







站在Arnold Lu@南京大佬的肩膀,俯瞰内存管理之slab
文章目录
关键词
slab/slub/slob、slab描述符、kmalloc、slabs_partial/slabs_full/slabs_free、avail/limit/batchcount。
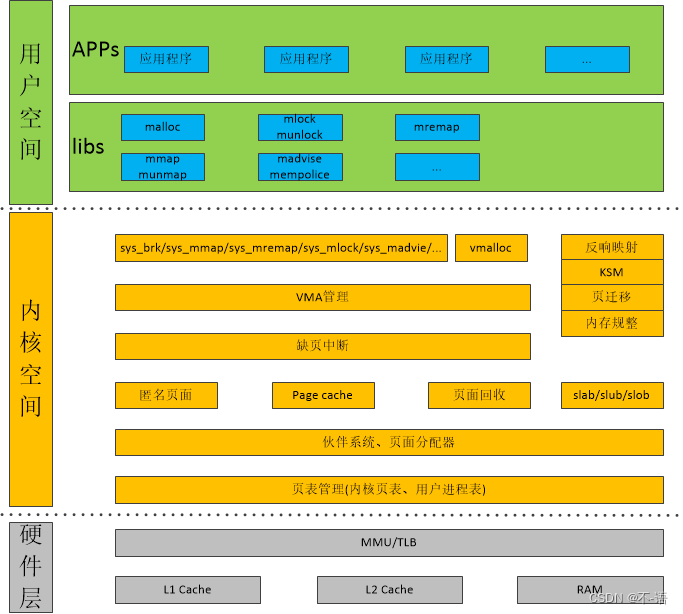
从【Linux内存管理框架】图可以看出:slab/slub/slob都是基于伙伴系统。
伙伴系统是以page为单位进行操作的。但是很多场景并不需要如此大的内存分配,slab就是用在这种场景的。
本章节主要内容:从slab相关数据结构讲起,对slab有一个静态的认识;然后介绍slab从创建描述符->分配缓存->释放缓存->销毁描述符介绍整个slab生命周;最后介绍基于slab分配器的kmalloc的运行原理。
slab层的由来
分配和释放数据结构是所有内核中最普遍的操作之一。为了便于数据的频繁分配和回收,常常会用到一个空间链表,它就相当于对象高速缓存以便快速存储频繁使用的对象类型。在内核中,空闲链表面临的主要问题之一是不能全局控制。当可用内存变得紧张的时候,内核无法通知每个空闲链表,让其收缩缓存的大小以便释放一些内存来。实际上,内核根本就不知道存在任何空闲链表。为了弥补这一缺陷,也为了是代码更加稳固,linux内核提供了slab层(也就是所谓的slab分类器),slab分配器扮演了通用数据结构缓存层的角色。slab分配器试图在如下几个原则中寻求一种平衡:
1.频繁使用的数据结构也会频繁分配和释放,因此应当缓存它们。
2.频繁分配和回收必然会导致内存碎片。为了避免这种情况,空闲链表的缓存会连续地存放。因为已释放的数据结构又会放回空闲链表,不会导致碎片。
3.回收的对象可以立即投入下一次分配,因此,对于频繁的分配和释放,空闲链表能够提高其性能。
4.如果让部分缓存专属于单个处理器,那么,分配和释放就可以在不加SMP锁的情况下进行。
5.对存放的对象进行着色,以防止多个对象映射到相同的高速缓存行。
6.如果分配器知道对象大小,页大小和总的高速缓存的大小,会做出更明智的选择。
slab分配器可以创建新的slab;
slab层只有当给定的高速缓存中没有部分满或空闲的slab时才会调用页分配函数。
当内存短缺时,才会调用释放高速缓存接口释放高速缓存。
