







一、索引的本质,数据结构

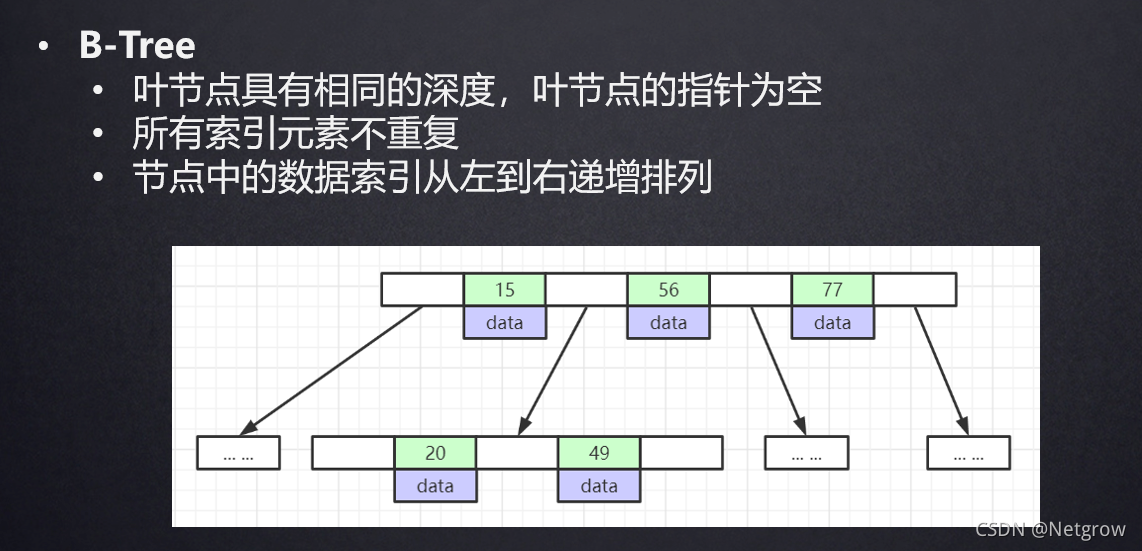
B-Tree结构
B+Tree结构
load第一次最多16kb,16384 字节。一个节点可以放1170个元素
第二层一个节点也可以放1170元素,
叶子节点data假设1kb,也可以放16kb。
所有元素个数为1170117016,大概2000多万的数据索引,数据高度仅仅为3。
在ram中查找速度相较于一次磁盘IO可以忽略不计。
