







免责声明:
- 笔记来源:本系列所有笔记均整理自 B站·王道考研·数据结构 视频教程。
- 参考书籍:《2021年数据结构考研复习指导》,王道论坛所著,电子工业出版社出版,ISBN :9787121379819。
1 栈
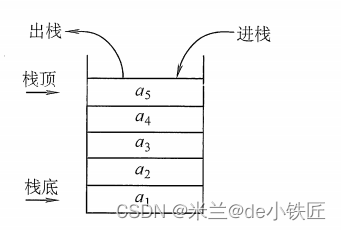
栈 Stack,是一种只允许在一端进行插入或者删除的线性表。
特点:
- 只允许在栈顶插入或者删除
- 后进先出 LIFO
1.1 栈的顺序存储结构
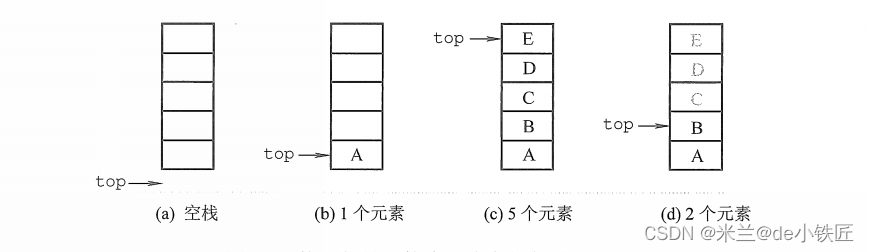
采用顺序存储的栈,称为顺序栈。
#include <iostream>
using namespace std;
// 栈最大容量
#define MaxSize 10
// 顺序存储的方式实现栈
struct SqStack {
// 静态数组中存储元素
int data[MaxSize];
int top; // 栈顶指针
};
// 初始化一个空栈
void InitSqStack(SqStack& stack) {
// 栈顶指针设置为-1,便于区分是否为空栈
stack.top = -1;
}
// 判断是否为空栈
bool SqStackIsEmpty(SqStack& stack) {
// 通过栈顶指针是否为 -1 来判断
return stack.top == -1;
}
// 元素入栈
bool SqStackPush(SqStack& stack, int e) {
if (stack.top == MaxSize - 1) {
// 栈已经满了
return false;
}
// 先将栈顶指针往后移动一位
// 再把元素存入栈顶位置
stack.data[++stack.top] = e;
return true;
}
// 元素出栈
bool SqStackPop(SqStack& stack, int& x) {
if (stack.top == -1) {
//空栈
return false;
}
// 先将当前值存入x返回
// 再将栈顶指针往前移动一位
// 此处只是逻辑上删除,实际上数据还存在内存中
x = stack.data[stack.top--];
return true;
}
// 返回栈顶元素
bool GetSqStackTop(SqStack& stack, int& x) {
if (stack.top == -1) {
//空栈
return false;
}
x = stack.data[stack.top];
return true;
}
1.2 栈的链式存储结构
采用链式存储的栈,称为链栈。