slab分配器模式对基于内存区分配算法有较高的效率。
slab分配器模式基于以下前提:
(1)所存放的数据可以影响内存区的分配方式
(2)内核函数倾向于反复请求同一类型的内存区
(3)对内存区的请求可以根据它们发生的频率来分类④数据结构的起始地址不是物理地址2的幂⑤硬件高速缓存的高性能可以尽可能的限制对伙伴系统分配器调用。
包含告诉缓存的主内存区被划分为多个slab,每个slab有一个或多个连续的页框组成,这些页框中既包含已分配的对象,也包含空闲对象。
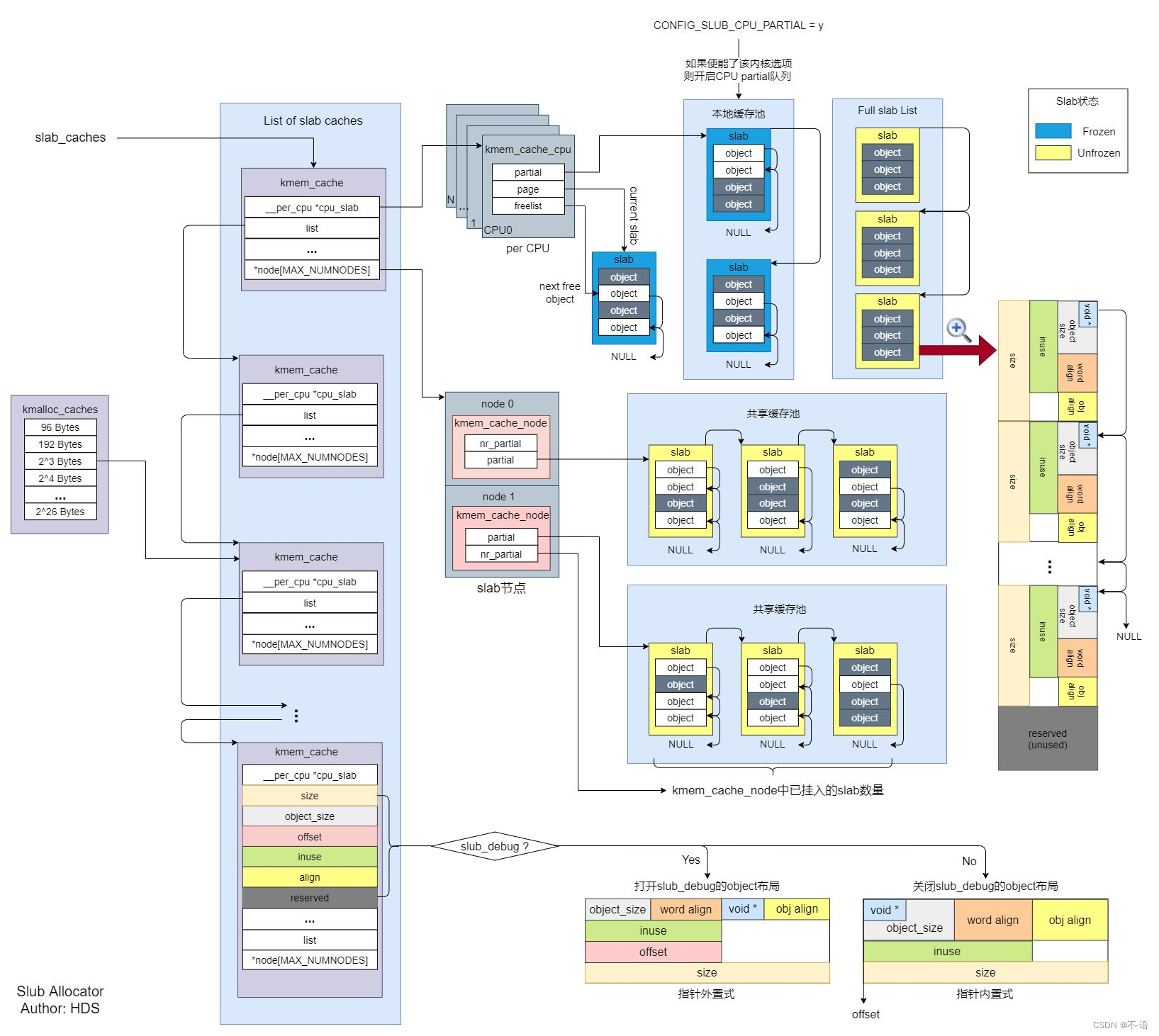
slab/slub/slob
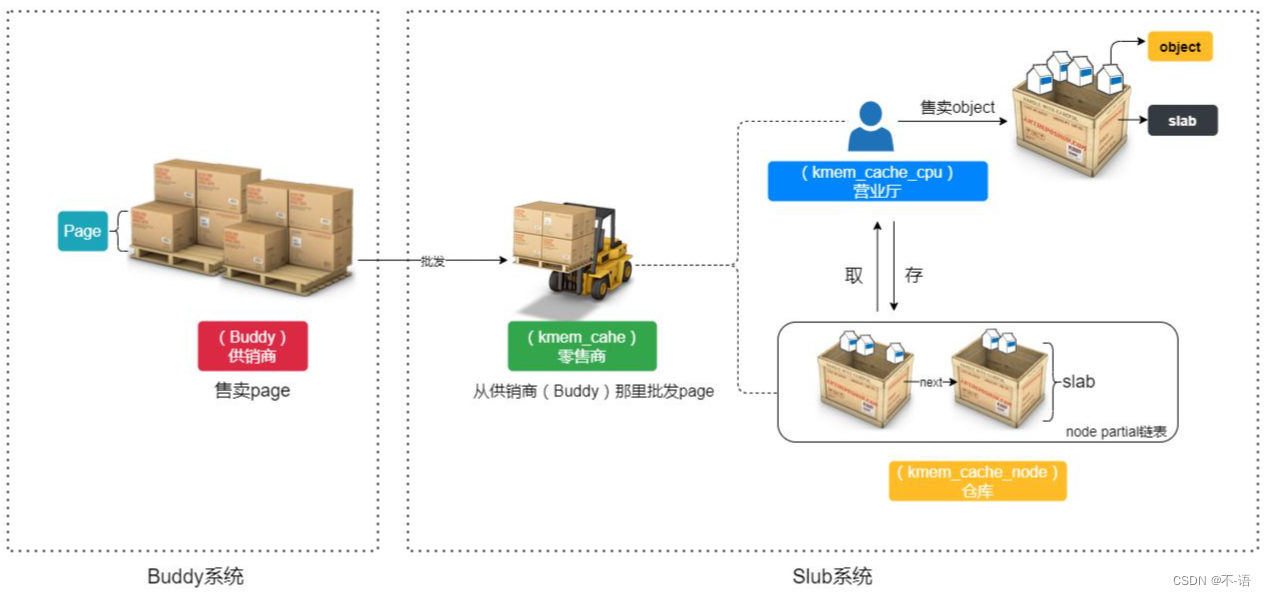
slab、slob和slub都是小内存分配器,slab是slob和slub实现的基础,而slob和slub是针对slab在不同场景下的优化版本。slob 适用于微小嵌入式系统,slub 使用大型大内存系统,这样性能比slab更好。
slab层的设计思想
1.slab层把不同的对象划分为所谓的高速缓存组,其中每个高速缓存都存放不同的类型对象。
2.每种对象类型对应一个高速缓存。kmalloc()接口建立在slab层上,使用了一组通用高速缓存。
3.这些高速缓存又被划分为slab, slab由一个或多个物理上连续的页组成,一般情况下,slab也就仅仅由一页组成。每个高速缓存可以由多个slab组成。每个slab都包含一些对象成员,这里的对象指的是被缓存的数据结构,每个slab处于三种状态之一:满,部分满,空。 当内核的某一部分需要一个新的对象时,先从部分满的slab中进行分配。如果没有部分满的slab,就从空的slab中进行分配。如果没有空的slab,就要创建一个slab了。这种策略能减少碎片。
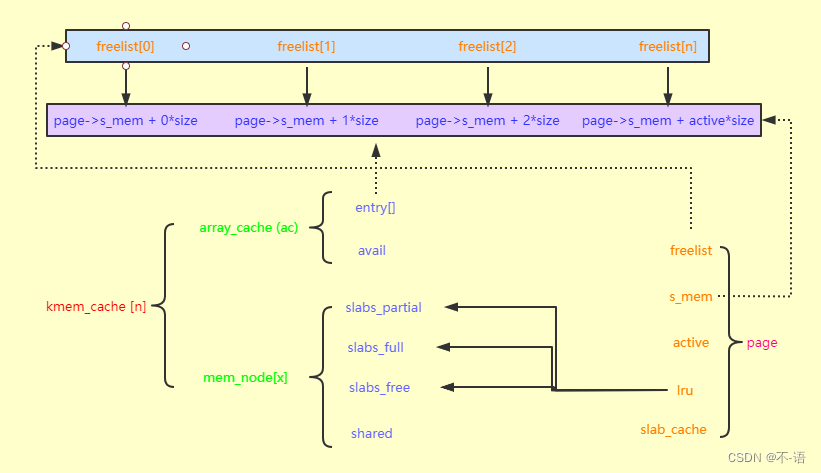
高速缓存、slab和对象之间的关系:
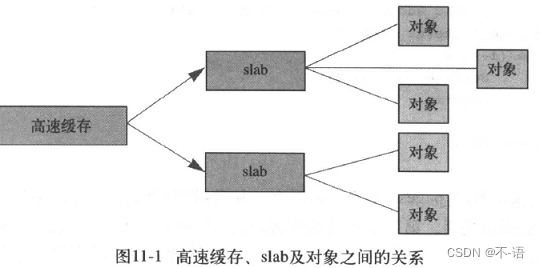
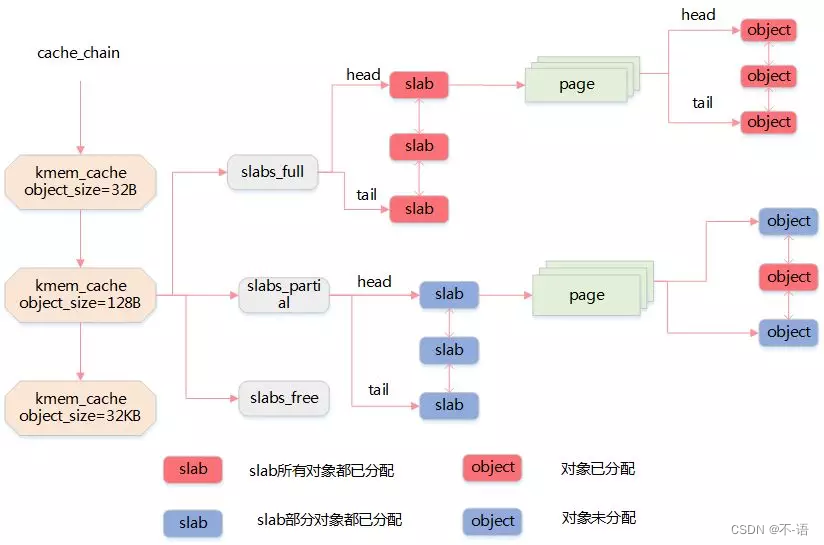
slab分配器最终还是由伙伴系统来分配出实际的物理页面,只不过slab分配器在这些连续的物理页面上实现了自己的算法,以此来对小内存块进行管理。
- 每个slab由多少个页面组成?