第一层第二层可以常驻ram,这样时间就主要耗费在load叶子节点。
B树非叶子节点也存储了data,存储同样的数据,树的高度会远高于B+Tree
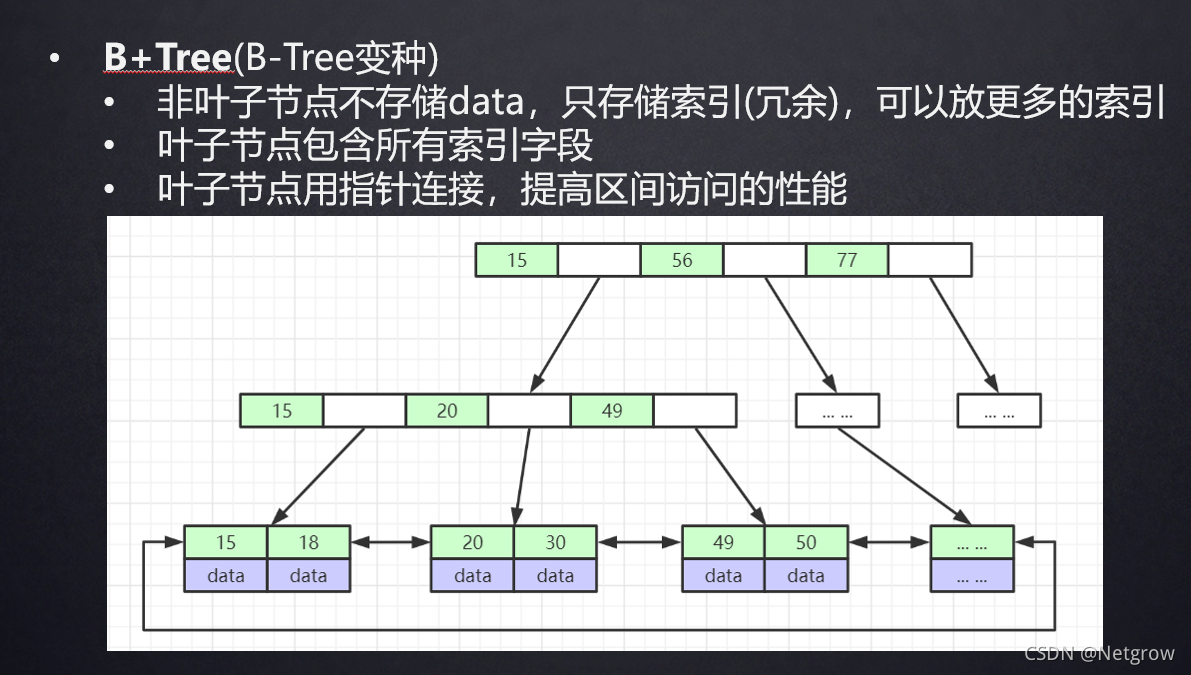
B+树叶子节点的连接前后的指针可以支持范围查找,叶子节点是有序的,
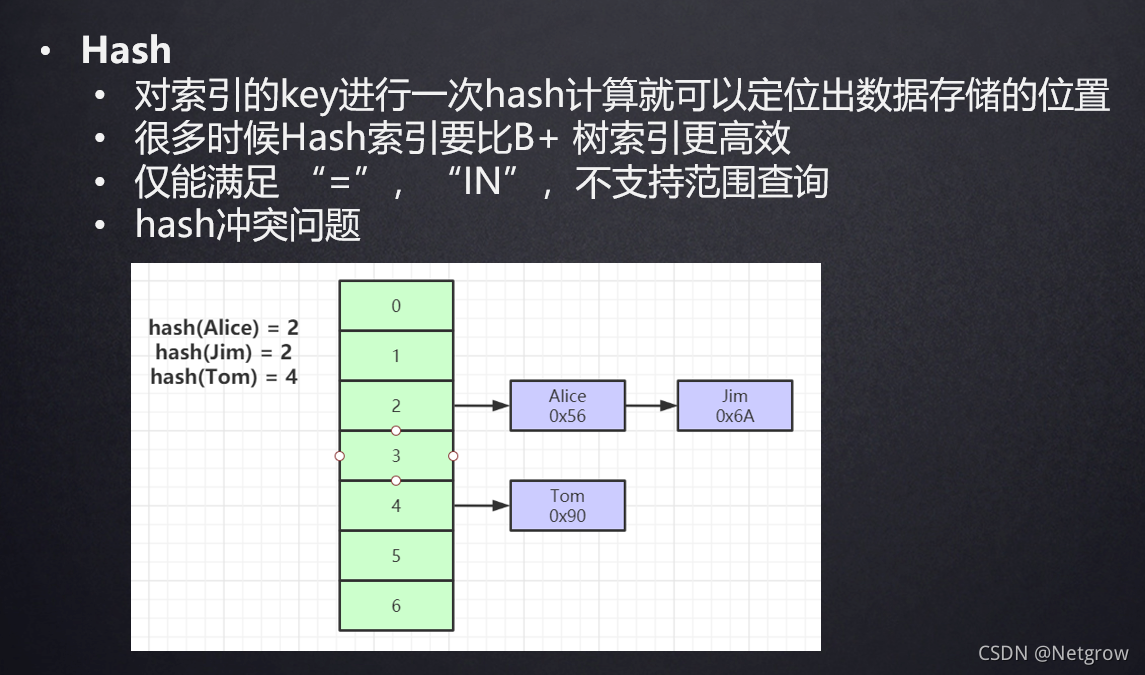
hash结构
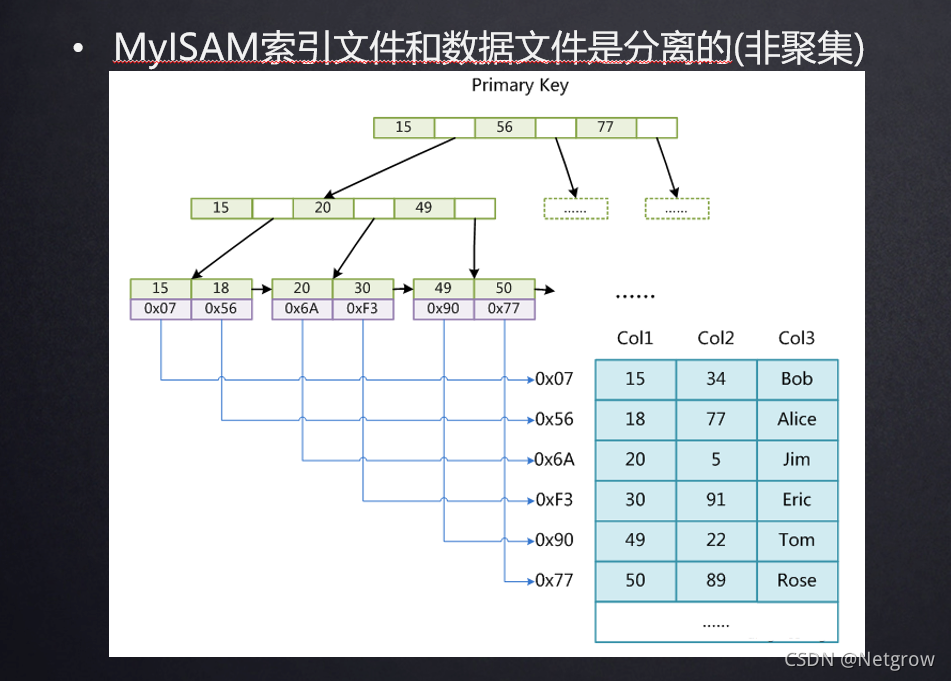
