







u1s1,这门课的assignment还是有点难度的,特别是assigment4(哀怨),放给大家参考啦~
有时间(需求)就把所有代码放到github上(好担心被河蟹啊)
先放下该课程相关链接:
Coursera | Introduction to Data Science in Python(University of Michigan)| quiz答案
Coursera | Introduction to Data Science in Python(University of Michigan)| Assignment1
Coursera | Introduction to Data Science in Python(University of Michigan)| Assignment2
Coursera | Introduction to Data Science in Python(University of Michigan)| Assignment3
Coursera | Introduction to Data Science in Python(University of Michigan)| Assignment4
嘿,顺便推广下自己的博客,以后CSDN的文章都会放到自己的博客的。
Coursera | Introduction to Data Science in Python(University of Michigan)| Assignment2
Assignment2
For this assignment you’ll be looking at 2017 data on immunizations from the CDC. Your datafile for this assignment is in assets/NISPUF17.csv. A data users guide for this, which you’ll need to map the variables in the data to the questions being asked, is available at assets/NIS-PUF17-DUG.pdf. Note: you may have to go to your Jupyter tree (click on the Coursera image) and navigate to the assignment 2 assets folder to see this PDF file).
Question 1
Write a function called proportion_of_education which returns the proportion of children in the dataset who had a mother with the education levels equal to less than high school (<12), high school (12), more than high school but not a college graduate (>12) and college degree.
This function should return a dictionary in the form of (use the correct numbers, do not round numbers):
{"less than high school":0.2,
"high school":0.4,
"more than high school but not college":0.2,
"college":0.2}
Code
def proportion_of_education():
# your code goes here
# YOUR CODE HERE
# raise NotImplementedError()
import pandas as pd
import numpy as np
df = pd.read_csv("assets/NISPUF17.csv", index_col=0)
EDUS=df['EDUC1']
edus=np.sort(EDUS.values)
poe={"less than high school":0,
"high school":0,
"more than high school but not college":0,
"college":0}
n=len(edus)
poe["less than high school"]=np.sum(edus==1)/n
poe["high school"]=np.sum(edus==2)/n
poe["more than high school but not college"]=np.sum(edus==3)/n
poe["college"]=np.sum(edus==4)/n
return poe
assert type(proportion_of_education())==type({}), "You must return a dictionary."
assert len(proportion_of_education()) == 4, "You have not returned a dictionary with four items in it."
assert "less than high school" in proportion_of_education().keys(), "You have not returned a dictionary with the correct keys."
assert "high school" in proportion_of_education().keys(), "You have not returned a dictionary with the correct keys."
assert "more than high school but not college" in proportion_of_education().keys(), "You have not returned a dictionary with the correct keys."
assert "college" in proportion_of_education().keys(), "You have not returned a dictionary with the correct keys."
结果

Question 2
Let’s explore the relationship between being fed breastmilk as a child and getting a seasonal influenza vaccine from a healthcare provider. Return a tuple of the average number of influenza vaccines for those children we know received breastmilk as a child and those who know did not.
This function should return a tuple in the form (use the correct numbers:
(2.5, 0.1)
Code
def average_influenza_doses():
# YOUR CODE HERE
# raise NotImplementedError()
import pandas as pd
import numpy as np
df = pd.read_csv("assets/NISPUF17.csv", index_col=0)
cbf_flu=df.loc[:,['CBF_01','P_NUMFLU']]
cbf_flu1=cbf_flu[cbf_flu['CBF_01'] ==1].dropna()
cbf_flu2=cbf_flu[cbf_flu['CBF_01'] ==2].dropna()
flu1=cbf_flu1['P_NUMFLU'].values.copy()
flu1[np.isnan(flu1)] = 0
f1=np.sum(flu1)/len(flu1)
flu2=cbf_flu2['P_NUMFLU'].values.copy()
flu2[np.isnan(flu2)] = 0
f2=np.sum(flu2)/len(flu2)
aid =(f1,f2)
return aid
assert len(average_influenza_doses())==2, "Return two values in a tuple, the first for yes and the second for no."
