






ES基本使用
文章目录
重置es密码,初始用户elastic
elasticsearch-reset-password -u elastic
1.es的访问
使用URL访问
将用户名和密码拼接到 URL 中的格式为:
http://{username}:{password}@{host}:{port}/{api_path}
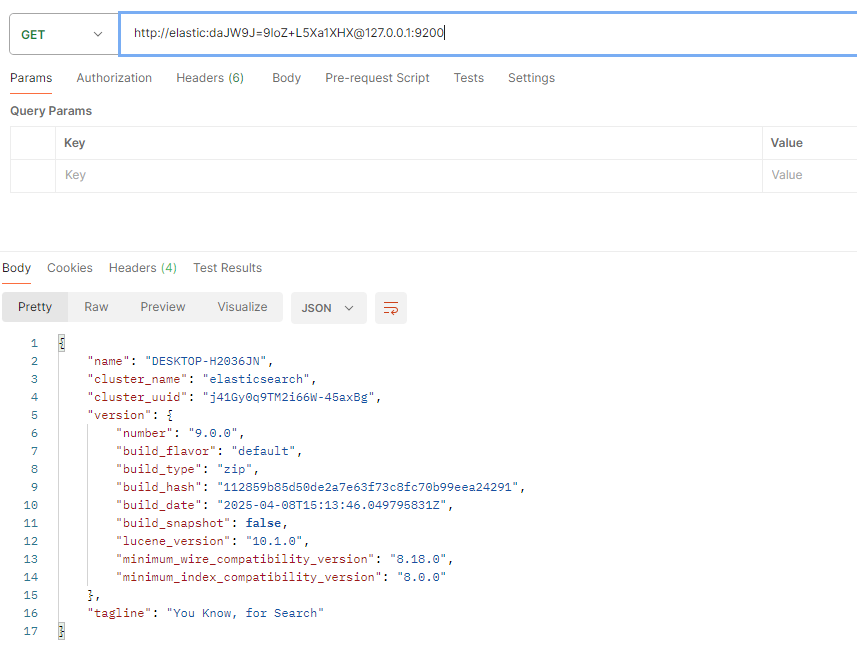
2.mapping的理解
Dynamic Mapping
如果创建的索引没有预先设计好的mapping,那么写入数据的时候会自动创建mapping。
dynamic: true
- 写入
{"new_field": "test"}时,若new_field未在Mapping中定义,ES会自动将其类型推断为text(主字段)和keyword(子字段)25。 - 风险:可能导致“Mapping爆炸”(字段数量过多),影响集群性能和稳定性
dynamic: false
- 新字段不会被索引,但数据会完整存储在
_source中。 - 结果:无法通过该字段进行搜索或聚合,但可通过
_source获取原始值。 - 适用场景:需保留原始数据但无需查询的场景,如日志存储
dynamic: strict
- 写入包含未定义字段的文档会直接报错,数据无法入库。
- 示例:返回错误提示
"strict_dynamic_mapping_exception": "mapping set to strict"。 - 适用场景:需严格保证Mapping结构一致性的场景,如生产环境数据规范。
keyword 与 text的区别
基础定义与核心差异
| 特性 | text 类型 | keyword 类型 |
|---|---|---|
| 存储方式 | 文本被分词器拆分后存储(如 "苹果手机" → ["苹果", "手机"]) | 原样存储,不进行分词(如 "苹果手机" 整体存储) |
