







布隆过滤器的使用场景
在redis缓存的那篇文章中,讲到了出现缓存穿透的时候,因为redis和数据库都没有数据,所以如果出现大量的空返回,这样无意义的值,大量的查询打到redis和数据库当中,会对两者的性能产生较大的性能影响。所以在这里我们使用布隆过滤器(bloom filter)在进入redis查询前来判断所要查询的数据是否存在。下面介绍一下bloom filter实现原理。
布隆过滤器实现原理
首先布隆过滤器要有1个二进制数组,然后准备一批预计要插入的数据,指定一些哈希函数。
我们假设输入对象个数为n,bitarray大小(也就是布隆过滤器大小)为m,然后将得到的key值根据哈希函数进行哈希计算,每次结果得到的值作为数组索引标识置bitarray对应位置为1,然后下次进行判断当前key是否存在于redis当中时,就可以根据hash函数进行哈希,然后去bitarray数组中判断每次哈希的结果在数组对应位置其值是否为1,只有全部为1时,才认为redis中含有数据,否则可以直接返回。这样请求就不会达到redis数据查询和数据库中。
这里需要注意布隆过滤器我推荐部署在一个单独的redis实例中,作为缓存的拦截器进行拦截过滤,当然这样相应的也会增加网络开销,当然布隆过滤器还有其他的方式,比如guava的内存布隆过滤器,当然它的缺点也很明显,就是内存的大小限制了它的使用,比如我们要存一个接近50G的数据,全部放在内存中,然后利用bloom filter判断数据是否存在,这样很明显有些过于浪费,如果是使用java,那么一般情况下内存大小也没有这么大,而且这只是一个功能而已。
当然也可以利用分布式redis布隆过滤器,用来支持大容量数据的判断,但是这个缺点也很明显,就是对于性能的影响,比如更大的网络开销,我们还要做额外的二次哈希,来将判断请求达到已经存在的节点,当然也可以使用pipeline的方式。
布隆过滤器的误差
布隆过滤器的误差,大家有没有想过,如果一个key计算的哈希值,被其他多个键计算的哈希值占用,那么就会进行误判,认为这个key会存在。而布隆过滤器的误判率,与我们设定的bitarray的数组大小,还有所预设的key的数量有关。
下面是公式:
 这里重点介绍n个元素,依然为0的概率计算,是因为n个元素同时为0,所以需要进行乘运算,然后根据此,可以计算都被设置为1的概率。
这里重点介绍n个元素,依然为0的概率计算,是因为n个元素同时为0,所以需要进行乘运算,然后根据此,可以计算都被设置为1的概率。
算出被设置为1的概率后,由此可以得到命中的概率:
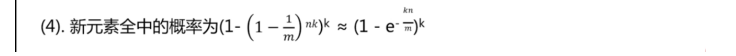 新元素全中的概率就是什么时间数组全部被置为1,这样就开始产生误判,所以第四条也可以称为bloom filter过滤器误差率的计算。
新元素全中的概率就是什么时间数组全部被置为1,这样就开始产生误判,所以第四条也可以称为bloom filter过滤器误差率的计算。















 3425
3425











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









