







一、What is XXL-JOB?
XXL-JOB是美团点评开源的轻量级分布式任务调度平台;
该项目于2015年11月发布第一个版本1.0,目前最新版本2.2.0;
Github:[https://github.com/xuxueli/xxl-job](https://github.com/xuxueli/xxl-job)
文档:[http://www.xuxueli.com/xxl-job/](http://www.xuxueli.com/xxl-job/)
XXL-JOB在国内线上生产环境的案例使用比较多,同时也是比较受欢迎的国产开源软件之一,https://www.oschina.net/project/top_cn_2019
XXL-JOB有多家公司线上产品在使用,有电商业务,O2O业务和大数据作业等,XXL-JOB自己的不完全统计,已接入的公司有300多家(可能还更多)
二、 XXL-JOB整体架构
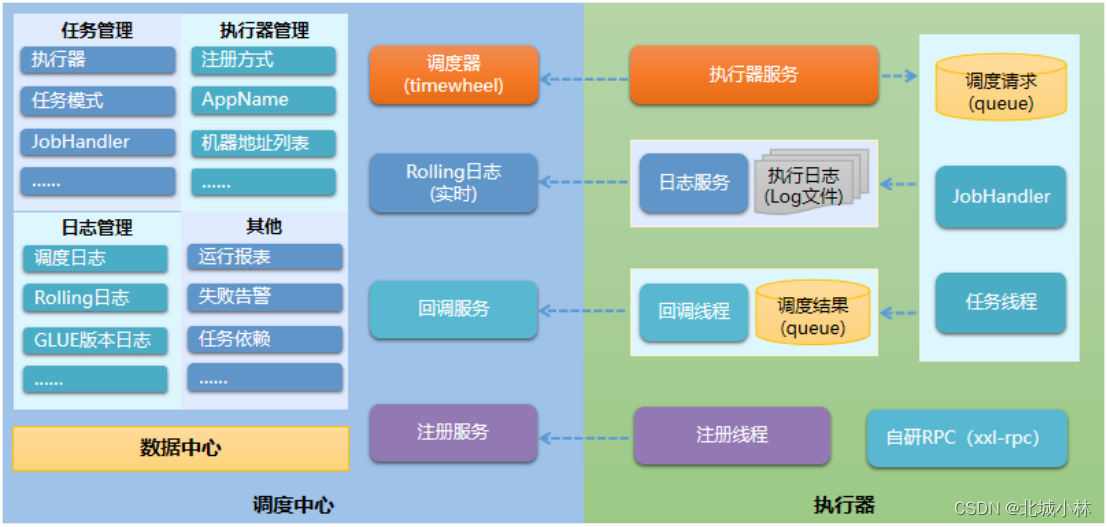
调度中心
调度中心我们可以看作是服务端,这是一个web管理后台,一个spring boot的web项目,我们需要单独部署到服务器上;
页面:
AdminLTE https://github.com/ColorlibHQ/AdminLTE
Freemarker https://freemarker.apache.org/
后端:
SpringBoot、MyBatis
执行器
执行器我们可以看作是客户端,也就是我们写的Java代码,这个代码里面执行定时任务的具体业务逻辑;
三、调度中心部署
1、从github获取项目源码https://github.com/xuxueli/xxl-job/releases;
2、从源码中doc目录下得到SQL脚本,创建和初始化数据库;
需要有权限:GRANT CREATE,EXECUTE,INSERT,SELECT,UPDATE,DELETE ON xxl_job.* TO 'mysql'@'%';
3、Maven编译打包xxl-job-admin并部署为调度中心;
4、启动运行xxl-job-admin,并访问http://localhost:8080/xxl-job-admin
默认用户名 admin,密码123456;
四、执行器开发(具体任务)
1、创建执行器,可以支持集群;
2、配置文件需要填写xxl-job注册中心地址;
3、每个具体执行job服务器需要创建一个netty连接端口号;
4、需要执行job的任务类,集成IJobHandler抽象类注册到job容器中;
5、Execute方法中编写具体job任务;
6、写一个执行器(任务:做具体的业务逻辑处理,比如发短信,对账,清理等)
访问令牌(AccessToken)
为提升系统安全性,调度中心和执行器进行安全性校验,双方AccessToken匹配才允许通讯;
调度中心和执行器,可通过配置项 “xxl.job.accessToken” 进行AccessToken的设置;
调度中心和执行器,如果需要正常通讯,只有两种设置;
- 设置一:调度中心和执行器,均不设置
AccessToken,关闭安全性校验; - 设置二:调度中心和执行器,设置了相同的
AccessToken;
五、调度中心功能菜单
1、修改密码/注销;
2、运行报表;