每个slab由一个或多个连续页面组成,最低一个,物理连续。 - slab需要的物理内存在什么时候分配?
首先kmem_cache_create是并不分配页面,等到kmem_cache_alloc时才有可能分配页面。首先从本地缓冲池和共享缓冲池、三大链表都没有空闲对象时,才会去分配2^gfporder个页面,然后挂入到slabs_free中。 - slab描述符中空闲对象过多,是否要回收?
有两种方式回收空闲对象:
(1)使用kmem_cache_free释放对象,当本地和共享对象缓冲池中空闲对象数目ac->avail大于ac->limit时,系统会主动释放batchcount个对象。当所有空闲数目大于系统空闲对象数目极限值,并且slab没有活跃对象时,可以销毁此slab,回收内存。
(2)系统注册了delayed_work,定时扫描slab描述符,回收一部分空闲对象,在cache_reap中实现。 - slab的cache colour着色区作用?
使不同slab上同一个相对位置slab对象的起始地址在高速缓存中相互错开,有利于改善高速缓存的行能。
另一个利用cache场景是Per-CPU类型本地对象缓冲池。两个优点:让一个对象尽可能地运行在同一个CPU上;访问Per-CPU类型本地对象缓冲池不需要获取额外自选锁。
slab相关数据结构
- slab对象的描述符struct kmem_cache,即高速缓存描述符
kernel-4.19/include/linux/slab_def.h
struct kmem_cache {
struct array_cache __percpu *cpu_cache; -----------------用于找到空闲内存的结点信息
/* 1) Cache tunables. Protected by slab_mutex */
unsigned int batchcount;-----------------------------------表示当前CPU本地缓冲池array_cache为空时,从共享缓冲池或者slabs_partial/slabs_free列表中获取对象的数目。
unsigned int limit;----------------------------------------表示当本地对象缓冲池空闲对象数目大于limit时就会主动释放batchcount个对象,便于内核回收和销毁slab。
unsigned int shared;
unsigned int size;-----------------------------------------align过后的对象长度
struct reciprocal_value reciprocal_buffer_size;
/* 2) touched by every alloc & free from the backend */
unsigned int flags; /* constant flags */------------分配掩码
unsigned int num; /* # of objs per slab */----------slab中有多少个对象
/* 3) cache_grow/shrink */
/* order of pgs per slab (2^n) */
unsigned int gfporder;------------------------------------此slab占用z^gfporder个页面
/* force GFP flags, e.g. GFP_DMA */
gfp_t allocflags;
size_t colour; /* cache colouring range */----一个slab有几个不同的cache line
unsigned int colour_off; /* colour offset */----------一个cache order的长度,和L1 Cache Line长度相同
struct kmem_cache *freelist_cache;
unsigned int freelist_size;
/* constructor func */
void (*ctor)(void *obj);
/* 4) cache creation/removal */
const char *name;----------------------------------------slab描述符的名称
struct list_head list;
int refcount;--------------------------------------------被引用的次数,供slab描述符销毁参考
int object_size;-----------------------------------------对象的实际大小
int align;-----------------------------------------------对齐的大小
/* 5) statistics */
#ifdef CONFIG_DEBUG_SLAB
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsigned long node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
/*
* If debugging is enabled, then the allocator can add additional
* fields and/or padding to every object. size contains the total
* object size including these internal fields, the following two
* variables contain the offset to the user object and its size.
*/
int obj_offset;
#endif /* CONFIG_DEBUG_SLAB */
#ifdef CONFIG_MEMCG_KMEM
struct memcg_cache_params memcg_params;
#endif
struct kmem_cache_node *node[MAX_NUMNODES];-------slab对应的节点的struct kmem_cache_node数据结构
}
- 本地CPU缓冲池struct array_cache
kernel-4.19/mm/slab.c
struct array_cache {
unsigned int avail;-------------对象缓冲池中可用的对象数目
unsigned int limit;-------------ac中最大可用缓存的片段数量
unsigned int batchcount;--------ac一次性申请或者释放的片段数量
unsigned int touched;----------从缓冲池移除一个对象时,touched置1;收缩缓存时,touched置0。
void *entry[];-----------------保存对象的实体
};
- 内存节点的slab列表
kernel-4.19/mm/slab.h
/*
* The slab lists for all objects.
*/
struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLAB
struct list_head slabs_partial; /* partial list first, better asm code */----slab链表中部分对象空闲
struct list_head slabs_full;----------------------------------------------------slab链表中没有对象空闲
struct list_head slabs_free;----------------------------------------------------slab链表中所有对象空闲
unsigned long free_objects;-----------------------------------------------------三个链表中空闲对象数目
unsigned int free_limit;--------------------------------------------------------slab中可容许的空闲对象数目最大阈值。
unsigned int colour_next; /* Per-node cache coloring */
struct array_cache *shared; /* shared per node */----------------------------多核CPU公用的共享对象缓冲池
struct alien_cache **alien; /* on other nodes */
unsigned long next_reap; /* updated without locking */
int free_touched; /* updated without locking */
#endif
#ifdef CONFIG_SLUB
unsigned long nr_partial;
struct list_head partial;
#ifdef CONFIG_SLUB_DEBUG
atomic_long_t nr_slabs;
atomic_long_t total_objects;
struct list_head full;
#endif
#endif
};
kmem_cache的关键结构体,page的lru会链接到mem_node的slabs_xxx链表上,而page的freelist用来记录该order的page的不同片段的起始地址,page->s_mem为page所代码的地址的起始地址。另外有些从kmem_cache的ac中分配,然后再是mem_node(ac只是mem_node的一个缓存而已)。
- slab flags
| Slab flags | 描述 |
|---|---|
| SLAB_HWCACHE_ALIGN | 这个标志命令slab层把一个slab内的所有对象按高速缓存行对齐。可以防止“错误的共享”(两个或多个对象尽管位于不同的内存地址,但映射到相同的高速缓存行)。可以提高性能,但是以增加内存踪迹为代价。 |
| SLAB_MUST_HWCACHE_ALIGN | 这个标志强制slab层缓存对齐对象。通常这个标志是不需要的,上一个标志就足够了。 |
| SLAB_POSION | 这个标志使slab层用已知的值(a5a5a5a5)填充slab。这就是所谓的“中毒”,有利于对未初始化内存的访问。 |
| SLAB_RED_ZONE | 这个标志导致slab层在已分配的内存周围插入“红色警戒区”以探测缓冲越界。 |
| SLAB_PANIC | 这个标志当分配失败时提醒slab层。这在要求分配只能成功的时候非常有用。 |
| SLAB_CACHE_DMA | 这个标志命令slab层使用可以执行DMA的内存给每个slab分配空间,只有在分配的对象用于DMA,而且必须驻留在ZONE_DMA区时才需要这个标志。 |
/*
* Flags to pass to kmem_cache_create().
