







文章目录
第1章 大数据概念
1.1大数据的概念
- 目前工业界普遍认为大数据具有5V+1C的特征:大量(volume)、多样(variety)、价值(value)、高速(velocity)、准确性(veracity)和复杂(complexity)
- 大数据的起始计量单位至少是P(1000个T)、E(100万个T)或Z(10亿个T)
- 数据的种类包括结构化、半结构化和非结构化数据
- 人类社会的数据产生方式大致经历了3 个阶段:传统数据库阶段、互动式互联网阶段、智慧社会阶段
1.2大数据的关键技术
- 根据大数据的处理过程,可将其分为数据采集、数据预处理、数据存储、数据分析与挖掘以及数据可视化等环节
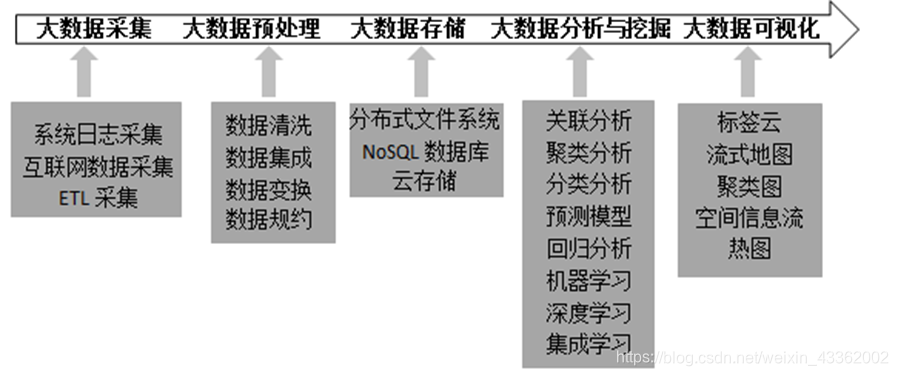
- 数据采集,又称数据获取,是
处于大数据生命周期的第一个环节 - 现实世界中,数据通常存在不完整、不一致的“脏”数据,无法直接进行数据挖掘,或挖掘结果差强人意,为了提高数据挖掘的质量产生的
数据预处理技术 分布式文件系统(DFS):是指文件系统管理的物理存储资源不一定直接连接在本地节点上,而通过计算机网络与节点相连。如HDFS等- NoSQL数据库采用<key,value>格式存储数据
- 大数据存储通常采用分布式文件系统、NoSQL数据库以及云存储等技术
1.3大数据采集与数据预处理技术
1.3.1大数据采集技术
- 大数据采集与预处理是大数据处理分析的第一阶段。
- 基于分布式数据库的数据采集方法相比传统数据采集方法的特点如下:
1》具有更高的数据访问速度
2》具有更强的可扩展性
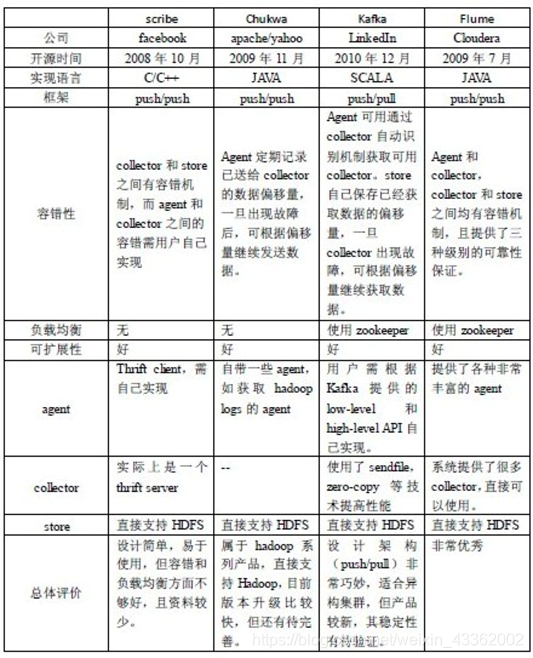
3》更高的并发访问量 - 目前,采用用分布式架构的大数据采集平台有:Apache Chukwa、Flume、Scrible以及Apache kafka等。
- Flume是一种分布式、可靠和可用的服务,可以有效地采集海量日志数据。
- kafka是一个分布式、支持分区的、多副本的、基于ZooKeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大数据以满足各种需求场景。
1.3.2数据预处理技术
- 采集到的原始数据通常存在的问题有:杂乱性、重复性、不完整性
- 常用的数据预处理技术有:数据清理、数据集成、数据变化、数据规约
- 数据清理主要是达到数据规格标准化、异常数据清理、数据错误纠正、重复数据的清除等目标
- 数据集成是将多个数据源中的数据结合起来并统一存储,建立数据仓库
- 数据变换是通过平滑聚集、数据概化、规范化等方式,将数据转换成适用于数据挖掘的形式
- 数据规约是指在对挖掘任务和数据本身内容理解的基础上,寻找依赖于发现目标数据的应用特征,以缩减数据规模,从而在尽可能保持数据原貌的前提下,最大限度的精简数据量
第二章 数据采集基础
2.1 传统数据采集技术
- 数据采集系统一般由硬件和软件两部分组成。从硬件方面来看,目前数据采集系统的架构包括两种形式,微型计算机数据采集系统和集散型数据采集系统。
- 计算机处理的信号是二进制的离散数字信号
- 采样技术