使用链式存储结构实现栈时,推荐使用不带头结点的链表形式。
#include <iostream>
using namespace std;
// 一个链栈节点定义
struct StackNode {
int data; // 当前节点值
StackNode* next; // 下一个节点指针
};
// 一个链栈
typedef StackNode* LinkStack;
// 使用不带头结点方式初始化一个空链栈
bool InitLinkStack(LinkStack& stack) {
// 初始化为空链表
stack = NULL;
return true;
}
// 判断链栈是否为空
bool LinkStackIsEmpty(LinkStack& stack) {
return stack == NULL;
}
// 入栈
bool LinkStackPush(LinkStack& stack, int e) {
// 创建新的节点
StackNode* p = new StackNode;
if (p == NULL) {
// 分配内存失败
return false;
}
// 先将元素存入节点
p->data = e;
// 头指针指向的是第一个节点
// 将原来的第一个节点作为新节点的后继节点
p->next = stack;
// 头指针重新指向新节点
stack = p;
return true;
}
// 出栈
bool LinkStackPop(LinkStack& stack, int& e) {
if (stack == NULL) {
// 空栈
return false;
}
// 当前要删除的节点就是第一个节点
// 头指针 stack 指向的也就是第一个节点
// 先将值以变量引用形式返回
e = stack->data;
// 指向当前要删除的节点指针
StackNode* p = stack;
// 头指针指向下一个节点
stack = stack->next;
// 释放当前节点内存
delete p;
return true;
}
// 返回栈顶元素
bool GetLinkStackTop(LinkStack& stack, int& x) {
if (stack == NULL) {
// 空栈
return false;
}
x = stack->data;
return true;
}
// 释放整个链栈空间
void DestoryLinkStack(LinkStack& stack) {
// 指向当前要删除的节点指针
StackNode* p;
while (stack != NULL) {
p = stack;
// 头指针指向下一个节点
stack = stack->next;
// 释放当前节点内存
delete p;
}
}
int main() {
// 创建一个空栈
LinkStack stack;
InitLinkStack(stack);
// 判断栈是否为空
cout << LinkStackIsEmpty(stack) << endl; // true
// 元素入栈
LinkStackPush(stack, 1);
LinkStackPush(stack, 2);
LinkStackPush(stack, 3);
LinkStackPush(stack, 4);
// 判断栈是否为空
cout << LinkStackIsEmpty(stack) << endl; // false
// 获取栈顶元素
int top;
GetLinkStackTop(stack, top);
cout << top << endl; // 4
// 销毁整个链栈
DestoryLinkStack(stack);
// 元素出栈
/*int a1, a2, a3, a4;
LinkStackPop(stack, a1);
LinkStackPop(stack, a2);
LinkStackPop(stack, a3);
LinkStackPop(stack, a4);
cout << a1 << "," << a2 << "," << a3 << "," << a4 << endl;*/
// 判断栈是否为空
cout << LinkStackIsEmpty(stack) << endl; // true
return 0;
}
2 队列
队列 Queue,是一种只允许在一端进行插入另一端进行删除的线性表。
特点:
- 在队尾插入,在队头删除
- 先进先出FIFO