* The ones marked DEBUG are only valid if CONFIG_SLAB_DEBUG is set.
*/
#define SLAB_CONSISTENCY_CHECKS ((slab_flags_t __force)0x00000100U) /* DEBUG: Perform (expensive) checks on alloc/free */
#define SLAB_RED_ZONE ((slab_flags_t __force)0x00000400U) /* DEBUG: Red zone objs in a cache */
#define SLAB_POISON ((slab_flags_t __force)0x00000800U) /* DEBUG: Poison objects */
#define SLAB_HWCACHE_ALIGN ((slab_flags_t __force)0x00002000U) /* Align objs on cache lines */
#define SLAB_CACHE_DMA ((slab_flags_t __force)0x00004000U) /* Use GFP_DMA memory */
#define SLAB_CACHE_DMA32 ((slab_flags_t __force)0x00008000U) /* Use GFP_DMA32 memory */
#define SLAB_STORE_USER ((slab_flags_t __force)0x00010000U) /* DEBUG: Store the last owner for bug hunting */
#define SLAB_PANIC ((slab_flags_t __force)0x00040000U) /* Panic if kmem_cache_create() fails */
创建slab描述符
kmem_cache_create的最主要功能就是填充struct kmem_cache
kernel-4.19/mm/slab_common.c
kmem_cache_create函数调用核心流程是
kmem_cache_create-----------------------------进行合法性检查,以及是否有现成slab描述符可用
create_cache----------------------将主要参数配置到slab描述符,然后将得到的描述符加入slab_caches全局链表中。
__kmem_cache_create-------------------是创建slab描述符的核心进行对齐操作,计算需要页面,对象数目,对slab着色等等操作。
set_objfreelist_slab_cache/set_off_slab_cache/set_on_slab_cache-------------------设置page片段的结构
calculate_slab_order--------------计算slab对象需要的大小,以及一个slab描述符需要多少page
setup_cpu_cache-------------------继续配置slab描述符
/*
kmem_cache_create输入参数说明
name:该参数指缓存名称,proc文件系统(在/proc/slabinfo中)使用它标识一个缓存。
size:该参数指定了为这个缓存创建的对象的大小,它是以字节为单位的。
align:该参数定义了每个对象的对齐方式。
flags:该参数指定了分配缓存时的选项,这些选项标志如slab flags表所示。
ctor:参数定义了一个可选的对象构造器,构造器是用户提供的回调函数。当从缓存中分配新对象时,可以通过构造器进行初始化。
实际上,Linux内核的高速缓存不使用构造函数。你可以将ctor参数赋值为NULL
*/
struct kmem_cache *
kmem_cache_create(const char *name, unsigned int size, unsigned int align,
slab_flags_t flags, void (*ctor)(void *))----------------该函数不能在中断上下文中调用,可能会睡眠。
{
return kmem_cache_create_usercopy(name, size, align, flags, 0, 0,
ctor);
}
struct kmem_cache *
kmem_cache_create_usercopy(const char *name,
unsigned int size, unsigned int align,
slab_flags_t flags,
unsigned int useroffset, unsigned int usersize,
void (*ctor)(void *))
{
struct kmem_cache *s = NULL;
const char *cache_name;
int err;
if (!usersize)
/*
*检查传递的大小和一些flag是否可以和系统中已经创建的slab匹配上,
*如果匹配上则就不用重新申请了,直接使用别名就行,相当于链接过去,下面if判断就直接跳到末尾执行,否则返回NULL,继续执行
*/
s = __kmem_cache_alias(name, size, align, flags, ctor);
if (s)
goto out_unlock;
// 定义这个缓存的名字,用于在/proc/slabinfo中显示
cache_name = kstrdup_const(name, GFP_KERNEL);
if (!cache_name) {
err = -ENOMEM;
goto out_unlock;
}
/* 如果没有找到可以复用的slab缓存,则创建一个新的slab缓存*/
s = create_cache(cache_name, size,
calculate_alignment(flags, align, size),
flags, useroffset, usersize, ctor, NULL, NULL);
if (IS_ERR(s)) {
err = PTR_ERR(s);
kfree_const(cache_name);
}
out_unlock:
return s;
}
static struct kmem_cache *create_cache(const char *name,
unsigned int object_size, unsigned int align,
slab_flags_t flags, unsigned int useroffset,
unsigned int usersize, void (*ctor)(void *),
struct kmem_cache *root_cache)
{
struct kmem_cache *s;
int err;
// useroffset和usersize初始值就是0,跳过if判断
if (WARN_ON(useroffset + usersize > object_size))
useroffset = usersize = 0;
err = -ENOMEM;
s = kmem_cache_zalloc(kmem_cache, GFP_KERNEL); -----------------创建一个slab缓存
if (!s)
goto out;
s->name = name;
s->size = s->object_size = object_size;
s->align = align;
s->ctor = ctor;
#ifdef CONFIG_HARDENED_USERCOPY
s->useroffset = useroffset;
s->usersize = usersize;
#endif
err = __kmem_cache_create(s, flags); ----------- slab缓存创建成功,则返回0
if (err)
goto out_free_cache;
s->refcount = 1;
list_add(&s->list, &slab_caches);--------------将创建的slab缓存添加到系统的slab_caches链表中。
out:
if (err)
return ERR_PTR(err);
return s;
out_free_cache:
kmem_cache_free(kmem_cache, s);
goto out;
}
kernel-4.19/mm/slab.c
int __kmem_cache_create(struct kmem_cache *cachep, slab_flags_t flags)
{
size_t ralign = BYTES_PER_WORD;
gfp_t gfp;
int err;
unsigned int size = cachep->size;
/*
* Check that size is in terms of words. This is needed to avoid
* unaligned accesses for some archs when redzoning is used, and makes
* sure any on-slab bufctl's are also correctly aligned.
*/
size = ALIGN(size, BYTES_PER_WORD);
if (flags & SLAB_RED_ZONE) {
ralign = REDZONE_ALIGN;
/* If redzoning, ensure that the second redzone is suitably
* aligned, by adjusting the object size accordingly. */
size = ALIGN(size, REDZONE_ALIGN);
}
/* 3) caller mandated alignment */
if (ralign < cachep->align) {
ralign = cachep->align;
}
/* disable debug if necessary */
if (ralign > __alignof__(unsigned long long))
flags &= ~(SLAB_RED_ZONE | SLAB_STORE_USER);
/*
* 4) Store it.
