






3.20:熟悉产品产品流程管理
3.25:环境搭建、项目熟悉(阿里规范手册)
4.2:基础服务、功能分配
4.13:第一阶段需求开发、第一阶段技术需求
4.20:第二阶段需求开发、第二阶段技术需求
4.23:代码review、代码优化
4.25:技术博客、项目整体验收
4.26:项目结束总结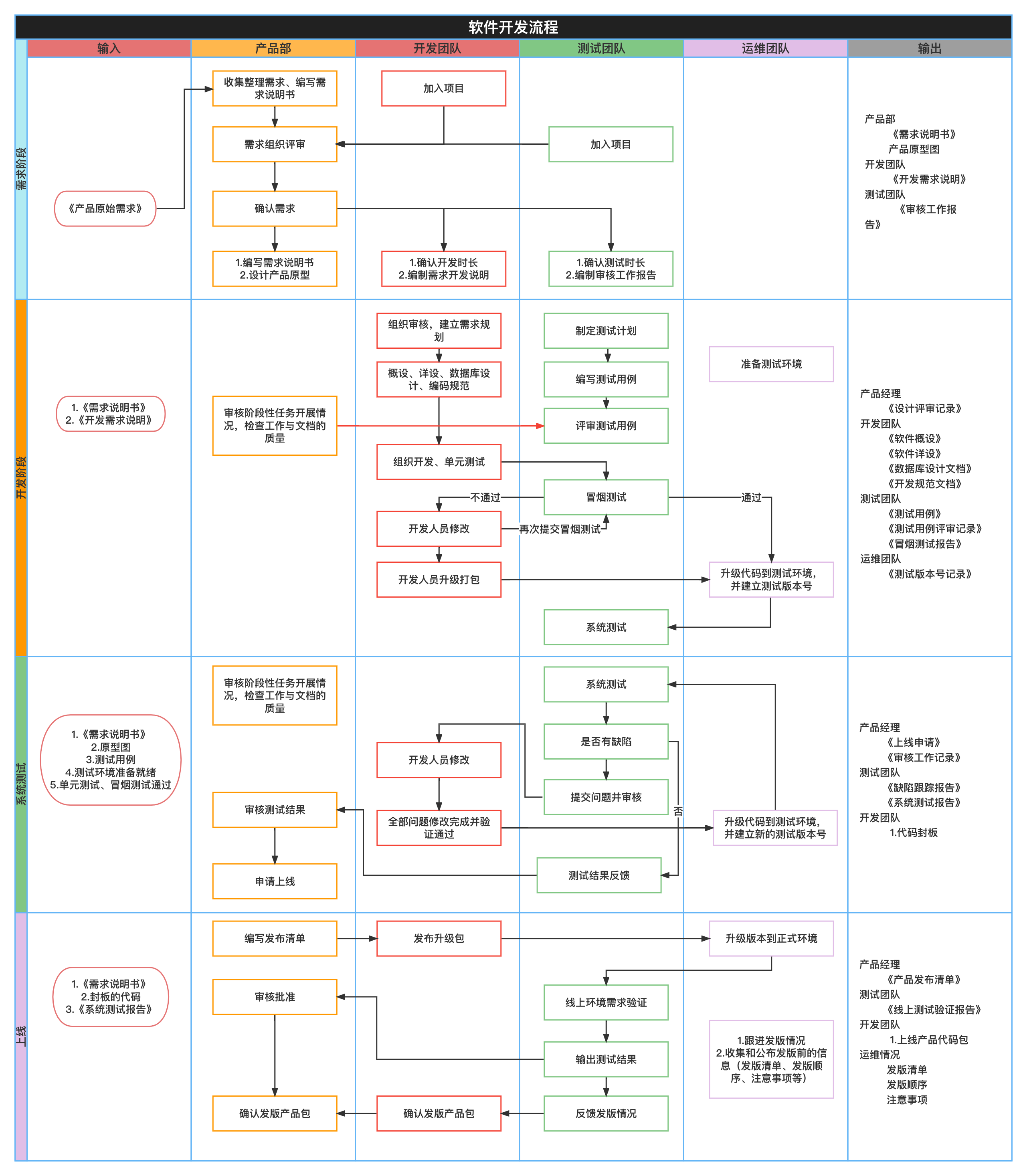
架构图
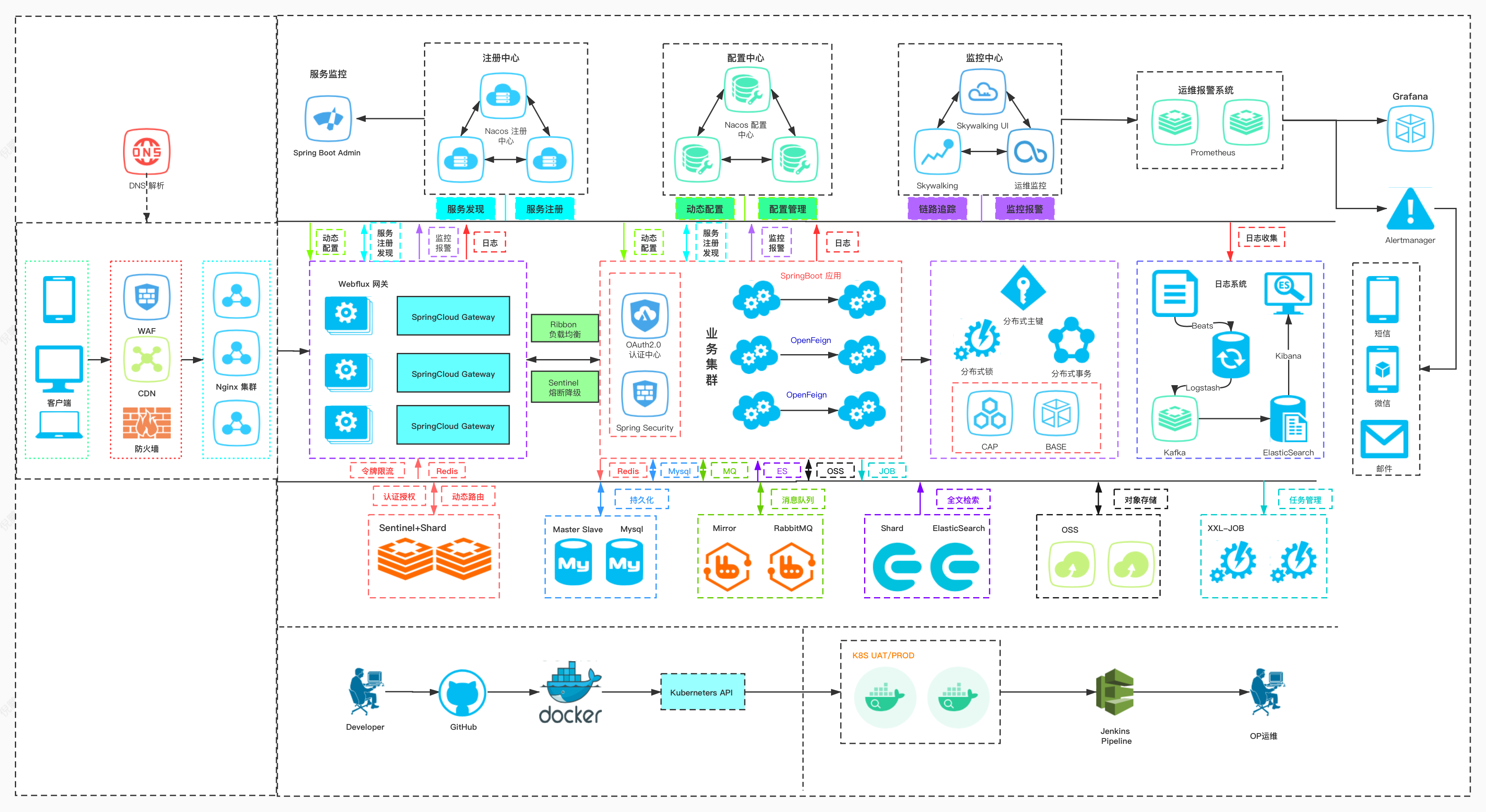
流程:
用户在客户端发起请求,进行DNS(Domain Name System域名服务器)解析,其中包括WAF(Web Application Firewall)、CDN(Content Distribution Network内容分发网络)、防火墙,
再通过Nginx集群反向代理到Spring5.0之后添加的Webflux网关,通过SpringCloud Gateway进行动态路由指定Predicate(断言)和Filter(过滤器)寻址与Sentinel+Shard进行认证授权和令牌限流,中间还可以整合Redis;
另一方面还可以同时与Nacos合作为它提供监控报警和日志,集成服务注册发现功能,Nacos集群在整个架构中都能提供服务注册发现与动态配置和配置管理功能,整合SpringBoot Admin进行服务监控
同时Gateway可以通过Ribbon进行负载均衡、Sentinel熔断降级和业务集群建立桥梁,形成联系,先是通过SpringSecurity框架与OAuth2认证中心整合JWT进行公钥私钥的颁发授权与相应验签认证功能。
SpringBoot应用在业务集群中通过OpenFeign进行相互调用,中间还整合Redis、Mysql、MQ、ES、OSS、JOB等工具,其中Redis集群可以用来做分布式数据缓存,Mysql主从复制进行数据的持久化,RabbitMQ进行系统解耦削峰填谷异步调用,ES全文搜索引擎整合Kibana、Logstash进行近乎实时搜索、分析和可视化的全文检索,使用阿里云OSS云存储服务进行对象存储、企业数据管理,使用xxl-job进行分布式任务调度。
业务集群还与分布式相挂钩,有着分布式主键,分布式锁,分布式事务,其中有两个理论,一个是CAP(分别是Consistency一致性、Availability可用性、Partitiontolerance 分区容错性)理论(这三个要素最多只能同时实现两点,不可能三者兼顾),一个是BASE(Basically Available基本可用、Soft State软状态、Eventual Consistency最终一致性)理论(即使无法做到强一致性,CAP的核心就是强一致性,但应用可以采用适合的方式达到最终一致性)