2.1 队列的顺序存储结构
队列的顺序存储实现是指分配一块连续的存储空间来存放队列中的元素。
- 使用一个静态数组来存储数据 data,数组长度即队列最打容量 MAX_SIZE
- 设置两个指针
- front 队头指针指向队头元素
- rear 队尾指针指向队尾元素的下一个位置(下一个元素插入的位置)
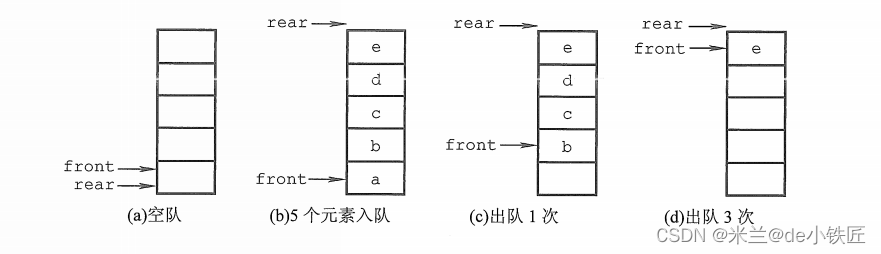
初始状态下,队列的头指针指向 0 位置,队列的尾指针也指向0位置,这样可以通过队头指针与队尾指针是否指向同一个位置(front == rear)来判断队列是否为空;
当一个元素从队尾进入时(若队列未满),队尾指针加1;当一个元素从队头出去时(若队列不为空),队头指针加1。但是如何判断队列已满?能否通过 (rear == MAX_SIZE) 来判断?
假如队列最大容量MAX_SIZE = 5,有5个元素依次入队,然后再依次出队,当队列中只剩下一个元素时,队头指针与队尾指针指向了同一个位置,而且此时 rear 与 MAX_SIZE 相等,无法判断队列是否已满。
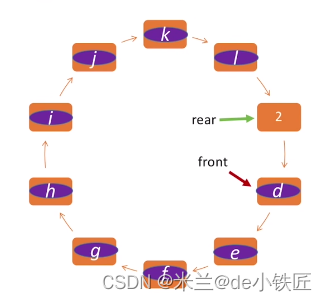
判断队列是否已满——循环队列
通过上面的顺序队列存在的确定,引出了循环队列。将顺序队列从逻辑上看作一个环:
- 初始时,队首队尾指针指向相同的位置,表示空队列:front = rear = 0
- 入队,队尾指针移动一个位置:rear = (rear + 1) % MAX_SIZE
- 出队,队首指针移动一个位置:front = (front + 1) % MAX_SIZE
- 队列长度:(rear + MAX_SIZE - front) % MAX_SIZE
- 判断队列是否已满:通过牺牲一个单元来区分是否已满,如果队尾指针的下一个位置(顺时针方向)就是队头指针,那么此时队列已满,即 (rear + 1) % MAX_SIZE == front
#include <iostream>
using namespace std;
#define MAX_SIZE 5
// 采用顺序存储实现队列
struct SqQueue {
int data[MAX_SIZE]; // 存储数据的静态数组
int front;// 队头指针
int rear; // 队尾指针
};
// 初始化一个空队列
void InitSqQueue(SqQueue& queue) {
// 初始时,队头队尾指针都指向第0个位置
queue.front = 0;
queue.rear = 0;
}
// 判断队列是否为空
bool SqQueueIsEmpty(SqQueue& queue) {
// 通过队头与队尾指针是否指向同一个位置来判断队列是否为空
return queue.front == queue.rear;
}
// 判断队列是否已满
bool SqQueueIsFull(SqQueue& queue) {
return (queue.rear + 1) % MAX_SIZE == queue.front;
}
// 获取队列长度
int GetSqQueueLength(SqQueue& queue) {
return (queue.rear + MAX_SIZE - queue.front) % MAX_SIZE;
}
// 入队(采用循环队列方式来解决队列假溢出问题,顺时针方向入队)
bool SqQueueIn(SqQueue& queue, int e) {
// 判断队列是否已满
// 采用循环队列方式实现,这种方式需要浪费一个存储位置
// 用来判断队列是否已满
if ((queue.rear + 1) % MAX_SIZE == queue.front) {
// 队列已满
return false;
}
// 将新元素入队
queue.data[queue.rear] = e;
// 重新计算出新的队尾指针指向
queue.rear = (queue.rear + 1) % MAX_SIZE;
return true;
}
// 出队(采用循环队列方式来解决队列假溢出问题,顺时针方向出队)
bool SqQueueOut(SqQueue& queue, int& x) {
if (queue.front == queue.rear) {
// 队列为空
return false;
}
// 取出队头元素
x = queue.data[queue.front];
// 重新计算出新的队头指针指向
queue.front = (queue.front + 1) % MAX_SIZE;
return true;
}
// 获取队头元素
bool GetSqQueueHead(SqQueue& queue, int& x) {
if (queue.front == queue.rear) {
// 队列为空
return false;
}
// 取出队头元素
x = queue.data[queue.front];
return true;
}
使用该方式的缺点是,需要牺牲一个存储位置来区分队列是否已满。
判断队列是否已满——元素个数
可以在队列定义中增加一个表示元素个数的成员 size:
- 初始:front = rear = 0 , size = 0
- 队列是否为空:size == 0
- 队列是否已满:size == MAX_SIZE
- 入队:rear ++ , size ++
- 出队: front ++ ,size –
- 队列为空或者队列已满时都存在 front = rear
判断队列是否已满——出入队标识
可以在队列定义中增加一个表示 导致 front = rear 的原因的成员 tag:
- 如果最近一次是入队操作导致 front = rear ,则 tag = 1,此时表示队列已满
