







WordCloud-安装与应用
- 配置
pip镜像源
# 临时下载镜像
pip install 【替换为所需要安装库名称】 -i https://pypi.douban.com/simple/
# 永久设置(python版本需高于3.5+) 链接地址可替换
pip config set global.index-url https://pypi.douban.com/simple/
# 可选择如下镜像链接以提高下载速度
# 阿里云
http://mirrors.aliyun.com/pypi/simple/
# 清华大学
https://pypi.tuna.tsinghua.edu.cn/simple/
# 中国科技大学
https://pypi.mirrors.ustc.edu.cn/simple/
# 中国科学技术大学
http://pypi.mirrors.ustc.edu.cn/simple/
# 豆瓣
https://pypi.douban.com/simple/
-
确认安装
python版本安装版本确定,尽可能选择高版本( python3.5不支持config参数)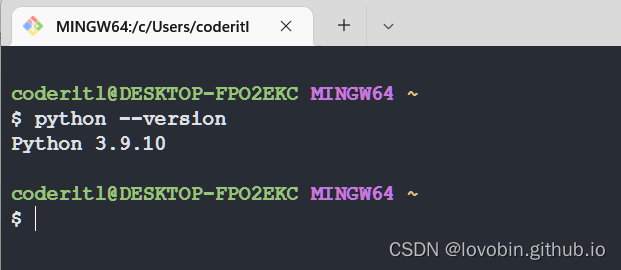
wordcloud
wordcloud
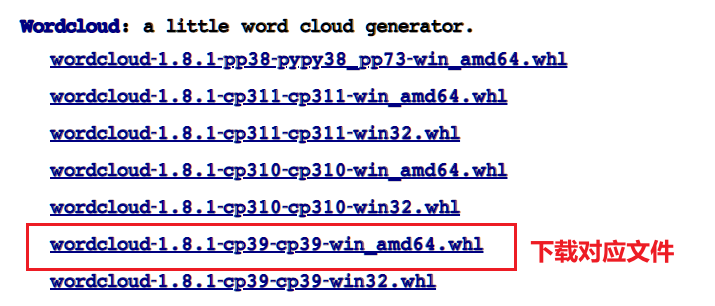
# 由于版本问题直接安装报错,可痛过如下地址下载 wheel
https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud
| 选择对应版本下载 | 下载为python3.9,放在需要启动的项目处 |
|---|---|
 |  |
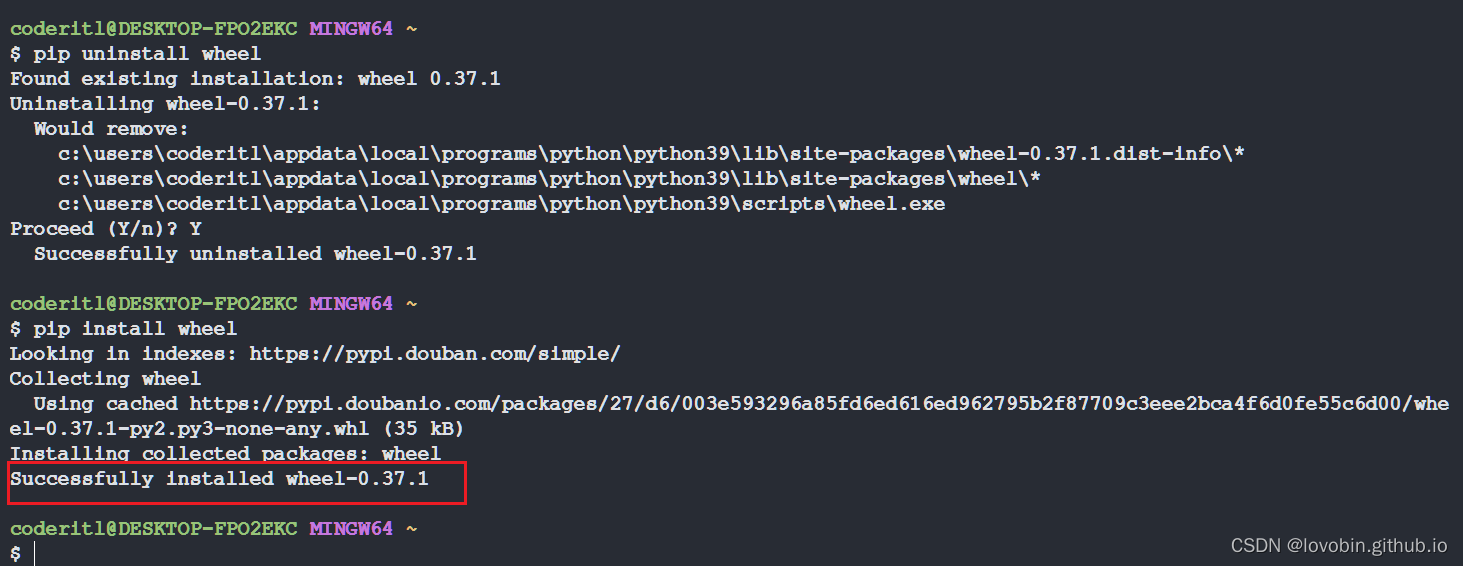
wheel
# wheel 是 Python生态系统的一个组件,它有助于使包的安装工作正常进行。它们允许更快的安装和更稳定的包分发过程。
pip install wheel
