








python cookbook内容提炼-第二章 字符串和文本
这篇博客,我们继续cookbook内容提炼,这部分是关于字符串和文本处理的,都是干货,这篇博客比第一篇博客更重要,在实战开发中可以快速提升开发速度。
下面内容中 只有2.9和2.16不怎么用,其他的都是开发中很重要的技巧和知识点,感兴趣的可以好好学习学习。
2.1 使用多个界定符分割字符串
2.2 字符串开头或结尾匹配
2.3 用Shell通配符匹配字符串
2.4 字符串匹配和搜索
2.5 字符串替换
2.7 最短匹配模式
2.8 多行匹配模式
2.9 将Unicode文本标准化
2.10 在正则式中使用Unicode
2.11 删除字符串中不需要的字符
2.12 字符串对齐
2.13 合并拼接字符串
2.14 字符串中插入变量
2.15 以指定列宽格式化字符串
2.16 在字符串中处理html和xml
2.1 使用多个界定符分割字符串
问题:你需要将一个字符串分割为多个字段,但是分隔符(还有周围的空格)并不是固定的。
就是说,我们现在有一个字符串,想进行分割,但是分隔符不止一个,可能有很多个,这个使用正则表达式去实现的。
这个技巧很实用。
那么来看一下代码:
line = 'asdf fjdk;afed, fjek,asdf, foo'
import re
spstr=re.split(r'[;,\s]\s*',line)
print(spstr)
运行结果:

可以看到这个方法重点在于匹配模式的设置 ‘[;,\s]\s*’
来解释一下 ‘[;,\s]\s*’
这个这个其中’[;,\s] ; ,\s(也就是空格)都可以作为分割符 \s*则表示任意多个空格。
就是分割符可以是 逗号,分号或者是空格,并且后面紧跟着任意个的空格。
再看一下一些例子,方便大家理解。
line = 'asdf fjdk;afed, fjek,asdf, foo'
import re
spstr=re.split(r'[;,\s]\s*',line)
print(spstr)
print("*"*50)
s="fasojfiaoo dfaojf; dfjiaidfa, dfja da dfiaff;fdasf,dfa;"
spstr=re.split(r'[;,\s]\s*',s)
print(spstr)
print("*"*50)
s="fa;;fas ;,fa; fsfda"
spstr=re.split(r'[;,\s]\s*',s)
print(spstr)

可以看到 ; , 首先作为一个分隔符,如果后面还有空格,也只会进行一次分割,如果两个连续的 ;或者, 则会进行两次分割。
再看一下例子:
s="fa;;fas ;,fa; fsfda"
spstr=re.split(r'[;,\s]\s*;*,*',s)
print(spstr)
看一下结果:

对于这段知识点,我觉得不在于详细去说,而在去根据结果分析代码。
2.2 字符串开头或结尾匹配
这个就是判断字符串是否以另一段字符串为结尾或者开头。
来看一下代码就知晓了:
filename = 'spafsadfsafasm.txt'
print(filename.endswith('.txt'))
print(filename.endswith('.txx'))
print(filename.startswith('spafsa'))
print(filename.startswith('afsa'))
运行结果:

这个在开发中也是很常用的。
这个也支持多种后缀匹配:
filenames=[ 'Makefile', 'foo.c','bar.py', 'spam.c', 'spam.h' ]
res=[name for name in filenames if name.endswith(('.c', '.h')) ]
print(res)
结果:

支持多种匹配,就很棒了,在开发中使用,可以很方便实现很多应用。
这部分技巧,对于我们解决字符串,开头和结尾匹配有很大帮助。
2.3 用Shell通配符匹配字符串
如果你学过shell通配符,这部分内容对你有很大帮助,当然即使没有学过,也没关系,掌握一些常用的,也会有很大帮助。
我们先简单介绍一下通配符用法:
任意一个:?、任意数量:*、任意包含[]、[^]:任意不包含
假如当前文件夹下有如下文件:
$ ls
README.md file1.txt file2.txt file3.txt file4.txt string.c string.h string.txt
看如下几个例子,可以快速帮助大家了解通配符用法。
$ ls string.?
string.c string.h
$ ls string.???
string.txt
$ ls *.txt
file1.txt file2.txt file3.txt file4.txt string.txt
$ ls string.[ch]
string.c string.h
$ ls file[1-3].txt
file1.txt file2.txt file3.txt
$ ls file[!24].txt
file1.txt file3.txt
那么看一下在python中怎么使用:
fnmatch 模块提供了两个函数—— fnmatch() 和 fnmatchcase() ,可以用来实现通配符匹配。用法如下:
from fnmatch import fnmatch, fnmatchcase
print(fnmatch('foo.txt','*.txt'))
print(fnmatch('foo.txt','?oo.txt'))
names = ['Dat1.csv', 'Dat2.csv', 'config.ini', 'foo.py']
print([name for name in names if fnmatch(name,'Dat*.csv')])