日志收集通过Beats、ELK、和Kafka整和完成,具体过程是这样的:Beats用于日志数据采集使用,Logstash收集日志,发送给Kafka进行解耦、异步处理和流量削峰,然后通过Elasticsearch集群存储日志数据,索引日志数据,再通过Kibana视图形式展现日志信息,更加人性化地在客户端进行检索以及相关操作。
以Skywalking为核心的运维监控中心可用提供链路追踪和监控报警机制,与运维报警系统Prometheus结合Grafana最终和Alertmanager通过短信、微信或者邮件的形式给模块负责人发送警告通知。
最后Developer将代码文件上传到GitHub上通过docker容器部署,使用K8s AP对资源进行编排,管理应用的全生命周期,同时也提高发布与更新版本的效率,然后通过Jenkins Pipeline进行整个构建、测试、交付等持续集成,运维人员继续对这些进行维护。
API 文档规范
请求方式只用 GET/POST
请求路径按照任务分配表上的写
GET 请求的参数在 Query 里面填写,POST 在 Body 里写。不要混用
不要使用 RESTFul 的路径传参
环境的使用:
不要使用环境变量,目前用不上
只使用一个环境 url 前缀即可(协议+ip+端口)
已有的环境可以直接用,但是不要改,因为这是公用的。如果有需求自己建一个环境即可。
请求参数规范:以下
参数名采用驼峰命名
数据库中存在的字段的参数,命名要保持一致
如果参数中用多个 id 参数,必须区分命名,且要与数据库一致
传参的实例值尽量真实一点
类型要选择正确,类型的选项很多自己看看。
参数描述简练准确
响应数据示例的格式必须的实际的格式
响应数据的类型和描述和请求参数的要求一致
金额数据:后端使用整数存,但是到了前端部分要转化为小数(类型为Number)
ES技术介绍
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
Elasticsearch 是一个分布式、高扩展、高实时的搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用Elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。