结果
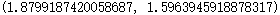
## Question 3 It would be interesting to see if there is any evidence of a link between vaccine effectiveness and sex of the child. Calculate the ratio of the number of children who contracted chickenpox but were vaccinated against it (at least one varicella dose) versus those who were vaccinated but did not contract chicken pox. Return results by sex.
This function should return a dictionary in the form of (use the correct numbers):
{"male":0.2,
"female":0.4}
Note: To aid in verification, the chickenpox_by_sex()['female'] value the autograder is looking for starts with the digits 0.0077.
Code
def chickenpox_by_sex():
# YOUR CODE HERE
# raise NotImplementedError()
import pandas as pd
import numpy as np
df = pd.read_csv("assets/NISPUF17.csv", index_col=0)
cpo_sex=df[df['P_NUMVRC'].gt(0) & df['HAD_CPOX'].lt(3)].loc[:,['HAD_CPOX','SEX']]
#Male 1 Female 2
cpo1_sex1=len(cpo_sex[(cpo_sex['HAD_CPOX']==1) & (cpo_sex['SEX']==1)])
cpo1_sex2=len(cpo_sex[(cpo_sex['HAD_CPOX']==1) & (cpo_sex['SEX']==2)])
cpo2_sex1=len(cpo_sex[(cpo_sex['HAD_CPOX']==2) & (cpo_sex['SEX']==1)])
cpo2_sex2=len(cpo_sex[(cpo_sex['HAD_CPOX']==2) & (cpo_sex['SEX']==2)])
cbs={"male":0,
"female":0}
cbs['male']=cpo1_sex1/cpo2_sex1
cbs['female']=cpo1_sex2/cpo2_sex2
return cbs
assert len(chickenpox_by_sex())==2, "Return a dictionary with two items, the first for males and the second for females."
结果
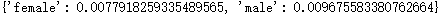
Question 4
A correlation is a statistical relationship between two variables. If we wanted to know if vaccines work, we might look at the correlation between the use of the vaccine and whether it results in prevention of the infection or disease [1]. In this question, you are to see if there is a correlation between having had the chicken pox and the number of chickenpox vaccine doses given (varicella).
Some notes on interpreting the answer. The had_chickenpox_column is either 1 (for yes) or 2 (for no), and the num_chickenpox_vaccine_column is the number of doses a child has been given of the varicella vaccine. A positive correlation (e.g., corr > 0) means that an increase in had_chickenpox_column (which means more no’s) would also increase the values of num_chickenpox_vaccine_column (which means more doses of vaccine). If there is a negative correlation (e.g., corr < 0), it indicates that having had chickenpox is related to an increase in the number of vaccine doses.
Also, pval is the probability that we observe a correlation between had_chickenpox_column and num_chickenpox_vaccine_column which is greater than or equal to a particular value occurred by chance. A small pval means that the observed correlation is highly unlikely to occur by chance. In this case, pval should be very small (will end in e-18 indicating a very small number).
[1] This isn’t really the full picture, since we are not looking at when the dose was given. It’s possible that children had chickenpox and then their parents went to get them the vaccine. Does this dataset have the data we would need to investigate the timing of the dose?
Code
def corr_chickenpox():
import scipy.stats as stats
import numpy as np
import pandas as pd
# this is just an example dataframe
# df=pd.DataFrame({"had_chickenpox_column":np.random.randint(1,3,size=(100)),
# "num_chickenpox_vaccine_column":np.random.randint(0,6,size=(100))})
df = pd.read_csv("assets/NISPUF17.csv", index_col=0)
df=df[df['HAD_CPOX'].lt(3)].loc[:,['HAD_CPOX','P_NUMVRC']].dropna()
df.columns=['had_chickenpox_column','num_chickenpox_vaccine_column']
# here is some stub code to actually run the correlation
corr, pval=stats.pearsonr(df["had_chickenpox_column"],df["num_chickenpox_vaccine_column"])
# just return the correlation
return corr
assert -1<=corr_chickenpox()<=1, "You must return a float number between -1.0 and 1.0."
结果
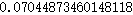
大家其他还有需要的就在评论留言哦 😃 欢迎讨论分享~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









