







开发中发现某一个SQL比较慢,通常排查方式如下:
分析:
1. 观察,至少跑一天,看看生产的慢SQL情况。
2. 开启慢查询日志,设置阈值,比如超过5s的就是慢SQL,并将它抓取出来
3. explain+慢SQL分析
4. show profile
5. 进行SQL数据库服务器的参数调优(运维经历orDBA做)
总结:
1)慢查询的开启并捕获
2)explain+慢SQL分析
3)show profile查询SQL在mysql服务器里面的执行细节和生命周期情况
4)SQL数据库服务器的参数调优
1. 查询优化
1.1 永远小表驱动大表
即小的数据集驱动大的数据集
以in与exists来说明
select * from A where id in (select id from B)
等价于==>
for select id from B
for select * from A where B.id=A.id
当B表的数据集必须小于A表的数据集的时候,用in优于exists
select * from A where exists (select 1 from B where B.id=A.id)
等价于==>
for select * from A
for select *8 from B where B.id=A.id
当A表的数据集小于B表的数据集的时候,用exists优于in
总结:
1)小表驱动大表可以看作是一个嵌套循环,在mysql中,循环次数少的位于第一层要优于循环次数少的位于第二层。
2)in 和exists都可以看成是一个嵌套的循环,in的关键点是子查询,即子查询表示外层循环;exists的关键点是主查询,即主查询为外层循环。
1.2 order by排序优化
1.2.1 order by子句,尽量使用index方式排序,避免使用filesort方式排序
尽可能在索引列上完成排序操作,遵照索引建立、的最佳左前缀法则
mysql支持两种方式的排序,filesort和index,index效率高,它指mysql扫描索引本身完成排序。filesort方式效率较低
order满足两种情况,会使用index方式排序:
1)order by语句使用索引最左前列
2)使用where子句与order by子句条件列组合满足索引最左前列
如果不在索引列上,filesort有两种算法,单路排序和双路排序。
1.2.2 order by条件不在索引列上的2种算法
1)双路排序:两次扫描磁盘
2)单路排序;一次性读取磁盘上的所有数据在buffer中排序
由于单路算法是后出的,总体而言好过双路,但是用单路可能出现多次读取磁盘的情况(数据过大的时候)
优化策略,增大sort_buffer_size参数的设置,增大max_length_for_sort_data参数的设置
总结:提升order by速度
1)order by时select * 是一个大忌,只query需要的字段,这点非常重要,在这里的影响是:
1.1 当query的字段大小总和小于max_length-for_sort_data而且排序字段不是text | blob类型时,会用改进后的算法——单路排序,否则用多路排序
1.2 两种算法的数据都有可能超出sort_buffer容量,超出后,会创建tmp文件进行合并排序,导致多次IO,但单路排序算法的风险会更大一些,所以需要提高sort_buffer_size的大小
2)尝试提高sort_buffer_size:不管哪种算法,提高这个参数都会提高效率,当然,要根据系统的能力去提高,因为这个参数是针对每个进程的
3)尝试提高max_length_for_sort_data:提高这个参数,会增加用改进算法的概率,但是如果设置的太高,数据总容量超出sort_buffer_size的概率就增大,明显症状是高的磁盘IO活动和低的处理器使用率
order by总结:

1.3 group by分组优化
1)group by实质是先排序后进行分组,遵照索引建的最佳左前缀。
2)当无法使用索引列,增大max_length_for_sort_data参数的设置+增大sort_buffer_size参数的设置。
3)where高于having,能写在where限定的条件就不要去having限定了。
2. 慢查询日志
1)mysql的慢查询日志是mysql提供的一种日志记录,它用来记录在mysql中响应时间超过阈值的语句,具体指运行时间超过long_query_time的SQL,则会被记录到慢查询日志中。long_query_time的默认值为10,意思是运行10秒以上的语句。
2)由他来查看哪些SQL超出了我们的最大忍耐时间值,比如一条SQL执行超过5s,我们就算慢SQL,希望能收集超5s的SQL,结合explain进行全面分析
3)默认情况下,mysql数据库没有开启慢查询日志,需要手动设置,如果不是调优需要的话,一般不建议开启,因为开启慢查询日志或多或少会带来一定的性能影响。慢查询日志支持将日志记录写入文件
2.1 玩转慢查询日志
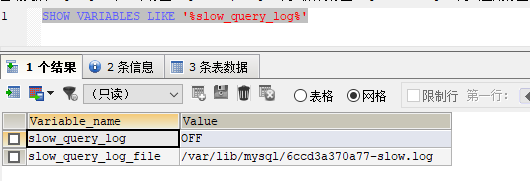
2.1.1 查看是否开启与开启慢查询功能
1)默认:SHOW VARIABLES LIKE '%slow_query_log%'
2)代码开启:SET GLOBAL slow_query_log=1;
运行之后,再次查看
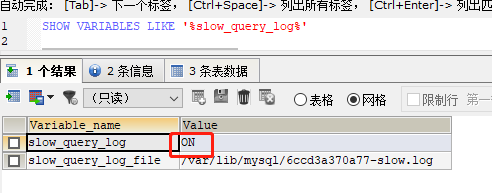
注意:使用该方式开启的慢查询日志,只对当前数据库有效,如果mysql重启后则会失效
3)配置文件开启
如果要永久生效,就必须修改配置文件my.conf。修改my.conf文件,[mysqId]下增加或修改参数
slow_query_log和slow_query_log-file后,然后重启mysql服务器,即
slow_query_log=1
slow_query_log_file=/var/lib/mysql/queryLog.log
配置版:在【mysqld】文件配置
slow_query_log=1;
slow_query_log_file=/var/lib/mysql/xxx.log
long_query_time=3;
log_output=FILE注意:
1)slow_file_log_file,它指定慢查询日志文件的存放路径,如果未指定slow_file_log_file系统默认会给一个缺省的文件host_name-slow.log。
2)在mysql中慢查询日志记录的是运行时间大于slow_query_log指定的时间才会记录,而不是大于等于。
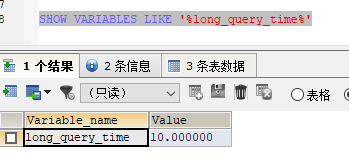
2.1.2 查看当前慢查询时间
默认开启之后,默认慢查询SQL的时间是10s
2.1.3 设置慢查询阈值
SET GLOBAL long_query_time=3再次查看,发现还是10,如图:
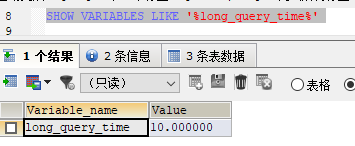
这是因为,需要重新连接或者新开一个会话,该命令才能看到修改值
重连之后,再次查看
SHOW VARIABLES LIKE '%long_query_time%'
如图:
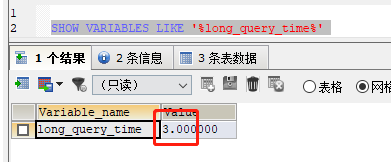
也可以直接使用下面的命令,不需要重新连接
SHOW GLOBAL VARIABLES LIKE '%long_query_time%'2.1.4 模拟SQL超时
使用SQL提供的sleep命令,如图:
睡眠4s
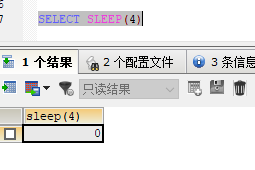
查看慢查询日志:


