









目录
| 链接 | |
|---|---|
| project | https://sites.google.com/view/dreamface |
| paper | https://arxiv.org/abs/2304.03117 |
| video | https://youtu.be/yCuvzgGMvPM |
| .Demo | https://sites.google.com/view/dreamface |
目标
文本引导的细粒度3D人脸生成,我理解应该是单个人头的定制生成,即通过输入一段文本渐进的去执行几何和纹理优化生成一个对应的3D人脸,但基于高分辨率的纹理、几何(法线)和基于物理的渲染可以生成高质量的3D人脸。
代价方面主要是训练数据,训练的成本使用A6000单/双卡GPU。
相似文章 AvatarClip、describe3d、EVA3D、HeadSculpt
方法
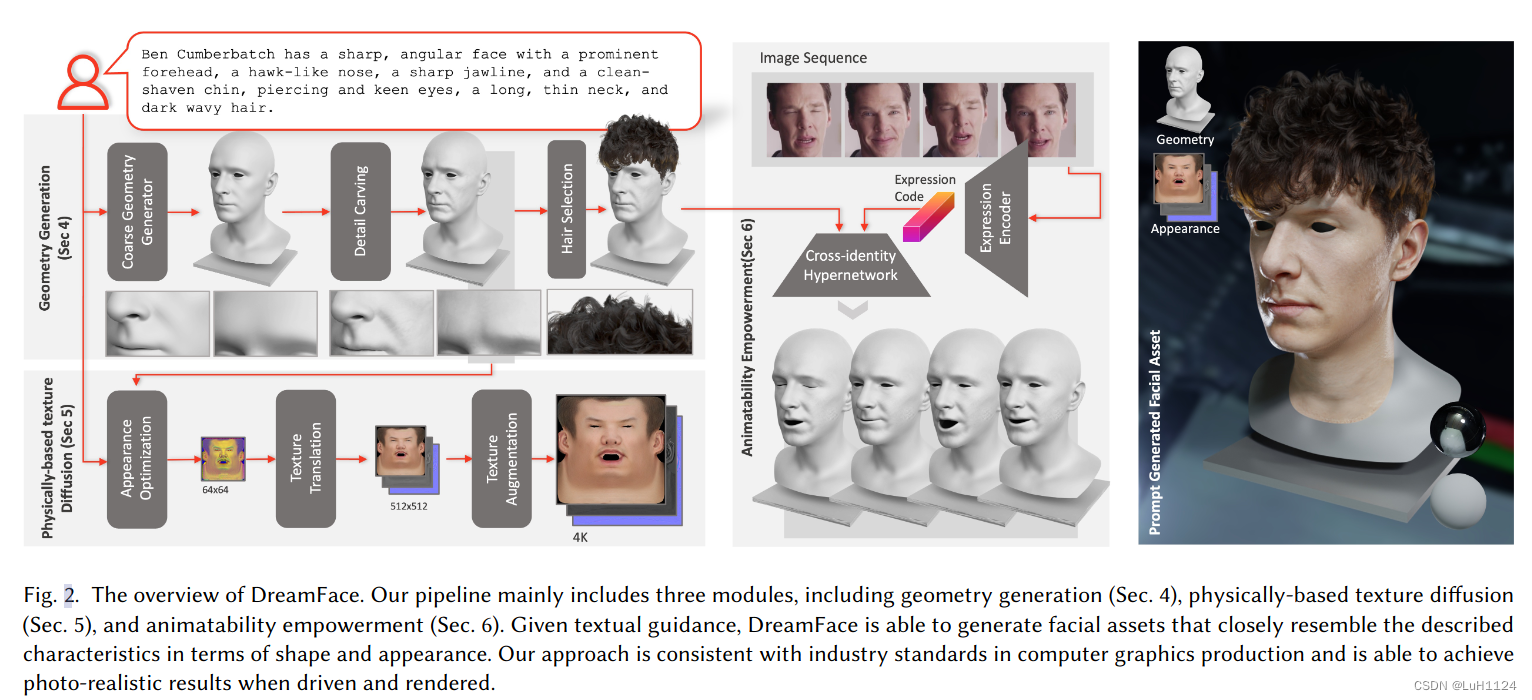
主要分为三个部分,分别是几何生成,基于物理的纹理生成、 动画部署
几何生成
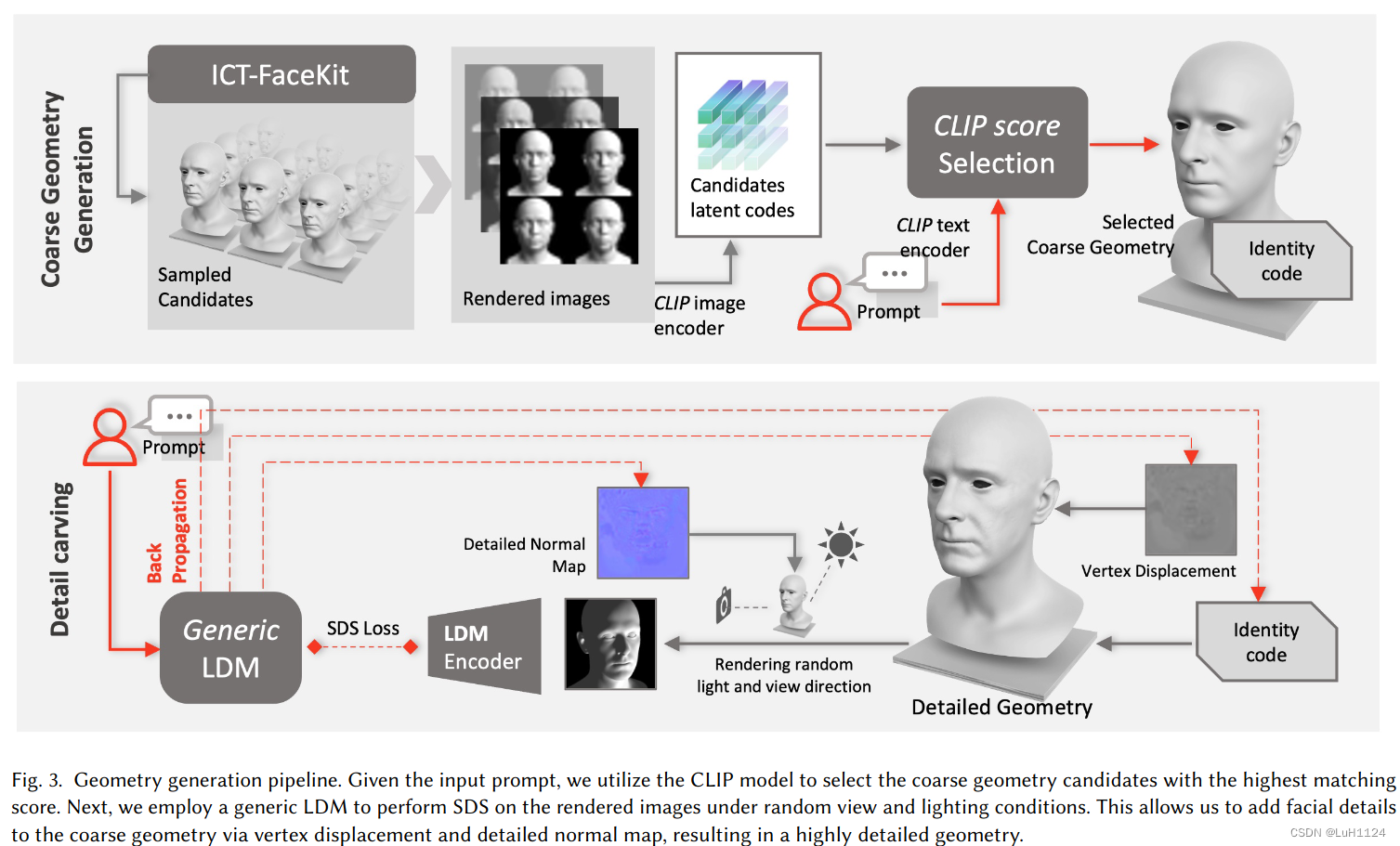
首先从候选几何和prompts中进行匹配,然后基于SDSloss对法线贴图、位置贴图、形状参数进行优化以得到Detail 几何。
Coarse geometry
- 在ICTFaceKit的shape space (14062 vertices)构建faces(28068 faces),也就是从高斯分布中随机采样形状参数,和平均shape组合成多个中性人脸。
T = T ( β ) = T ‾ + ∑ i β i S i \mathrm{T}=T(\boldsymbol{\beta})=\overline{\mathrm{T}}+\sum_{i} \beta_{i} \mathrm{~S}_{i} T=T(β)=T+i∑βi Si - 根据预先设定的prompts对这些faces进行匹配
2.1 对每个face选取三个角度,10个光照,取clip 视觉encoder的特征编码期望 e i e_i ei
2.2 对每个prompt使用clip text encoder提取文本编码 e t e_t et
2.3 根据AvatarClip提取相对相似度
