






按评估RAG系统的目的分类
一、检索性能评估 (Retrieval Performance Evaluation)
目标:衡量检索器在获取相关信息方面的有效性和准确度
- Recall:
其中:
TP(True Positive)是模型正确识别的正例数量。
FN(False Negative)是模型错误识别的正例数量,即实际为正例但模型预测为负例的数量。
输入:
TP(True Positive)的数量。
FN(False Negative)的数量。
输出:
Recall的值,范围从0到1,表示模型在所有实际正例中正确识别正例的比例。
- Recall@k
其中:
R 是相关文档的总数。
rel(i) 是一个指示函数,如果第 i 个结果是相关的,则 rel(i)=1,否则为 0。
输入
相关文档总数 R:实际存在的相关文档总数。
前 k 个检索结果:模型返回的前 k 个结果。
相关性标记:对于每个检索结果,标记其是否为相关文档。
输出
Recall@k 的值:范围从 0 到 1,值越高表示在前 k 个结果中捕获的相关文档比例越高
- Precision@k
其中:
k 是考虑的检索结果数量。
rel(i) 是一个指示函数,如果第 i 个结果是相关的,则 rel(i)=1,否则为 0。
输入
前 k 个检索结果:模型返回的前 k 个结果。
相关性标记:对于每个检索结果,标记其是否为相关文档。
输出
Precision@k 的值:范围从 0 到 1,值越高表示在前 k 个结果中相关文档的比例越高。
- NDCG (Normalized Discounted Cumulative Gain)
其中:
DCG@K(Discounted Cumulative Gain):折扣累积增益,用于衡量前 K 个结果的相关性得分。计算公式为:
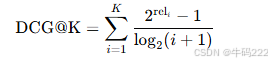
其中,reli 是第 i 个结果的相关性得分。
iDCG@K(Ideal Discounted Cumulative Gain):理想折扣累积增益,即在前 K 个结果中,按照相关性得分从高到低排序时的最大可能 DCG 值。
输入
相关性得分列表:每个结果的相关性得分。
K:考虑的前 K 个结果数量。
输出
NDCG@K 的值:范围从 0 到 1。值越接近 1,表示排序结果越接近理想状态
- MRR (Mean Reciprocal Rank)
其中:
n 是查询的总数。
ranki 是第 i 个查询的正确结果在排序列表中的位置。
输入
查询列表:每个查询的正确结果在排序列表中的位置。
输出
MRR 的值:范围从 0 到 1。值越高,表示正确结果的平均位置越靠前
- Top-1/5/20 Accuracy
其中:
Number of correct predictions in top-k:在前 k 个预测结果中正确的预测数量。
Total number of predictions:总预测数量。
输入
预测结果列表:模型对每个样本的前 k 个预测结果。
实际结果列表:每个样本的实际结果。
输出
Top-k Accuracy 的值:范围从 0 到 1。值越高,表示在前 k 个预测结果中正确的预测比例越高
- Search Recall
其中:
Number of relevant documents retrieved:检索到的相关文档数量。
Total number of relevant documents:所有相关文档的总数。
输入
检索结果列表:模型返回的检索结果。
相关性标记:每个文档是否为相关文档的标记。
输出
Search Recall 的值:范围从 0 到 1。值越高,表示检索到的相关文档比例越高。
- Citation Recall / Precision
Citation Recall(引用召回率):
Citation Precision(引用精确率):
其中:
Number of relevant citations retrieved:检索到的相关引用数量。
Total number of relevant citations:所有相关引用的总数。
Total number of citations retrieved:检索到的引用总数。
输入
检索结果列表:检索到的引用列表。
相关性标记:每个引用是否为相关引用的标记。
输出
Citation Recall 的值:范围从 0 到 1。值越高,表示检索到的相关引用比例越高。
Citation Precision 的值:范围从 0 到 1。值越高,表示检索到的引用中相关引用的比例越高
- Key-facts Recall / Precision
Key-facts Recall(关键事实召回率):
Key-facts Precision(关键事实精确率):
其中:
Number of relevant key-facts retrieved:检索到的相关关键事实的数量。
Total number of relevant key-facts:所有相关关键事实的总数。
Total number of key-facts retrieved:检索到的关键事实的总数。
输入
检索结果列表:检索到的关键事实列表。
相关性标记:每个关键事实是否为相关的标记。
输出
Key-facts Recall 的值:范围从 0 到 1。值越高,表示检索到的相关关键事实的比例越高。
Key-facts Precision 的值:范围从 0 到 1。值越高,表示检索到的关键事实中相关事实的比例越高
二、生成质量评估 (Generation Quality Evaluation)
目标:衡量生成文本的正确性、完整性和流畅度
- EM (Exact Match)
其中:
Number of exact matches:完全匹配的样本数量。
Total number of samples:总样本数量。
输入
预测结果列表:模型对每个样本的预测结果。
真实结果列表:每个样本的真实结果。
输出
EM 的值:范围从 0 到 1。值越高,表示完全匹配的样本比例越高。
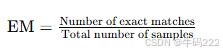
- F1 Score
其中:
Precision:精确率,即模型预测为正例的样本中实际为正例的比例。
Recall:召回率,即模型正确识别的正例数量占所有实际正例数量的比例。
输入
TP(True Positive):模型正确识别的正例数量。
FP(False Positive):模型错误识别的正例数量,即实际为负例但模型预测为正例的数量。
FN(False Negative):模型错误识别的正例数量,即实际为正例但模型预测为负例的数量。
输出
F1 Score 的值:范围从 0 到 1。值越高,表示模型的精确率和召回率的平衡越好
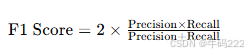
- Accuracy
其中:
Number of correct predictions:模型正确预测的样本数量。
Total number of predictions:总样本数量。
输入
预测结果列表:模型对每个样本的预测结果。
真实结果列表:每个样本的真实结果。
输出