*/
cachep->align = ralign;------------------------------对齐大小设置到struct kmem_cache
cachep->colour_off = cache_line_size();----------------------------------------L1 Cache line大小,由CONFIG_ARM_L1_CACHE_SHIFT配置,此处为64B。
/* Offset must be a multiple of the alignment. */
if (cachep->colour_off < cachep->align)
cachep->colour_off = cachep->align;
if (slab_is_available())----------------------------slab_state>=UP时,可以使用GFP_KERNEL分配,否则只能使用GFP_NOWAIT
gfp = GFP_KERNEL;
else
gfp = GFP_NOWAIT;
kasan_cache_create(cachep, &size, &flags);-------------------- 预留Kasan的空间,即增加size大小
size = ALIGN(size, cachep->align);------------------按照cachep->align对size进行对齐
/*
* We should restrict the number of objects in a slab to implement
* byte sized index. Refer comment on SLAB_OBJ_MIN_SIZE definition.
*/
if (FREELIST_BYTE_INDEX && size < SLAB_OBJ_MIN_SIZE)
size = ALIGN(SLAB_OBJ_MIN_SIZE, cachep->align);
if (set_objfreelist_slab_cache(cachep, size, flags)) {---------------- 设置管理page片段的管理结构位置
flags |= CFLGS_OBJFREELIST_SLAB;
goto done;
}
if (set_off_slab_cache(cachep, size, flags)) {------------------- 设置 page片段管理结构不在slab上
flags |= CFLGS_OFF_SLAB;
goto done;
}
if (set_on_slab_cache(cachep, size, flags))--------------- 设置Page片段管理结构在slab上
goto done;
return -E2BIG;
done:
cachep->freelist_size = cachep->num * sizeof(freelist_idx_t);
cachep->flags = flags;
cachep->allocflags = __GFP_COMP;
if (flags & SLAB_CACHE_DMA)
cachep->allocflags |= GFP_DMA;
if (flags & SLAB_CACHE_DMA32)
cachep->allocflags |= GFP_DMA32;
if (flags & SLAB_RECLAIM_ACCOUNT)
cachep->allocflags |= __GFP_RECLAIMABLE;
cachep->size = size;
cachep->reciprocal_buffer_size = reciprocal_value(size);
err = setup_cpu_cache(cachep, gfp);------------根据slab_state状态进行不同处理,计算limit/batchcount,分配本地对象缓冲池,共享对象缓冲池
if (err) {
__kmem_cache_release(cachep);
return err;
}
return 0;
}
注:
1. kasan是Linux内核引入的一种专门检测slab内存越界问题的,通过给内存打上特定的pad来实现,这个操作比较消耗内存。
2. 通过cache_line_size 可以得到L1 cache的size, 可见最终是通过读取SYS_CTR_EL0 这个寄存器来得到L1 cache size的
static inline int cache_line_size(void)
{
u32 cwg = cache_type_cwg();
return cwg ? 4 << cwg : L1_CACHE_BYTES;
}
static inline u32 cache_type_cwg(void)
{
return (read_cpuid_cachetype() >> CTR_CWG_SHIFT) & CTR_CWG_MASK;
}
static inline u32 __attribute_const__ read_cpuid_cachetype(void)
{
return read_cpuid(CTR_EL0);
}
#define read_cpuid(reg) read_sysreg_s(SYS_ ## reg)
kernel-4.19/mm/slab.c
static bool set_objfreelist_slab_cache(struct kmem_cache *cachep,
size_t size, slab_flags_t flags)
{
size_t left;
cachep->num = 0;
/*
* If slab auto-initialization on free is enabled, store the freelist
* off-slab, so that its contents don't end up in one of the allocated
* objects.
*/
if (unlikely(slab_want_init_on_free(cachep)))
return false;
if (cachep->ctor || flags & SLAB_TYPESAFE_BY_RCU)
return false;
left = calculate_slab_order(cachep, size,
flags | CFLGS_OBJFREELIST_SLAB);
if (!cachep->num)
return false;
if (cachep->num * sizeof(freelist_idx_t) > cachep->object_size)
return false;
cachep->colour = left / cachep->colour_off;
return true;
}
slab_state用于表示slab分配器的状态:
```C
/*
* State of the slab allocator.
*
* This is used to describe the states of the allocator during bootup.
* Allocators use this to gradually bootstrap themselves. Most allocators
* have the problem that the structures used for managing slab caches are
* allocated from slab caches themselves.
*/
enum slab_state {
DOWN, /* No slab functionality yet */
PARTIAL, /* SLUB: kmem_cache_node available */
PARTIAL_NODE, /* SLAB: kmalloc size for node struct available */
UP, /* Slab caches usable but not all extras yet */
FULL /* Everything is working */------------------------完全初始化
};
calculate_slab_order计算slab的大小,返回值是page order。同时也计算此slab中可以容纳多少个同样大小的对象。
static size_t calculate_slab_order(struct kmem_cache *cachep,
size_t size, slab_flags_t flags)
{
size_t left_over = 0;
int gfporder;
for (gfporder = 0; gfporder <= KMALLOC_MAX_ORDER; gfporder++) {-------------从gfporder=0开始,直到KMALLOC_MAX_ORDER=10,即从4KB到4MB大小。
unsigned int num;
size_t remainder;
num = cache_estimate(gfporder, size, flags, &remainder);
if (!num)----------------------不等于0则表示gfporder已经满足条件,最低分配到一个size大小的对象。等于0则继续下一次for循环。
continue;
/* Can't handle number of objects more than SLAB_OBJ_MAX_NUM */
if (num > SLAB_OBJ_MAX_NUM)------------slab中对象最大数目,SLAB_OBJ_MAX_NUM为255,所以所有的slab对象不超过255
break;
if (flags & CFLGS_OFF_SLAB) {
struct kmem_cache *freelist_cache;
size_t freelist_size;
size_t freelist_cache_size;
freelist_size = num * sizeof(freelist_idx_t);
if (freelist_size > KMALLOC_MAX_CACHE_SIZE) {
freelist_cache_size = PAGE_SIZE << get_order(freelist_size);
} else {
freelist_cache = kmalloc_slab(freelist_size, 0u);
if (!freelist_cache)
continue;
freelist_cache_size = freelist_cache->size;
/*
* Needed to avoid possible looping condition
* in cache_grow_begin()
*/
if (OFF_SLAB(freelist_cache))
continue;
}
/* check if off slab has enough benefit */
if (freelist_cache_size > cachep->size / 2)
continue;
}
/* Found something acceptable - save it away */
cachep->num = num;
cachep->gfporder = gfporder;
left_over = remainder;----------------确定对象个数和需要的页面数
/*
* A VFS-reclaimable slab tends to have most allocations
* as GFP_NOFS and we really don't want to have to be allocating
* higher-order pages when we are unable to shrink dcache.
