节点,忽略哑节点
}
} 先创建一个哑节点(dummy node),其next指针指向原链表的头节点,可以简化对头节点的处理。使用一个prev指针来追踪当前待交换节点对的前一个节点。在循环中,找到两个相邻的节点,交换它们的位置,并更新prev指针到交换后的新位置,继续向后遍历直至无法再进行交换。返回dummy.next作为新链表的头节点。
K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例:
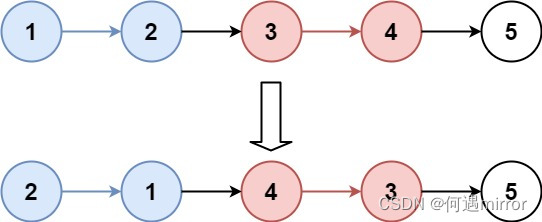
输入:head = [1,2,3,4,5], k = 2
输出:[2,1,4,3,5]Solution:
class Solution {
public ListNode reverseKGroup(ListNode head, int k) {
ListNode hair = new ListNode(0);
hair.next = head;
ListNode pre = hair;
while (head != null) {
ListNode tail = pre;
// 查看剩余部分长度是否大于等于 k
for (int i = 0; i < k; ++i) {
tail = tail.next;
if (tail == null) {
return hair.next;
}
}
ListNode nex = tail.next;
ListNode[] reverse = myReverse(head, tail);
head = reverse[0];
tail = reverse[1];
// 把子链表重新接回原链表
pre.next = head;
tail.next = nex;
pre = tail;
head = tail.next;
}
return hair.next;
}
public ListNode[] myReverse(ListNode head, ListNode tail) {
ListNode prev = tail.next;
ListNode p = head;
while (prev != tail) {
ListNode nex = p.next;
p.next = prev;
prev = p;
p = nex;
}
return new ListNode[]{tail, head};
}
}
随机链表的复制
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例:
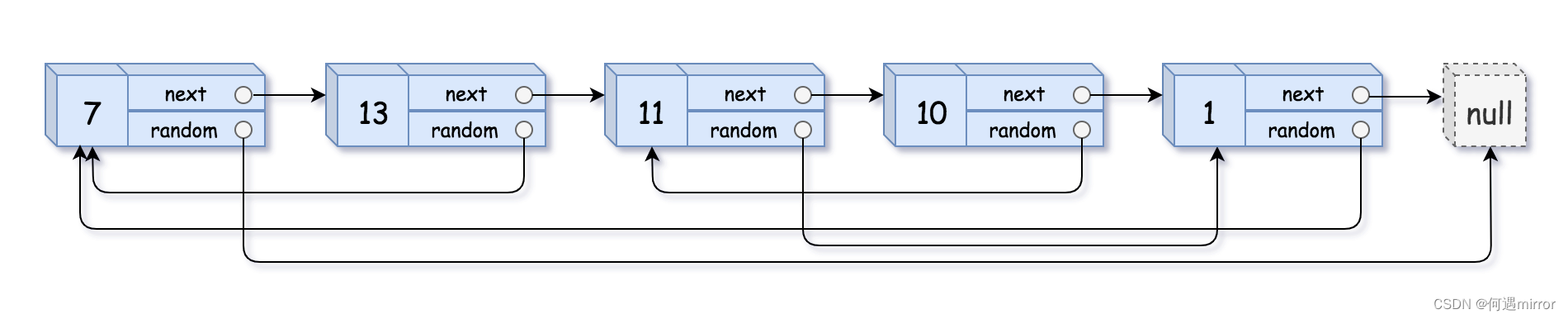
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]Solution:
可以采用原地复制的方法,即在原有的每个节点旁边创建一个具有相同值的新节点,然后调整新节点的next和random指针。
public class Node {
int val;
Node next;
Node random;
public Node(int val) {
this.val = val;
this.next = null;
this.random = null;
}
}
public class Solution {
public Node copyRandomList(Node head) {
if (head == null) {
return null;
}
// 第一步:复制每个节点,并将其插入到原节点的下一个位置
Node current = head;
while (current != null) {
Node newNode = new Node(current.val);
newNode.next = current.next;
current.next = newNode;
current = newNode.next;
}
// 第二步:设置复制节点的random指针
current = head;
while (current != null) {
if (current.random != null) {
current.next.random = current.random.next;
}
current = current.next.next;
}
// 第三步:拆分原链表和复制链表
Node oldList = head;
Node newList = head.next;
Node newHead = newList;
while (oldList != null) {
oldList.next = oldList.next.next;
if (oldList.next != null) {
newList.next = newList.next.next;
}
oldList = oldList.next;
newList = newList.next;
}
return newHead;
}
}在原链表每个节点旁边创建一个值相同的新节点,正确设置新节点的random指针,将原链表和复制链表分离。
排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例:
输入:head = [4,2,1,3]
输出:[1,2,3,4]Solution:
public class ListNode {
int val;
ListNode next;
ListNode() {}
ListNode(int val) { this.val = val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}
public class Solution {
public ListNode sortList(ListNode head) {
if (head == null || head.next == null) {
return head;
}
// 使用快慢指针找中点,对链表进行分割
ListNode slow = head, fast = head.next;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
ListNode mid = slow.next; // 中点
slow.next = null; // 断开链表
// 递归排序左右两半
ListNode left = sortList(head);
ListNode right = sortList(mid);
// 合并两个有序链表
return merge(left, right);