| 查询场景 | 支持全文搜索(模糊匹配、相似度排序) | 仅支持精确匹配、聚合、排序(如过滤状态码、分类标签) |
| 分词处理 | 默认使用标准分词器(可自定义如 ik_max_word) | 不进行分词,视为单一词元 |
| 适用场景 | 文章内容、商品描述等需模糊搜索的字段 | 订单号、状态码、标签等需精确匹配的字段 |
keyword仅支持精准匹配
text支持模糊匹配
主字段,子字段
主字段支持模糊匹配,子字段支持精确查询
可以防止同一个字段创建连个独立字段
GET /products/_search {
"query": {
"match": { "product_name": "智能" } // 主字段分词后匹配
}
}
GET /products/_search {
"query": {
"term": { "product_name.raw": "iPhone 15" } // 子字段精确匹配
},
"sort": [{ "product_name.raw": "asc" }] // 按原始值排序
}
创建mapping
post请求创建模板,_template/模板名称
http://elastic:daJW9J=9loZ+L5Xa1XHX@127.0.0.1:9200/_template/my_template
参数说明
{
//模板名称,index会自动匹配
"index_patterns": ["mytest*"],
"settings": {
//主分片数
//将索引数据水平拆分到多个物理分片,实现分布式存储并行计算
//影响索引写入吞吐量,一旦创建不可修改
//按照每片300GB设置,设置后无法修改
"number_of_shards": 3,
//副本分片数
//创造冗余副本,数据容灾+负载均衡
//读取优化,副本数越多,查询并发处理能力越强,会额外占用资源,数据同步延迟
"number_of_replicas": 1,