Accuracy 的值:范围从 0 到 1。值越高,表示模型正确预测的比例越高
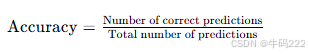
- BLEU
BLEU 是一种用于评估机器翻译质量的指标,主要通过比较机器翻译结果与参考翻译之间的 n-gram 精确匹配来计算。其公式较为复杂,以下是其核心计算步骤:
计算 n-gram 精确率:
计算 BLEU 分数:
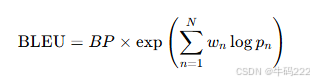
其中:
BP 是Brevity Penalty(简短惩罚),用于惩罚过短的翻译结果,计算公式为:
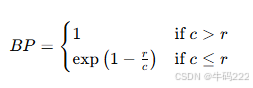
其中 c 是候选翻译的长度,r 是参考翻译的长度。
wn 是 n-gram 的权重,通常 wn=N1(假设所有 n-gram 的权重相等)。
N 是最高 n-gram 的阶数,通常取 N=4。
输入
候选翻译:机器翻译生成的翻译结果。
参考翻译:人工翻译的参考结果,可以有多个。
最高 n-gram 阶数:通常取 N=4。
输出
BLEU 的值:范围从 0 到 1。值越高,表示候选翻译与参考翻译的匹配度越高。
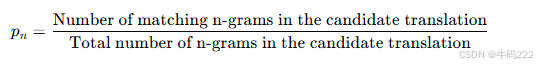
- ROUGE (ROUGE-1, ROUGE-2, ROUGE-L)
其中:
W 是参考摘要中的所有单词集合。
cw(x) 是候选摘要中单词 w 的出现次数。
cw(r) 是参考摘要中单词 w 的出现次数。
输入:
候选摘要(机器生成的文本)。
参考摘要(人工编写的文本)。
输出:
ROUGE-1 的值,范围从 0 到 1,值越高表示候选摘要与参考摘要的单词重合度越高。
ROUGE-2
公式:
其中:
W2 是参考摘要中的所有二元组(2-gram)集合。
cw2(x) 是候选摘要中二元组 w2 的出现次数。
cw2(r) 是参考摘要中二元组 w2 的出现次数。
输入:
候选摘要(机器生成的文本)。
参考摘要(人工编写的文本)。
输出:
ROUGE-2 的值,范围从 0 到 1,值越高表示候选摘要与参考摘要的二元组重合度越高。
ROUGE-L
公式:
其中:
LCS(x,r) 是候选摘要 x 和参考摘要 r 之间的最长公共子序列(LCS)的长度。
∣x∣ 和 ∣r∣ 分别是候选摘要和参考摘要的长度。
输入:
候选摘要(机器生成的文本)。
参考摘要(人工编写的文本)。
输出:
ROUGE-L 的值,范围从 0 到 1,值越高表示候选摘要与参考摘要的最长公共子序列越长
- BERTScore
BERTScore 的计算基于预训练语言模型(如 BERT)的词嵌入。具体计算步骤如下:
计算词嵌入:
对于候选文本 C 和参考文本 R,使用预训练模型(如 BERT)提取每个词的嵌入向量。
设 ec 和 er 分别为候选文本和参考文本中词的嵌入向量集合。
计算相似度矩阵:
计算候选文本中的每个词与参考文本中每个词的余弦相似度,形成相似度矩阵 S:
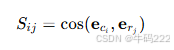
其中,eci 是候选文本中第 i 个词的嵌入,erj 是参考文本中第 j 个词的嵌入。
计算 Precision、Recall 和 F1 Score:
Precision(P):候选文本中每个词与参考文本中最近词的相似度的平均值:
Recall(R):参考文本中每个词与候选文本中最近词的相似度的平均值:
F1 Score(F1):Precision 和 Recall 的调和平均值:
输入
候选文本:机器生成的文本。
参考文本:人工编写的参考文本。
预训练模型:用于提取词嵌入的预训练模型(如 BERT、RoBERTa 等)。
语言:文本的语言(如
en表示英语,zh表示中文)。输出
Precision(P):范围从 0 到 1,值越高表示候选文本中的词与参考文本越相似。
Recall(R):范围从 0 到 1,值越高表示参考文本中的词在候选文本中被匹配得越好。
F1 Score(F1):范围从 0 到 1,值越高表示候选文本和参考文本的语义相似性越高。
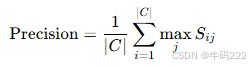
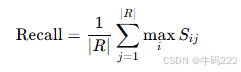
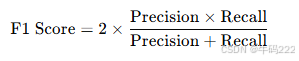
- FActScore
FActScore 的计算基于生成文本中“原子事实”(Atomic Facts)的真实性和覆盖范围。具体公式如下:
原子事实提取:
将生成文本 G 分解为一系列原子事实 {f1,f2,…,fn}。
每个原子事实 fi 是一个简短的陈述,只包含一条信息。
事实验证:
对于每个原子事实 fi,使用知识源(如维基百科)验证其真实性。
设 V(fi) 为原子事实 fi 的验证结果,如果 fi 是真实的,则 V(fi)=1,否则 V(fi)=0。
计算 FActScore:
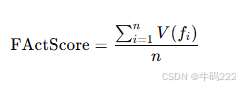
其中:
n 是生成文本中提取的原子事实总数。
是验证为真实的原子事实数量。
输入
生成文本:模型生成的长篇文本。
知识源:用于验证原子事实真实性的可靠知识库(如维基百科)。
语言:文本的语言(如英语、中文)。
输出
FActScore 的值:范围从 0 到 1,值越高表示生成文本中的事实越准确
- MAUVE
MAUVE(Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers)通过计算生成文本与人类文本之间的分布差异来衡量生成文本的质量。其核心公式如下:
混合分布:
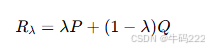
其中:
P 是真实文本的分布。
Q 是生成文本的分布。
λ 是一个参数,控制混合比例。
KL 散度计算:
曲线绘制与面积计算:
通过滑动参数 λ 从 0 到 1,绘制 DKL(P∥Rλ) 和 DKL(Q∥Rλ) 的曲线。
计算该曲线下的面积 A,作为 MAUVE 的最终得分。
输入
生成文本:模型生成的文本数据。
真实文本:人类编写的参考文本数据。
预训练语言模型:用于提取文本特征的预训练模型(如 BERT、RoBERTa 等)。
参数 λ:控制混合比例的参数,通常在 0 到 1 之间滑动。
输出
MAUVE 的值:范围从 0 到 1,值越接近 1,表示生成文本与真实文本的分布越接近,生成质量越高。
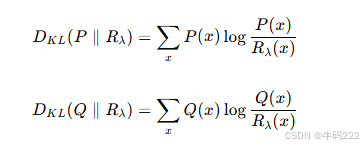
- Edit Similarity (ES)
Edit Similarity(ES)是一种基于编辑距离(Edit Distance)的相似度度量方法,用于衡量两个字符串之间的相似性。其公式如下:
其中:
Edit Distance(s1,s2) 是将字符串 s1 转换为字符串 s2 所需的最少编辑操作数(包括插入、删除和替换操作)。
len(s1) 和 len(s2) 分别是字符串 s1 和 s2 的长度。
输入
字符串 s1:第一个字符串。
字符串 s2:第二个字符串。
输出
Edit Similarity 的值:范围从 0 到 1。值越接近 1,表示两个字符串越相似