3、任务管理;
4、调度日志;
5、执行器管理;
6、用户管理;
7、使用教程;
六、XXL-JOB任务管理
1、执行器:
任务的绑定的执行器,任务触发调度时将会自动发现注册成功的执行器, 实现任务自动发现功能; 另一方面也可以方便的进行任务分组。每个任务必须绑定一个执行器, 可在 “执行器管理” 进行设置;
2、任务描述:
任务的描述信息,便于任务管理;
3、 Cron:
触发任务执行的Cron表达式;
4、运行模式:
- BEAN模式:
任务以JobHandler方式维护在执行器端;需要结合 “JobHandler” 属性匹配执行器中任务; - GLUE模式(Java):
任务以源码方式维护在调度中心;该模式的任务实际上是 一段继承自IJobHandler的Java类代码并 “groovy” 源码方式维护,它在 执行器项目中运行,可使用@Resource/@Autowire注入执行器里中的其他服 务; - GLUE模式(Shell):
任务以源码方式维护在调度中心;该模式的任务实际上 是一段 “shell” 脚本; - GLUE模式(Python):
任务以源码方式维护在调度中心;该模式的任务实际上 是一段 “python” 脚本; - GLUE模式(PHP):
任务以源码方式维护在调度中心;该模式的任务实际上是 一段 “php” 脚本; - GLUE模式(NodeJS):
任务以源码方式维护在调度中心;该模式的任务实际上 是一段 “nodejs” 脚本; - GLUE模式(PowerShell):
任务以源码方式维护在调度中心;该模式的任务实 际上是一段 “PowerShell” 脚本;
5、 XXL-JOB路由策略
当执行器集群部署时,XXL-JOB提供丰富的路由策略:
- 1.FIRST(第一个):固定选择第一个机器;
- 2.LAST(最后一个):固定选择最后一个机器;
- 3.ROUND(轮询):每个机器轮流执行;
- 4.RANDOM(随机):随机选择在线的机器;
- 5.CONSISTENT_HASH(一致性HASH):每个任务按照Hash算法固定选择某一台机器,且所有任务均匀散列在不同机器上;
- 6.LEAST_FREQUENTLY_USED(最不经常使用):使用频率最低的机器优先被选举;
- 7.LEAST_RECENTLY_USED(最近最久未使用):最久未使用的机器优先被选举;
- 8.FAILOVER(故障转移):按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行器并发起调度;
- 9.BUSYOVER(忙碌转移):按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标执行器并发起调度;
- 10.SHARDING_BROADCAST(分片广播):广播触发对应集群中所有机器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务;
- 抽象类ExecutorRouter

JobHandler:
运行模式为 “BEAN模式” 时生效,对应执行器中新开发的JobHandler类“@XxlJob”注解自定义的value值;
阻塞处理策略:
- 调度过于密集执行器来不及处理时的处理策略;
- 单机串行(默认):