2.2大数据采集基础
- 大数据采集常用方法包括:系统日志采集、利用ETL工具采集以及网络爬虫等。
- 日志文件是由数据源系统自动生成的记录文件
- Web服务器主要包括以下三种日志文件格式:公用日志文件格式、扩展日志格式和IIS日志格式。
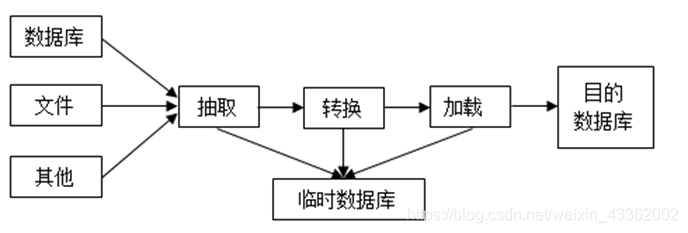
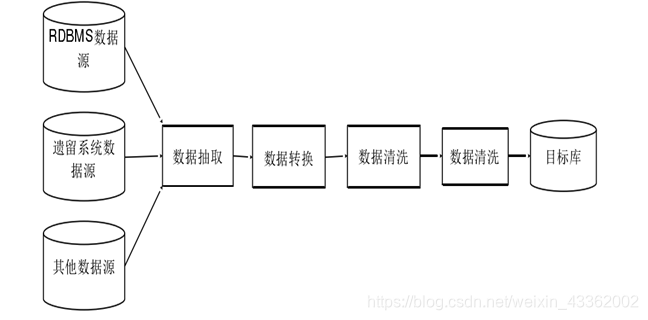
- ETL即数据抽取( Extract)、转换( Transform)、加载(Load)的过程
- 按照系统结构和实现技术,互联网爬虫可以分为通用网络爬虫、聚焦网络爬虫、增量式网络爬虫和分布式网络爬虫。
第三章 大数据采集架构



