



 本文记录了作者在本地调试Spark任务时遇到的挑战,包括Driver IP配置、序列化问题(因Scala版本不匹配)、读取本地文件失败、UDF函数加载、Hive连接和SpringBoot集成中的问题,以及如何逐一解决这些问题的过程。
本文记录了作者在本地调试Spark任务时遇到的挑战,包括Driver IP配置、序列化问题(因Scala版本不匹配)、读取本地文件失败、UDF函数加载、Hive连接和SpringBoot集成中的问题,以及如何逐一解决这些问题的过程。
在平时的 Spark 开发中,若要将代码提交到 Spark 集群中,就必须打包,然后上传。这样非常繁琐,不方便调试,所以想着在本地调试将任务提交上Spark集群,记录一下连条过程遇到的问题。
正确配置
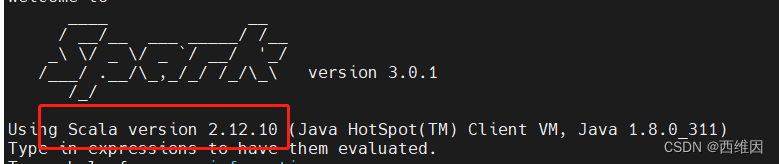
集群Scala版本:2.12.10
Spark集群版本:3.0.1
Pom文件:
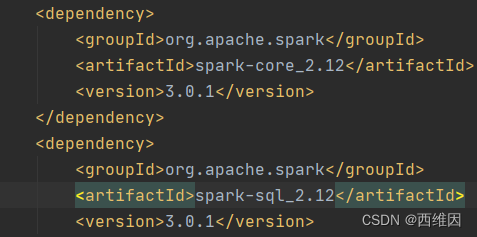
这里导入的Scala版本的Spark版本必须与集群一致,本地环境配置的Scala版本也必须和集群一致,可以启动spark-shell查看scala的版本。
问题
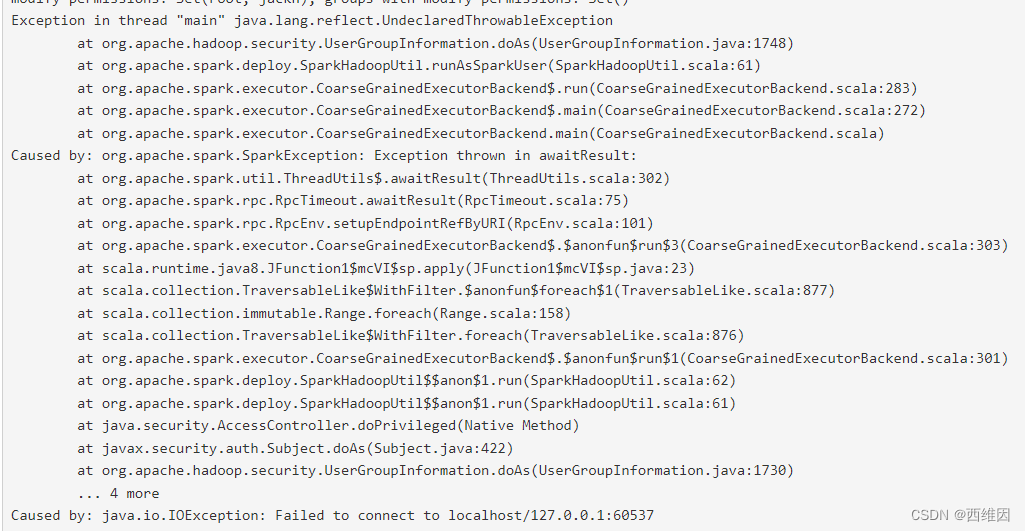
问题一:一开始遇到问题的是SparkSession提交任务到集群时,Driver启动在本地,想着把Driver启动到虚拟机的集群上面,但是conf设置Driver的IP地址、包括地址映射主机名都没有成功,Driver还是只能指定本机的IP地址(与Spark集群同一网段的IP)启动在本地进程上。
问题截图:
问题二:解决完问题一的Driver启动位置问题后,又遇到一个关于序列化的问题(serialVersionUID)
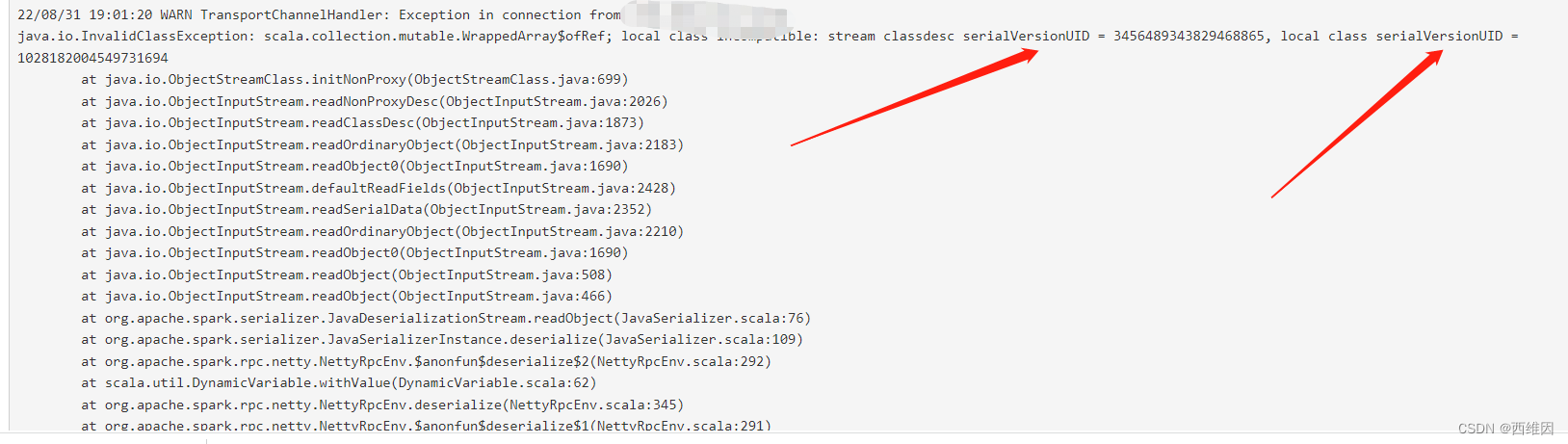
一开始在CDSN上找问题,在类里边直接写死了一个serialVersionUID,但是无效