MyISAM存储引擎索引实现
InnoDB存储引擎索引实现
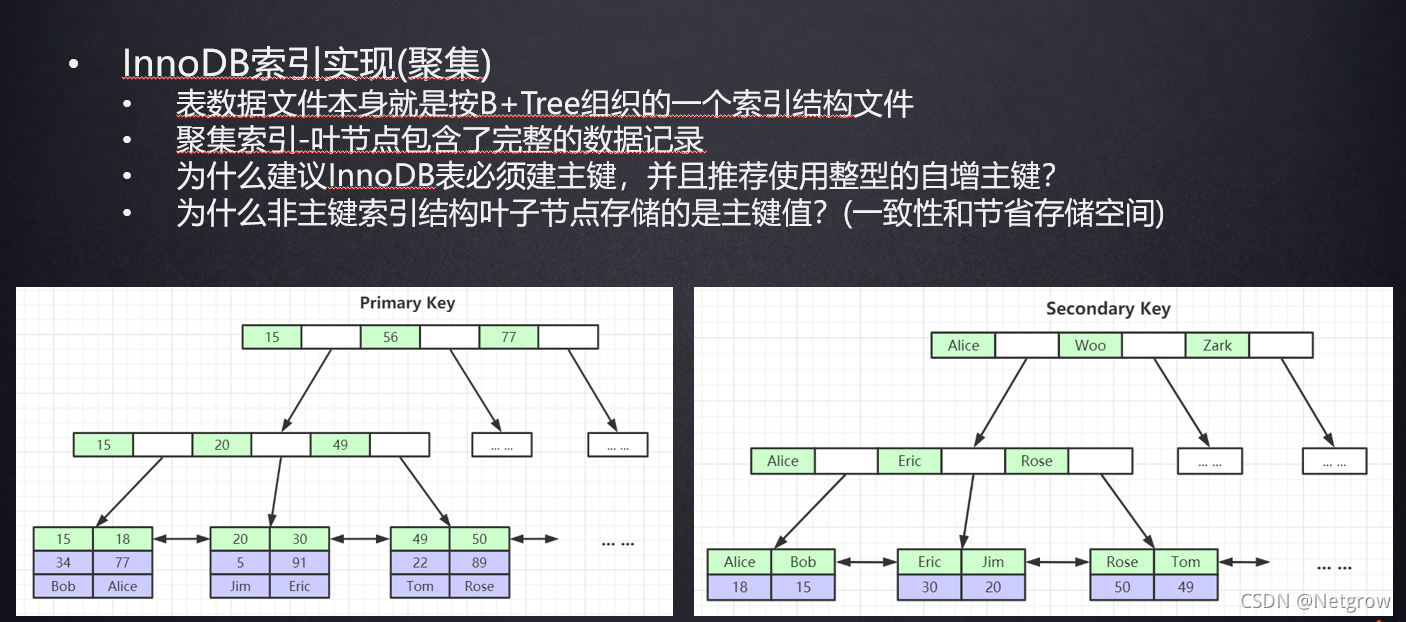
ibd文件设计的时候必须用一颗B+Tree来组织,如果有主键会自动构建索引,如果没有主键就会挑选一条没有重复元素列来构建B+Tree,如果没有这条列,那么就会创建一个隐藏列来构建。
uuid和整形的自增主键
uuid是字符串比较效率低,整形的占用空间也比较小。
为什么DBA推荐使用整形的自增主键?