- LLM Score
LLM Score 并不是一个单一的固定公式,而是多种评估指标的集合,用于综合评估大语言模型(LLM)的性能。常见的评估指标包括:
答案相关性(Answer Relevancy):
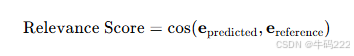
其中,epredicted 和 ereference 分别是预测答案和参考答案的嵌入向量。
正确性(Correctness): 通过比对模型生成的内容与已知的真实信息来计算,通常使用事实核查API。
幻觉检测(Hallucination Detection): 检测模型是否生成了虚假或不准确的信息,通常通过人工审核或自动化工具实现。
上下文相关性(Contextual Relevancy):
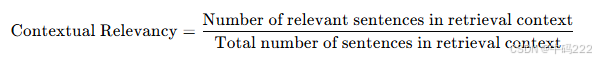
评估检索上下文中与输入相关的句子比例。
上下文精度(Contextual Precision):

评估检索上下文中相关节点的比例。
上下文召回率(Contextual Recall):
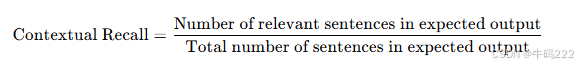
评估预期输出中可以归因于检索上下文中的节点的句子比例。
输入
模型输出:LLM生成的文本。
参考文本:人工编写的参考文本或已知的真实信息。
检索上下文:与输入相关的上下文信息。
预训练模型:用于嵌入向量计算的预训练模型(如 BERT、MiniLM 等)。
输出
答案相关性得分:范围从 0 到 1,值越高表示预测答案与参考答案越相似。
正确性得分:布尔值,表示模型输出是否符合事实。
幻觉检测结果:布尔值,表示模型输出是否包含幻觉。
上下文相关性得分:范围从 0 到 1,值越高表示检索上下文与输入越相关。
上下文精度得分:范围从 0 到 1,值越高表示检索上下文中的相关节点比例越高。
上下文召回率得分:范围从 0 到 1,值越高表示预期输出中与检索上下文相关的句子比例越高
- Hit Rate
Hit Rate 是一种用于评估推荐系统或检索系统性能的指标,衡量系统返回的结果中包含相关项的比例。其公式如下:
其中:
Number of queries with at least one relevant result:在所有查询中,至少有一个结果是相关的查询数量。
Total number of queries:总查询数量。
输入
查询列表:每个查询及其对应的检索结果。
相关性标记:每个检索结果是否为相关结果的标记。
输出
Hit Rate 的值:范围从 0 到 1。值越高,表示系统在更多查询中返回了相关结果,性能越好
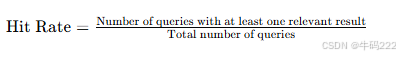
- FactScore
FactScore 是一种用于评估生成文本事实精确度的工具,通过将生成文本分解为一系列“原子事实”(Atomic Facts),并计算这些原子事实被可靠知识源支持的比例。具体公式如下:
设 M 为要评估的语言模型,X 为一组提示(prompt),C 为知识源。对于 x∈X,模型的响应为 y=M(x),Ay 是 y 中的原子事实列表。则 FactScore 定义为:
其中:
I[a is supported by C] 是一个指示函数,如果原子事实 a 被知识源 C 支持,则为 1,否则为 0。
输入
生成文本:模型生成的长篇文本。
知识源:用于验证原子事实真实性的可靠知识库(如维基百科)。
提示集合:一组用于生成文本的提示(prompt)。
输出
FactScore 的值:范围从 0 到 1,值越高表示生成文本中的原子事实被知识源支持的比例越高,即生成文本的事实精确度越高
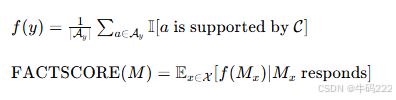
三、真实性与幻觉检测 (Factuality & Hallucination Detection)
目标:衡量生成内容的真实性及是否存在虚构信息
- FEQA (Factuality Evaluation for QA)
FEQA 是一种用于评估生成文本事实性的指标,通过问答(QA)的方式来衡量生成文本与源文档的一致性。其核心步骤如下:
问题生成(Question Generation):
从生成的摘要或回答中提取关键信息,生成一系列问题。
设 Q 为生成的问题集合。
答案提取(Answer Extraction):
使用预训练的问答模型(如 BERT for QA)从源文档中提取每个问题的答案。
设 Adoc 为从源文档中提取的答案集合。
答案匹配(Answer Matching):
将生成的摘要或回答中的答案与从源文档中提取的答案进行匹配。
设 Agen 为生成的摘要或回答中的答案集合。
计算匹配分数,通常使用精确匹配(Exact Match)或 F1 分数。
FEQA 得分:
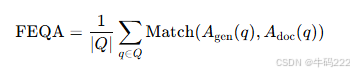
其中:
是生成答案与文档答案的匹配分数,可以是精确匹配(Exact Match)或 F1 分数。
输入
生成文本:模型生成的摘要或回答。
源文档:生成文本的源文档。
预训练问答模型:用于从源文档中提取答案的模型(如 BERT for QA)。
输出
FEQA 的值:范围从 0 到 1,值越高表示生成文本与源文档的事实一致性越高
- QAG (Question-Answering based Groundedness)
QAG(Question-Answering based Groundedness)是一种利用问答对来评估生成文本事实性的指标。其核心步骤如下:
问题生成(Question Generation):
从生成的文本中提取关键信息,生成一系列封闭式问题。
设 Q 为生成的问题集合。
答案提取(Answer Extraction):
使用预训练的问答模型(如 BERT for QA)从源文档中提取每个问题的答案。
设 Adoc 为从源文档中提取的答案集合。
答案匹配(Answer Matching):
将生成文本中的答案与从源文档中提取的答案进行匹配。
设 Agen 为生成文本中的答案集合。
计算匹配分数,通常使用精确匹配(Exact Match)或 F1 分数。
QAG 得分:
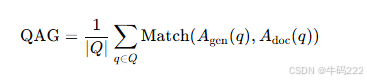
其中:
是生成答案与文档答案的匹配分数,可以是精确匹配(Exact Match)或 F1 分数。
输入
生成文本:模型生成的文本。
源文档:生成文本的源文档。
预训练问答模型:用于从源文档中提取答案的模型(如 BERT for QA)。
输出
QAG 的值:范围从 0 到 1,值越高表示生成文本与源文档的事实一致性越高
- AUC (Area Under the ROC Curve)
AUC(Area Under the ROC Curve)是接收者操作特征曲线(ROC Curve)下的面积,用于衡量分类模型的性能。ROC 曲线是通过在不同阈值下计算模型的真阳性率(True Positive Rate, TPR)和假阳性率(False Positive Rate, FPR)绘制的。
其中:
TPR(True Positive Rate):真阳性率,即模型正确识别的正例数量占所有实际正例数量的比例。
FPR(False Positive Rate):假阳性率,即模型错误识别的正例数量占所有实际负例数量的比例。
输入
模型预测的概率:模型对每个样本属于正类的概率预测。
真实标签:每个样本的实际标签(正类或负类)。
输出
AUC 的值:范围从 0 到 1。值越高,表示模型的分类性能越好
- PCC (Pearson Correlation Coefficient)
Pearson Correlation Coefficient(皮尔逊相关系数)用于衡量两个变量之间的线性相关程度。其公式如下:
其中:
Xi 和 Yi 是两个变量的第 i 个观测值。
Xˉ 和 Yˉ 分别是变量 X 和 Y 的平均值。
n 是观测值的数量。
计算步骤
计算平均值:
计算协方差:
计算 X 和 Y 的协方差:
计算标准差:
计算相关系数:
将协方差除以两个标准差的乘积,得到相关系数 r:
示例
假设我们有两组数据:
X=[1,2,3,4,5]
Y=[2,4,6,8,10]
计算平均值:
计算协方差:
计算标准差:
计算相关系数:
因此,PCC 的值为 1,表示 X 和 Y 之间存在完全正相关。
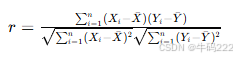