T = T ( β ) = T ‾ + ∑ i β i S i s = λ d s d + λ r s r , where s d = e ~ i ⋅ e ~ t , s r = Δ e i ~ ⋅ Δ e t ~ \mathrm{T}=T(\boldsymbol{\beta})=\overline{\mathrm{T}}+\sum_{i} \beta_{i} \mathrm{~S}_{i}s=\lambda_{d} s_{d}+\lambda_{r} s_{r} \text {, where } s_{d}=\tilde{e}_{i} \cdot \tilde{e}_{\mathrm{t}}, \quad s_{r}=\tilde{\Delta e_{i}} \cdot \tilde{\Delta e_{\mathrm{t}}} T=T(β)=T+i∑βi Sis=λdsd+λrsr, where sd=e~i⋅e~t,sr=Δei~⋅Δet~
其中 x ~ \tilde{x} x~表示对 x x x进行归一化, Δ x ~ = x − x ~ \Delta{\tilde{x}}=x-\tilde{x} Δx~=x−x~- text “The Face”对应平均shape T ‾ \overline{\mathrm{T}} T
- 根据clip的分数匹配prompt与粗糙网格( T ∗ \mathbf{T}^{*} T∗ and β ∗ \boldsymbol{\beta}^{*} β∗)
Geometry detail curving
- 由于粗网格是根据参数生成的,往往过于平滑,使用顶点的displacement map V d \mathcal{V}_d Vd和切线空间normal map N d \mathcal{N}_d Nd 两个组件协助细节生成
- 作者使用通用LDM,即Stable Diffusion,通过提示引导将面部细节添加到粗几何中。简单来说应用SDS loss在渲染过程中优化位置贴图和法线图
T † = T ∗ + V d ⊙ n ( T ∗ ) I = R m ( T † ( V d ) , N d , c , l ) \mathrm{T}^{\dagger} = \mathrm{T}^{*}+\mathcal{V}_{d} \odot \mathbf{n}\left(\mathrm{T}^{*}\right) \\ \mathbf{I}=\mathcal{R}_{m}\left(\mathbf{T}^{\dagger}\left(\mathcal{V}_{d}\right), \mathcal{N}_{d}, c, l\right) T†=T∗+Vd⊙n(T∗)I=Rm(T†(Vd),Nd,c,l)