wheel |
|---|
 |
-
打开一个项目(启动时会随机启动
虚拟环境或者是运行环境,安装在当前运行环境下,wordcloud将可用)wordcloud安装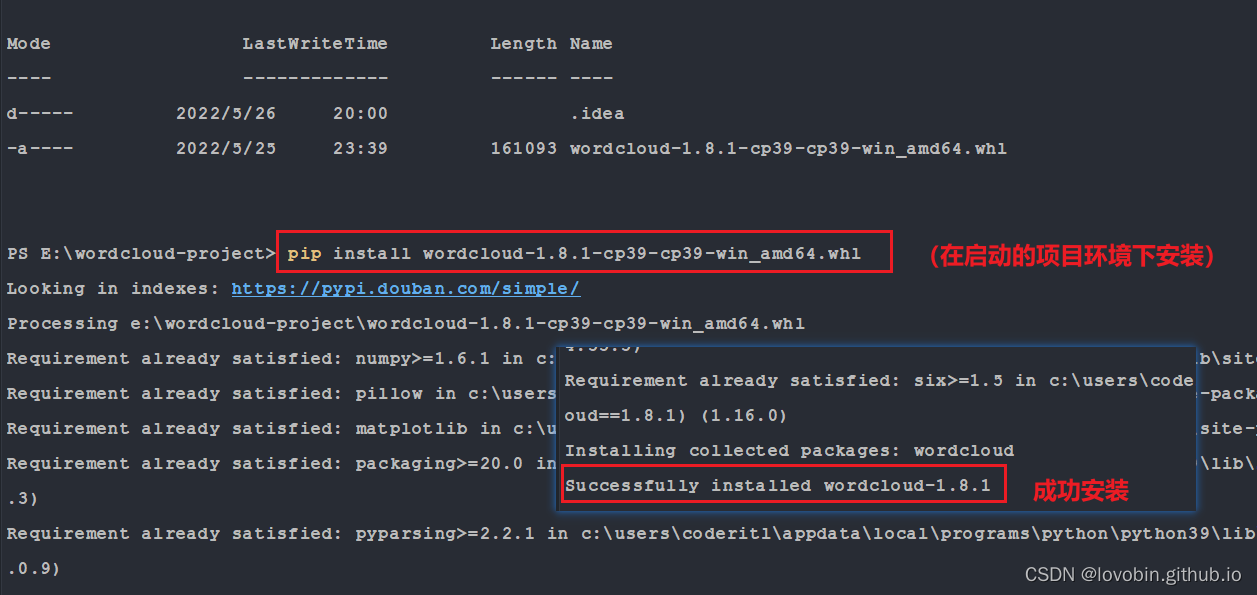
-
使用测试
wordcloud使用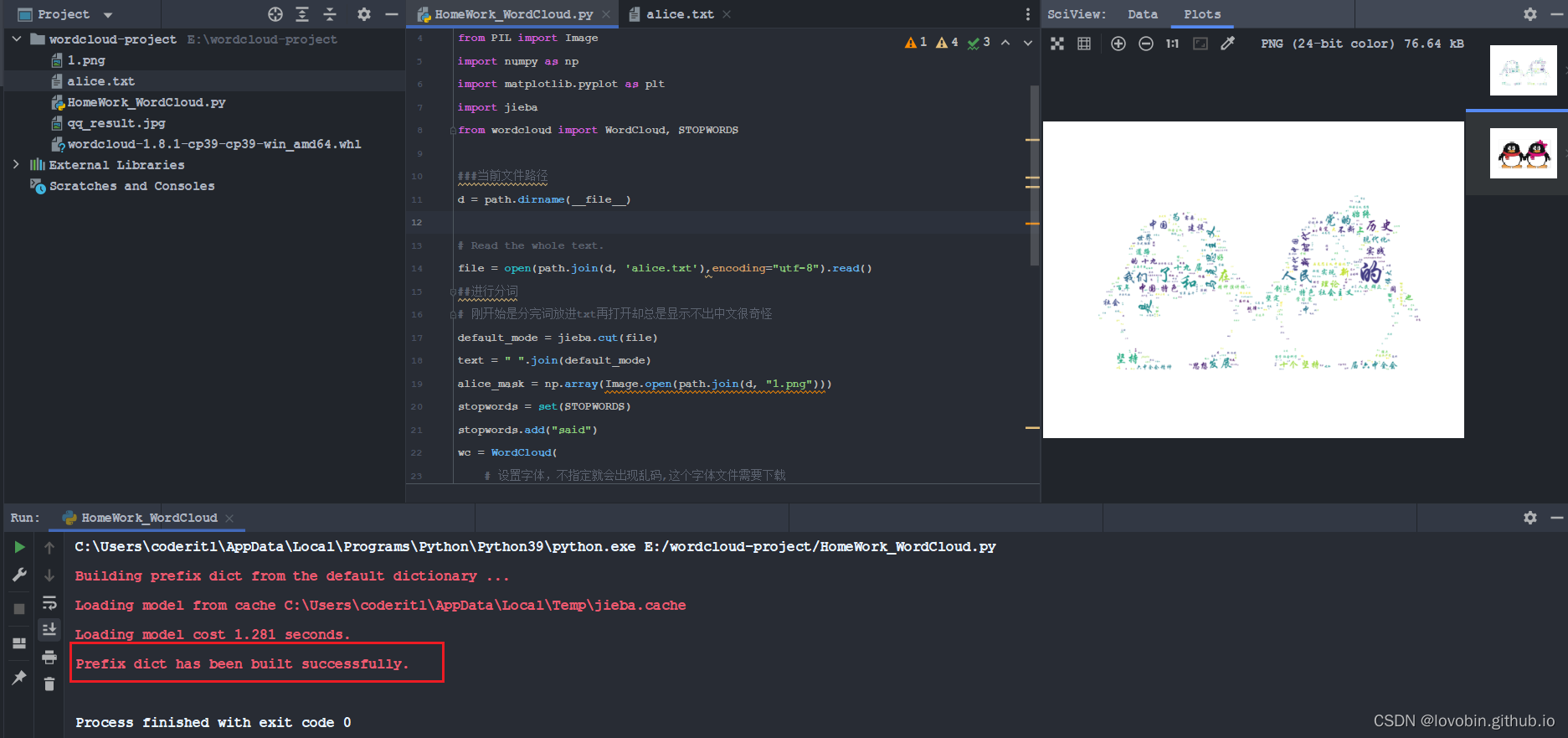
-
词云图(原始素材图需要为
png)词云分析结果 
-
jieba
- 安装
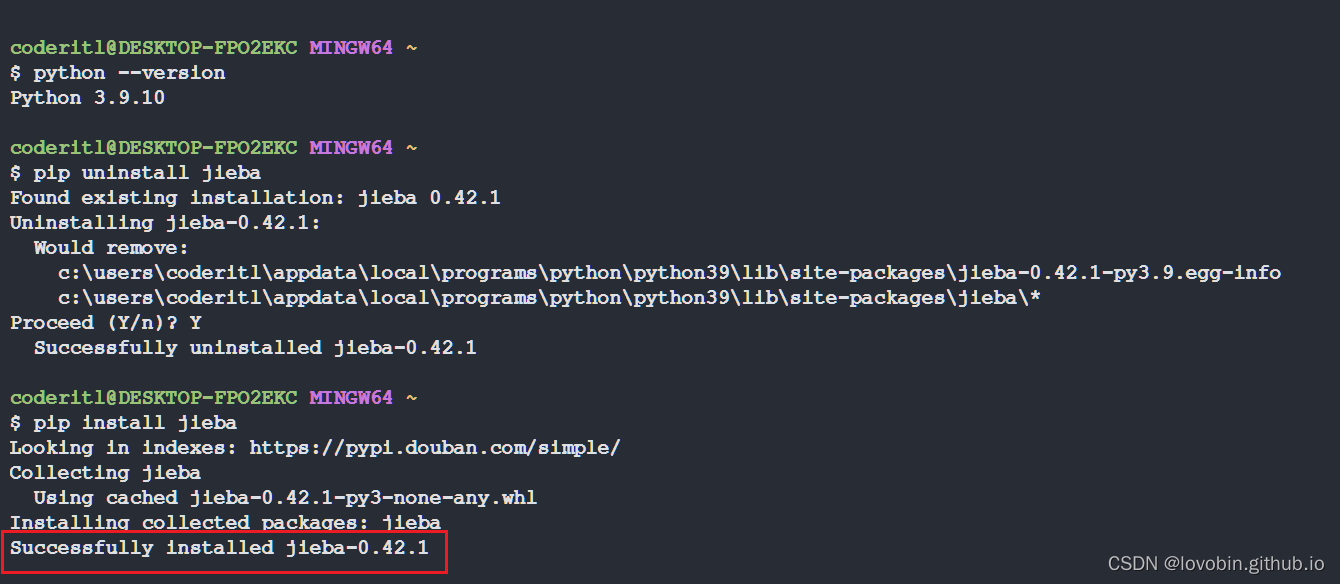
jieba库
pip install jieba
jieba库安装 | |
|---|---|
 |
jieba.cut方法接受三个输入参数: 需要分词的字符串;cut_all参数用来控制是否采用全模式;HMM参数用来控制是否使用HMM模型jieba.cut_for_search方法接受两个参数:需要分词的字符串;是否使用HMM模型。该方法适合用于搜索引擎构建倒排索引的分词,粒度比较细- 待分词的字符串可以是
unicode或UTF-8字符串、GBK字符串。注意:不建议直接输入GBK字符串,可能无法预料地错误解码成 UTF-8 jieba.cut以及jieba.cut_for_search返回的结构都是一个可迭代的generator,可以使用for循环来获得分词后得到的每一个词语(unicode),或者用jieba.lcut以及jieba.lcut_for_search直接返回listjieba.Tokenizer(dictionary=DEFAULT_DICT)新建自定义分词器,可用于同时使用不同词典。jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射。














 488
488











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