Elasticsearch 的实现原理主要分为以下几个步骤,首先用户将数据提交到Elasticsearch 数据库中,再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据,当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch是与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。
Elasticsearch可以用于搜索各种文档。它提供可扩展的搜索,具有接近实时的搜索,并支持多租户。Elasticsearch是分布式的,这意味着索引可以被分成分片,每个分片可以有0个或多个副本。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
Elasticsearch使用Lucene,并试图通过JSON和Java API提供其所有特性。它支持facetting和percolating,如果新文档与注册查询匹配,这对于通知非常有用。另一个特性称为“网关”,处理索引的长期持久性;例如,在服务器崩溃的情况下,可以从网关恢复索引。Elasticsearch支持实时GET请求,适合作为NoSQL数据存储,但缺少分布式事务。
Shay Banon在2004年创造了Elasticsearch的前身,称为Compass。在考虑Compass的第三个版本时,他意识到有必要重写Compass的大部分内容,以“创建一个可扩展的搜索解决方案”。因此,他创建了“一个从头构建的分布式解决方案”,并使用了一个公共接口,即HTTP上的JSON,它也适用于Java以外的编程语言。Shay Banon在2010年2月发布了Elasticsearch的第一个版本。
Elasticsearch BV成立于2012年,主要围绕Elasticsearch及相关软件提供商业服务和产品。2014年6月,在成立公司18个月后,该公司宣布通过C轮融资筹集7000万美元。这轮融资由新企业协会(NEA)牵头。其他投资者包括Benchmark Capital和Index Ventures。这一轮融资总计1.04亿美元
2015年3月,Elasticsearch公司更名为Elastic。
在2018年6月,Elastic提交了首次公开募股申请,估值在15亿到30亿美元之间。公司于2018年10月5日在纽约证券交易所挂牌上市。一些组织将Elasticsearch作为托管服务提供。这些托管服务提供托管、部署、备份和其他支持。大多数托管服务还包括对Kibana的支持。