- 如果最近一次是出队操作导致 front = rear ,则 tag = 0,此时表示队列为空
2.2 队列的链式存储结构
队列的链式存储称为链队列,是一个带有队头指针和队尾指针的单链表:
- 头指针指向队头节点(同样,链式队列可以使用带头接或者不带头结点方式实现)
- 尾指针指向队尾节点(即最后一个节点,与顺序队列不一样,顺序队列的尾指针指向的是队尾元素的下一个位置)
#include<iostream>
using namespace std;
// 链式队列节点
struct LQNode {
int data;
LQNode* next;
};
// 链式队列
struct LinkQueue {
LQNode* front; // 队头指针,指向第一个节点或者指向头结点
LQNode* rare; // 队尾指针,指向最后一个节点
};
// 带头结点的链式队列 初始化
void InitLinkQueue(LinkQueue& queue) {
// 初始时,队头指针、队尾指针都指向头结点
queue.front = queue.rare = new LQNode;
// 头结点的next指针域指向空
queue.front->next = NULL;
}
// 带头结点的链式队列 判断是否为空
bool LinkQueueIsEmpty(LinkQueue queue) {
// 通过头指针与尾指针是否指向同一个位置判断
return queue.front == queue.rare;
}
// 带头结点的链式队列 入队
bool LinkQueueIn(LinkQueue& queue, int e) {
// 创建一个新的节点
LQNode* s = new LQNode;
if (s == NULL) {
// 分配内存失败
return false;
}
// 将数据存入新的节点
s->data = e;
// 新节点应该是最后一个节点,它的指针域应该指向NULL
s->next = NULL;
// 将新的节点插入到队尾(只能从队尾插入)
queue.rare->next = s;
// 队尾指针后移,指向新插入的节点
queue.rare = s;
return true;
}
// 带头结点的链式队列 出队
bool LinkQueueOut(LinkQueue& queue, int& x) {
if (queue.front == queue.rare) {
return false; // 空队列
}
// 指向要出队的节点
// 队首元素是头结点的后继节点
LQNode* p = queue.front->next;
// 先使用引用变量将要出队的元素返回
x = p->data;
// 修改头结点的后继节点
queue.front->next = p->next;
// 如果此时是最后一个元素出队
if (queue.rare == p) {
// 队尾指针也指向头结点
queue.rare = queue.front;
}
// 释放接口空间
delete p;
return true;
}
// 不带头结点的链式队列 初始化
void InitLinkQueue1(LinkQueue& queue) {
// 初始时,队头指针、队尾指针都指向NULL
queue.front = queue.rare = NULL;
}
// 不带头结点的链式队列 判断是否为空
bool LinkQueueIsEmpty1(LinkQueue queue) {
// 通过第一个节点是否为空判断
return queue.front == NULL;
}
// 不带头结点的链式队列 入队
bool LinkQueueIn1(LinkQueue& queue, int e) {
// 创建一个新的节点
LQNode* s = new LQNode;
if (s == NULL) {
// 分配内存失败
return false;
}
// 将数据存入新的节点
s->data = e;
// 新节点应该是最后一个节点,它的指针域应该指向NULL
s->next = NULL;
// 如果当前队列为空,需要特殊处理
if (queue.front == NULL) {
// 直接将队头指针指向新的节点
queue.front = s;
// 队尾指针也指向新的节点
queue.rare = s;
}
// 如果当前队列不是空
else {
// 将新的节点插入到队尾(只能从队尾插入)
queue.rare->next = s;
// 队尾指针后移,指向新插入的节点
queue.rare = s;
}
return true;
}
// 不带头结点的链式队列 出队
bool LinkQueueOut1(LinkQueue& queue, int& x) {
if (queue.front == NULL) {
// 空队列
return false;
// 指向此次要出对的节点
LQNode* p = queue.front;
// 先使用引用变量将要出队的元素返回
x = p->data;
// 修改队头指针,指向下一个节点
queue.front = p->next;
// 如果此次是最后一个节点出队,需要特殊处理
if (queue.rare = p) {
// 队尾指针 队头指针都指向空
queue.rare = NULL;
queue.front = NULL;
}
// 释放内存
delete p;
return true;
}
}
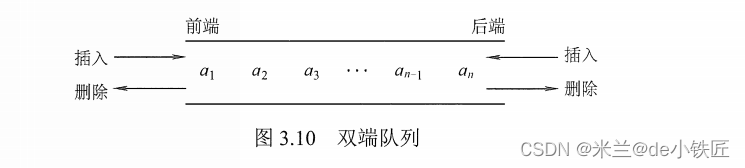
2.3 双端队列
双端队列是一种两端都可以简写插入和删除操作的队列。
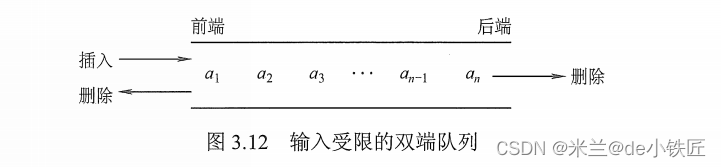
输出受限的双端队列:一端允许插入和删除操作,另一端只允许插入操作的双端队列。