思来想去以为是本地环境的JDK和集群依赖的JDK不一致,导致序列化方式不一致,所以Driver序列化下发资源文件到Worker手里时,Worker无法反序列化。
然后想着还是从Driver入手,把Driver运行在集群上应该没什么问题,结果就是换不了Driver执行的IP
最后发现是Spark集群依赖的Scala版本和我本地的Scala版本不一致。。。。
集群是2.12.10,而我的是2.12.16。。。
更改本地的Scala版本后,提交任务正常。。SparkSession终于走到了读取数据源的那一步
问题三:试着去读取一份Json文件(放在本地环境),但是SparkSession一直找不到这个文件,报错FileNotFound,然后我在服务器上启动了本地线程模式的Spark集群读取Json文件,读取没问题。然后切换成Standalone集群模式启动读取本地的Json文件,蛤蛤读不了。最后将文件路径替换成Hdfs的路径,把Json文件放到Hdfs上面,读取成功,解决。
最后附上Connection测试代码:
SparkConf sparkConf = new SparkConf()
.setMaster("spark://ip:7077") //master运行的主机端口
.setAppName("JavaSpark")
.set("spark.driver.host", "本地ip"); //drivefr运行的本地IP,端口随机分配
SparkSession spark = SparkSession.builder()
.config(sparkConf)
.getOrCreate();
Dataset<Row> json = spark.read().format("json")
.json("hdfs://namenode:8020/user.json");
json.show();
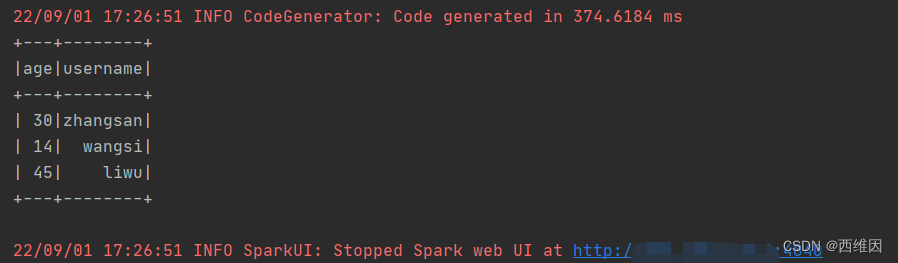
spark.close();成功结果:
后续问题
1、使用UDF函数报错