*/
if (flags & SLAB_RECLAIM_ACCOUNT)
break;
/*
* Large number of objects is good, but very large slabs are
* currently bad for the gfp()s.
*/
if (gfporder >= slab_max_order)
break;
/*
* Acceptable internal fragmentation?
*/
if (left_over * 8 <= (PAGE_SIZE << gfporder))-------------------满足着色条件,退出for循环
break;
}
return left_over;
}
cache_estimate() 根据当前大小2^gfporder来计算可以容纳多少个对象,以及剩下多少空间用于着色。
/*内核提供了计算一个Slab缓存的大小的函数,Slab缓存的内存布局分成以下两种:
*1. Slab缓存管理区在Slab内,即同对象存放在一起。
*2. Slab缓存管理区存放在单独的一片区域,即同对象分别存放。
*通过宏CFLGS_OFF_SLAB和CFLGS_OBJFREELIST_SLAB来区分。
*参数介绍:
- gfporder: Slab缓存大小为2^gfporder个页面
- buffer_size: 每个对象的大小
- align:对齐
- flags:CFLGS_OFF_SLAB表示Slab管理区在缓存外,否则表示在缓存内。
- left_over:输出参数,在一个Slab中被浪费的大小。
- num: 输出参数,一个Slab中,对象的数量。
*/
/*
* Calculate the number of objects and left-over bytes for a given buffer size.
*/
static unsigned int cache_estimate(unsigned long gfporder, size_t buffer_size,
slab_flags_t flags, size_t *left_over)
{
unsigned int num;
size_t slab_size = PAGE_SIZE << gfporder;
/*
* The slab management structure can be either off the slab or
* on it. For the latter case, the memory allocated for a
* slab is used for:
*
* - @buffer_size bytes for each object
* - One freelist_idx_t for each object
*
* We don't need to consider alignment of freelist because
* freelist will be at the end of slab page. The objects will be
* at the correct alignment.
*
* If the slab management structure is off the slab, then the
* alignment will already be calculated into the size. Because
* the slabs are all pages aligned, the objects will be at the
* correct alignment when allocated.
*/
if (flags & (CFLGS_OBJFREELIST_SLAB | CFLGS_OFF_SLAB)) {
num = slab_size / buffer_size;
*left_over = slab_size % buffer_size;
} else {
num = slab_size / (buffer_size + sizeof(freelist_idx_t));
*left_over = slab_size %
(buffer_size + sizeof(freelist_idx_t));
}
return num;
}
分配slab对象
1)slab分配机制: slab分配器是基于对象进行管理的,所谓的对象就是内核中的数据结构(例如:task_struct,file_struct 等)。相同类型的对象归为一类,每当要申请这样一个对象时,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免内部碎片。slab分配器并不丢弃已经分配的对象,而是释放并把它们保存在内存中。slab分配对象时,会使用最近释放的对象的内存块,因此其驻留在cpu高速缓存中的概率会大大提高。
2)kmem_cache_alloc() 是slab分配缓存对象的核心函数,在slab分配缓存过程中,是全程关闭本地中断的。kmem_cache_alloc()函数从给定的高速缓存cachep中, 返回一个指向对象的指针。如果高速缓存的所有slab中都没有空闲的对象,那么slab层必须通过kmem_getpages() 获取新的页,flags的值传递给 __get_free_pages()。
kmem_cache_alloc–>__kmem_cache_alloc_lru–>slab_alloc–>slab_alloc_node–>__do_cache_alloc是关中断的。
void *kmem_cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
return __kmem_cache_alloc_lru(cachep, NULL, flags);
}
EXPORT_SYMBOL(kmem_cache_alloc);
static __always_inline void *__kmem_cache_alloc_lru(struct kmem_cache *cachep, struct list_lru *lru,
gfp_t flags)
{
void *ret = slab_alloc(cachep, lru, flags, cachep->object_size, _RET_IP_);
trace_kmem_cache_alloc(_RET_IP_, ret, cachep, flags, NUMA_NO_NODE);
return ret;
}
static __always_inline void *
slab_alloc(struct kmem_cache *cachep, struct list_lru *lru, gfp_t flags,
size_t orig_size, unsigned long caller)
{
return slab_alloc_node(cachep, lru, flags, NUMA_NO_NODE, orig_size,
caller);
}
static __always_inline void *
slab_alloc_node(struct kmem_cache *cachep, struct list_lru *lru, gfp_t flags,
int nodeid, size_t orig_size, unsigned long caller)
{
unsigned long save_flags;
void *objp;
struct obj_cgroup *objcg = NULL;
bool init = false;
flags &= gfp_allowed_mask;
cachep = slab_pre_alloc_hook(cachep, lru, &objcg, 1, flags);
if (unlikely(!cachep))
return NULL;
objp = kfence_alloc(cachep, orig_size, flags);
if (unlikely(objp))
goto out;
local_irq_save(save_flags);
objp = __do_cache_alloc(cachep, flags, nodeid);
local_irq_restore(save_flags);
objp = cache_alloc_debugcheck_after(cachep, flags, objp, caller);
prefetchw(objp);
init = slab_want_init_on_alloc(flags, cachep);
out:
slab_post_alloc_hook(cachep, objcg, flags, 1, &objp, init,
cachep->object_size);
return objp;
}
由于没有定义NUMA,所以__do_cache_alloc就仅通过____cache_alloc来分配缓存。
static __always_inline void *
__do_cache_alloc(struct kmem_cache *cachep, gfp_t flags, int nodeid __maybe_unused)
{
return ____cache_alloc(cachep, flags);
}
static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags)
{
void *objp;
struct array_cache *ac;
check_irq_off();
ac = cpu_cache_get(cachep);----------------------------------获取本地对象缓冲池
if (likely(ac->avail)) {-------------------------------------本地对象缓冲池有空闲对象
ac->touched = 1;
objp = ac->entry[--ac->avail];
STATS_INC_ALLOCHIT(cachep);
goto out;
}
STATS_INC_ALLOCMISS(cachep);
objp = cache_alloc_refill(cachep, flags);------------是slab分配缓存的核心
/*
* the 'ac' may be updated by cache_alloc_refill(),
* and kmemleak_erase() requires its correct value.
*/
ac = cpu_cache_get(cachep);
out:
/*
* To avoid a false negative, if an object that is in one of the
* per-CPU caches is leaked, we need to make sure kmemleak doesn't
* treat the array pointers as a reference to the object.
*/
if (objp)
kmemleak_erase(&ac->entry[ac->avail]);
return objp;
}
cache_alloc_refill() 是slab分配缓存的核心。 如果高速缓存中的所有slab中都没有空闲的对象,那么slab层必须通过cache_alloc_refill()重新填充本地高速缓存并获得一个空闲对象
static void *cache_alloc_refill(struct kmem_cache *cachep, gfp_t flags)
{
int batchcount;
struct kmem_cache_node *n;
struct array_cache *ac, *shared;
int node;
void *list = NULL;
struct slab *slab;
check_irq_off();
node = numa_mem_id();
ac = cpu_cache_get(cachep); --------获取本地对象缓冲池ac
batchcount = ac->batchcount;
if (!ac->touched && batchcount > BATCHREFILL_LIMIT) {
/*
* If there was little recent activity on this cache, then
* perform only a partial refill. Otherwise we could generate
* refill bouncing.