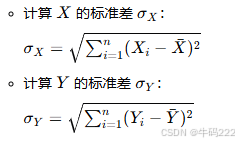
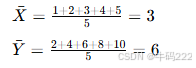
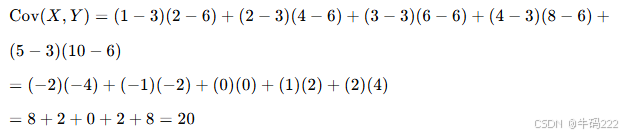
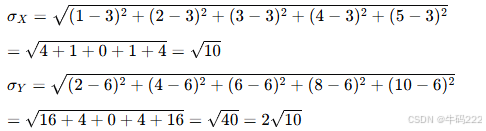
- Accuracy (针对幻觉检测)
Accuracy(准确率)用于衡量幻觉检测模型的性能,计算公式如下:
其中:
Number of correct predictions:模型正确预测的样本数量(即正确识别幻觉或非幻觉的样本)。
Total number of predictions:总样本数量。
输入
模型预测结果:模型对每个样本是否包含幻觉的预测结果。
真实标签:每个样本是否包含幻觉的真实标签。
输出
Accuracy 的值:范围从 0 到 1。值越高,表示模型在幻觉检测任务中的性能越好
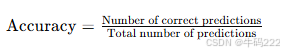
- Recall (针对幻觉检测)
Recall(召回率)用于衡量幻觉检测模型在所有实际包含幻觉的样本中正确识别幻觉的比例。其公式如下:
其中:
Number of true positives:模型正确识别为包含幻觉的样本数量。
Number of false negatives:模型错误识别为不包含幻觉的样本数量,即实际包含幻觉但模型未识别出的样本数量。
输入
模型预测结果:模型对每个样本是否包含幻觉的预测结果。
真实标签:每个样本是否包含幻觉的真实标签。
输出
Recall 的值:范围从 0 到 1。值越高,表示模型在所有实际包含幻觉的样本中正确识别幻觉的比例越高
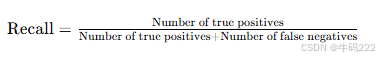
- F1 Score (针对幻觉检测)
F1 Score 是一种综合考虑精确率(Precision)和召回率(Recall)的评估指标,用于衡量幻觉检测模型的性能。其公式如下:
其中:
Precision:精确率,即模型预测为包含幻觉的样本中实际包含幻觉的比例。
Recall:召回率,即模型正确识别的包含幻觉的样本数量占所有实际包含幻觉的样本数量的比例。
输入
模型预测结果:模型对每个样本是否包含幻觉的预测结果。
真实标签:每个样本是否包含幻觉的真实标签。
输出
F1 Score 的值:范围从 0 到 1。值越高,表示模型在幻觉检测任务中的性能越好
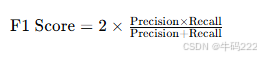
- Hallucination Rate
其中:
Number of samples predicted as hallucination:模型预测为包含幻觉的样本数量。
Total number of samples:总样本数量。
输入
模型预测结果:模型对每个样本是否包含幻觉的预测结果。
总样本数量:用于评估的总样本数量。
输出
Hallucination Rate 的值:范围从 0 到 1。值越低,表示模型生成的文本中包含幻觉的比例越低,生成内容的可信度越高。
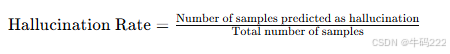
- Scoreh (幻觉答案惩罚指标)
Scoreh 是一个针对幻觉答案的惩罚指标,用于衡量系统生成回答中虚构信息的严重程度。其计算公式如下:
其中:
n 是生成回答中的句子数量。
Penalty(ai) 是对第 i 个句子的幻觉惩罚值,通常是一个二值函数,如果句子包含幻觉则为 1,否则为 0。
输入
生成回答:模型生成的文本回答。
真实答案:与生成回答相对应的真实文本或事实。
输出
Scoreh 的值:范围从 0 到 1。值越高,表示生成回答中包含幻觉的比例越高,生成内容的可信度越低
四、效率与性能评估 (Efficiency & Performance Evaluation)
目标:衡量模型在推理、检索、生成等环节的速度与资源消耗
- 推理时间 (Inference Time)
推理时间是指模型在处理单个样本时所需的时间,通常以毫秒(ms)或秒(s)为单位。其计算公式如下:
其中:
Start Time:开始推理的时间点。
End Time:结束推理的时间点。
输入
模型:预训练的模型。
输入数据:用于测试的输入数据。
设备:运行模型的设备(如 CPU 或 GPU)。
输出
Inference Time 的值:范围从 0 到正无穷,值越小,表示模型的推理速度越快
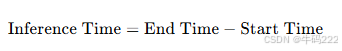
- 编码速度 (Encoding Speed)
编码速度是指编码器在单位时间内处理数据的能力,通常以比特每秒(bps)或字节每秒(B/s)为单位。其计算公式如下:
其中:
Data Volume:编码器处理的数据量,通常以比特(bit)或字节(byte)为单位。
Time:处理数据所需的时间,通常以秒(s)为单位。
输入
数据量:编码器处理的数据量。
时间:处理数据所需的时间。
输出
编码速度的值:范围从 0 到正无穷,值越高,表示编码器的处理速度越快
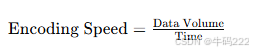
- 解码速度 (Decoding Speed)
解码速度是指解码器在单位时间内处理数据的能力,通常以比特每秒(bps)或字节每秒(B/s)为单位。其计算公式如下:
其中:
Data Volume:解码器处理的数据量,通常以比特(bit)或字节(byte)为单位。
Time:处理数据所需的时间,通常以秒(s)为单位。
输入
数据量:解码器处理的数据量。
时间:处理数据所需的时间。
输出
解码速度的值:范围从 0 到正无穷,值越高,表示解码器的处理速度越快

- 执行时间 (Execution Time)
执行时间是指程序或模型完成特定任务所需的总时间,通常以秒(s)或毫秒(ms)为单位。其计算公式如下:
其中:
Start Time:任务开始执行的时间点。
End Time:任务完成执行的时间点。
输入
任务开始时间:任务开始执行的时间点。
任务结束时间:任务完成执行的时间点。
输出
执行时间的值:范围从 0 到正无穷,值越小,表示任务的执行速度越快
- 构建延迟 (Constructing Latency)
构建延迟是指在系统设计和实现过程中,从开始构建到完成构建所需的时间。它通常用于评估构建系统的效率和性能。
计算方法
构建延迟可以通过以下步骤计算:
记录开始时间:记录构建开始的时间点。
记录结束时间:记录构建完成的时间点。
计算延迟:计算结束时间与开始时间的差值。
输入
开始时间:构建开始的时间点。
结束时间:构建完成的时间点。
输出
构建延迟的值:范围从 0 到正无穷,值越小,表示构建速度越快
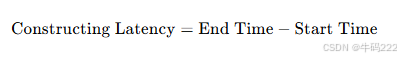
- 阅读延迟 (Reading Latency)
阅读延迟是指从请求读取数据到实际获取数据所需的时间,通常以毫秒(ms)或秒(s)为单位。其计算公式如下:
其中:
Start Time:开始请求读取数据的时间点。
End Time:实际获取数据的时间点。
输入
开始时间:请求读取数据的时间点。
结束时间:实际获取数据的时间点。
输出
阅读延迟的值:范围从 0 到正无穷,值越小,表示读取数据的速度越快
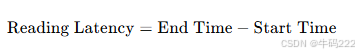
- 存储效率 (Storage Efficiency)
存储效率是指在给定的存储容量中有效利用存储资源的程度,通常以百分比(%)表示。其计算公式如下:
其中:
Used Storage:实际使用的存储量,通常以字节(B)、千字节(KB)、兆字节(MB)、吉字节(GB)或太字节(TB)为单位。
Total Storage:总存储容量,通常以字节(B)、千字节(KB)、兆字节(MB)、吉字节(GB)或太字节(TB)为单位。
输入
实际使用的存储量:系统或设备中实际使用的存储量。
总存储容量:系统或设备的总存储容量。
输出
存储效率的值:范围从 0 到 100,值越高,表示存储资源的利用效率越高
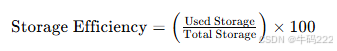
- API调用次数 / 迭代步数
API调用次数与迭代步数的关系通常用于评估API在生成或处理任务中的效率。其计算公式如下:
其中:
API调用次数:在特定时间段内调用API的总次数。
迭代步数:完成任务所需的迭代次数。
输入
API调用次数:统计周期内调用API的总次数。
迭代步数:完成任务所需的迭代次数。
输出
API调用次数 / 迭代步数 的值:范围从 0 到正无穷,值越小,表示每次迭代所需的API调用次数越少,效率越高