从日志中可以看出,导致慢查询的SQL是select sleep(4)
2.1.5 查询当前系统中有多少条慢查询记录
SHOW GLOBAL STATUS LIKE '%Slow_queries%'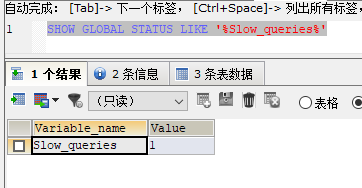
2.1.6 日志分析工具mysqldumpslow
在生产环境中,如果要手动分析日志,查找,分析SQL,显然是个体力活,mysql提供了日志分析工具mysqldumpslow
1)查看帮助信息:mysqldumpslow --help
如图:

参数解析:

2)工作中常用:
2.1 得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 /var/lib/mysql/xxx.log2.2 得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 /var/lib/mysql/xxx.log2.3 得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" /var/lib/mysql/xxx.log注意:这些命令一般需要结合 | 和 more使用,否则很可能出现爆屏情况
mysqldumpslow -s r -t 10 /var/lib/mysql/xxx.log | more3. show profile
是mysql提供可以用来分析当前会话中语句执行的资源消耗情况,可以用于SQL的调优的测量,默认情况下,参数处于关闭状态,并保存最近15次的运行结果
3.1 分析步骤
3.1.1 查看当前版本是否支持
SHOW VARIABLES LIKE '%profiling%'
3.1.2 开启profile
SET profiling=ON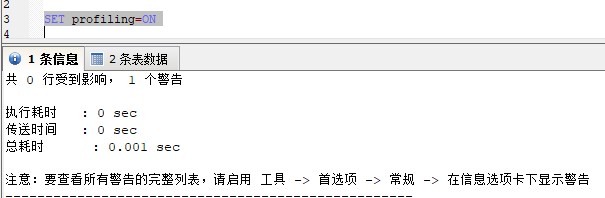
3.1.3 运行SQL
SELECT * FROM emp GROUP BY id%10 LIMIT 150000;
SELECT * FROM emp GROUP BY id%20 ORDER BY 5;3.1.4 查看结果
SHOW profiles;
3.1.5 诊断SQL
SQL导致服务器卡顿,要么是查询复杂要么是频繁IO
语法:SHOW type FOR QUERY query_id
例如:
SHOW profile cpu,block io FOR QUERY query_id
如图所示:

执行SQL,结果如图:

这个查询结果就代表了该SQL的完整的生命周期与执行流程。
所有类型参数;
1)ALL:显示所有的开销信息
2)BLOCK IO:显示块IO相关开销
3)CONTEXT SWITCHES:上下文切换相关开销
4)CPU:显示CPU相关开销信息
5)IPC:显示发送和接收相关开销信息
6)MEMORY:显示内存相关开销信息
7)PAGE FAULTS:显示页面错误相关开销信息
8)SOURCE:显示和Source_function,Source_file,Source_line相关的开销信息
9)SWAPS:显示交换次数相关开销的信息
3.1.6 常见的要不得的诊断结论
1)converting HEAP to MyISAM :表示查询结果太大,内存都不够用了往磁盘搬
2)createing tmp table:创建临时表
该步骤会经过三个小步骤:
2.1 新建临时表
2.2 拷贝数据到临时表
2.3 用完之后,删除临时表
因此,应该尽量避免产生临时表,在group by的时候很容易产生临时表,要注意
3)copying to tmp table on disk:把内存中临时表复制到磁盘,危险!!!
4)locked
以上四个诊断说明,出现任意一个都需要优化SQL
4. 全局查询日志
4.1 配置启用
在mysql的my.cnf中,设置如下:
#开启
general_log=1
#记录日志文件的路径
general_log_file=/path/logfile
#输出格式
log_output=FILE4.2 编码启用
命令:
set global general_log=1;
set global log_output='TABLE';此后,你所编写的SQL语句,将会记录到mysql库里的general_log表。
可以用下面的命令查看
select * from mysql.general_log如图:

注意:永远不要在生产上开启这个功能。















 561
561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