调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行; - 丢弃后续调度:
调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败; - 覆盖之前调度:
调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务;
子任务:
每个任务都拥有一个唯一的任务ID(任务ID可以从任务列表获取),当本任务执行结束并且执行成功时,将会触发子任务ID所对应的任务的一次主动调度。
任务超时时间:
- 支持自定义任务超时时间,任务运行超时将会主动中断任务;
失败重试次数:
- 支持自定义任务失败重试次数,当任务失败时将会按照预设的失败重试次数主动进行重试;
报警邮件:
执行参数:
- 任务执行所需的参数;
六、XXL-JOB一致性Hash路由策略
一致性hash算法
一致性hash算法,是麻省理工学院1997年提出的一种算法,主要应用于分布式缓存当中,一致性hash算法可以有效地解决分布式存储结构下动态增加和删除节点所带来的问题;(不会带来大量的缓存失效)
传统的hash算法
传统的hash算法是对hash结果取余数 (hash(x) / N):对机器编号从0到N-1,按照自定义的hash算法,对每个请求的hash值按N取模得到余数i,然后将请求分发到编号为i的机器;
Hash(“abc”) % 3 = [0,1,2]
传统hash算法的缺陷
如果某一台机器宕机,那么应该落在该机器的请求就无法得到正确的处理,这时需要将宕机的服务器剔除,重新计算(hash(x) /(N-1))的值,这意味着大量缓存的失效或者数据需要转移;
宕机一台机器,会有(N-1)/N的服务器的缓存数据需要重新进行计算;
新增一台机器,会有N/(N+1)的服务器的缓存数据需要进行重新计算;
3 --> 2/3 节点缓存失效
4 --> 3/4 节点缓存失效
一致性hash算法
(hash(x) % N ) --> [0 ~ N-1]
(hash(x) % (2^32)) --> [0 ~ 2^32-1]
一致性Hash算法也是使用取模的方法,只是对2^32 取模,什么意思呢?简单来说,一致性Hash算法将整个哈希值区间组织成一个虚拟的圆环,如假设某哈希函数H的值区间为0 - 2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下:

整个区间按顺时针方向形成一个圆环,圆环正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、5、6……直到232-1,也就是说0点左侧的第一个点代表232-1, 0和232-1在零点方向重合,我们把这个由232个点组成的圆环称为Hash环;
下一步将各个服务器使用Hash算法进行哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希Hash(ip),这样每台机器就能确定其在哈希环上的位置,这里假设有四台服务器使用IP地址哈希后在环区间的位置如下:
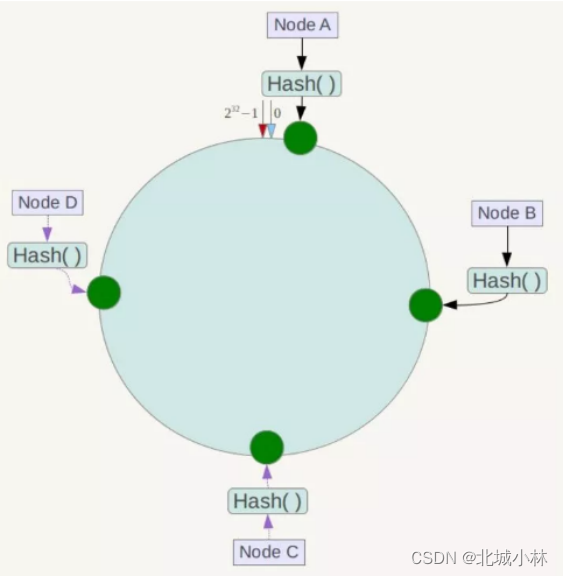
接下来使用如下算法定位数据访问到相应服务器:将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器;
