







python爬虫requests+lxml的使用(入门级)
爬虫流程
1.用requests库的get方法发起请求
2.获取网页源码
3.用lxml中的xpath语法进行解析
4.对拿到的数据进行遍历
5.保存为txt文件
A.获取网页源码
import requests
from lxml import etree
url = 'http://qiushi.92game.net/'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:70.0) Gecko/20100101 Firefox/70.0'}
response = requests.get(url,headers=headers)
print(response.text)

B.将内容遍历打印出来
import requests
from lxml import etree
url = 'http://www.lovehhy.net/Joke/Detail/QSBK/3'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:70.0) Gecko/20100101 Firefox/70.0'}
response = requests.get(url,headers=headers)
#print(response.text)
html = etree.HTML(response.text)
a_list = html.xpath('//div[@id="endtext"]/text()')
print(a_list)
for i in a_list:
print(i)
 C.将内容进行保存为.txt文件
C.将内容进行保存为.txt文件
整体代码
import requests
from lxml import etree
url = 'http://www.lovehhy.net/Joke/Detail/QSBK/3'
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:70.0) Gecko/20100101 Firefox/70.0'}
response = requests.get(url,headers=headers)
#print(response.text)
html = etree.HTML(response.text)
a_list = html.xpath('//div[@id="endtext"]/text()')
#print(a_list)
with open('qsbk.txt','w',encoding='utf-8') as fp:
for i in zip(a_list):
a = i
print(a)
fp.write(str(a)+'\n')
最后的效果
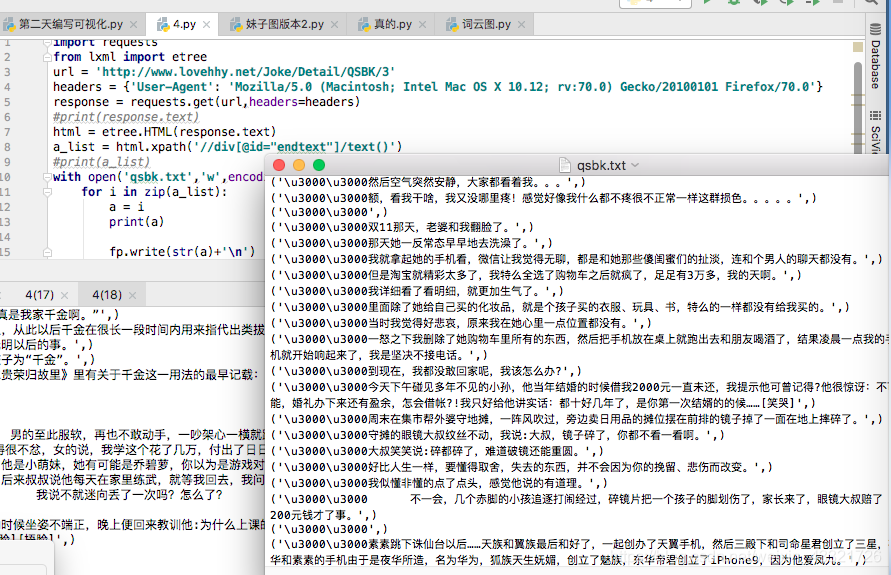















 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