B+Tree叶子层元素是排好序的,如果是自增的新插入的元素会被放在最后面,如果是无须的会产生很多冗余节点改变树的结构(分裂、平衡)效率低。
为什么非主键索引结构叶子节点存储的是主键值?(一致性和节省空间)
二级索引不把所有数据都放入叶子节点。如果放很多数据,存储空间会很大。
如果哪里插入失败会出问题,减少复杂度。
如果字段太多,索引不够用就需要建立二级索引。
索引最左前缀原理
联合索引底层数据结构长什么样?
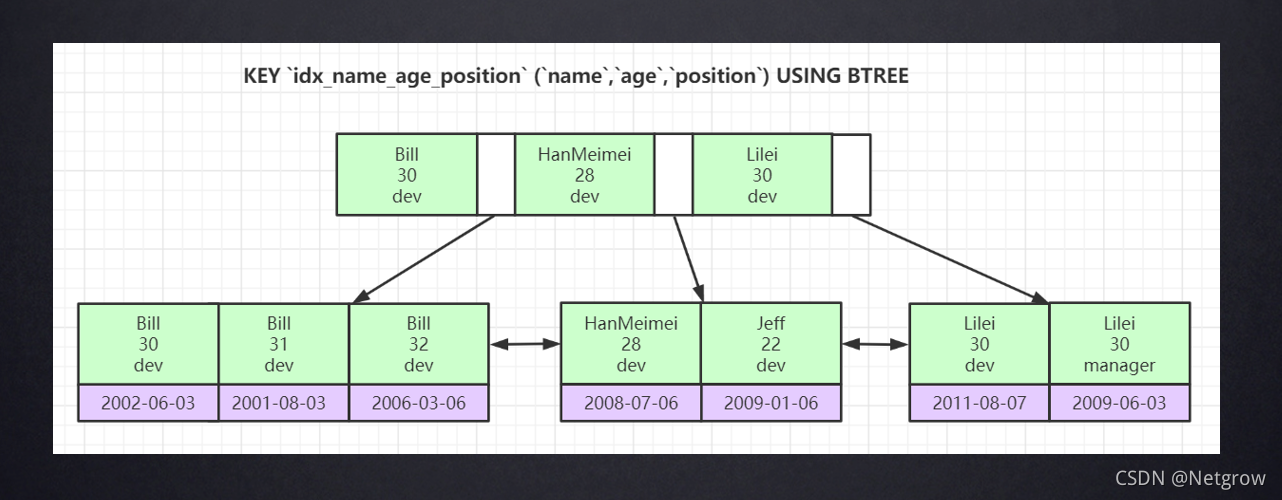
通过字段给主键排序,如果第一个字段会排好序就不看下一个字段,第一个字段相等看下一个字段。辅助索引如果所有字段都相等排在一起,根据主键回表查询元素。

只有第一条sql语句走索引,联合索引要按照顺序去使用。
联合索引只有前面是排好序的后面才是排好序的,如果跳过第一个索引,后面的索引在整张表中不是排好序的,所以需要全表扫描才能找到想要的元素。
联合索引:
多个字段构成一个索引。想办法通过两到三个联合索引把所有条件包括。















 2305
2305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