在使用UDF函数时,报了个序列化的错误。
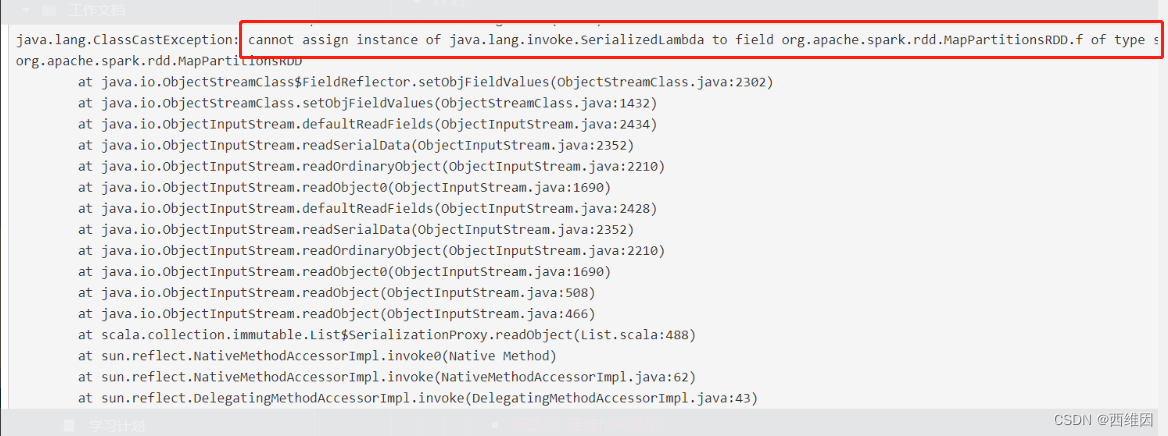
需要指定Jar包路径才能正常加载函数,经测试,在本地调试需要把Jar包打到Hdfs上。打包运行则可以指定在本地。
两种方式都需要上传,所以测试UDF函数时可以先用 local[*] 模式测试,调试完再上传。这样应该会方便点。
2、Standalone-Cluster模式下读取不到数据
集群模式默认读取的还是Hdfs,但是还是需要指定hdfs文件系统,否则程序会读本地文件系统,并且还读不到数据。
3、连条Hive
3.1、hadoop_home not found
有报这个错误是因为导入的依赖与Hadoop版本不一致。
3.2、SparkSQL与Hive版本兼容问题
通过SparkSession去连条需要加入两条依赖,指定元数据服务端口还有数据仓库位置。
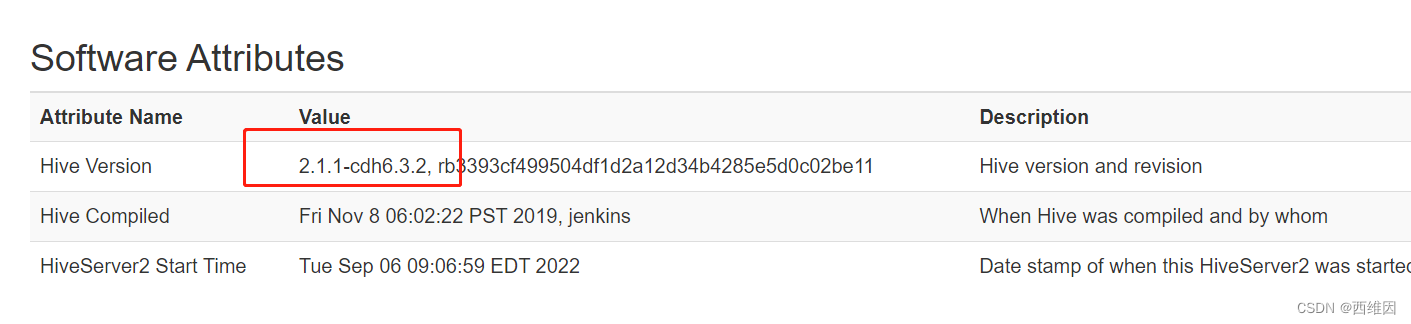
一开始连接的是CDH 6.3.2 安装的Hive版本是 2.1.1
配置好以后调用SparkSQL一直报错(在类里找不到 get_table_req 的方法)

一看Spark3.x的版本默认支持Hive-2.3.7,试过依赖降级、把CDH上的Hive依赖Jar包下载到本地指定,都没成功而且相对来说比较麻烦,还是对应版本来操作好一点,后来测试连接自己虚拟机的Hive-3.1.2,可以正常连接。
4、SpringBoot集成(序列化问题
java.lang.ClassCastException: cannot assign instance of java.lang.invoke.SerializedLambda to field org.apache.spark.rdd.MapPartitionsRDD.f of type scala.Function3 in instance of org.apache.spark.rdd.MapPartitionsRDD