- TPQ (查询平均时间)
其中:
总查询时间:所有查询操作的总耗时。
查询次数:在特定时间段内执行的查询操作数量。
输入
总查询时间:所有查询操作的总耗时。
查询次数:在特定时间段内执行的查询操作数量。
输出
TPQ 的值:范围从 0 到正无穷,值越小,表示每次查询的平均时间越短,系统性能越高

- TPER (时间池效率比)
TPER(时间池效率比,Time Pool Efficiency Ratio)是评估系统在处理多个查询或任务时的时间效率的指标。它衡量系统在处理任务时,实际使用的时间与理想时间的比值。其计算公式如下:
其中:
实际总处理时间:系统实际处理所有任务所花费的总时间。
理想总处理时间:如果系统在理想状态下(无等待、无延迟)处理所有任务所需的总时间。
输入
实际总处理时间:系统实际处理所有任务所花费的总时间。
理想总处理时间:在理想状态下处理所有任务所需的总时间。
输出
TPER 的值:范围从 0 到正无穷,值越接近 1,表示系统的时间效率越高

五、情境真实性与可靠性 (Contextual Faithfulness & Reliability)
目标:衡量模型在不同上下文环境中的稳定性及真实度
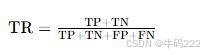
- True Context Accuracy (TR)
评估大语言模型(LLMs)在特定上下文中的预测准确性的指标。其计算公式如下:
其中:
TP(True Positive):正确预测为正类的样本数量。
TN(True Negative):正确预测为负类的样本数量。
FP(False Positive):错误预测为正类的负类样本数量。
FN(False Negative):错误预测为负类的正类样本数量。
输入
TP:正确预测为正类的样本数量。
TN:正确预测为负类的样本数量。
FP:错误预测为正类的负类样本数量。
FN:错误预测为负类的正类样本数量。
输出
TR 的值:范围从 0 到 1,值越高,表示模型在特定上下文中的预测正确性越高
- False Context Accuracy (FA)
False Context Accuracy(FA)是评估大语言模型(LLMs)在处理错误上下文时的预测准确性的指标。它衡量模型在错误上下文中生成错误内容的比例。其计算公式如下:
其中:
TP(True Positive):正确预测为正类的样本数量。
TN(True Negative):正确预测为负类的样本数量。
FP(False Positive):错误预测为正类的负类样本数量。
FN(False Negative):错误预测为负类的正类样本数量。
输入
TP:正确预测为正类的样本数量。
TN:正确预测为负类的样本数量。
FP:错误预测为正类的负类样本数量。
FN:错误预测为负类的正类样本数量。
输出
FA 的值:范围从 0 到 1,值越低,表示模型在错误上下文中生成错误内容的比例越低,模型的鲁棒性越高
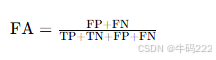
- Overall Situated Faithfulness (OV)
Overall Situated Faithfulness(OV)是评估大语言模型(LLMs)在特定上下文中的整体保真度的指标。它综合考虑了模型在正确上下文和错误上下文中的表现。其计算公式如下:
其中:
TR(True Context Accuracy):在所有正确上下文中模型的准确率。
FA(False Context Accuracy):在所有错误上下文中模型的准确率。
输入
TR:模型在正确上下文中的准确率。
FA:模型在错误上下文中的准确率。
输出
OV 的值:范围从 0 到 1,值越高,表示模型在不同上下文中的整体保真度越高
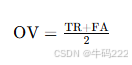
- Accuracy Given True/False Contexts (Acct/Accf)
Acct 和 Accf 是两个用于评估大语言模型(LLMs)在不同上下文条件下的准确性的指标。具体公式如下:
Accuracy Given True Contexts (Acct):
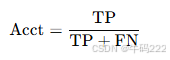
其中:
TP(True Positive):在正确上下文中正确预测为正类的样本数量。
FN(False Negative):在正确上下文中错误预测为负类的正类样本数量。
Accuracy Given False Contexts (Accf):
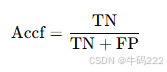
其中:
TN(True Negative):在错误上下文中正确预测为负类的样本数量。
FP(False Positive):在错误上下文中错误预测为正类的负类样本数量。
输入
TP:在正确上下文中正确预测为正类的样本数量。
FN:在正确上下文中错误预测为负类的正类样本数量。
TN:在错误上下文中正确预测为负类的样本数量。
FP:在错误上下文中错误预测为正类的负类样本数量。
输出
Acct 的值:范围从 0 到 1,值越高,表示模型在正确上下文中的预测正确性越高。
Accf 的值:范围从 0 到 1,值越高,表示模型在错误上下文中的预测正确性越高
六、鲁棒性评估 (Robustness Evaluation)
目标:衡量模型在不完美数据或恶意干扰情况下的表现
- 鲁棒准确率 (Robust Accuracy)
鲁棒准确率(Robust Accuracy, RA)是评估模型在对抗性扰动下保持正确分类能力的指标。其计算公式如下:
其中:
N 是样本总数。
yi^ 是模型预测的标签。
yi 是真实标签。
1 是指示函数,如果条件成立则为 1,否则为 0。
输入
样本总数 N:测试集中样本的总数。
模型预测的标签 yi^:模型对每个样本的预测标签。
真实标签 yi:每个样本的真实标签。
输出
鲁棒准确率的值:范围从 0 到 1,值越高,表示模型在对抗性扰动下保持正确分类的能力越强
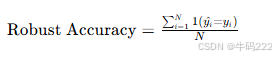
- Noise Robustness
噪声鲁棒性(Noise Robustness)是评估大语言模型(LLMs)在输入数据包含噪声时保持性能的能力。其计算公式如下:
其中:
模型在噪声数据上的性能:模型在添加噪声后的数据集上的性能指标(如准确率、召回率等)。
模型在干净数据上的性能:模型在未添加噪声的原始数据集上的性能指标。
输入
模型在干净数据上的性能:模型在未添加噪声的原始数据集上的性能指标。
模型在噪声数据上的性能:模型在添加噪声后的数据集上的性能指标。
输出
Noise Robustness 的值:范围从 0 到 1,值越接近 1,表示模型在噪声数据上的性能越接近干净数据上的性能,即模型的噪声鲁棒性越高
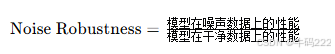
- 顺序鲁棒性 (Order Robustness)
顺序鲁棒性(Order Robustness)是指系统或模型在面对输入数据顺序变化时,仍能保持其性能和稳定性的能力。顺序鲁棒性特别重要,因为在实际应用中,输入数据的顺序可能会因各种因素而发生变化,而这些变化不应显著影响系统的性能。
计算方法
顺序鲁棒性的评估通常涉及以下步骤:
数据准备:准备包含不同顺序排列的输入数据集。
模型评估:使用模型对不同顺序的输入数据进行预测,并计算性能指标(如准确率、召回率等)。
鲁棒性评估:比较模型在不同顺序下的性能差异,评估模型对顺序变化的鲁棒性。
具体公式可以表示为:
输入
模型在原始顺序数据上的性能:模型在未改变顺序的原始数据集上的性能指标。
模型在不同顺序数据上的性能:模型在改变顺序后的数据集上的性能指标。
输出
顺序鲁棒性的值:范围从 0 到 1,值越接近 1,表示模型在不同顺序下的性能越接近原始顺序下的性能,即模型的顺序鲁棒性越高