1.Chukwa数据采集

2.Flume数据采集
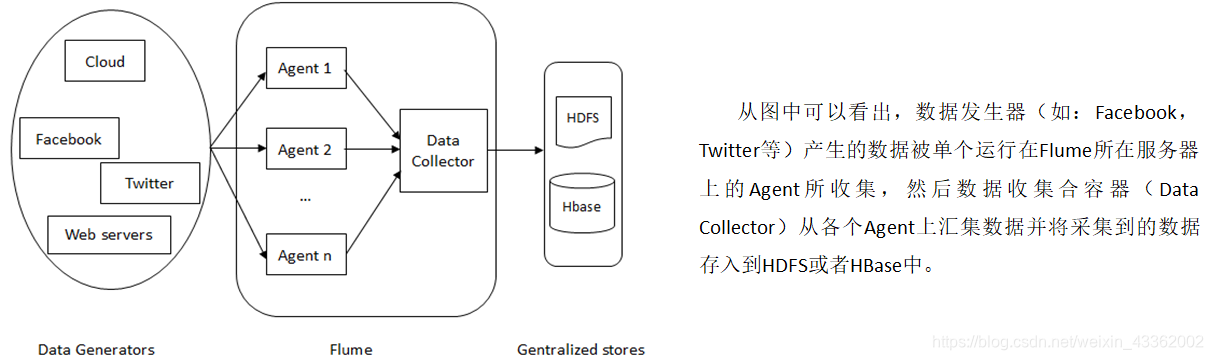

 Flume的核心是
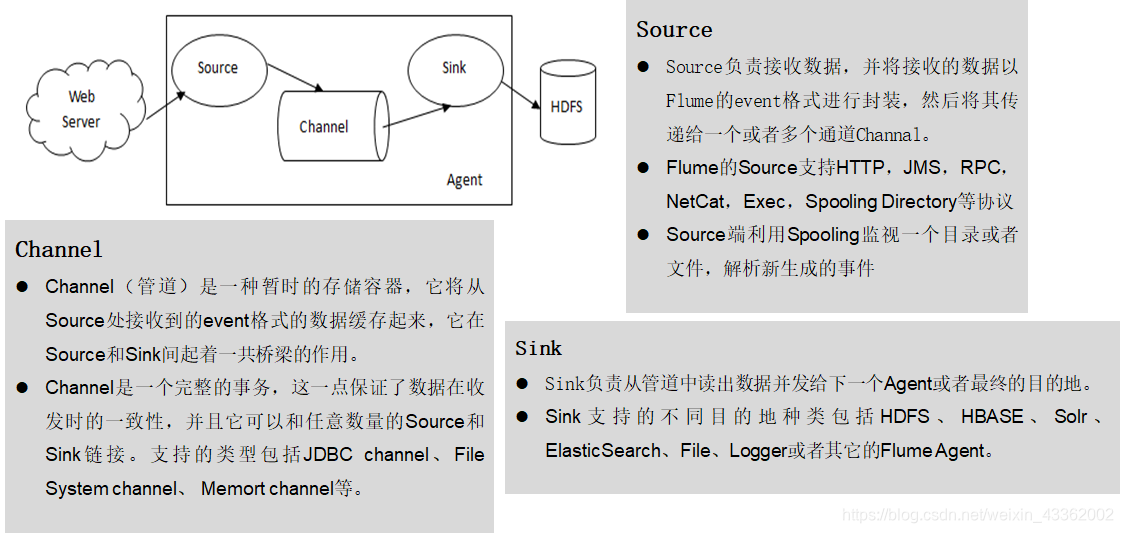
Flume的核心是Agent
Flume Agent由Source、Channel和Sink组成