例如我们有Object A、Object B、Object C、Object D四个数据对象,经哈希计算后,在环区间上的位置如下:
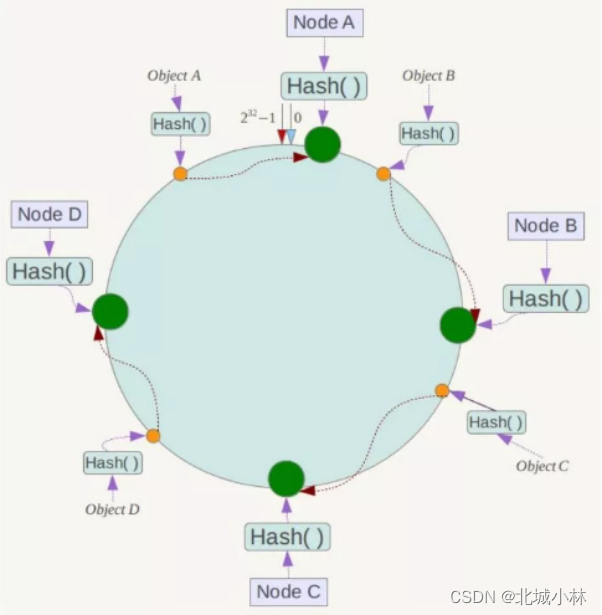
根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上;
一致性Hash算法的容错与扩容‘
现假设Node C宕机,此时对象A、B、D不会受到影响,只有C对象被重新定位到Node D,一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据不会受到影响,如下所示:’
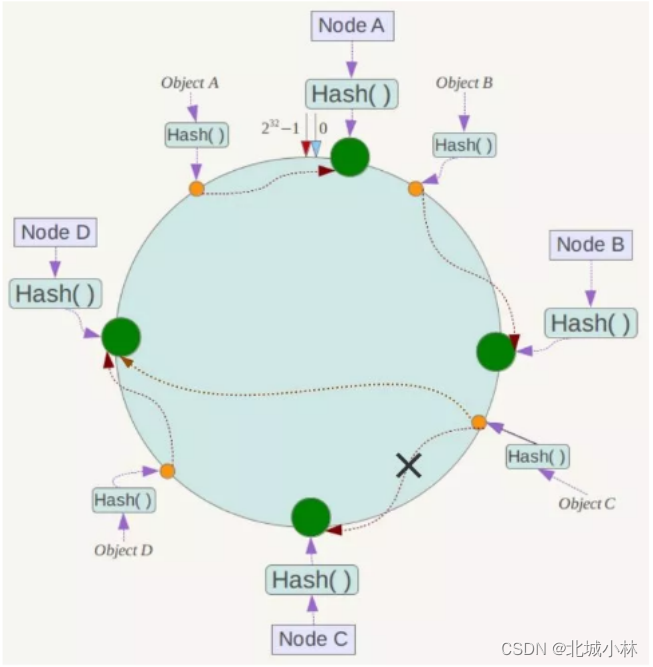
如果在系统中增加一台服务器Node X,如下图所示:
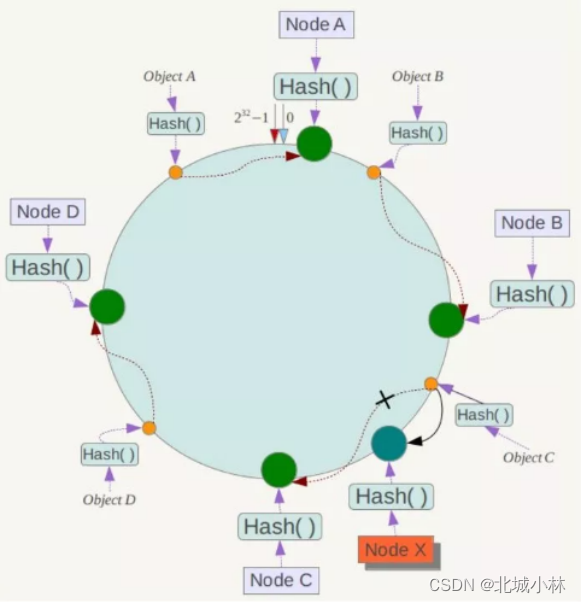
此时对象Object A、B、D不受影响,只有对象C需要重新定位到新的Node X,一般的,在一致性Hash算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响;
综上所述,一致性Hash算法对于节点的增减都只需重新定位环区间中的一小部分数据,具有较好的容错性和可扩展性;
Hash环的数据倾斜问题
一致性Hash算法在服务节点较少时,容易因为节点分布不均而造成数据倾斜问题(被缓存的数据大部分集中在某一台服务器上),比如系统中只有两台服务器,其环分布如下:

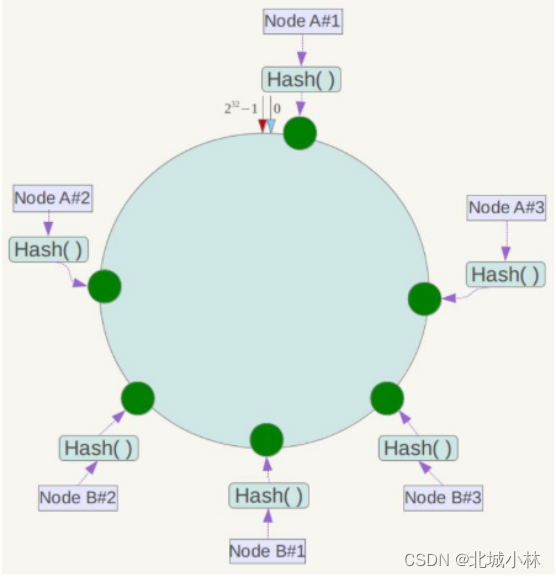
此时造成大量数据集中到Node A上,而只有极少量会定位到Node B上,为了解决这种数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点,具体做法可以在服务器IP或主机名的后面增加编号来实现。
比如可以为每台服务器计算三个虚拟节点,于是可以分别计算
“Node A#1”、“Node A#2”、“Node A#3”
“Node B#1”、“Node B#2”、“Node B#3”
的哈希值,于是形成六个虚拟节点:
Object.hashCode() apahce 工具类
同时数据定位算法不变,只是多了一步虚拟节点到实际节点的映射,如果定位到“Node A#1”、“Node A#2”、“Node A#3”三个虚拟节点的数据均定位到Node A上,这样就解决了服务节点少时数据倾斜的问题;在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布;
七、XXL-JOB分片广播路由策略
执行器集群部署时,任务路由策略选择”分片广播”情况下,一次任务调度将会广播触发对应集群中所有执行器执行一次任务,同时系统自动传递分片参数;可根据分片参数开发分片任务; index = 0,1 total = 部署了2台机器
“分片广播” 以执行器为维度进行分片,支持动态扩容执行器集群从而动态增加分片数量,协同进行业务处理;在进行大数据量业务操作时可显著提升任务处理能力和速度。
“分片广播” 和普通任务开发流程一致,不同之处在于可以获取分片参数,获取分片参数进行分片业务处理。(根据框架传过来的分片index参数,需要我们自己进行数据的分片)