Elasticsearch 自从诞生以来,其应用越来越广泛,特别是大数据领域,功能也越来越强大,但是如何有效的监控管理 Elasticsearch 一直是公司所面对的难题,由于 Elasticsearch 集群的稳定性,决定了其业务发展的高度,对于一个应用来说其稳定是第一目标,所以完善的监控体系是必不可少的。此外,Elasticsearch 写入和查询对资源的消耗都很大,如何合理有效地控制资源,既能满足写入和查询的需求,又能满足资源充分利用,这是公司必须面对的问题。
在国内,还没较为完善的面向 Elasticsearch 的监控管理平台,很多企业往往只关注搭建一套简单分布式的集群环境,而对这个集群的缺乏监控和管理,元数据混乱,写入和查询耦合,缺乏监控一旦集群出现问题,就会导致数据丢失,甚至很容易导致线上应用故障。相比于小公司,中大型公司的资金较为充足,所以中大型公司,会选择为每个应用去维护一套集群,但是这每当资源不够需要扩容或者缩容时,极其不方便,需要增加删除节点,其运维成本过高。而且对每个应用来说,可能不能够充分利用资源,但是如果和其他应用混合部署,但是又涉及到复杂的资源分配问题,而且随着应用的发展,资源经常需要变动。在国外,ELasticsearch 的应用也很广泛,也有对 Elasticsearch 进行很好的监控和管理,Amazon AWS中也有基于 Elasticsearch 构建的平台服务,帮助电商应用程序,网站等提供安全、高可靠、低成本、低延时、高吞吐量的个性化搜索。虽然,对集群进行了监控和管理,但是管理的维度还是集群级别的,而对于应用往往是模板级别的,如果应用无法与集群一一对应,那就无法进行更高效的管理。这无法满足公司级别想要高效利用资源,集群内部能支持多个应用的场景
cluster:代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。
shards:代表索引分片,es可以把一个完整的索引分成多个分片,这样的好处是可以把一个大的索引拆分成多个,分布到不同的节点上。构成分布式搜索。分片的数量只能在索引创建前指定,并且索引创建后不能更改。
replicas:代表索引副本,es可以设置多个索引的副本,副本的作用一是提高系统的容错性,当某个节点某个分片损坏或丢失时可以从副本中恢复。二是提高es的查询效率,es会自动对搜索请求进行负载均衡。
recovery:代表数据恢复或叫数据重新分布,es在有节点加入或退出时会根据机器的负载对索引分片进行重新分配,挂掉的节点重新启动时也会进行数据恢复。