输入受限的双端队列:一端允许插入和删除操作,另一端只允许删除操作的双端队列。
3 栈与队列的应用
3.1 栈与括号匹配
程序代码中的括号(小括号、中括号、大括号)匹配问题:

基于栈的特性实现括号匹配思想:
- 开始扫描括号
- 如果是左括号,压入栈顶;扫描下一个
- 如果是右括号,弹出栈顶的左括号与之匹配,如果栈为空则或者左右括号不匹配则失败,结束;否匹配成功,继续扫描下一个
- 所有括号扫描完了且都匹配成功,最后检查栈是否为空,不为空则表示匹配失败
代码实现:
# include <iostream>
namespace TEST1 {
#define MaxSize 10
// 顺序栈定义(也可以使用链栈形式)
struct SqStack {
char data[MaxSize]; // 静态数组存放栈中的元素
int top; // 栈顶指针
};
// 初始化一个空栈栈
void InitStack(SqStack& stack) {
// 栈顶指针指向 -1 位置表示空栈
stack.top = -1;
}
// 判断栈是否为空
bool StackIsEmpty(SqStack& stack) {
return stack.top == -1;
}
// 元素压入栈顶
bool InStack(SqStack& stack, char e) {
if (stack.top == MaxSize - 1) {
// 栈已满
return false;
}
// 先将栈顶指针后移一位
// 再将元素存入
stack.data[++stack.top] = e;
return true;
}
// 元素出栈
bool OutStack(SqStack& stack, char& x) {
if (stack.top == -1) {
// 栈为空
return false;
}
x = stack.data[stack.top--];
return true;
}
// 判断str中的括号序列是否合法
// 假设str中的括号序列只由 ( [ { } ] ) 组成
bool BracketCheck(char str[], int n) {
char top; // 用于接收栈顶元素
// 创建一个栈,用于存储左括号
SqStack stack;
// 初始化为空栈
InitStack(stack);
// 开始扫描代匹配括号
for (int i = 0; i < n; i++) {
// 如果扫描到 [ ( { 三种左括号,则压入栈
if (str[i] == '(' || str[i] == '[' || str[i] == '{') {
InStack(stack, str[i]);
}
// 如果扫描到右括号
else {
// 先判断栈是否为空
if (StackIsEmpty(stack)) {
// 栈为空则表示匹配失败
return false;
}
else {
// 栈不为空,则弹出栈顶元素
OutStack(stack, top);
// 分别进行匹配
if (str[i] == ')' && top != '(') {
// 右小括号匹配失败
return false;
}
if (str[i] == ']' && top != '[') {
// 右中括号匹配失败
return false;
}
if (str[i] == '}' && top != '{') {
// 右大括号匹配失败
return false;
}
}
}
}
// 至此,所有括号匹配成功,需要检查栈中是否还有剩余的左括号,如果有,则失败
return StackIsEmpty(stack);
}
}
int main() {
using namespace TEST1;
using std::cout;
char str[] = { '{','[','(','[',']',')','}' };
cout << TEST1::BracketCheck(str, 7);
return 0;
}
3.2 栈与表达式求值
表达式
我们熟悉的表达式:

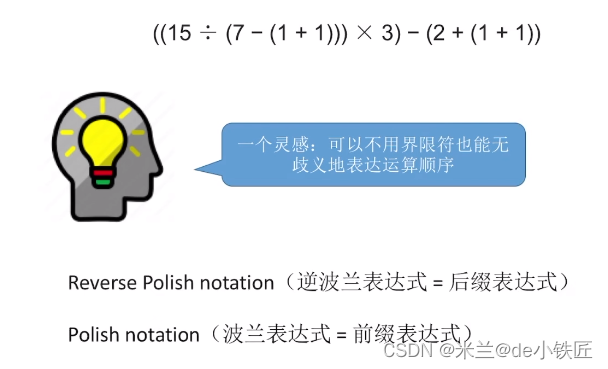
波兰表达式与逆波兰表达式:
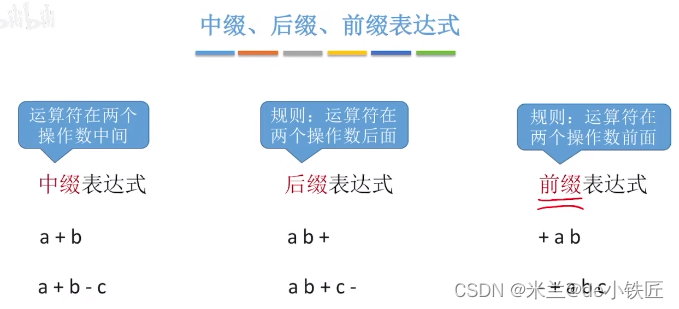
中缀表达式与后缀表达式
中缀转后缀 手算