*/
batchcount = BATCHREFILL_LIMIT;
}
n = get_node(cachep, node); --------找到对应的slab节点
BUG_ON(ac->avail > 0 || !n);
shared = READ_ONCE(n->shared);
if (!n->free_objects && (!shared || !shared->avail))
goto direct_grow;
raw_spin_lock(&n->list_lock);
shared = READ_ONCE(n->shared);
/* See if we can refill from the shared array */
if (shared && transfer_objects(ac, shared, batchcount)) {----判断共享对象缓冲池(n->shared)是否有空闲对象。tansfer_objects尝试迁移batchcount个空闲对象到ac中。
shared->touched = 1;
goto alloc_done;
}
while (batchcount > 0) {
/* Get slab alloc is to come from. */
slab = get_first_slab(n, false);
if (!slab)---------------------------------如果从slabs_partial/slabs_free中分配不到对象,则跳到must_grow分配对象。
goto must_grow;
check_spinlock_acquired(cachep);
batchcount = alloc_block(cachep, ac, slab, batchcount);
fixup_slab_list(cachep, n, slab, &list);
}
must_grow:
n->free_objects -= ac->avail;
alloc_done:
raw_spin_unlock(&n->list_lock);
fixup_objfreelist_debug(cachep, &list);
direct_grow:----------------------------没有足够的内存片段,则向伙伴子系统进货
if (unlikely(!ac->avail)) {
/* Check if we can use obj in pfmemalloc slab */
if (sk_memalloc_socks()) {
void *obj = cache_alloc_pfmemalloc(cachep, n, flags);
if (obj)
return obj;
}
slab = cache_grow_begin(cachep, gfp_exact_node(flags), node);
/*
* cache_grow_begin() can reenable interrupts,
* then ac could change.
*/
ac = cpu_cache_get(cachep);
if (!ac->avail && slab)
alloc_block(cachep, ac, slab, batchcount);
cache_grow_end(cachep, slab);
if (!ac->avail)
return NULL;
}
ac->touched = 1;
return ac->entry[--ac->avail];
}
释放slab对象
kmem_cache_free()函数释放一个曾经由slab分配器分配给某个内核函数的对象,在释放过程中也是全程关中断的。其参数为cachep(高速缓存描述符的地址)和objp(将被释放对象的地址)。
kernel-4.19/mm/slab.c
void kmem_cache_free(struct kmem_cache *cachep, void *objp)
{
cachep = cache_from_obj(cachep, objp);---------------------通过对象找到slab描述符
if (!cachep)
return;
trace_kmem_cache_free(_RET_IP_, objp, cachep);
__do_kmem_cache_free(cachep, objp, _RET_IP_);
}
EXPORT_SYMBOL(kmem_cache_free);
cache_from_obj()通过要释放对象的虚拟地址,找到所在页面,继而找到对应的struct kmem_cache结构体。
然后将转换得到的slab描述符和入参描述符对比,即可判断两者是否有效。
static inline struct kmem_cache *cache_from_obj(struct kmem_cache *s, void *x)
{
struct kmem_cache *cachep;
if (!IS_ENABLED(CONFIG_SLAB_FREELIST_HARDENED) &&
!kmem_cache_debug_flags(s, SLAB_CONSISTENCY_CHECKS))
return s;
cachep = virt_to_cache(x);
if (WARN(cachep && cachep != s,
"%s: Wrong slab cache. %s but object is from %s\n",
__func__, s->name, cachep->name))
print_tracking(cachep, x);
return cachep;
}
kernel-4.19/mm/slab.c
static inline struct kmem_cache *virt_to_cache(const void *obj)
{
struct page *page = virt_to_head_page(obj);
return page->slab_cache;
}
销毁缓存
调用kmem_cache_destroy()函数之前必须确保以下两个条件:
- 高速缓存中的所有slab必须为空。
- 在调用kmem_cache_destroy期间不再访问这个高速缓存。
linux-4.19/mm/slab_common.c
void kmem_cache_destroy(struct kmem_cache *s)
{
int err;
if (unlikely(!s)) --------------- 如果s为NULL,直接退出
return;
get_online_cpus();-------------- get_online_cpus是对cpu_online_map的加锁,其与末尾的put_online_cpus()是配对使用的;get_online_mems类似,不过是对mem操作
get_online_mems();
mutex_lock(&slab_mutex);
s->refcount--;
if (s->refcount)
goto out_unlock;
#ifdef CONFIG_MEMCG_KMEM
memcg_set_kmem_cache_dying(s);
mutex_unlock(&slab_mutex);
put_online_mems();
put_online_cpus();
flush_memcg_workqueue(s);
get_online_cpus();
get_online_mems();
mutex_lock(&slab_mutex);
/*
* Another thread referenced it again
*/
if (READ_ONCE(s->refcount)) {
spin_lock_irq(&memcg_kmem_wq_lock);
s->memcg_params.dying = false;
spin_unlock_irq(&memcg_kmem_wq_lock);
goto out_unlock;
}
#endif
err = shutdown_memcg_caches(s);
if (!err)
err = shutdown_cache(s);
if (err) {
pr_err("kmem_cache_destroy %s: Slab cache still has objects\n",
s->name);
dump_stack();
}
out_unlock:
mutex_unlock(&slab_mutex);
put_online_mems();
put_online_cpus();
}
EXPORT_SYMBOL(kmem_cache_destroy);
在内核栈上的静态分配
用户空间能够奢侈地负担起非常大的栈,而且空间还可以动态增长,但是内核却不能这么奢侈,因为内核栈大小固定。当给每个进程分配一个固定大小的小栈,不但可以减少内存的消耗,而且内核也无需负担太重的栈管理任务。