//全局启用 字段格式错误容忍机制,数据类型不匹配时候,丢弃匹配失败字段,非拒绝整个文档
"index.mapping.ignore_malformed": true
},
"mappings": {
// 动态映射控制
// strict 严格模式 禁止未声明字段写入
// true(默认)自动推断并扩展添加映射(可能导致索引膨胀)
// false 忽略新字段,保留原始数据不会索引(仅存储,不能搜索)(映射级别)
"dynamic": "strict",
"_source": {
//控制是否存储原始json
//true保留完整原始数据,支持数据更新、高亮显示、reindex 等操作
//false不存储原始数据,节省存储空间,但无法通过 _update API 修改文档或使用
"enabled": true,
// 查询结果中不显示 filead1 和 filed2
"excludes": ["filead1","filed2"],
// 启用压缩
//"compress": true
},
//用于定义文档中每个字段的数据类型,存储规则和检索
"properties": {
//字段名
"host_name": {
//数据类型
"type": "keyword",
//当字段类型为keyword的字符串长度超过设定值时,该字段不会被索引
//无法通过该字段搜索或聚合,每个中文每个字符几计为1
"ignore_above": 256,
//空值替换
"null_value": "N/A"
},
"created_at": {
"type": "date",
//确保正确解析字符串或数值为时间戳
"format": "yyyy-MM-dd HH:mm:ss",
//字段兼容错误模式开启
"ignore_malformed": true
},
"data_info": {
"type": "text", // 主字段用于分词全文搜索
"analyzer": "ik_max_word",