如果运算顺序不唯一,对应的后缀表达式也不唯一,例如:
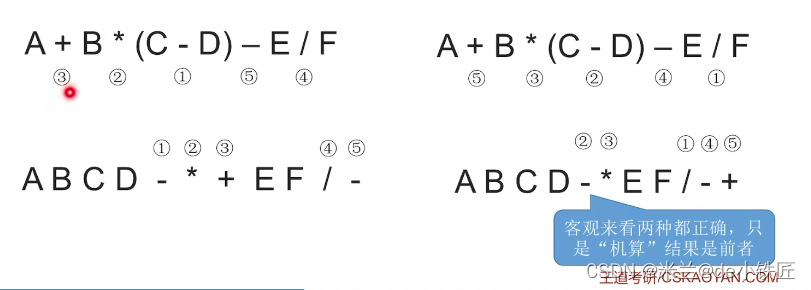
按照算法确定性的特点:同样的输入,应该只得到同样的输出。
对于不同运算顺序能够得到相同运算结果的情况,可以通过左优先原则(只要左边的元运算符可以先运算,那就先运算左边的)
- 算法计算后缀表达式时优先选择靠左的运算符
- 检验算法正确性的时候也优先选择靠左的运算符
后缀表达式计算 手算

通过栈由中缀表达式转为后缀表达式,并计算后缀表达式



中缀表达式与前缀表达式
中缀表达式转前缀表达式 手算

前缀表达式手算

3.3 栈与递归
函数调用的特点:最后调用的函数最先执行完毕,与栈先进后出的特点一致。
函数调用时需要一个栈,用来存储:
- 调用返回的地址
- 实参
- 局部变量
栈在递归中的应用:递归调用时,函数调用栈可称为“递归工作栈”,每进入一层递归,就将递归调用所需的信息压入栈顶

递归算法示例:
// 递归算法求阶乘
int Factorial(int n) {
if (n == 1 || n == 0) {
return 1;
}
else {
return n * Factorial(n - 1);
}
}
// 递归算法求斐波那契数列
int Fibonacci(int n) {
if (n == 0) {
return 0;
}
else if(n == 1){
return 1;
}
else {
return Fibonacci(n - 1) + Fibonacci(n - 2);
}
}
3.4 队列与层次遍历
队列在树的层次遍历中的应用
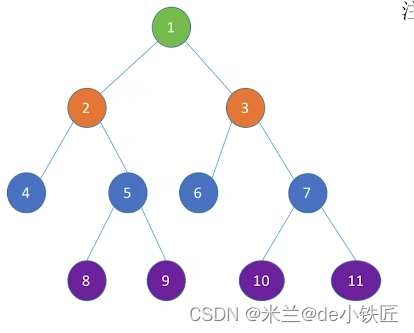
比如,层次遍历这棵树:
- 根结点 1 入队,作为队头
- 处理队头的子节点,2和3分别入队,然后1出队,2作为队头
- 处理队头的子节点,4和5分别入队,然后2出队,3作为队头
- 处理队头的子节点,6和7分别入队,然后3出队,4作为队头
- 处理队头的子节点,无子节点,4出队,5作为队头
- 处理队头的子节点,8和9分别入队,然后5出队,6作为队头
- 处理队头的子节点,无子节点,6出队,7作为队头
- 处理队头的子节点,10和11分别入队,然后7出队,8作为队头
- 处理队头的子节点,无子节点,8出队,9作为队头
- 处理队头的子节点,无子节点,9出队,10作为队头
- 处理队头的子节点,无子节点,10出队,11作为队头
根据出队的顺序得出中序遍历结果:1 2 3 4 5 6 7 8 9
3.5 队列与计算机
计算机中多个进程竞争使用同一有限资源时,可以使用一直常用的策略“先来先服务 FCFS”,多个进程排好队,轮流使用资源。

4 矩阵压缩存储
一维数组
C中一维数组的定义:
int arr[10];

- 数组下标从0开始
- 各个元素大小相同(此处为int,假设为 sizeof(int) 个字节),且物理上连续存放
- 第 i (0<=i<10)个元素的地址:
LOC + i * sizeof(int)
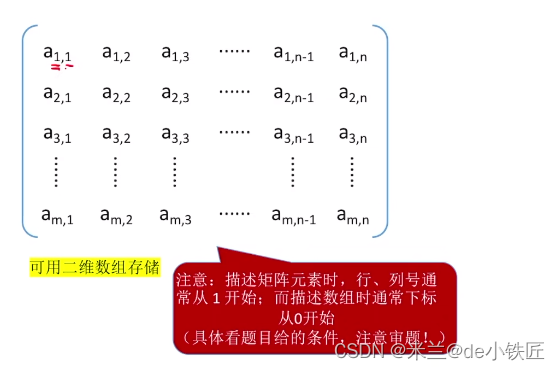
二维数组