I I I为渲染结果,c为相机参数,l为光源位置
2.3 SDS损失函数,参考DreamFusion
∇ x d L S D S ( I ) ≜ E t , ϵ [ w ( t ) ( ϵ ϕ ( z t d ; t , P ) − ϵ ) ∂ z t d ∂ I ∂ I ∂ x d ] \nabla_{x_{d}} \mathcal{L}_{\mathrm{SDS}}(\mathbf{I}) \triangleq \mathbb{E}_{t, \epsilon}\left[w(t)\left(\epsilon_{\phi}\left(z_{t}^{d} ; t, \mathcal{P}\right)-\epsilon\right) \frac{\partial \mathrm{z}_{t}^{d}}{\partial \mathbf{I}} \frac{\partial \mathbf{I}}{\partial x_{d}}\right] ∇xdLSDS(I)≜Et,ϵ[w(t)(ϵϕ(ztd;t,P)−ϵ)∂I∂ztd∂xd∂I]
where x d = [ V d , N d , β ∗ ] x_{d}=\left[\mathcal{V}_{d}, \mathcal{N}_{d}, \boldsymbol{\beta}^{*}\right] xd=[Vd,Nd,β∗] 被优化参数, z d = E ( I ) z^{d}=\mathcal{E}(\mathbf{I}) zd=E(I) is the encoded image using LDM image encoder, w ( t ) w(t) w(t) is a weighting depending on discrete time step t, ϵ ϕ \epsilon_{\phi} ϵϕ is the denoiser of generic LDM with classifier-free guidance. Notice we also refine the shape parameters β ∗ \boldsymbol{\beta}^{*} β∗ , denoted as β † \boldsymbol{\beta}^{\dagger} β†
相机姿态的采样空间被限制在一个弧上,端点在front View的左45到右45,照明方向 l l l在面部前部的半球内是随机的