"fields": {
"keyword": { // 子字段用于精确匹配
"type": "keyword",
"ignore_above": 256
}
}
},
"data_info2": {
"type": "text",
"fields": { "raw": { "type": "keyword" } }}
}
}
}
插入模板
{
"index_patterns": ["ldsx_test*"],
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1,
"index.mapping.ignore_malformed": true
},
"mappings": {
"dynamic": "true",
"_source": {
"enabled": "true"
},
"properties": {
"data_name": {
"type": "keyword",
"ignore_above": 256,
"null_value": "N/A"
},
"created_at": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss",
"ignore_malformed": true
},
"data_info": {
"type": "text",
"fields": { "raw": { "type": "keyword" } }}
}
}
}
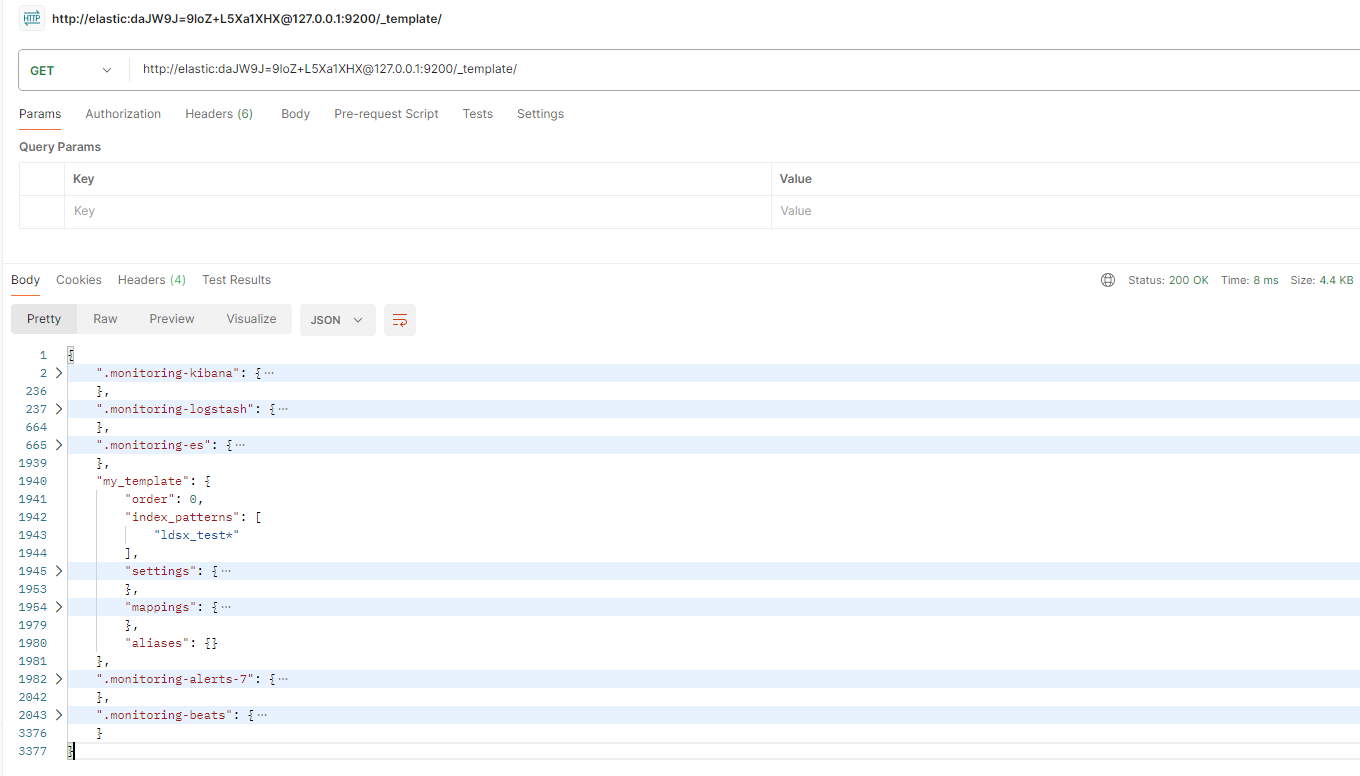
查看mapping列表
3.创建索引
已经创建模板后,索引根据模板名匹配mapping
http://elastic:daJW9J=9loZ+L5Xa1XHX@127.0.0.1:9200/要创建的索引名
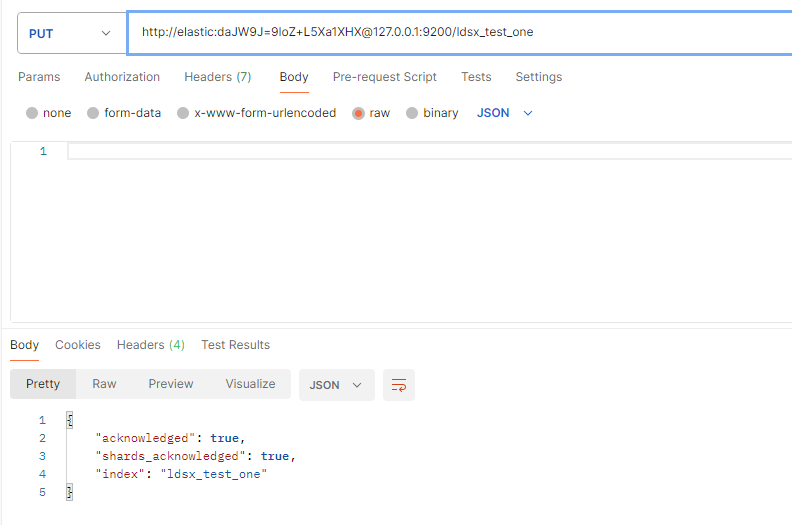
如果创建索引无匹配模板创建时可以设置mapping