river:代表es的一个数据源,也是其它存储方式(如:数据库)同步数据到es的一个方法。它是以插件方式存在的一个es服务,通过读取river中的数据并把它索引到es中,官方的river有couchDB的,RabbitMQ的,Twitter的,Wikipedia的。
gateway:代表es索引快照的存储方式,es默认是先把索引存放到内存中,当内存满了时再持久化到本地硬盘。gateway对索引快照进行存储,当这个es集群关闭再重新启动时就会从gateway中读取索引备份数据。es支持多种类型的gateway,有本地文件系统(默认),分布式文件系统,Hadoop的HDFS和amazon的s3云存储服务。
discovery.zen:代表es的自动发现节点机制,es是一个基于p2p的系统,它先通过广播寻找存在的节点,再通过多播协议来进行节点之间的通信,同时也支持点对点的交互。
Transport:代表es内部节点或集群与客户端的交互方式,默认内部是使用tcp协议进行交互,同时它支持http协议(json格式)、thrift、servlet、memcached、zeroMQ等的传输协议(通过插件方式集成)。

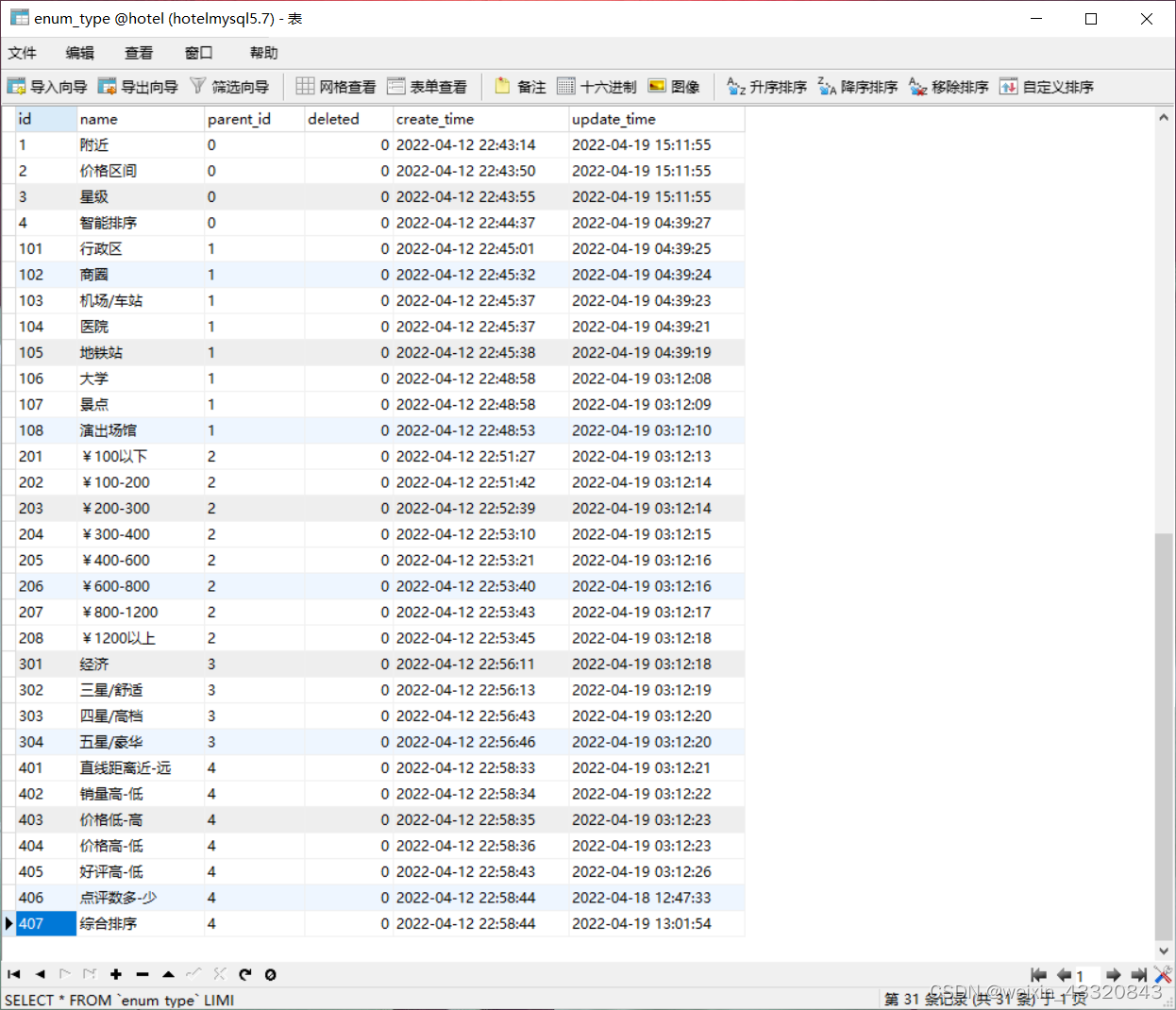
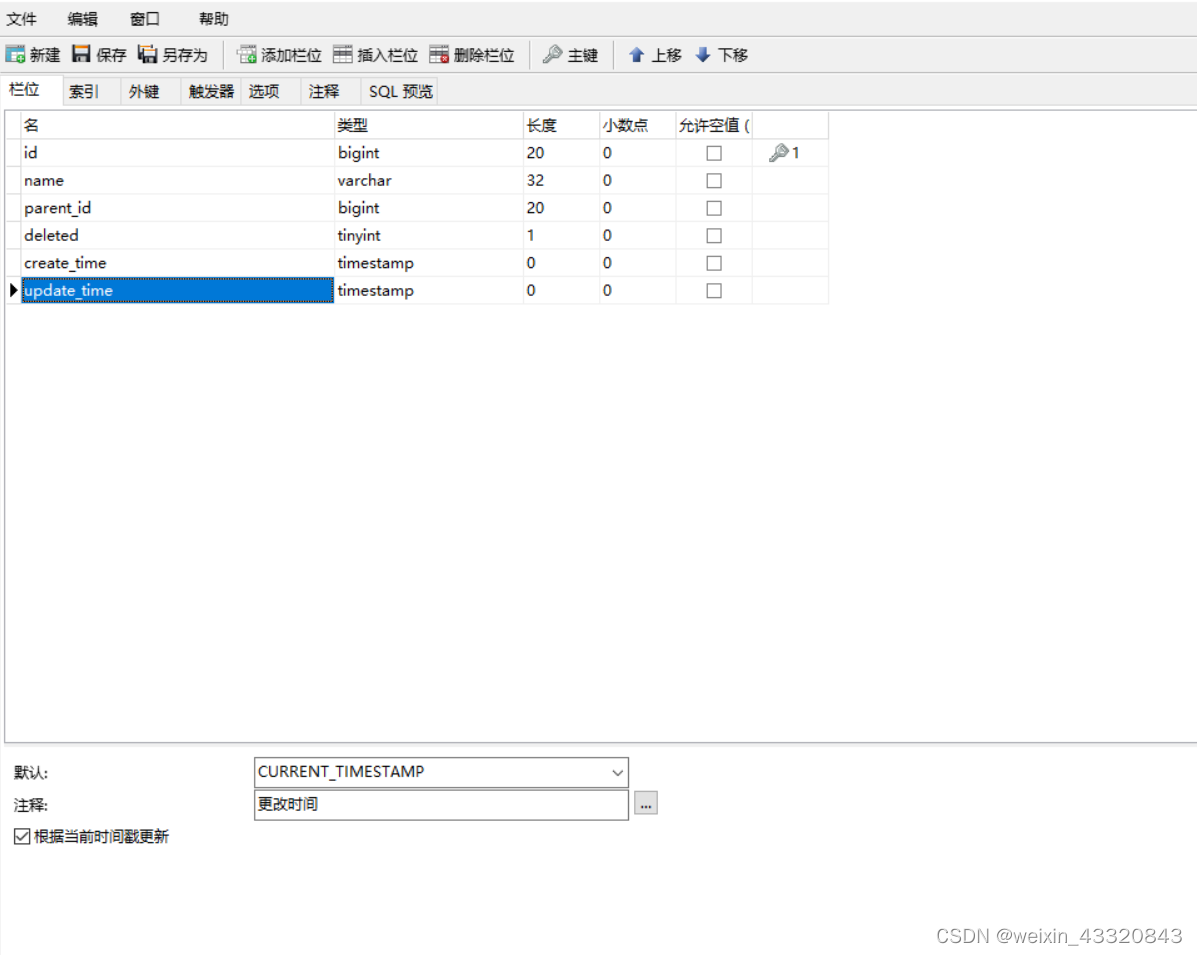
数据库设计
总结
现在经过这一个月忙碌的时间,这个项目自己写代码的时间可能不太长,但是花费的精力确实很大,从最开始什么都没有,什么都不知道的小白,慢慢了解软件开发的全过程,从需求设计,数据库设计,接口设计、熟悉版本控制工具的使用,代码编写阶段与代码review,期间的很多次小组会议,共同学习阿里开发规约等团队协作。对未来的工作也有了相对更为全面深刻的认知,期间我遇到了很多问题。下面列举总结一下
首先就应该是工具的熟悉与使用了,比如项目中使用到的git是我很久之前浅显地学习了一些,在实际操作中还闹出没有update直接pull到master分支的情况,再就是ApiPost和Chinner的使用,这些之前都没接触过,中间还出现为保存文件就直接退出的乌龙,所以以后一定要及时备份保存相关数据
再就是需求分析的时候有很大的问题,自己也第一次开始用ProgressOn这种在线画图工具去梳理酒店项目的一些具体流程,第一次以架构师的角度去考虑项目的问题,包括项目中的模块拆分,比如用户中心,商家中心,酒店中心,后台管理员中心。跟着现有的小程序界面去好好体验一下不同界面,梳理流程。从用户的视角来看可能是我们比较熟悉的,就主要是页面的浏览,针对地点星级价格评价等进行同一家商店的纵向对比和不同商家之间的横向对比。