2.4 其余Loss,身份系数正则化,网格间的拉普拉斯平滑损失,法线贴图的梯度和散度损失(三维重建任务可用)
L sha = ∥ β † − β ∗ ∥ 2 2 , L geo = Laplacian ( T † , T ∗ ) , L map = ∥ Δ N d ∥ 2 2 + ∥ ∇ N d ∥ 2 2 , \begin{array}{c} \mathcal{L}_{\text {sha }}=\left\|\boldsymbol{\beta}^{\dagger}-\boldsymbol{\beta}^{*}\right\|_{2}^{2}, \quad \mathcal{L}_{\text {geo }}=\text { Laplacian }\left(\mathrm{T}^{\dagger}, \mathrm{T}^{*}\right), \\ \mathcal{L}_{\text {map }}=\left\|\Delta \mathcal{N}_{d}\right\|_{2}^{2}+\left\|\nabla \mathcal{N}_{d}\right\|_{2}^{2}, \end{array} Lsha = β†−β∗ 22,Lgeo = Laplacian (T†,T∗),Lmap =∥ΔNd∥22+∥∇Nd∥22,
- 作者说可以得到非常高的细节质量(后续验证,时间复杂度上是个大问题)
- 可微分渲染 R m \mathcal{R}_{m} Rm参考nvdiffrec
头发
除了生成面部几何形状外,我们的管道还包括生成与输入提示相匹配的真实发型。与几何生成过程类似,我们使用CLIP从输入提示中选择匹配分数最高的发型候选。我们的头发数据集包含由专业艺术家创建的 16 种发型。我们首先选择与提示最匹配的发型,然后通过在几何的头部渲染头发来选择预定义的头发颜色。这导致详细的面部资产与相应的发型紧密匹配输入提示。
纹理生成
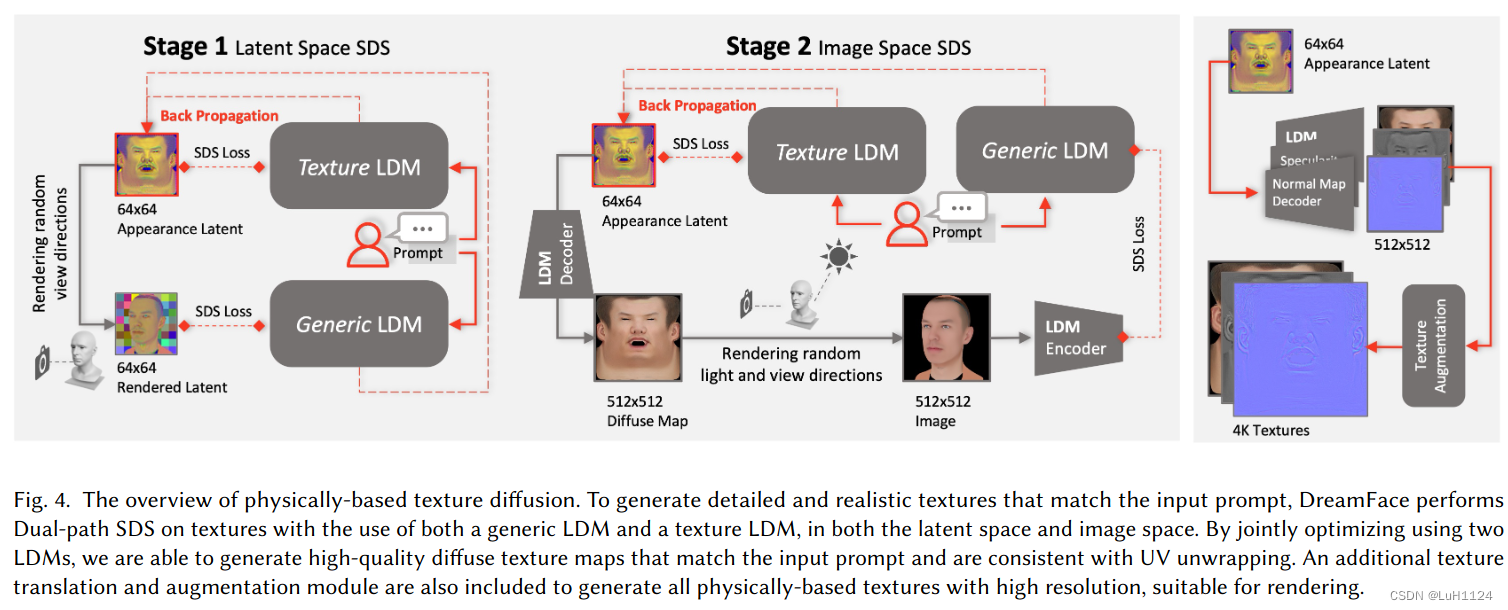
- 生成外观,由纹理空间中的漫反射、镜面反射和法线贴图控制;除了与输入提示紧密匹配的详细几何图形。除了有效地传达输入提示的描述特征外,还需要纹理图与UV展开的一致性以确保与现有计算机图形生产管道的兼容性。
- 因此提出了一种双路径机制,利用两种扩散模型联合优化纹理,一种针对不同生成能力的通用扩散模型从一般的提示输入,以及一种新颖的纹理,以确保UV空间中的纹理规范以预测与预测的几何和文本提示一致的中性面部资产。【简单来说用一个SD,一个专门训练的纹理Diffusion来联合优化面部纹理】