}
// 合并两个有序链表的函数
private ListNode merge(ListNode l1, ListNode l2) {
ListNode dummy = new ListNode(0);
ListNode tail = dummy;
while (l1 != null && l2 != null) {
if (l1.val < l2.val) {
tail.next = l1;
l1 = l1.next;
} else {
tail.next = l2;
l2 = l2.next;
}
tail = tail.next;
}
// 处理剩余部分
if (l1 != null) {
tail.next = l1;
} else if (l2 != null) {
tail.next = l2;
}
return dummy.next;
}
}先定义链表节点类ListNode,在Solution类中提供了排序链表的主要逻辑。sortList方法采用归并排序策略,将链表分成大致相等的两部分(通过快慢指针找到中点),对这两部分递归地进行排序,通过merge方法将两个已排序的链表合并成一个有序链表。
合并 K 个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例:
输入:lists = [[1,4,5],[1,3,4],[2,6]]
输出:[1,1,2,3,4,4,5,6]
解释:链表数组如下:
[
1->4->5,
1->3->4,
2->6
]
将它们合并到一个有序链表中得到。
1->1->2->3->4->4->5->6Solution:
合并K个升序链表的问题可以通过优先队列(最小堆)高效解决。
import java.util.*;
class ListNode {
int val;
ListNode next;
ListNode() {}
ListNode(int val) { this.val = val; }
ListNode(int val, ListNode next) { this.val = val; this.next = next; }
}
public class Solution {
public ListNode mergeKLists(ListNode[] lists) {
PriorityQueue<ListNode> minHeap = new PriorityQueue<>((a, b) -> a.val - b.val);
// 将所有非空链表的头节点加入最小堆
for (ListNode node : lists) {
if (node != null) {
minHeap.offer(node);
}
}
ListNode dummy = new ListNode(0); // 创建哑节点作为合并链表的起点
ListNode tail = dummy; // 用于连接新节点
while (!minHeap.isEmpty()) {
// 弹出堆顶元素,即当前最小的节点
ListNode smallestNode = minHeap.poll();
tail.next = smallestNode;
tail = tail.next;
// 如果弹出节点的下一个节点非空,将其加入堆中
if (smallestNode.next != null) {
minHeap.offer(smallestNode.next);
}
}
return dummy.next; // 返回合并后链表的头节点,忽略哑节点
}
}先将所有链表的头节点(如果存在的话)放入一个最小堆中。不断从堆中取出当前最小值的节点,将其添加到结果链表中,并检查该节点的下一个节点是否为空,如果不为空,则将下一个节点加入堆中。重复此过程,直到堆为空,此时所有链表已完全合并。
LRU 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
输入
["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
提示:
1 <= capacity <= 3000
0 <= key <= 10000
0 <= value <= 105
最多调用 2 * 105 次 get 和 putSolution:
可以使用哈希表(HashMap)结合双向链表来达到O(1)的平均时间复杂度。双向链表用于按访问顺序存储键值对,而哈希表用于快速查找键对应的节点。当缓存满时,可以从链表头部移除最久未使用的项。
public class LRUCache {
class DLinkedNode {
int key;
int value;
DLinkedNode prev;
DLinkedNode next;
public DLinkedNode() {}
public DLinkedNode(int _key, int _value) {key = _key; value = _value;}
}
private Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
private int size;
private int capacity;
private DLinkedNode head, tail;
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, value);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}
else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.value = value;
moveToHead(node);
}
}
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}
先定义一个内部类Node来表示链表中的节点,包含键、值以及前后指针。LRUCache类中维护了一个容量capacity、一个哈希表cache用于存储键到节点的映射,以及两个指向链表头部和尾部的指针。get方法查找键对应的值,并将访问的节点移到链表尾部。put方法插入或更新键值对,并在必要时移除最久未使用的项以保持容量限制。removeNode和appendToTail方法分别用于从链表中移除节点和将节点添加到链表尾部。
















 3144
3144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