**每个进程的内核栈大小既取决于体系结构,也与编译时的选项有关。**通常,每个进程都有两页的内核栈,32位和64位体系结构的页面大小分别是4KB和8KB,所以内核栈大小分别是8KB和16KB。当然,可以在编译时设置单页内核栈,当这个选项被激活时,每个进程的内核栈就只有一页那么大了,这样做,可以让每个进程减少内存消耗,给分配连续的页带来了好处。历史上,中断处理程序耶要放在内核栈中,同时增加了更加严格的约束条件。
为了纠正这问题,实现了一个附加选项:中断栈。中断栈为每个进程提供一个用于中断处理程序的栈。
总的来说,内核栈可以是1页,也可以是2页。当1页栈的选项被激活时,中断处理程序获得了自己的栈。在任何情况下,无限制的递归和alloc是不允许的。所以,在任意一个函数中,你都必须尽量节省栈资源,在具体的函数中让所有局部变量所占空间之和不要超过几百字节。
高端内存的映射
根据定义,在高端内存中的页不能永久地映射到内核地址空间上。因此,通过alloc_pages()函数以 __GFP_HIGHMEM 标志获得的页不可能有逻辑地址。
在x86体系结构上,高于896MB的所有物理内存的范围大都是高端内存,它并不会永久地或自动地映射到内核地址空间,尽管x86处理器能够寻址物理RAM的范围达到4GB(启用PAE可以寻址到64GB),一旦这些页被分配,就必须映射到内核的逻辑地址空间上。在x86上,高端内存中的页被映射到3GB~4GB。
内核有三种方式管理高端内存。第一种是非连续映射,在vmalloc中请求页面的时候,如果请求的是高端内存,则映射到VMALLOC_START与VMALLOC_END之间。第二种方式是永久内核映射。最后一种方式叫临时内核映射。
永久映射
<linux/highmem.h>
要映射一个给定的page结构到内核地址空间,可以使用:
void *kmap(struct page *page);
这个函数在高端内存或低端内存上都能用。如果page结构对应的是低端内存中的一页,函数只会单纯地返回该页的虚拟地址。如果页位于高端内存,则会建立一个永久映射,在返回地址。这个函数可以睡眠,只能用于进程上下文中。因为允许永久映射的数量是有限的,当不再需要高端内存时,应该解除映射:
void kunmap(struct page *page);
临时映射
内核在FIXADDR_START到FIXADDR_TOP之间保留了一些线性空间用于特殊需求。这个空间称为“固定映射空间”。在这个空间中,有一部分用于高端内存的临时映射。这块空间具有如下特点:
- 每个CPU占用一块空间
- 在每个CPU占用的那块空间中,又分为多个小空间,每个小空间大小是1个page,每个小空间用于一个目的,这些目的定义在kmap_types.h中的km_type中。
当要进行一次临时映射的时候,需要指定映射的目的。 根据映射目的,可以找到对应的小空间,然后把这个空间的地址作为映射地址。这意味着一次临时映射会导致以前的映射被覆盖。
当必须创建一个映射,而当前上下文不能睡眠时,内核提供了临时映射(原子映射):
void *kmap_atomic(struct page *page, enum_km_type type);
参数type定义在<asm/kmap_types.h>中,这个函数不会阻塞,禁止内核抢占,可以用在中断上下文中和其他不能重新调度的地方。
取消映射:
void kunmap_atomic(void *kvaddr, enum_km_type type);
这个函数也不会阻塞。在很多体系结构中,除非激活了内核抢占,否则kmap_atomic()根本就无事可做,因为只有在下一个临时映射到来前上一个临时映射才有效。因此,内核完全可以“忘掉”kmap_atomic()映射,kunmap_atomic()也无须做什么实际的事情。下一个原子映射将自动覆盖前一个映射。
每个CPU的分配
支持SMP的现代操作系统使用了每个CPU上的数据,对于给定的处理器,其数据时唯一的。一般来说,每个CPU的数据存放在一个数组中,数组中的每一项对应着系统上一个存在的处理器。这就是2.4内核的处理方式。该情况下,不再需要锁,而是关注内核抢占来防止并发访问。例如:
unsigned long my_percpu[NR_CPUS];
int cpu;
cpu=get_cpu(); // 获得当前处理器,并禁止内核抢占
my_percpu[cpu]++;
put_cpu(); // 激活内核抢占
----------CPU 部分只做简单记录学习–START---------
新的每个CPU接口
编译时的每个CPU数据
2.6内核为了方便创建和操作每个CPU数据,从而引进了新的操作接口,称着percpu。头文件<linux/percpu.h>声明了所有的操作接口例程。可以在文件mm/slab.c和<asm/percpu.h>中找到他们的定义。
DEFINE_PER_CPU(type, name);
这个语句为系统的每个处理器都创建了一个类型为type,名字为name的变量实例,如果你需要在别处声明变量,可以使用:
DECLARE_PER_CPU(type, name);
调用get_cpu_var返回当前处理器上指定的变量,同时禁止内核抢占;调用put_cpu_var将相应地重新激活抢占。
get_cpu_var(name)++;/*增加当前处理器变量的值*/
put_cpu_var(name);/*释放CPU*/
可以调用下面这个接口处理指定CPU的数据:
per_cpu(name, cpu);
函数per_cpu函数既不会禁止内核抢占,也不会提供任何形式的锁保护。
注意,编译时每个CPU数据的例子并不能在模块使用,因为连接程序实际上将它们创建在一个唯一的可执行段中(.data.percpu)。
运行时的每个CPU接口
该例程为系统上的每个处理器创建所需内存的实例,其原型在<linux/percpu.h>中。
void *alloc_percpu(type);
void *__alloc_percpu(size_t size, size_t align);
void *free_percpu(const void *);
宏alloc_percpu 给系统中的每个处理器分配一个指定类型对象的实例。它其实是__alloc_percpu的一个封装例程。这个原始宏接收的参数有两个:一个是要分配的实际字节数;一个是分配时要按多少字节对齐。而封装后的__alloc_percpu按照单字节对齐–按照给定类型的自然边界对齐。例如:
struct rabid_cheetah = alloc_percpu(struct rabid_cheetab);
等价于:
struct rabid_cheetab = = __alloc_percpu(sizeof(struct rabid_cheetab),
__alignof__( struct rabid_cheetab));
__alignof__结构式gcc的一个功能,它会返回指定类型或lvalue所需的对齐字节数。
无论是alloc_percpu还是__alloc_percpu都返回一个指针,用来间接引用动态创建的每个CPU数据,内核提供了两个宏利用指针来获取每个CPU数据:
get_cpu_ptr(ptr);
put_cpu_ptr(ptr);
函数get_cpu_ptr返回一个指向当前处理器数据的特殊实例,同时禁止内核抢占;而put_cpu_ptr会重新激活内核抢占。最后,函数per_cpu_ptr返回指定处理器的唯一数据:
per_cpu_ptr(ptr);
该函数不会禁止内核抢占。
使用每个CPU数据的原因
第一: 减少了数据锁定。编程时就规定了只有这个CPU能访问这个数据,所以不需要任何锁。
第二: 使用每个CPU数据可以大大减少缓存失效。失效发生在处理器试图使它们的缓存保持同步时。
----------CPU 部分只做简单记录学习–END---------
分配函数的选择(重点)
- 如果需要连续的物理页,就可以使用某个低级页分配器或kmalloc。但是需要注意GFP_KERNEL和GFP_ATOMIC标志的使用。
- 如果需要从高端内存进行分配,就使用alloc_pages。它返回一个指向struct page结构的指针,而不是指向某个逻辑地址的指针。为了获得真正的指针,需要调用kmap函数,把高端内存映射到内核的逻辑地址空间。
- 如果不需要物理页上连续的页,而仅仅需要虚拟地址连续的页,就使用vmalloc(有一定性能损失)。
- 如果需要创建和销毁很多较大的数据结构,那么可以使用slab高速缓存。
参考资料
Linux内核设计与实现
图解Slub
slab浅析
slub分配器
Arnold Lu@南京-slub分配器
深入理解Linux内存管理–slab

















 804
804











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