你会发现基本上和我们shell通配符用法没区别,只是借助了fnmatch()函数去实现。
2.4 字符串匹配和搜索
如果你想匹配的是字面字符串,那么你通常只需要调用基本字符串方法就行, 比如
str.find() , str.endswith() , str.startswith()
str.endswith() , str.startswith()前面讲过了。看一下str.find():
text = 'yeah, but no, but yeah, but no,but yeah'
print(text.find('no'))
返回的是下标:

text1 = '11/27/2012'
datepat = re.compile(r'\d+/\d+/\d+')
if datepat.match(text1):
print('yes')
else:
print('no')
结果是yes
这还一种是re.compile进行匹配,但是这种匹配,没什么好的,不常用,只是确定这种匹配模式存不存在,返回的是一个bool值,一般不怎么用。
实际中,下面这个方法才是用的真正比较多的:
text = 'Today is 11/27/2012. PyCon starts3/13/2013.'
res=datepat.findall(text)
print(res)
结果:

2.5 字符串替换
对于简单的字面模式,直接使用 str.repalce() 方法即可,比如:
看一个例子:
text = 'yeah, but no, but yeah, but no,but yeah'
t=text.replace('yeah', 'yep')
print(t)
运行结果:

对于复杂的,还是需要用到正则:
主要是通过re.sub实现。
import re
text = 'Today is 11/27/2012. PyCon starts 3/13/2013.'
res=re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-\1-\2',text)
print(res)
结果:

\3-\1-\2 就是我们吧原来的数据进行换位。
res=re.sub(r'(\d+)/(\d+)/(\d+)', r'\3-op-\1-\2',text)
print(res)
再看下面这个例子。注意替换都是在查询的基础上替换的

个人觉得 re.sub也不是很好用,只能处理一般的问题,太复杂的替换,还是需要大家逐步去处理好一些。
2.6 字符串忽略大小写的搜索替换
为了在文本操作时忽略大小写,只需要在使用 re 模块的时候给这些操作提供
re.IGNORECASE 标志参数。比如:
text = 'UPPER PYTHON, lower python, MixedPython'
res=re.findall('python', text, flags=re.IGNORECASE)
print(res)
res=re.sub('python', 'snake', text, flags=re.IGNORECASE)
print(res)

其实这一部分应该直接结合上一小姐一块用讲的。
2.7 最短匹配模式
看下面一段代码。
本质上,匹配模式一般会按最长匹配模型去匹配:
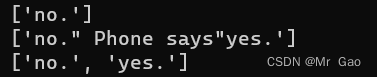
str_pat = re.compile(r'\"(.*)\"')
text1 = 'Computer says"no."'
print(str_pat.findall(text1))
text2 = 'Computer says"no." Phone says"yes."'
print(str_pat.findall(text2))

如果想改成最短匹配:
str_pat = re.compile(r'\"(.*)\"')
text1 = 'Computer says"no."'
print(str_pat.findall(text1))
text2 = 'Computer says"no." Phone says"yes."'
print(str_pat.findall(text2))
str_pat = re.compile(r'\"(.*?)\"')
print(str_pat.findall(text2))
看一下结果:
这个技巧还是挺重要的,很多时候很多人,碰到这样的问题,甚至于根本不知道该怎么去解决。
2.8 多行匹配模式
这个博主看了,这个技巧不常用,我记得有更好的方法,看一下文中的代码:
text2 = '''/* thisis a
multiline comment */'''
comment = re.compile(r'/\*((?:.|\n)*?)\*/')
print(comment.findall(text2))
结果:

其实就是在匹配串中加入\n:
((?:.|\n)*?)
正则表达式,大家可以学习学习,很实用。
2.9 将Unicode文本标准化
l
你正在处理Unicode字符串,需要确保所有字符串在底层有相同的表示。
看一下下面代码:
s1 = 'Spicy Jalape\u00f1o'
s2 = 'Spicy Jalapen\u0303o'
print(s1)
print(s2)
print(s1==s2)

其实我们的字符表示是一样的,但是由于编码问题,进行等于判断确实不相等的,这种跟底层表示有关。
怎么处理:
我们可以使用unicodedata模块先将文本标准化:
import unicodedata
t1 = unicodedata.normalize('NFC', s1)
t2 = unicodedata.normalize('NFC', s2)
print(t1 == t2)
输出为true。
2.10 在正则式中使用Unicode
这个其实听常用的的,尤其对于我们国内开发,比如汉语,藏语,等一些字符编码,我们进行正则匹配的时候,往往都是用Unicode去进行操作的,所以可以学习学习。
看一段代码:
import re
text = "我是dfas一段dfas中文字fadfa符串"
pattern = "[\u4e00-\u9fa5]+"
result = re.findall(pattern, text)
print(result)
结果如下:

2.11 删除字符串中不需要的字符
你想去掉文本字符串开头,结尾或者中间不想要的字符,比如空白。
strip() 方法能用于删除开始或结尾的字符。 lstrip() 和 rstrip() 分别从左和从右执
行删除操作。 默认情况下,这些方法会去除空白字符,但是你也可以指定其他字符。
这个方法,大家一般都会用:
如果直接使用,默认去掉空格
s = ' hello world \n'
print(s.strip())
print(s.lstrip())
print(s.rstrip('\n'))
print(s.rstrip('d \n'))
print(s.lstrip(' h'))
看结果:

这上面三个函数,能用到,但是使用范围没那么多。
replace() 方法更好一些,很多时候:
s = ' hello world \n'
print(s.replace('wo',''))

这个replace可以从任意一个位置删除字符串。
2.12 字符串对齐
这个博主也是第一次接触,没想到那么好用:
text = 'Hello World'
print(text.ljust(20))
print(text.rjust(20))
print(text.center(20))
print(text.rjust(20,'='))
print(text.center(20,'*'))
运行结果:

这个其实就是字符串补偿。
2.13 合并拼接字符串
将几个小的字符串合并为一个大的字符串。
这一部分内容不难,但是很常用:
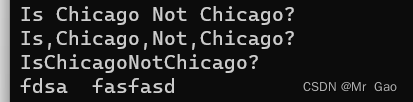
parts = ['Is', 'Chicago', 'Not', 'Chicago?']
print(' '.join(parts))
print(','.join(parts))
print(''.join(parts))
a="fdsa "
b="fasfasd"
c=a+b
print(c)
2.14 字符串中插入变量
这个梳理用的format 和format_map()实现的:
s = '{name} has {n} messages.'
re=s.format(name='Guido',n=37)
print(re)
name = 'Guido'
n = 37
re=s.format_map(vars())
print(re)
运行结果:

2.15 以指定列宽格式化字符串
这一部分内容主要是我们在处理文本段落的时候用到的:
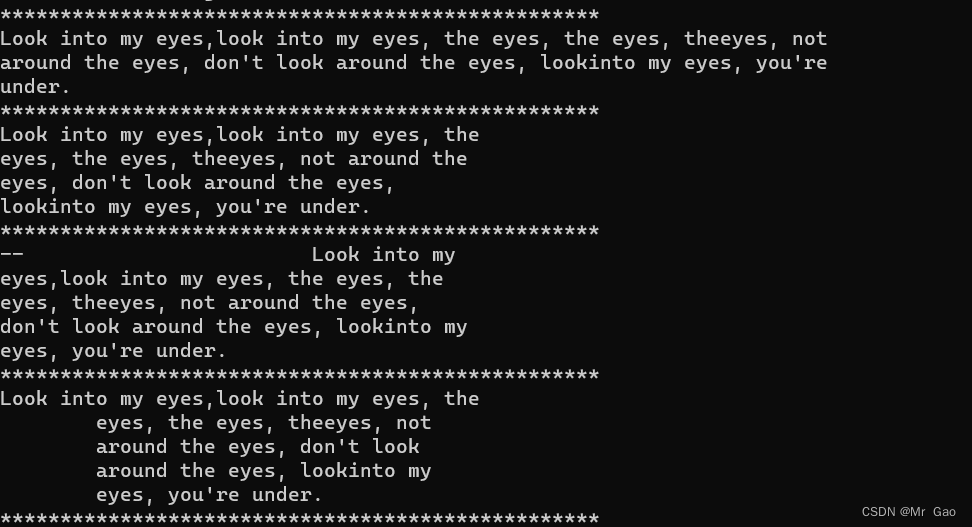
print("*"*50)
s ="Look into my eyes,look into my eyes, the eyes, the eyes, \
theeyes, not around the eyes, don't look around the eyes, \
lookinto my eyes, you're under."
import textwrap
print(textwrap.fill(s,70))
print("*"*50)
print(textwrap.fill(s,40))
print("*"*50)
print(textwrap.fill(s,40, initial_indent='-- '))
print("*"*50)
print(textwrap.fill(s,40, subsequent_indent=' '))
来看结果:
可以发现,这个其实这个是段落的一些操作。
2.16 在字符串中处理html和xml
这里我们讲一下解析html 和xml字符串的:
s = 'Spicy "Jalapeño".'
from html.parser import HTMLParser
p = HTMLParser()
print(p.unescape(s))
t = 'The prompt is>>>'
from xml.sax.saxutils import unescape
结果如下:

后面三节,博主都看了,基本上用不到,就算能用到,也可以有更好的替代方法,就不详细介绍了。














 625
625











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