m行n列的二维数组,求第 i 行 第 j 的元素地址:
- 行优先存储:
LOC +( i * n + j ) * sizeof(ElemType) - 列优先存储:
LOC + (j * m + i) * sizeof(ElemType)
普通矩阵
普通矩阵可以使用一个二维数组来存储
对称矩阵
对称矩阵压缩存储
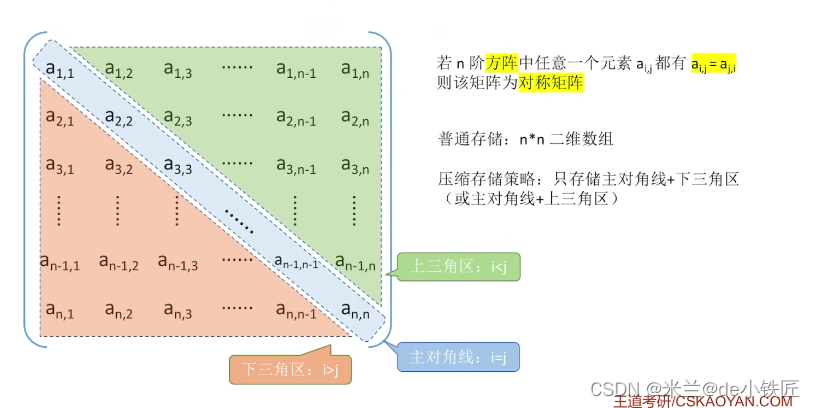
策略1:存储主对角线 + 下三角区

按行优先原则,将各元素存入一维数组中:

一维数组的大小 :1 + 2 + 3 + ... + n = (1 + n) * n / 2
如何通过矩阵的下标来访问实际存在一维数组中的元素?可以实现一个映射函数,将矩阵下标转为一维数组下标。
① 当 i >= j 时,访问的是下三角区域和中对角线上的元素

② 当i<j 时,访问的是上三角区域内的元素

三角矩阵
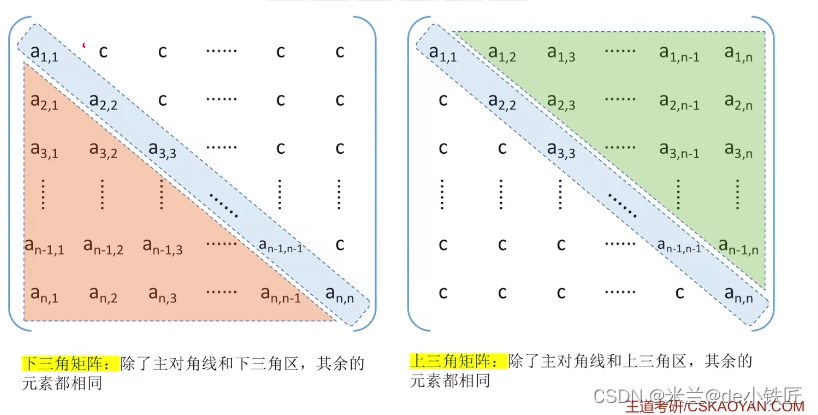
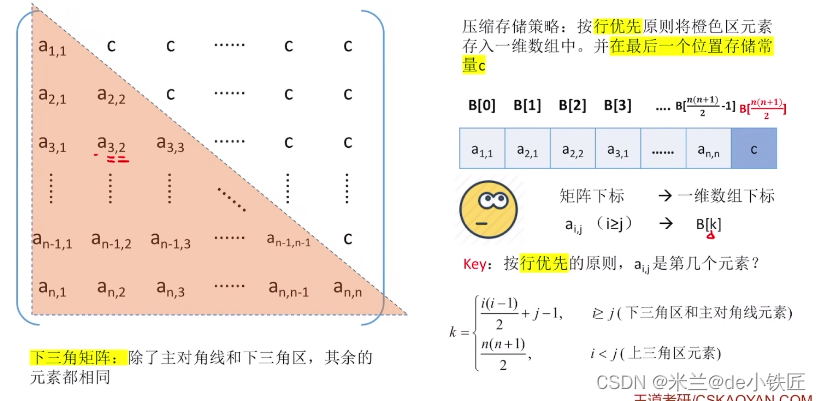
三角矩阵压缩存储
- 当 i>=j 时
- 当 i<j 时
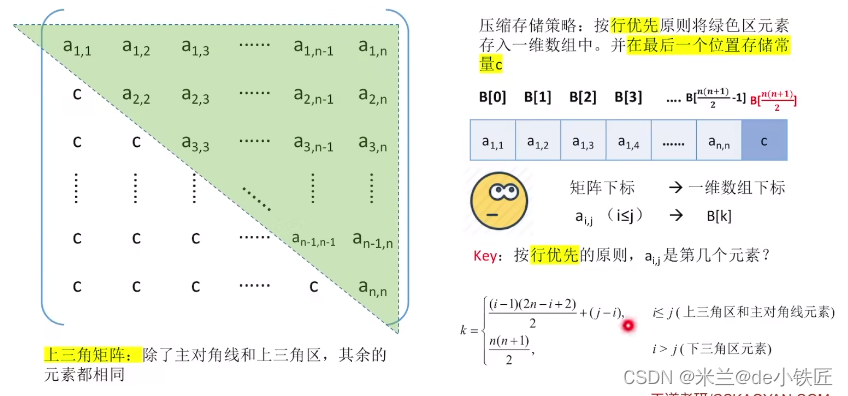
三对角矩阵
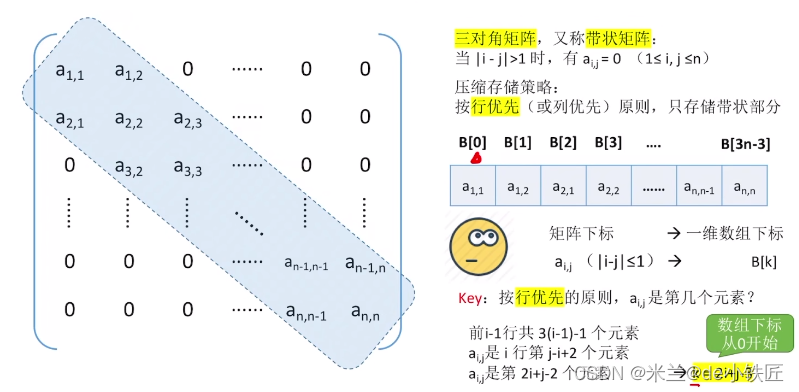