- 统计保证
统计保证是指在统计分析或模型评估中,对结果的可靠性、准确性和一致性的量化描述。它通常用于衡量模型预测或统计推断的可信度,确保结果在一定置信水平下具有统计显著性。
计算方法
统计保证的计算通常涉及以下步骤:
置信区间(Confidence Interval):计算模型预测或统计量的置信区间,表示在一定置信水平下,真实值可能落在的范围。
假设检验(Hypothesis Testing):通过假设检验来评估模型预测或统计量的显著性,通常计算 p 值(p-value)。
置信水平(Confidence Level):选择一个置信水平(如 95% 或 99%),表示结果的可信度。
具体公式可以表示为:
其中:
是估计的统计量(如均值、比例等)。
z 是对应置信水平的 z 分数(如 95% 置信水平对应的 z 分数为 1.96)。
SE 是标准误差(Standard Error)。
输入
估计的统计量 θ^:模型预测或统计量的估计值。
标准误差 SE:估计值的标准误差。
置信水平:选择的置信水平(如 95% 或 99%)。
输出
置信区间:表示在一定置信水平下,真实值可能落在的范围。
p 值:表示假设检验的显著性水平,值越小,表示结果越显著
七、公平性评估 (Fairness Evaluation)
目标:衡量模型在不同群体中的表现一致性,避免偏见
- 组差异 (Group Disparity, GD)
组差异(Group Disparity, GD)是指在不同组之间存在的差异程度,通常用于衡量模型或系统在不同群体中的表现是否存在显著差异。这种差异可能体现在多个方面,如性能、输出结果等。
计算方法
组差异的计算通常涉及以下步骤:
数据准备:准备不同组的数据。
性能评估:对每个组的数据进行性能评估,计算每个组的性能指标(如准确率、召回率等)。
差异计算:计算不同组之间的性能差异。
具体公式可以表示为:
其中:
N 是组的数量。
Pi 是第 i 组的性能指标。
Qi 是参考组的性能指标。
输入
不同组的性能指标:每个组的性能指标(如准确率、召回率等)。
参考组的性能指标:作为基准的参考组的性能指标。
输出
组差异的值:范围从 0 到正无穷,值越小,表示不同组之间的差异越小,模型的公平性越高
- 均等化机会 (Equalized Odds, EO)
八、数据与模型效率评估 (Data & Model Efficiency Evaluation)
目标:衡量模型在数据和参数优化方面的效率
- Preference Data Collection Efficiency
偏好数据收集效率(Preference Data Collection Efficiency, PDCE)是指在收集用于训练奖励模型(Reward Model, RM)的偏好数据时,数据收集过程的效率和质量。它衡量的是在有限的资源和时间内,收集到的偏好数据的有效性和多样性。
计算方法
偏好数据收集效率的评估通常涉及以下步骤:
数据准备:准备不同来源的偏好数据,包括由 AI 生成的数据和人类标注的数据。
数据过滤:通过 AI 模型对数据进行初步过滤,去除噪声数据。
人类标注:对过滤后的数据进行人类标注,以确保数据的质量。
效率评估:评估整个数据收集过程的效率,包括数据的多样性、有效性和标注成本。
具体公式可以表示为:
输入
高质量偏好数据的数量:经过 AI 过滤和人类标注后,确认为高质量的偏好数据的数量。
总标注成本和时间:收集和标注偏好数据所需的总成本和时间。
输出
PDCE 的值:范围从 0 到正无穷,值越高,表示偏好数据收集的效率越高
- 模型规模 (Model Size)
模型规模(Model Size)是指模型的参数数量,通常以百万(M)或十亿(B)为单位。它反映了模型的复杂性和计算资源需求。
计算方法
模型规模的计算通常涉及以下步骤:
参数计数:统计模型中所有参数的数量。
单位转换:将参数数量转换为百万(M)或十亿(B)。
具体公式可以表示为:
输入
总参数数量:模型中所有参数的数量。
输出
模型规模的值:以百万(M)或十亿(B)为单位,表示模型的规模

- 数据效率 (Data Efficiency)
数据效率(Data Efficiency)是指模型在有限的数据量下能够达到的性能水平,反映了模型对数据的利用效率。高数据效率意味着模型能够在较少的数据上达到较好的性能,从而减少数据收集和标注的成本。
计算方法
数据效率的评估通常涉及以下步骤:
性能评估:在不同数据量下评估模型的性能,通常使用准确率、召回率等指标。
效率评估:计算模型在不同数据量下的性能提升,评估数据效率。
具体公式可以表示为:
其中:
Model Performance with Limited Data:模型在有限数据量下的性能。
Model Performance with Full Data:模型在完整数据量下的性能。
输入
模型在有限数据量下的性能:模型在较少数据上的性能指标。
模型在完整数据量下的性能:模型在完整数据上的性能指标。
输出
数据效率的值:范围从 0 到 1,值越接近 1,表示模型在有限数据下的性能越接近完整数据下的性能,数据效率越高
- 训练参数更新数量
训练参数更新数量是指在模型训练过程中,参数被更新的总次数。这个指标可以反映训练过程的复杂性和模型的收敛速度。
计算方法
训练参数更新数量的计算通常涉及以下步骤:
记录每次更新:在训练过程中,记录每次参数更新的事件。
统计更新次数:统计整个训练过程中参数更新的总次数。
具体公式可以表示为:
其中:
N 是训练过程中的总迭代次数。
Updatei 是第 i 次迭代中参数是否更新的指示变量(1 表示更新,0 表示未更新)。
输入
训练过程记录:记录每次迭代中参数是否更新的信息。
输出
训练参数更新数量:表示在整个训练过程中参数被更新的总次数
- 迭代次数对性能的影响
迭代次数对性能的影响是指在模型训练过程中,随着迭代次数的增加,模型性能的变化情况。这通常涉及到模型的收敛速度、过拟合风险以及最终的性能水平。
计算方法
迭代次数对性能的影响可以通过以下步骤进行评估:
性能评估:在不同迭代次数下评估模型的性能,通常使用准确率、召回率等指标。
影响分析:分析随着迭代次数的增加,模型性能的变化趋势。
具体公式可以表示为:
其中:
k 是迭代次数。
f(k) 是模型在第 k 次迭代时的性能指标。
输入
不同迭代次数下的性能指标:模型在不同迭代次数下的性能指标。
输出
迭代次数对性能的影响:随着迭代次数的增加,模型性能的变化趋势