- 在潜在空间和图像空间中执行分数蒸馏采样(SDS),其中潜在的优化为细粒度合成提供了紧凑的先验;随后再用超分模型将纹理提升到4K分辨率
训练纹理diffusion
- 使用LDM在潜空间进行扩散,为了加强纹理规范,同时保持生成能力,作者首先收集不同的UV纹理数据集,然后通过对数据集上预训练的LDM进行微调来训练我们的纹理LDM,以监督纹理规范的一致性。
- 多个来源收集UV纹理数据集,包括使用多视图光度捕获系统、公共数据集[FaceScape]和商业数据集[3DScanStore]的纹理捕获的面部扫描。不同的数据集合并的数据使用不同的标准获得,并表现出不同的形式,包括UV展开、艺术修改和照明条件的变化。为了确保我们研究目的的一致性和适当性,艺术家和研究人员团队进行了广泛的统一和注释。
U = { U d , U s , U n } \mathcal{U}=\left\{U_{\mathrm{d}}, U_{\mathrm{s}}, U_{\mathrm{n}}\right\} U={Ud,Us,Un}分别为漫反射贴图、反射贴图和法线贴图,要求注释者根据特定规则生成相应的文本描述 T \mathcal{T} T,无几何的纹理,渲染于tempalate mesh(应该是平均几何)
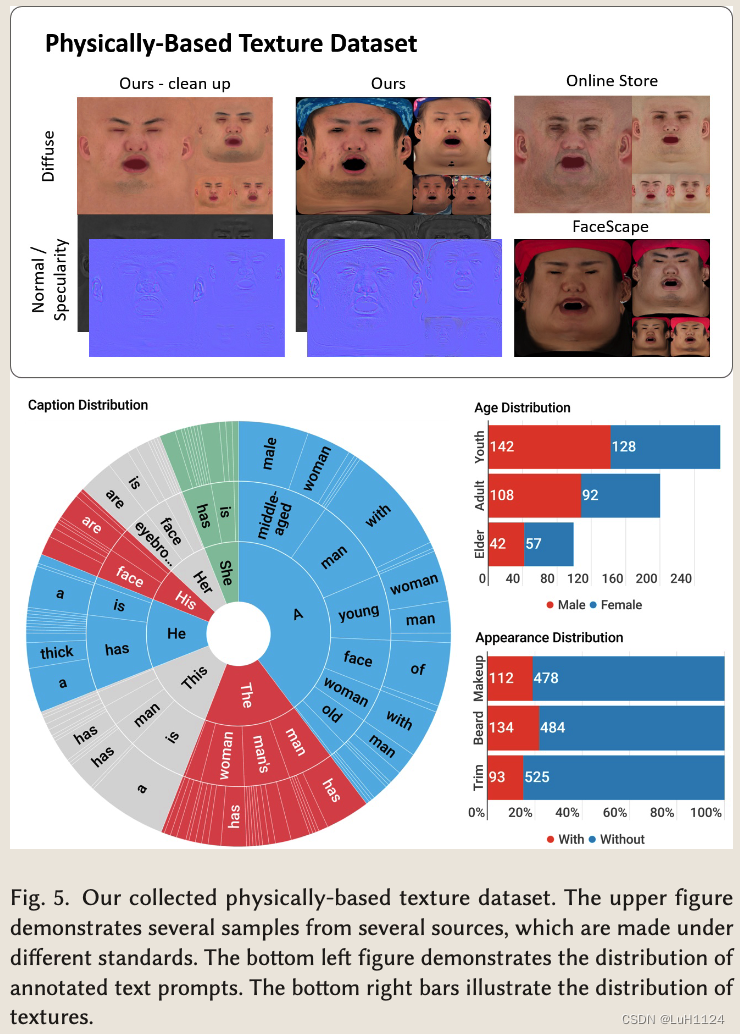
- 除了文本-纹理数据对,还包括非脸部区域mask,用于帮助LDM理解
- 数据一部分没有去除光照,为了统一使用一种新的提示条有调优方法,同时保证训练的纹理LDM只能在所需的域Ωd内创建漫反射映射,但可以在期望域和不需要的域{Ωd, Ωu}中的所有纹理-文本对上进行训练。如图6,作者利用提示调优来学习连续文本提示,即词嵌入向量
C
d
C_d
Cd(desired)和
C
u
C_u
Cu(undesired),其中mask为条件(不是VAE的Encoder编码,而是scale变换到潜空间分辨率后cat到Unet的起始端)。
L L D M ( ϵ θ , C ) = E ( U d , T ) , t [ ∥ ϵ θ ( E ( U d ) t , t , E t e x t ( Q ( T , C ) ) , B ) − ϵ ∥ 2 2 ] \mathcal{L}_{\mathrm{LDM}}\left(\epsilon_{\theta}, \mathcal{C}\right)=\mathbb{E}_{\left(\mathrm{U}_{\mathrm{d}}, \mathcal{T}\right), t}\left[\left\|\epsilon_{\theta}\left(\mathcal{E}\left(\mathrm{U}_{\mathrm{d}}\right)_{t}, t, \mathcal{E}_{\mathrm{text}}(\mathcal{Q}(\mathcal{T}, \mathcal{C})), \boldsymbol{B}\right)-\epsilon\right\|_{2}^{2}\right] LLDM(ϵθ,C)=E(Ud,T),t[∥ϵθ(E(Ud)t,t,Etext(Q(T,C)),B)−ϵ∥22]
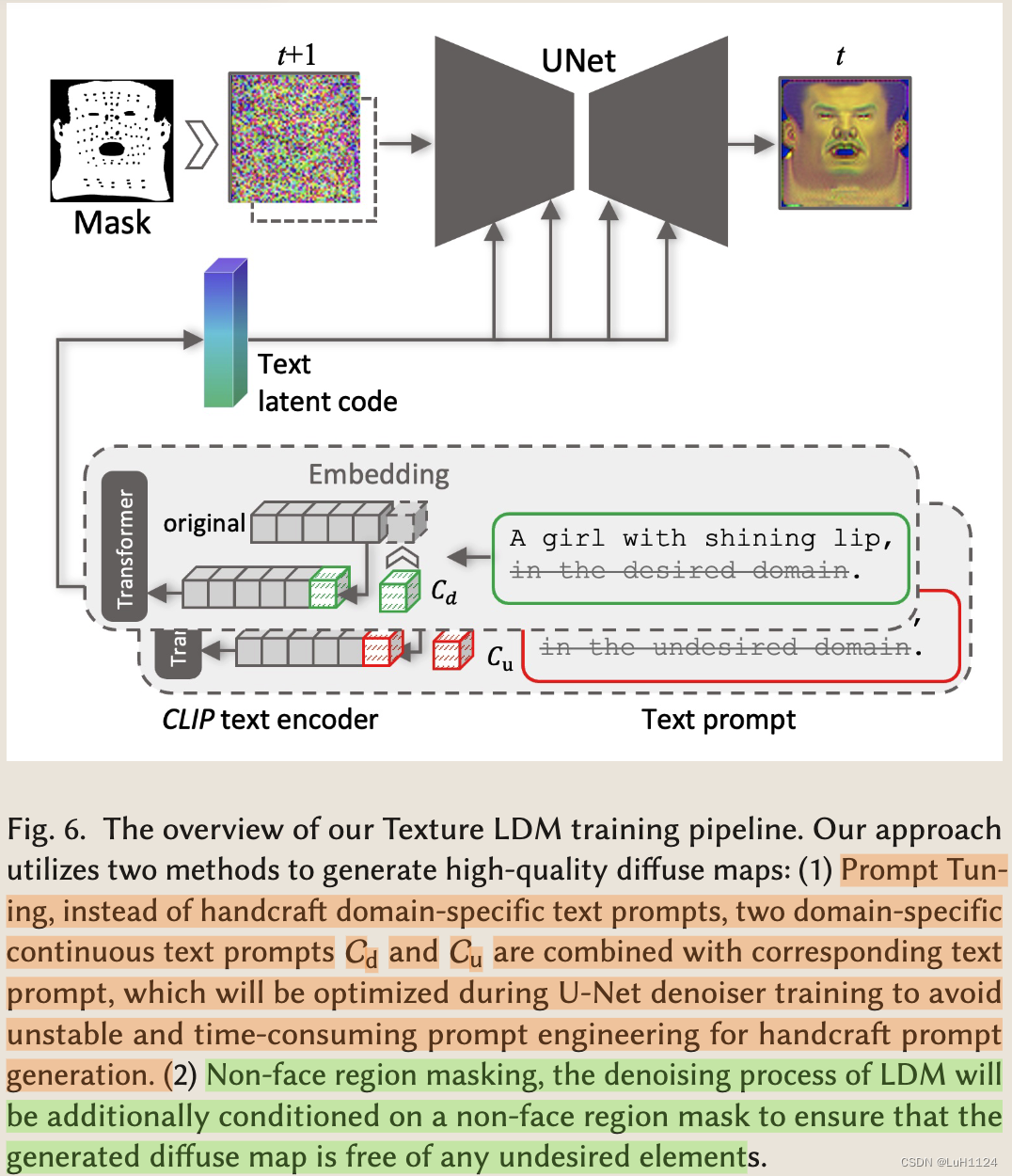
两阶段双流外观优化
分两个阶段进行SDS,首先优化潜在空间中的纹理(res 64),然后在图像空间进行细化。这种两阶段优化方案允许在保留高质量纹理生成的同时计算效率。
- 第一阶段(Lantent Space)使用双流优化在潜在空间中生成纹理,这为细粒度合成提供了紧凑的先验
1.1 潜空间优化的时候,SD需要将lantent进行可微渲染,纹理DM则直接对latant进行优化
1.2 观察到均匀采样t会导致难以优化,选择顺序降低采样步长t的间隔,即从 t m a x → 0 t_{max}\rightarrow0 tmax→0 - 第二阶段(Image Space)应用双流优化来强制纹理的UV地图规范并保留泛化能力,但应用详细的法线贴图和随机照明来增强图像空间的外观细节,同时将照明从漫反射贴图中分离出来。
2.1 将lantent解码后使用随机相机、光照和详细法线贴图增强SD的优化过程
基于物理的纹理生成
可靠的纹理资产需要基于物理的渲染组件,包括高分辨率漫反射、镜面反射和法线贴图,
- 使用收集的基于物理的渲染,训练了两个额外镜面反射和法线贴图解码器
D
s
,
D
n
\mathcal{D}_{\mathrm{s}}, \mathcal{D}_{\mathrm{n}}
Ds,Dn,Loss与LDM原文相同