其中涉及到的es搜索筛选,商品的增删改查都是以后真正工作要经常考虑的东西。以前只是停留在使用产品的层次上,不知道这些底层是什么,当我真正看到我们齐心协力写出的小程序展示出的效果的时候感觉非常惊喜,以及说不出的成就感。这里想先展示一下自己开始的设计,现在第一次的小组会议,被小组选出来给大家讲解的场景也确实历历在目,还有一丢丢小自豪。当然现在看着这个流程确实是还有很多欠缺,以后在学习和工作中需要去不断完善细节,也想不断加强自己的架构能力。会以一个开发者的角度去思考问题,我想这就是我在这个项目中学到的最有价值的东西,具体的增删改查能力自己可以慢慢增强。
其次是数据库的设计,原来也听说过这些都是架构师帮你想好的,你只需要去具体的使用就行。当这次真的自己去设计的时候,有很多相关知识就得应用起来,比如数据库三大范式,每个表中涉及到的字段,存在的话都是有一定的原因的,有时候因为需要方便而设计冗余字段,有时候还需要设计中间表,这就需要站在整个系统业务这一宏观角度去思考这些问题,再就是约束和索引的创建,约束用来保证字段的唯一性、不为空或者方便查询的外键,从而保证数据的正确性、有效性、完整性;首先要明确索引的创建的目的,是为了提高查询速度,但是索引的创建本身就是比较消耗磁盘性能,需要减少磁盘IO次数,只有在数据量很大的时候,当创建索引之后的提升比索引本身的消耗高的时候才适合创建,明确适合创建索引的情况,比如频繁作为WHERE查询条件的字段,DISTINCT字段、经常GROUP BY和ORDER BY的字段等等。同时我们应该也要注意索引失效的情况,比如使用了select * 、索引列上有计算、用了函数、不满足最左匹配、like左边包含%、使用OR关键字、NOT IN和NOT EXISTS等等。这些都是我需要在面试和以后工作的时候十分清楚的。还有就是在数据库的设计中我们需要重点关注最新的阿里开发规约,命名规范和一些必需的字段以及某些字段用的数据类型,尤其是跟金额相关的数据要格外注意,等以后工作的话在金额方面造成精度丢失可就是大事了。数据库的设计是个大头,我们团队合作共同商讨,几经改版,最终终于有一个相对合适的版本,当然可能因为我们前期经验不足,在后续业务代码开发的时候还需要重新新增一些表或者字段。