举例:分片查询语句:
举例:分片查询语句:
SELECT * FROM account WHERE mod(id, #{total}) = #{index};
SELECT * FROM account WHERE sex = #{index}; --部署两台机器
Java语言任务获取分片参数方式:BEAN、GLUE模式(Java)
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
脚本语言任务获取分片参数方式:GLUE模式(Shell)、GLUE模式(Python)、GLUE模式(Nodejs)
脚本任务入参固定为三个,依次为:任务传参、分片序号、分片总数。以Shell模式任务为例,获取分片参数代码如下
echo "分片序号 index = $2"
echo "分片总数 total = $3"
分片参数属性说明:
index:当前分片序号(从0开始),执行器集群列表中当前执行器的序号;
total:总分片数,执行器集群的总机器数量;
该特性适用场景如:
1、分片任务场景:10个执行器的集群来处理10w条数据,每台机器只需要处理1w条数据,耗时降低10倍;
2、广播任务场景:广播执行器机器运行shell脚本、广播集群节点进行缓存更新等;
XXL-JOB的GLUE模式
GLUE模式(Java)
GLUE模式(Java) 的执行代码托管到调度中心在线维护,相比“Bean模式任务”需要在执行器项目开发部署上线,更加简便轻量)
前提:请确认“调度中心”和“执行器”项目已经成功部署并启动;
任务以源码方式维护在调度中心,支持通过Web IDE在线更新,实时编译和生效,因此不需要指定JobHandler。
开发任务代码:
选中指定任务,点击该任务右侧“GLUE”按钮,将会前往GLUE任务的Web IDE界面,在该界面支持对任务代码进行开发(也可以在IDE中开发完成后,复制粘贴到编辑中)。
版本回溯功能(支持30个版本的版本回溯):在GLUE任务的Web IDE界面,选择右上角下拉框“版本回溯”,会列出该GLUE的更新历史,选择相应版本即可显示该版本代码,保存后GLUE代码即回退到对应的历史版本;
GLUE模式(Shell)
该模式的任务实际上是一段 “shell” 脚本;
GLUE模式(Python)
该模式的任务实际上是一段 “python” 脚本;
GLUE模式(NodeJS)
该模式的任务实际上是一段 “nodeJS” 脚本;
GLUE模式(PHP)
同上
GLUE模式(PowerShell)
同上
“GLUE模式(Java)” 任务原理
原理:每个 “GLUE模式(Java)” 任务的代码,实际上是“一个继承自“IJobHandler”的实现类的类代码”,“执行器”接收到“调度中心”的调度请求时,会通过Groovy类加载器加载此代码,实例化成Java对象,同时注入此代码中声明的Spring服务(请确保Glue代码中的服务和类引用在“执行器”项目中存在),然后调用该对象的execute方法,执行任务逻辑。
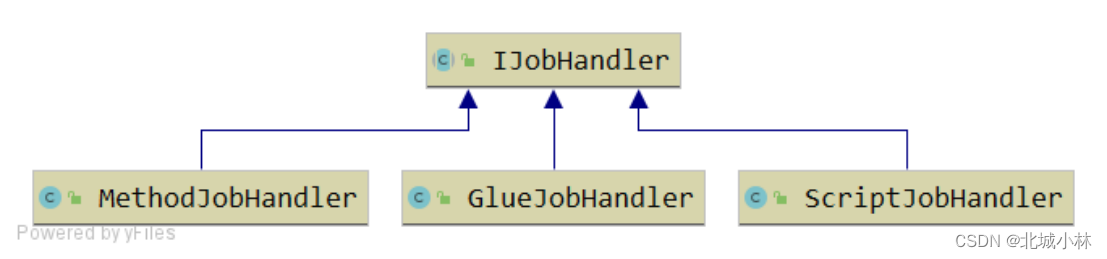
GLUE模式(Shell) + GLUE模式(Python) + GLUE模式(PHP) + GLUE模式(NodeJS) + GLUE模式(Powershell)