在之前为SparkSession设置了Jar路径后解决了这个问题(使用UDF),用Springboot的时候又出现了这个问题。
排查后发现,是打包的问题。Springboot有默认的打包方式,打包的目录结构与自定义的不同,所以在分发Jar包以后,Executor 无法load class。
尝试过自定义打包Springboot项目,也尝试过spring-boot-maven-plugin的repackage,但是repackage的jar包没带依赖。
解决:多打了一个maven-shade-plugin的包,用于SparkSession读取。
参考链接:记一次奇妙的 spring-boot + spark debug 经历 - Phantom01 - 博客园
5、本地SparkSQL连接远程Hive调试
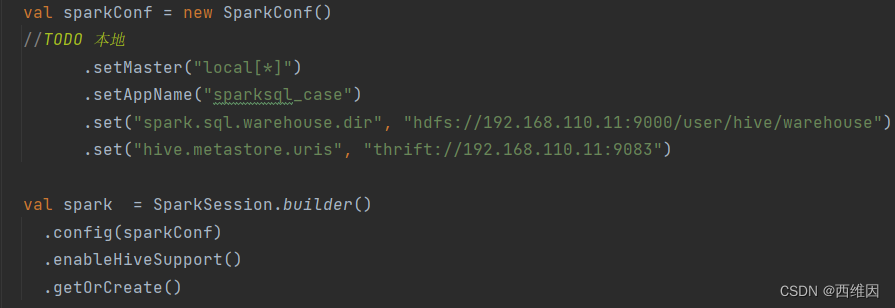
本地模式运行SparkSQL连接远程Hive遇到的问题:
HADOOP_HOME and hadoop.home.dir are unset。
解决方案:
不需要在windows搭建Hadoop,需要下载winutils-master.zip,并配置环境变量,将文件夹中对应的Hadoop版本bin下的hadoop.dll文件复制到C盘下的Windows\System32下,然后运行程序,若不生效则重启IDEA,若还不生效则重启电脑。

可见虚拟机中的Hdfs系统生成了本地用户的任务缓存文件夹(成功)
即可在本地sparksql程序中远程调用Hive
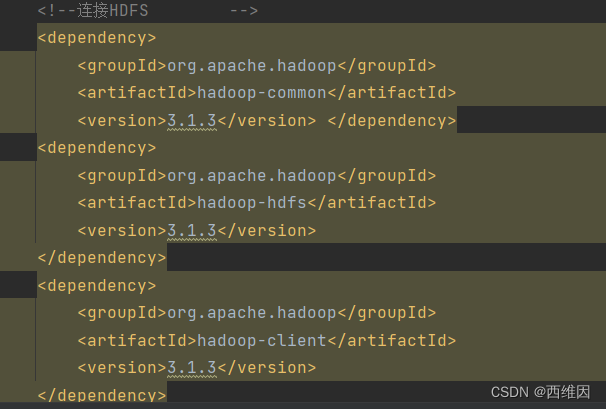
注意:pom.xml文件中导入的hdfs依赖版本需一致
参考链接:HADOOP_HOME and hadoop.home.dir are unset 报错处理_一念永恒的博客-CSDN博客_hadoop_home

















 2414
2414

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