L t e x = ℓ ( D s ( u d ) , U s ) + ℓ ( D n ( u d ) , U n ) \mathcal{L}_{\mathrm{tex}}=\ell\left(\mathcal{D}_{\mathrm{s}}\left(u_{\mathrm{d}}\right), \mathrm{U}_{\mathrm{s}}\right)+\ell\left(\mathcal{D}_{\mathrm{n}}\left(u_{\mathrm{d}}\right), \mathrm{U}_{\mathrm{n}}\right) Ltex=ℓ(Ds(ud),Us)+ℓ(Dn(ud),Un) - 在从相应的漫反射映射输入生成镜面反射和法线映射后,将它们提升到4K分辨率,以在保留身份信息的同时添加孔级细节。
2.1 具体来说,首先微调人脸恢复网络 RestoreFormer 在数据集上以 512 × 512 的分辨率增强面部细节
2.2 然后我们细化超分辨率模型 RealESRGAN使用我们的高分辨率纹理进一步生成4096 × 4096个基于物理的纹理。
2.3 最终的正常纹理合成面部的孔隙级细节,渲染过程中还使用了几何优化过程中的详细切线贴图。
动画生成
除了生成精细的人脸几何和基于物理的纹理外,作者还赋予了生成的面部资产的可动画性
- 方案1 基于统一拓扑使用blendshape的通用可动画性,但没用这个策略
- 方案2 开发了一个交叉身份几何超网络,它生成特定于人的表情,并作为表情空间的通用先验(参考Authentic Volumetric Avatars from a Phone Scan,一篇基于神经渲染的3D人脸驱动文章,采用变化的表情和不变的中性人脸联合训练表情潜向量,实现每个神经渲染基元的空间变换,从而影响渲染的表情)
2.1 在中性几何上调节几何生成器,并使用各种表情的大量几何图形训练超网络
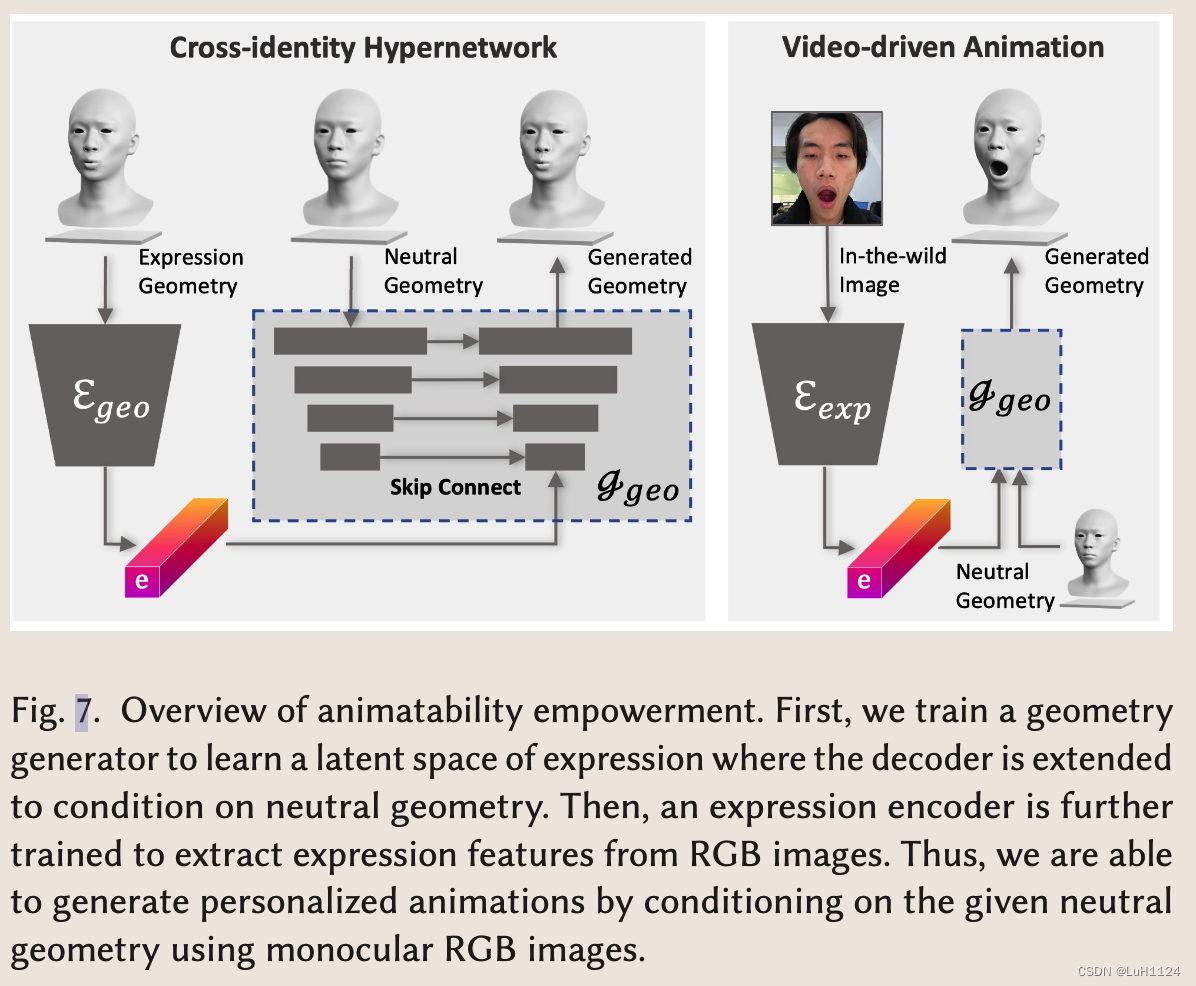
2.2 几何表情编码器将不同的面部表情编码为一个统一的表达式潜在代码,而几何生成器使用该代码以及特定身份的中性几何形状,生成具有相应表达式的期望面部几何形状。作者使用具有各种表情和身份的几何图形数据集,以自我监督的方式训练这个几何超网络。一旦经过训练,几何生成器
G
g
e
o
\mathcal{G}_{geo}
Ggeo 能够使用统一的表达式潜在代码为特定身份生成具有所需表达式的几何形状
2.3 几何生成器 Ggeo 训练好后,基于视频序列训练了一个图像表情编码器 Eexp 从 RGB 图像中提取统一的表达式潜在代码
2.4 为了训练几何生成器具有对各种身份的泛化能力和细粒度表情细节的准确捕获,捕获了一个数据集,其中包括大量不同表情和身份的静态扫描,以及来自各种表演者的几个动态性能序列。数据集由 38400 个网格和 614400 张图像组成,这些图像来自不同性别、年龄和种族的 300 个身份。