原理:脚本任务的源码托管在调度中心,脚本逻辑在执行器运行。当触发脚本任务时,执行器会加载脚本源码在执行器机器上生成一份脚本文件,然后通过Java代码调用该脚本;并且实时将脚本输出日志写到任务日志文件中,从而在调度中心可以实时监控脚本运行情况;
目前支持的脚本类型如下:
1.- shell脚本:任务运行模式选择为 "GLUE模式(Shell)"时支持 “Shell” 脚本任务;
2.- python脚本:任务运行模式选择为 "GLUE模式(Python)"时支持 “Python” 脚本任务;
3.- php脚本:任务运行模式选择为 "GLUE模式(PHP)"时支持 “PHP” 脚本任务;
4.- nodejs脚本:任务运行模式选择为 "GLUE模式(NodeJS)"时支持 “NodeJS” 脚本任务;
5.- powershell:任务运行模式选择为 "GLUE模式(PowerShell)"时支持 “PowerShell” 脚本任务;
执行日志:需要通过 “XxlJobLogger.log” 打印执行日志;
XXL-JOB执行器集群
执行器支持集群部署,提升调度系统可用性,同时提升任务处理能力;
执行器集群部署时,几点要求和建议:
1、执行器回调地址(xxl.job.admin.addresses)需要保持一致,执行器根据该配置进行执行器自动注册等操作。
2、同一个执行器集群内AppName(xxl.job.executor.appname)需要保持一致,调度中心根据该配置动态发现不同集群的在线执行器列表。
#XXL-JOB调度中心集群
调度中心支持集群部署,提升调度系统容灾和可用性。
调度中心支持集群部署,集群情况下各节点务必连接同一个mysql实例;
如果mysql做主从,调度中心集群节点务必强制走主库;
调度中心集群部署时,几点要求和建议:
1、DB配置保持一致;
2、集群机器时钟保持一致(单机集群忽视); ntp 时间服务
3、建议:推荐通过nginx为调度中心集群做负载均衡,分配域名。调度中心访问、执行器回调配置、调用API服务等操作均通过该域名进行;
集群登录会话保持问题?通过Cookie存放XXL_JOB_LOGIN_IDENTITY值,后端验证cookie值;
调度数据库
- xxl_job_lock:任务调度锁表;
- xxl_job_group:执行器信息表,维护任务执行器信息;
- xxl_job_info:调度扩展信息表: 用于保存XXL-JOB调度任务的扩展信息,如任务分组、任务名、机器地址、执行器、执行入参和报警邮件等等;
- xxl_job_log:调度日志表: 用于保存XXL-JOB任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等等;
- xxl_job_log_report:调度日志报表:用户存储XXL-JOB任务调度日志的报表,调度中心报表功能页面会用到;
- xxl_job_logglue:任务GLUE日志:用于保存GLUE更新历史,用于支持GLUE的版本回溯功能;
- xxl_job_registry:执行器注册表,维护在线的执行器和调度中心机器地址信息;
- xxl_job_user:系统用户表;
















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