若未预先定义模板,索引会根据首次插入的数据自动推断字段类型,此时不会关联任何显式模板
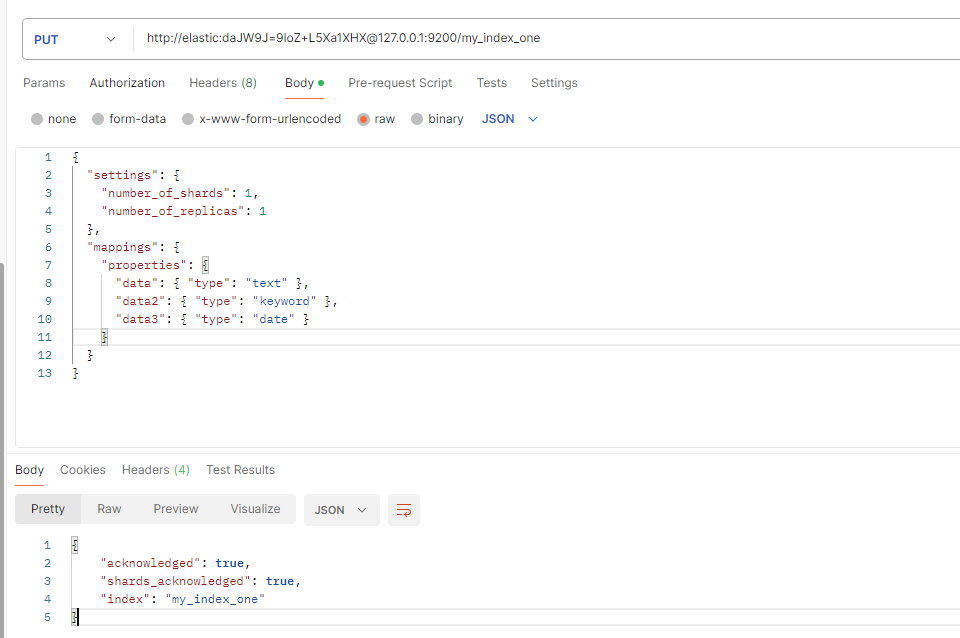
mapping是空的
4.查看索引列表
http://elastic:daJW9J=9loZ+L5Xa1XHX@127.0.0.1:9200/_cat/indices
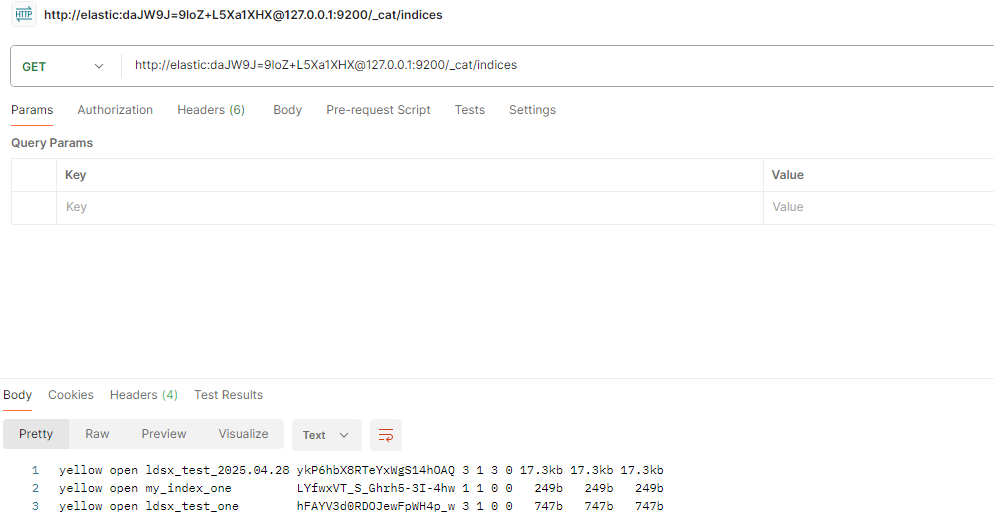
5.删除索引
http://elastic:daJW9J=9loZ+L5Xa1XHX@127.0.0.1:9200/索引名
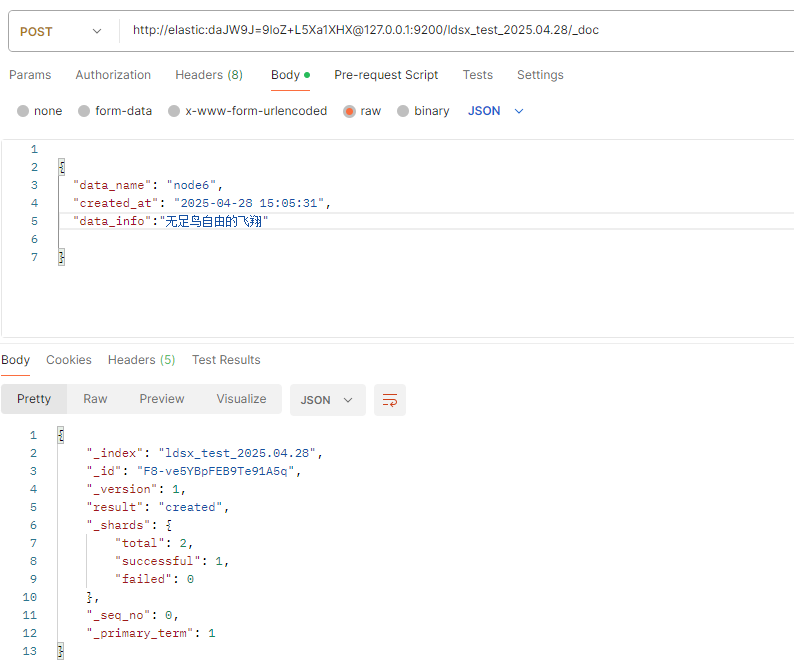
6.添加数据
post请求添加
http://elastic:daJW9J=9loZ+L5Xa1XHX@127.0.0.1:9200/ldsx_test_2025.04.28/_doc
{
"data_name": "node6",
"created_at": "2025-04-28 15:05:31",
"data_info":"无足鸟自由的飞翔"
}
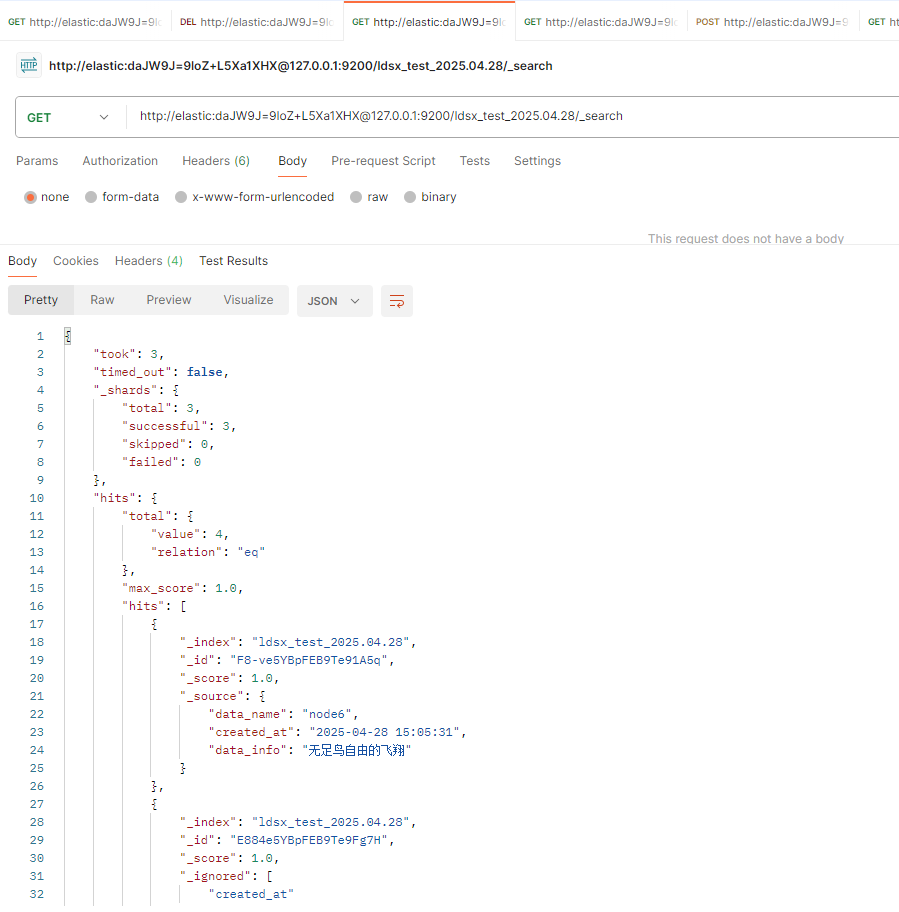
7.查询数据
get请求,查询数据
http://elastic:daJW9J=9loZ+L5Xa1XHX@127.0.0.1:9200/ldsx_test_2025.04.28/_search
控制返回条数
_search?size=1,size设置需要返回条数
http://elastic:daJW9J=9loZ+L5Xa1XHX@127.0.0.1:9200/ldsx_test_2025.04.28/_search?size=1

















 6009
6009

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









