







梯度消失和爆炸
当神经网络的层数较多时,模型的稳定性就容易变差
简单的来说,假设一个层数为L的多层感知机的第l层
H
(
l
)
H^{(l)}
H(l)的权重参数为
W
(
l
)
W^{(l)}
W(l),输出层
H
(
L
)
H^{(L)}
H(L)的权重为
W
(
L
)
W^{(L)}
W(L).在这里我们不考虑偏差参数设所有的激活函数为恒等映射及
Φ
(
x
)
=
x
\Phi (x) =x
Φ(x)=x。给定输入X,多层感知机第l的输出就会为
H
(
l
)
=
X
W
(
1
)
W
(
2
)
.
.
.
.
W
(
n
)
H^{(l)}=XW^(1)W^(2)....W^(n)
H(l)=XW(1)W(2)....W(n)。如果l较大,这个时候
H
(
l
)
H^{(l)}
H(l)就会出现衰减和爆炸的情况。
随机初始化
如果不进行随机初始化而是相同的参数的话,本质上只有一个单元发生作用。所以要随机初始化模型参数,尤其是权重参数。
随机初始化可以用
torch.nn.init.normal_()
nn.Moudle
循环神经网络
GRU

gru_layer = nn.GRU(input_size=vocab_size, hidden_size=num_hiddens)
model = d2l.RNNModel(gru_layer, vocab_size).to(device)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
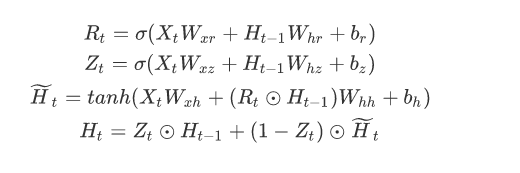
需要确定的参数为
W
x
r
,
W
h
r
,
b
r
,
W
x
z
,
W
h
z
,
b
z
,
W
x
h
,
W
h
h
,
b
h
W_{xr},W_{hr},b_{r},W_{xz},W_{hz},b_z,W_{xh},W_{hh},b_{h}
Wxr,Whr,br,Wxz,Whz,bz,Wxh,Whh,bh,以及第一个状态之前的
H
−
1
H_{-1}
H−1
LSTM

lstm_layer = nn.LSTM(input_size=vocab_size, hidden_size=num_hiddens)
model = d2l.RNNModel(lstm_layer, vocab_size)
d2l.train_and_predict_rnn_pytorch(model, num_hiddens, vocab_size, device,
corpus_indices, idx_to_char, char_to_idx,
num_epochs, num_steps, lr, clipping_theta,
batch_size, pred_period, pred_len, prefixes)
机器翻译
定义:
将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。 主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
需要的步骤:建立词典
def build_vocab(tokens):
tokens = [token for line in tokens for token in line]
return d2l.data.base.Vocab(tokens, min_freq=3, use_special_tokens=True)
Attention
对于机器翻译来说,难题在于输入和输出并不是等长的Encoder把转换为一种编码,即一种隐藏状态,encoder的输出将会作为decoder的输入
计算注意力分数并进行权重的归一化,输出的向量
o
o
o则是value的加权求和,而每个key计算的权重与value一一对应。
为了计算输出,我们首先假设有一个函数 α \alpha α 用于计算query和key的相似性,然后可以计算所有的 attention scores a 1 , … , a n a_1, \ldots, a_n a1,…,an by
a i = α ( q , k i ) . a_i = \alpha(\mathbf q, \mathbf k_i). ai=α(q,ki).
我们使用 softmax函数 获得注意力权重:
b 1 , … , b n = softmax ( a 1 , … , a n ) . b_1, \ldots, b_n = \textrm{softmax}(a_1, \ldots, a_n). b1,…,bn=softmax(a1,…,an).
最终的输出就是value的加权求和:
o = ∑ i = 1 n b i v i . \mathbf o = \sum_{i=1}^n b_i \mathbf v_i. o=i=1∑nbivi.
Transformer
- CNNs 易于并行化,却不适合捕捉变长序列内的依赖关系。
- RNNs 适合捕捉长距离变长序列的依赖,但是却难以实现并行化处理序列。
为了整合CNN和RNN的优势, 创新性地使用注意力机制设计了Transformer模型。该模型利用attention机制实现了并行化捕捉序列依赖,并且同时处理序列的每个位置的tokens,上述优势使得Transformer模型在性能优异的同时大大减少了训练时间。
与seq2seq模型相似,Transformer同样基于编码器-解码器架构,其区别主要在于以下三点:
- Transformer blocks:将seq2seq模型重的循环网络替换为了Transformer Blocks,该模块包含一个多头注意力层(Multi-head Attention Layers)以及两个position-wise feed-forward networks(FFN)。对于解码器来说,另一个多头注意力层被用于接受编码器的隐藏状态。
- Add and norm:多头注意力层和前馈网络的输出被送到两个“add and norm”层进行处理,该层包含残差结构以及层归一化。
- Position encoding:由于自注意力层并没有区分元素的顺序,所以一个位置编码层被用于向序列元素里添加位置信息。















 5321
5321











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