九、解释性与可解释性 (Explainability & Interpretability)
目标:衡量模型输出的可理解性和可信度
- LLM-as-a-judge
LLM-as-a-Judge 作为一种评估方法,利用大型语言模型(LLM)来评估其他模型的输出或任务结果。其评估过程可以形式化为:
其中:
E 是评估结果。
x 是输入数据。
C 是结合提示(Prompt)和上下文信息的上下文提示。
PLLM 是由相应 LLM 定义的概率函数,生成过程是自回归的。
评估结果的形式可以包括:
评分(Score):每个候选样本被分配一个连续或离散的分数。
排序(Ranking):输出是每个候选样本的排序。
选择(Selection):输出涉及选择一个或多个最佳候选。
输入
输入数据 x:需要评估的模型输出或任务结果。
上下文提示 C:结合提示和上下文信息,用于引导 LLM 进行评估。
输出
评估结果 E:LLM 生成的评分、排序或选择结果
- 解释的正确性和质量
解释的正确性和质量是指对模型预测或决策过程的解释在内容上的准确性以及表达上的清晰度和有用性。这不仅包括解释是否正确反映了模型的行为,还包括解释是否易于理解、是否提供了足够的信息来帮助用户信任和使用模型。
计算方法
解释的正确性和质量的评估通常涉及以下步骤:
正确性评估:验证解释是否准确反映了模型的决策过程。
质量评估:评估解释的清晰度、完整性和有用性。
具体公式可以表示为:
其中:
Number of Correct Explanations:正确解释的数量。
Total Number of Explanations:总解释的数量。
Quality Score:每个解释的质量评分,通常由人类评估者给出。
输入
模型解释:模型生成的解释。
真实决策过程:模型的实际决策过程。
质量评分:由人类评估者对每个解释的质量进行评分。
输出
正确性的值:范围从 0 到 1,值越高,表示解释的正确性越高。
质量的值:范围从 0 到 1,值越高,表示解释的质量越高

- 置信度评分
置信度评分是指模型对其预测结果的自信程度的量化表示。它通常是一个介于0和1之间的值,表示模型预测结果的可靠性。高置信度评分表示模型对预测结果非常有信心,而低置信度评分则表示模型对预测结果不太确定。
计算方法
置信度评分的计算通常依赖于模型的输出概率分布。对于分类任务,置信度评分通常是模型输出的最高概率值。对于回归任务,置信度评分可能需要通过其他方法(如不确定性估计)来计算。
具体公式可以表示为:
其中:
P(y∣x) 是模型预测的条件概率分布。
y 是预测的类别。
x 是输入数据。
输入
模型预测的概率分布:模型对输入数据的预测概率分布。
输出
置信度评分:范围从 0 到 1,值越高,表示模型对预测结果的置信度越高
十、任务特定指标 (Task-Specific Metrics)
目标:根据不同任务需求而设置的专用指标
- 困惑度 (Perplexity)
困惑度是一种衡量语言模型对一组数据的不确定性或混乱程度的指标,它反映了语言模型对给定文本的预测能力。具体来说,困惑度越低,表示模型在对给定数据进行预测时越自信、越准确,也就是说,模型越能够对给定的数据进行较好的拟合。
对于一个给定的句子 S,其困惑度 (Perplexity) 的计算公式为:
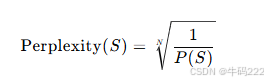
其中,N 是句子的长度,P(S) 是语言模型给出的句子 S 的概率。
对于整个测试集,困惑度的计算公式为:
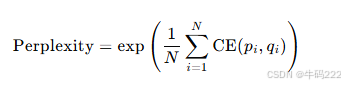
其中,N 是测试集中的样本数量,CE(pi,qi) 是交叉熵,表示模型预测的概率分布与真实分布之间的差异。
输入和输出
输入
测试集:包含多个句子或文本段落的集合,用于评估语言模型的性能。
语言模型:一个已经训练好的模型,能够对给定的句子或文本段落给出概率预测。
输出
困惑度 (Perplexity):一个数值,表示语言模型对测试集的预测能力。数值越小,表示模型的预测能力越强,模型越好。
计算步骤
计算句子概率:对于测试集中的每个句子 S,使用语言模型计算其概率 P(S)。
计算交叉熵:对于每个句子,计算模型预测的概率分布与真实分布之间的交叉熵 CE(pi,qi)。
计算平均交叉熵:将所有句子的交叉熵求和,并除以句子总数 N,得到平均交叉熵。
计算困惑度:将平均交叉熵取指数,得到困惑度。
- Coverage (覆盖范围)
覆盖范围(Coverage) 是一个衡量模型输出与输入之间信息匹配程度的指标。它反映了模型生成的文本或预测结果是否能够涵盖输入数据中的所有重要信息。高覆盖范围意味着模型能够更好地理解和利用输入数据中的信息,生成更全面、更准确的输出。
计算方法
覆盖范围的计算方法因具体任务而异,以下是一些常见的计算方法:
1. 基于词汇的覆盖范围
定义:计算模型生成的文本中包含的词汇与输入文本中词汇的重合程度。
公式:
应用场景:适用于文本生成、机器翻译等任务,用于评估生成文本是否涵盖了输入文本中的关键词汇。
2. 基于语义的覆盖范围
定义:通过语义相似度计算模型生成的文本与输入文本之间的覆盖程度。
方法:使用词嵌入(如 Word2Vec、GloVe)或上下文嵌入(如 BERT)来计算生成文本和输入文本之间的语义相似度。
公式:
应用场景:适用于需要考虑语义信息的任务,如问答系统、文本摘要等。
3. 基于信息单元的覆盖范围
定义:计算模型生成的文本中包含的信息单元(如事实、事件、实体等)与输入文本中信息单元的重合程度。
方法:通过信息抽取技术(如 NER、事件抽取)提取输入文本和生成文本中的信息单元,然后计算重合度。
公式:
应用场景:适用于需要精确信息匹配的任务,如问答系统、知识图谱生成等。
输入和输出
输入
输入文本:需要评估的原始文本,可以是一个句子、段落或文档。
生成文本:模型生成的文本,用于与输入文本进行比较。
输出
覆盖范围(Coverage):一个数值,表示生成文本对输入文本的覆盖程度。数值越高,表示覆盖范围越广,模型的输出越全面。

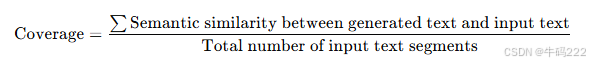

- Selective Accuracy (选择性准确率)
选择性准确率:

其中,τ 是置信度阈值,分子是置信度大于或等于 τ 的正确预测数量,分母是置信度大于或等于 τ 的总预测数量。
覆盖率(Coverage):
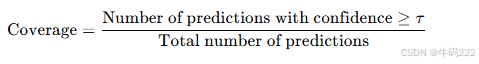
其中,分子是置信度大于或等于 τ 的预测数量,分母是总预测数量。
AUC值:通过绘制选择性准确率与覆盖率的曲线,计算该曲线下的面积(AUC),AUC值越高,表示模型在选择性预测时的性能越好。
输入
模型预测结果:模型对每个样本的预测结果及其对应的置信度。
示例:
[("样本1", "预测标签1", 0.95), ("样本2", "预测标签2", 0.85), ...]真实标签:每个样本的真实标签。
示例:
[("样本1", "真实标签1"), ("样本2", "真实标签2"), ...]置信度阈值 τ:用于筛选高置信度预测的阈值。
示例:
0.9输出
选择性准确率(Selective Accuracy):一个数值,表示在给定置信度阈值下,模型预测正确的比例。
示例:
0.92覆盖率(Coverage):一个数值,表示置信度高于阈值的样本占总样本的比例。
示例:
0.75AUC值:曲线下的面积,用于综合评估模型在不同置信度阈值下的性能。
示例:
0.88计算步骤
筛选高置信度预测:
从模型预测结果中筛选出置信度大于或等于 τ 的预测。
示例:假设阈值 τ=0.9,筛选出置信度大于或等于 0.9 的预测。
计算正确预测数量:
对筛选出的预测,计算其与真实标签一致的数量。
示例:假设筛选出的预测中有 10 个,其中 9 个与真实标签一致,则正确预测数量为 9。
计算选择性准确率:
使用上述公式计算选择性准确率。
示例:选择性准确率 = 109=0.9。
计算覆盖率:
计算置信度大于或等于 τ 的预测数量占总预测数量的比例。
示例:假设总预测数量为 20,则覆盖率 = 2010=0.5。
绘制曲线并计算AUC值:
对不同的置信度阈值 τ,重复上述步骤,绘制选择性准确率与覆盖率的曲线。
计算曲线下的面积(AUC值)
- Recall@10 (文档分析)
Recall@10 是一种评估检索系统性能的指标,特别是在文档检索任务中。它衡量的是在返回的前10个文档中,相关文档的数量占所有相关文档总数的比例。简单来说,Recall@10 表示系统在前10个检索结果中,是否能够有效地覆盖正确的文档或信息。
计算公式
Recall@10 的计算公式如下:

其中:
前10个结果中相关文档的数量:在检索结果的前10个文档中,与查询相关的文档数量。
所有相关文档的总数:在知识库或文档集合中,与查询相关的文档总数。
输入
查询集合:包含多个查询的集合,每个查询对应一个或多个相关文档。
示例:
{"query1": ["doc1", "doc2"], "query2": ["doc3", "doc4"]}文档集合:包含所有文档的集合,用于检索。
示例:
{"doc1": "内容1", "doc2": "内容2", "doc3": "内容3", "doc4": "内容4"}检索结果:对于每个查询,检索系统返回的前10个文档。
示例:
{"query1": ["doc1", "doc5", "doc2", "doc6", ...], "query2": ["doc3", "doc7", "doc8", ...]}输出
Recall@10 值:一个介于 0 和 1 之间的数值,表示检索系统在前10个结果中覆盖相关文档的能力。
示例:
0.75表示在前10个结果中,有75%的相关文档被检索到
- Scoreh (知识接地性)
Scoreh (知识接地性) 是评估生成内容与真实世界知识一致性的指标,主要用于衡量系统生成的回答是否有足够的事实依据。它在自然语言处理任务中,尤其是生成式问答和文本生成任务中,用于评估生成内容的可靠性和准确性。
计算方法
Scoreh 的计算通常涉及以下几个步骤:
标注真实知识:对每个查询或问题,标注出所有相关的事实或知识。
生成内容分析:分析系统生成的回答,提取其中包含的知识点。
匹配与评分:将生成内容中的知识点与标注的真实知识进行匹配,计算匹配程度。
计算得分:根据匹配结果,计算生成内容的知识接地性得分。
具体的计算公式可能因任务而异,但一般可以表示为:

输入
查询集合:包含多个查询或问题的集合。
示例:
["问题1", "问题2", ...]标注的真实知识:每个查询对应的真实知识或事实。
示例:
{"问题1": ["知识点1", "知识点2"], "问题2": ["知识点3", "知识点4"]}生成内容:系统对每个查询生成的回答。
示例:
{"问题1": "生成的回答1", "问题2": "生成的回答2"}输出
Scoreh 值:一个介于 0 和 1 之间的数值,表示生成内容与真实知识的一致性。
示例:
0.85表示生成内容中有 85% 的知识点与真实知识匹配
- Pass@1 (代码生成)
Pass@1 是一种评估代码生成模型性能的指标,用于衡量模型在第一次尝试生成代码时的正确率。具体来说,Pass@1 表示模型生成的代码在第一次尝试中通过所有测试用例的概率。
计算方法
Pass@1 的计算相对直接,对于每个问题或任务:
模型生成一个代码样本。
判断该代码样本是否通过所有测试用例。
统计所有问题中通过测试用例的比例,即为 Pass@1。
公式可以表示为:

输入
问题集合:包含多个编程任务或问题的集合。
示例:
["问题1", "问题2", ...]测试用例:每个问题对应的测试用例集合,用于验证生成代码的正确性。
示例:
{"问题1": [测试用例1, 测试用例2, ...], "问题2": [测试用例3, 测试用例4, ...]}输出
Pass@1 值:一个介于 0 和 1 之间的数值,表示模型在第一次尝试生成代码时的正确率。
示例:
0.85表示模型在第一次尝试中,有 85% 的代码通过了所有测试用例
- Matthews相关系数 (MCC)
Matthews相关系数 (MCC) 是一种用于评估分类模型性能的指标,特别适用于二分类问题。它考虑了真阳性、真阴性、假阳性和假阴性,提供了一个衡量模型预测结果与实际标签之间相关性的指标。MCC的值范围从-1到1,其中1表示完美预测,0表示随机预测,-1表示完全错误的预测。
计算公式
MCC的计算公式如下:
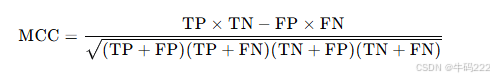
其中:
TP (True Positive):真阳性,即模型正确预测为正类的样本数量。
TN (True Negative):真阴性,即模型正确预测为负类的样本数量。
FP (False Positive):假阳性,即模型错误预测为正类的样本数量。
FN (False Negative):假阴性,即模型错误预测为负类的样本数量。
输入
真实标签:每个样本的实际标签,通常为0或1。
示例:
[0, 1, 0, 1, 1, 0]预测标签:模型对每个样本的预测标签,通常为0或1。
示例:
[0, 1, 1, 1, 0, 0]输出
MCC值:一个介于-1和1之间的数值,表示模型预测结果与实际标签之间的相关性。
示例:
0.4表示模型的预测结果与实际标签之间有中等程度的相关性
- Unit Tests (UT) 通过率 (功能级代码补全)
Unit Tests (UT) 通过率 是一种评估代码生成模型在功能级代码补全任务中性能的指标。它衡量的是模型生成的代码片段通过单元测试(Unit Tests)的比例。单元测试是软件开发中用于验证代码片段是否按预期工作的一种测试方法,通常针对代码中的单个函数或模块。
计算方法
UT通过率的计算公式如下:

其中:
通过单元测试的代码片段数量:模型生成的代码片段中,能够通过所有相关单元测试的代码片段数量。
生成的代码片段总数:模型生成的所有代码片段的数量。
输入
代码片段集合:模型生成的代码片段集合。
示例:
["def add(a, b): return a + b", "def subtract(a, b): return a - b", ...]单元测试集合:每个代码片段对应的单元测试集合。
示例:
{"def add(a, b): return a + b": [assert add(1, 2) == 3, assert add(0, 0) == 0], ...}输出
UT通过率:一个介于0和1之间的数值,表示模型生成的代码片段通过单元测试的比例。
示例:
0.85表示模型生成的代码片段中有85%通过了单元测试。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