2.5 训练代价:训练几何超网络
E
g
e
o
\mathcal{E}_{geo}
Egeo的第一阶段,
D
g
e
o
\mathcal{D}_{geo}
Dgeo需要5天才能收敛。第二阶段训练图像编码器
E
e
x
p
\mathcal{E}_{exp}
Eexp需要48小时才能收敛。所有训练都是使用带有 AdaBelief 优化器的 Pytorch 和学习率 5e-5 完成的,使用单个 Nvidia A6000 GPU。
实验结果
实现细节
- 依靠通用的LDM和纹理LDM进行几何生成和纹理扩散。在实现中,使用SDv1-5作为通用LDM,clip-vit-large-patch14作为文本编码器。
- 对于纹理LDM,复制了一个通用的LDM,并对其进行了微调,在两个Nvidia A6000 GPU上训练纹理LDM150个周期,大约需要12小时。
- 在几何生成过程期间,根据预定义的分布从 ICT-FaceKit 中采样一百万个候选者,然后执行 300步细节雕刻。
- 在纹理扩散阶段,我们在潜在空间中执行200步双路径优化,图像空间执行200步。通过我们的两阶段设计,基于 SDS 的生成过程非常有效,能够在单个 Nvidia A6000 GPU 上 5 分钟内生成高质量的面部资产。
More Results
论文展示了更多的视觉对比和消融实验,可以看论文实验部分。
限制
- 一个限制是,虽然我们已经将发型生成纳入我们的框架,但目前不可能生成完整的面部成分,如眼睛和嘴巴内部。特别是眼睛的建模和渲染带来了尚未完全解决的重大技术挑战。
- 另一个限制是,作为基于提示条件扩散模型的框架,DreamFace 受到这些模型能力的限制。例如,虽然基于 GAN 的方法能够轻松反转给定样本,但扩散模型的反演尚未得到充分探索。虽然DreamFace的性能受到扩散模型研究的最新技术的影响,但该领域的进一步发展可能会改善我们的结果。最后,虽然我们的框架通过混合形状的原生支持和增强动画方案展示了强大的动画能力,但在基于提示的动画控制领域仍有进一步研究潜力。面部运动的生成,包括生动的表达和细微的表现,是一个特别有趣且具有挑战性的问题,仍有待解决。(感觉HiFiFace提供了一种解决途径,将表情变化导致的位移贴图建模为了线性组合,可以生成更为自然和稳定的运动变化,但可惜还未开源)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