再来谈接口设计这一块。我们用的ApiPost这个国产软件,团队开发人数在没付费之前是有15这样一个限制的,前期确实优点阻碍我们工作的进行,但整体使用类似Postman,还是中文,比较友好。具体设计是根据前端页面,确定接收的参数和传给前端的参数,有些参数在实体表中不存在的情况下很多时候还需要自己封装DTO来进行数据的传输,前后端的交互也是项目中很关键的一个部分,后期代码开发出来之后进行一系列的联调来确保程序可以正常进行。这就让我想起了自己原来做练手小项目的时候,就一边后端debug,一边在前端服务器查看请求传递的json数据,不然用Postman直接报个500或者404也没什么太多的头绪去修改。在设计接口的时候团队最好统一参数的传递格式,倒也不一定要用Restful风格,接口名称模块名+具体功能名,中间用 / 隔开,而且当功能名的词数过多时,应该用 - 来分开,而不是我们经常用的驼峰命名法。
这会到了具体代码的开发,因为报名了项目架构小组,这算是给自己额外的任务,因为之前看微服务的直播课的时候刘雪松老师经常讲Oauth2授权部分,所有我看到有这部分的时候毫不犹豫选择了这个模块,但确实这个模块比较晦涩,也是每个项目的核心部分,一般的底层程序员不太可能接触的到,我原以为看了好多遍其中的好几种授权模式就会比较好接受,当我看到原来那些auth模块的代码的时候还是很懵,又是一堆陌生的知识,其中关于公钥的颁发和验签流程是我在后续学习得继续巩固的,要求自己在面试如果问到这一块的时候必须得说清楚。前期搭建对我来说是再次熟悉一遍流程+抄代码,其中因为数据库中没有resource表以及相应字段就导致程序始终启动失败,好在是在于小伙伴交流之后解决了。我在代码开发前面一段时间都没有在做项目,而是在关注JUC和面试的一些知识点,对于MVC三层架构的具体应用也出了很多差错,只知道DAO层继承mp的BaseMapper,而service中接口和对应实现类并没有去继承,也给自己带来了很多的麻烦,这里有一些细节,就是继承mp那些之后就拥有了那些常用的增删改查方法,在每一层具体调用就行,能给我们减少很多代码的开发,当然,当我们需要扩展的方法的时候,就直接在service接口中扩展,尽量在service实现类中进行单表查询而不是在dao层自己加个方法写SQL,因为这在以后项目的拆分的时候非常不方便,这样写的话这些代码全部要改。这里也需要注意service实现类中、如果是涉及本张表的时候可以直接用this调用其中强大的方法,需要其他表的操作时候需要在前面自动注入其他表的相应service接口,其实最开始使用mp时,感觉比较陌生,其中的Lambda写法更是让我摸不着头脑,刚开始编码的好几天每天都是在看这些API的具体使用,期间去官网好好看了一些操作,也去阅读相应的代码,有一定的认知之后再去开发,这个过程其实还是蛮痛苦的,看着感觉啥也不会就要动手写代码的感觉还是特别慌,后来使用多了其实主要也就是那么些东西,主要就是一些条件条件构造器