Flume的运行机制
Flume的核心是Agent。Agent对外有两个进行交互的地方,一个是接受数据的输入Source,一个是数据的输出Sink。
Source接收到数据之后,将数据发送给Channel,Chanel作为一个数据缓冲区会临时存放这些数据,随后Sink会将Channel中的数据发送到指定的地方,例如HDFS等。
Flume可以支持多级Flume的Agent。例如Sink可以将数据写到下一个Agent的Source中,这样的话就可以连成串。
Flume还支持扇入(fan-in)、扇出(fan-out)。所谓扇入就是Source可以接受多个输入,所谓扇出就是Sink可以将数据输出多个目的地。
3.Scribe数据采集
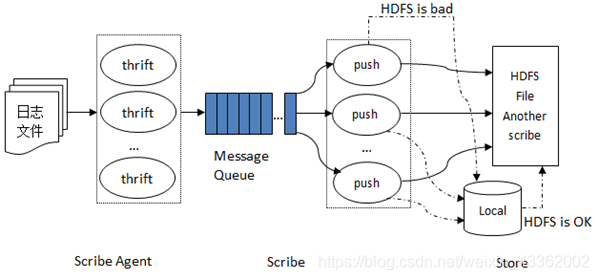
- Scribe由Scribe Agent、Scribe和存储系统三部分组成。
- Scribe能够从各种日志源上收集日志,存储到一个中央存储系统 (NFS或分布式文件系统等),以便于进行集中统计分析处理。
4.kafka数据采集
-
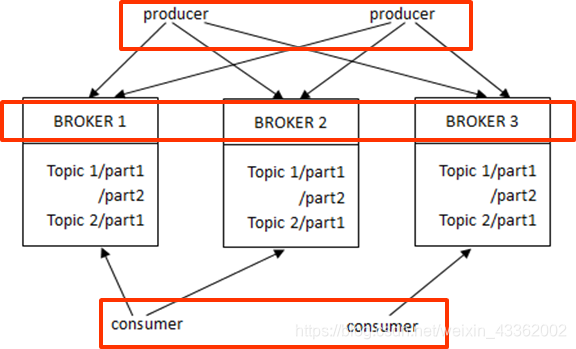
Apache Kafka是一种分布式发布-订阅消息系统。
-
Kafka被设计为能够高效地处理大量实时数据,具有快速、可扩展、分布式、分区和多副本等特点。
-
Kafka使用由Scala语言编写。
-
Kafka架构不仅具有高可扩展性、容错性和高并发性、还具有高吞吐量。
-
Kafka包括Consumers、Broker、Producers三层架构。

第四章 大数据迁移技术
1.数据迁移概念
- 数据迁移(HSM,Hierarchical Storage Management) 又称分级存储管理,是一种将离线存储与在线存储融合的技术
- 数据迁移的三个阶段:数据迁移前的准备、数据迁移的实施、数据迁移后的校验
2.数据迁移相关技术


3.数据迁移工具
4.3.1 Apache Sqoop
-
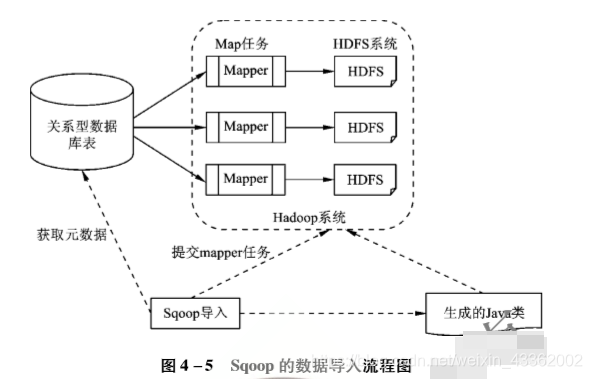
Apache Sqoop 是一种用于 Apache Hadoop 与关系型数据库之间结构化、非结构化数据转换的工具,它是Java语言编写的数据迁移开源工具
-
Sqoop可以通过Sqoop这个工具实现传统的关系型数据库(RDBMS )与Hadoop云环境平台的数据迁移
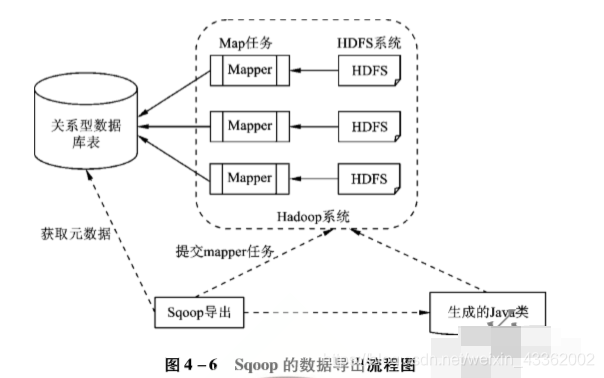
4.3.2 ETL
ETL处理流程


















 832
832

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