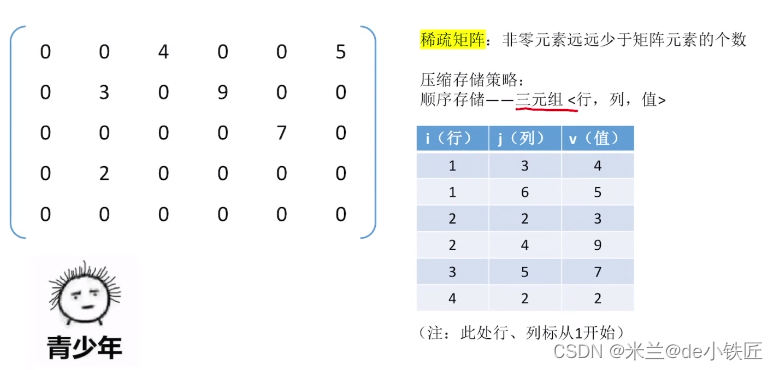
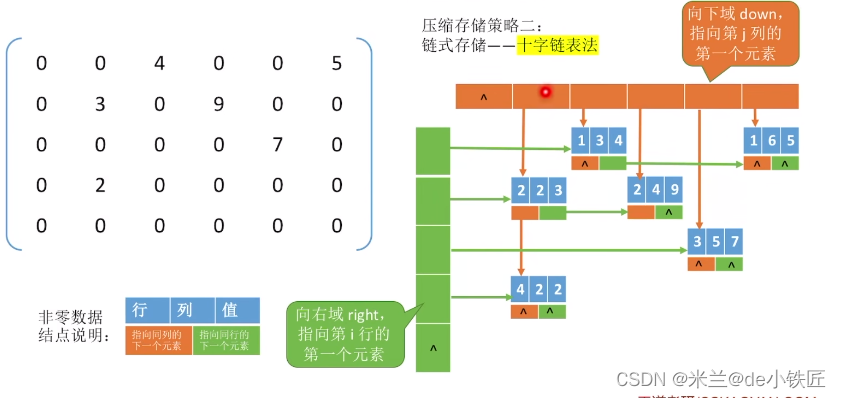
稀疏矩阵















 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