的使用,有基础的话最好结合Lambda表达式去写,这样写起来代码也会比较优雅,注意使用条件构造器的时候需要很清楚要用的SQL语句是什么,再就是其中使用stream流将实体类数据赋值,比如在传输中用的DTO赋值,就会经常用到Stream流,这些算是在公司中需要掌握的基础知识吧,如果连这种简单的CRUD都不太熟练,那可能真的在公司里也会过得很难受。这中间我还在另一个项目中犯了一个错,就是在controller层中注入的是service实现类,导致在新增某个方法时程序报动态代理异常,因为Spring是自动选择动态代理类型的,当我使用的不一致就会报错,要不就在配置文件中都强制使用同一个动态代理。在具体业务中暂时也没有太复杂的逻辑,就是尽量用卫语句尽量减少if-else的嵌套,多使用if就行,这样相应代码的可读性也会提高。当然在遇到复杂的业务不可避免使用if-else的情况下写一些也没事,这里其实就体验出程序员的水平了,如果算法功底比较好,对于这些的分类判断就是会很清晰的,这也坚定了我学好算法的决心,做好长期战斗的准备,因为是非科班,这方面基础欠缺,要想以后自己更上一层楼,这些也是必经之路,好在年轻,好在对这些有足够的热情,在面试前再集中分类刷题,才能真的进入比较好的公司。
最后需要扩展提升的就是对于微服务和中间件的熟悉,当前对于Redis、MQ、ES等的使用还是有很大的欠缺,在做积分模块的时候就涉及到过期积分的处理,我们还是因为经验不足,直接使用xxl-job来处理,这其中有很大的一个弊端,如果直接使用这个那定时任务设置的更新时间就有很大的问题,如果设计的是1s更新一次那就对系统是很大的性能消耗,设计1min那时效性又会比较差;过期积分放在Rocket延时队列或者Redis延迟队列中,比如优惠券过期时间,就是到了那个时间之后,才把消息发给你,这样就能保证数据的实时性。后面优先复习Redis和MQ的知识。
接下来要多学习的地方:先多看这个项目大家写的代码,并选择其中一些有代表的功能自己去手动实现,把基础再打扎实一些,多背面试题,刷算法题,巩固多线程这些东西,并且去系统学习计算机网络和操作系统,弥补非科班的短板。上文的Redis和MQ知识的学习是必不可少的,MySQL相关知识基础也要打牢再就是多去熟悉各种微服务理论知识以及实际的应用。再就是有时间的情况下对JVM有一个初步的系统的了解,在以后的工作中多关注一些深入的点和一些细节上的东西。















 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









