






 文章讲述了作者遇到一个奇特的课程任务,需要将WOS下载的文献CSV文件转换回WOS格式以便进行聚类分析。作者借助ChatGPT编写Python脚本,完成了字段名转换、行列转置、数据格式调整等步骤,最终完成文件转换。
文章讲述了作者遇到一个奇特的课程任务,需要将WOS下载的文献CSV文件转换回WOS格式以便进行聚类分析。作者借助ChatGPT编写Python脚本,完成了字段名转换、行列转置、数据格式调整等步骤,最终完成文件转换。
遇到个很奇葩的课程老师,把wos上检索到的2000多篇文献集合下载后又处理成csv格式文件给我们做聚类分析,文件就像这样:

于是怒写了个python脚本将这个csv文件又转置回了wos文件……过程如下……
准备:观察wos格式
观察从wos上下载的正经wos格式的文件,发现规律如下:
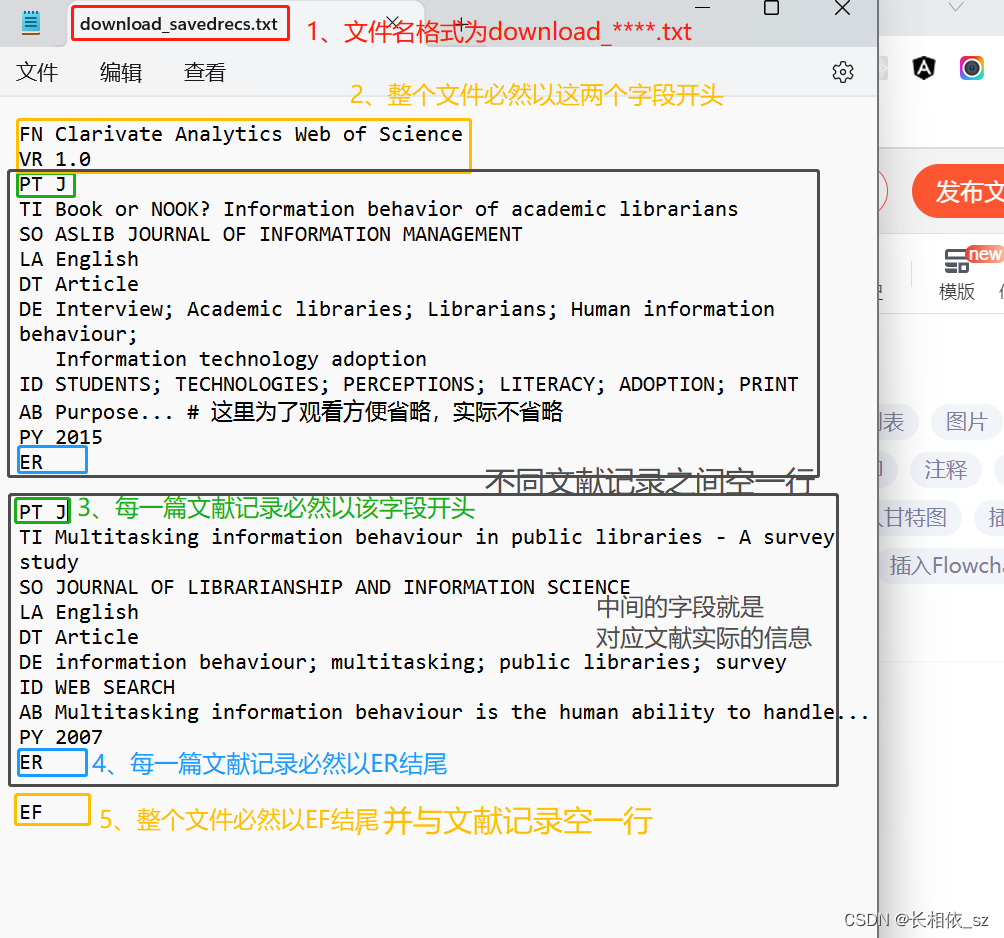
那么我要做的就是
1、将每个字段名转换成对应的wos专有字段名,比如文章名称=》TI,摘要=》AB等等;
2、对表格进行一次行列转置;
3、将每个记录按照次序,一行一行地排列在上个字段的下方,就像图中一行一行地排列那样,并添加PT J和ER这两个起始符和终止符;
4、文件首位的FN,VR,EF加上。
思路介绍到此,懂代码的话可以直接自己上手搞,像我一样的代码小白可以继续往下看:
下面一步步来看:
1、字段名转换
这个没什么难度,对着Web of Science核心收藏领域标签 把表头一个个换掉就行。结果就像这样:

2、表格行列转置
这个是excel自带的功能,全选表格数据=》打开一个新的表格=》右键=》选择性粘贴=》转置就行。不会的搜一下excel行列转换,网上一大堆教程。最终结果就像这样:

3、数据处理
新建一个文件夹(以后所有的操作都在这个文件夹下面进行),将2中处理好的csv文件以input.csv命名放在该文件夹下,新建一个process1.py文件,内容如下:
# process1.py
import csv
def transpose_columns(input_file, output_file):
# 读取输入文件
with open(input_file, 'r') as file:
reader = csv.reader(file)
rows = list(reader)
# 获取列数
num_columns = len(rows[0])
# 转换列
transposed_rows = []
for col_index in range(1, num_columns):
column = [row[col_index] for row in rows]
transposed_rows.append(['PT J']) # 添加起始符
transposed_rows.extend([[row[0], column[i]] for i, row in enumerate(rows)])
transposed_rows.append(['ER']) # 添加终止符
transposed_rows.append([]) # 添加空行
# 写入输出文件
with open(output_file, 'w', newline='') as file:
writer = csv.writer(file)
writer.writerows(transposed_rows)
# 示例用法
input_file = 'input.csv'
output_file = 'output1.csv'
transpose_columns(input_file, output_file)
输出文件output1.csv文件长这样:
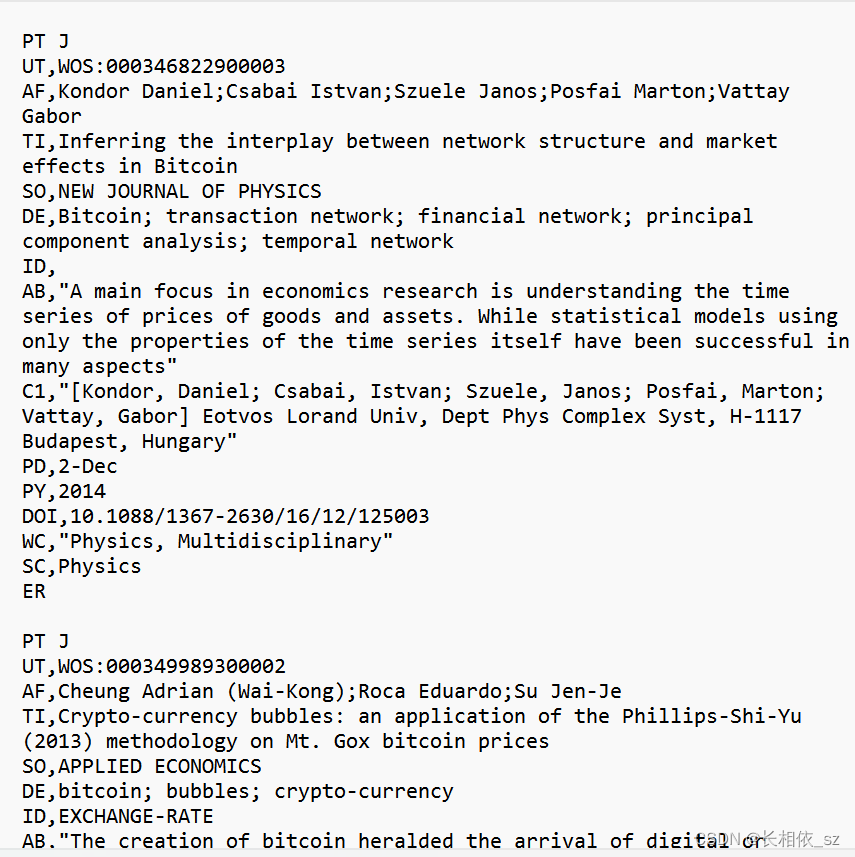
一个问题,在wos格式中,字段名和字段值之间是用空格( )隔开的,而不是结果中的逗号(,)同一文件夹下新建一个process2.py脚本,代码如下:
# process2.py
def replace_comma_with_space(input_file, output_file):
with open(input_file, 'r') as file:
lines = file.readlines()
modified_lines = []
for line in lines:
modified_line = line.replace(',', ' ', 1)
modified_lines.append(modified_line)
with open(output_file, 'w') as file:
file.writelines(modified_lines)
# 示例用法
input_file = 'output1.csv' # 也就是process1.py的输出文件
output_file = 'output2.txt'
replace_comma_with_space(input_file, output_file)
这样,就能把结果里每行的第一个逗号换成空格了。最终获得结果如下:

最后用记事本打开output2.txt,手动把文件的起始符和终止符加上,文件名改成download_1.txt(download_XXX.txt填任意数字字母可以),大功告成
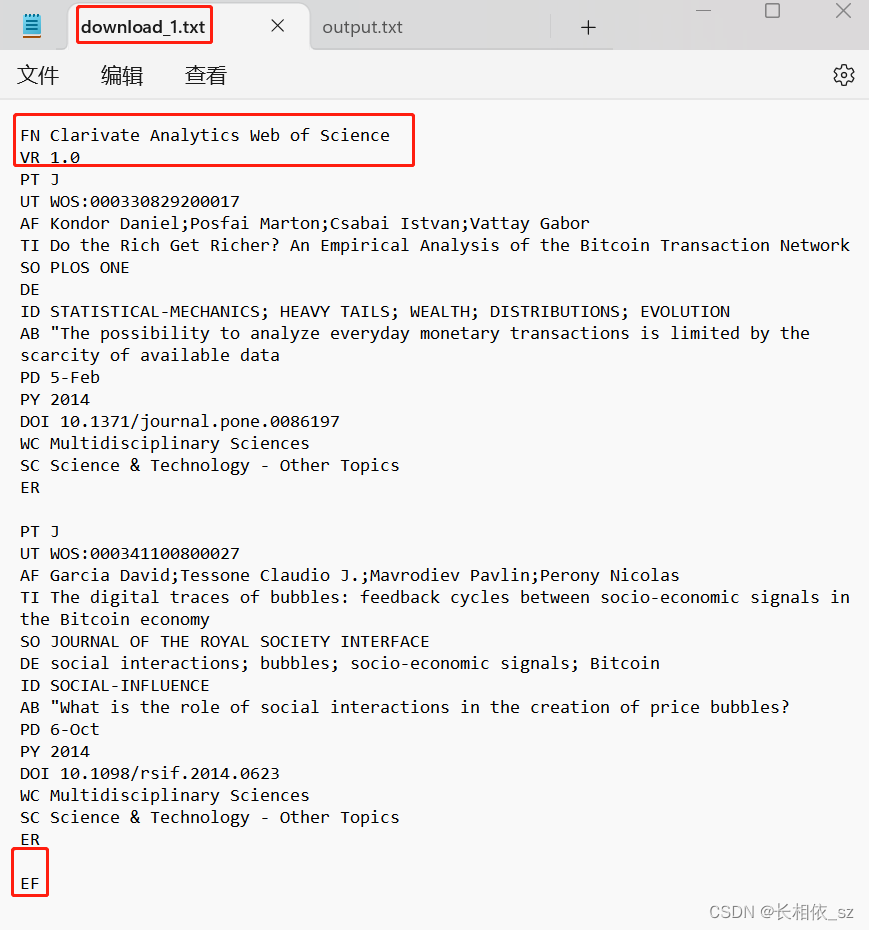
现在就可以拿着它去citespace生成学术垃圾了。导入citespace的方法这篇写得很详细:CiteSpace导入WOS数据详细步骤

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









