







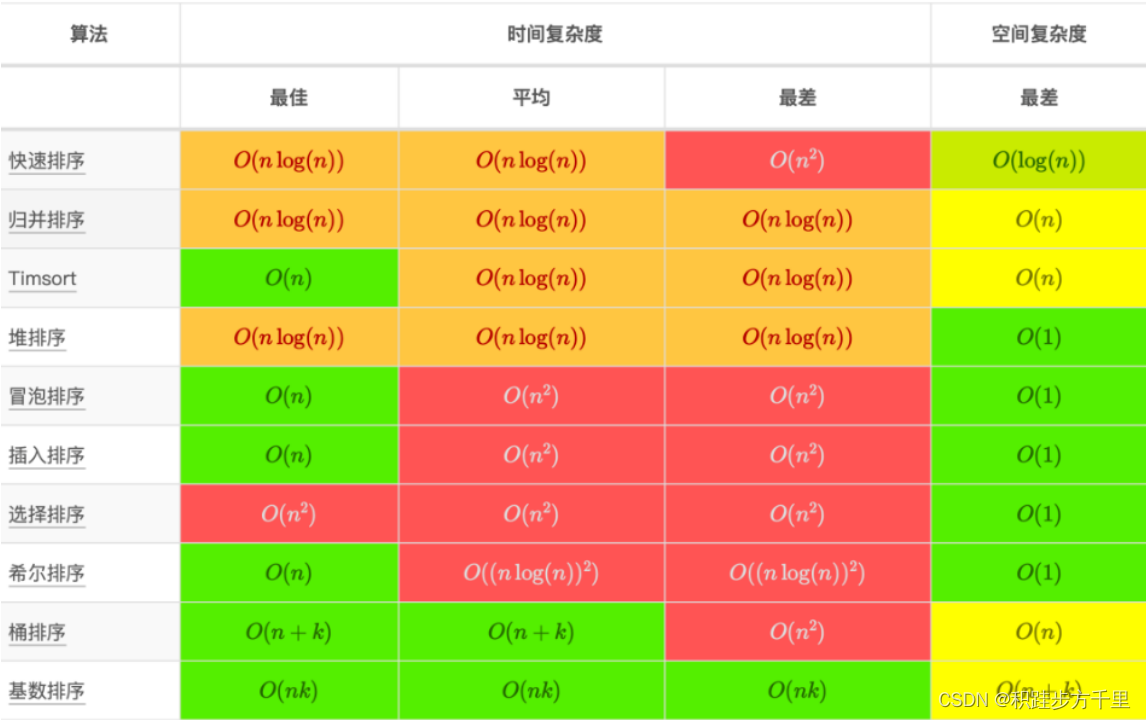
十大排序
排序算法基础知识
1、时间复杂度O(n^2)的排序算法:冒泡、选择、插入、希尔
2、时间复杂度O(nlogn)的排序算法:快速、归并、堆
3、时间复杂度O(n)的排序算法:计数、桶等
排序算法稳定性分析:如果值相同的元素在排序后仍保持着排序前的顺序,则称为稳定排序;否则为不稳定排序。
一、Bubble Sort(冒泡排序)
冒泡排序 升序 时间复杂度O(n^2)
// 冒泡排序 升序 时间复杂度O(n^2)
void bubbleSort(vector<int>& vec)
{
for (int i = 0; i < vec.size()-1; ++i)
{
for (int j = 0; j < vec.size() - i - 1; ++j)
{
if (vec[j] > vec[j + 1])
{
int temp = vec[j];
vec[j] = vec[j + 1];
vec[j + 1] = temp;
}
}
}
}
基于冒泡排序的升级排序法,鸡尾酒排序法。
二、选择排序
选择排序是给每个位置选择当前元素最小的,比如第一个位置选择最小的,在剩余元素里面给第二个元素选择第二小的,以此类推,直到第n-1个元素,第n个元素就不用进行处理了(已经是剩余元素中最小的了)
时间复杂度O(n^2) 空间复杂度O(1) 非稳定排序 原地排序
/*
选择排序是给每个位置选择当前元素最小的,比如第一个位置选择最小的,在剩余元素里面给第二个元素选择
第二小的,以此类推,直到第n-1个元素,第n个元素就不用进行处理了(已经是剩余元素中最小的了)
时间复杂度O(n^2) 空间复杂度O(1) 非稳定排序 原地排序
*/
void selectionSort(vector<int>& nums)
{
// 记录未排序序列中最小(大)元素下标
int minIndex = 0;
for(int i = 0; i < nums.size(); ++i)
{
// 从剩余未排序序列中寻找最小(大)元素,然后放到已排序序列的末尾,以此类推,直到所有元素均排序完毕
minIndex = i;
for(int j = i + 1; j < nums.size(); ++j)
{
if(nums[j] < nums[minIndex])
{
minIndex = j;
}
}
// 将当前序列中的最小元素交换到已排序序列的末尾
swap(nums[i], nums[minIndex]);
}
}
三、插入排序
介绍:插入排序是在一个已经有序的小序列的基础上,一次插入一个元素,刚开始这个有序的小序列只有1个元素,就是第一个元素。比较是从有序序列的末尾开始,也就是想要插入的元素和 已经有序的最大者 开始比起,如果比 已经有序的最大者 大 则直接插入在其后面,否则一直往前找直到找到它该插入的位置。
如果碰见一个 和插入元素相等 的,那么插入元素把想插入的元素放在相等元素的后面(插入排序是稳定的)。
时间复杂度O(n^2) 空间复杂度O(1)
void insertSort(vector<int>& nums)
{
// 从第一个元素开始遍历,认为第0个元素是已经有序的一个小序列
for(int i = 1; i < nums.size(); ++i)
{
// 当待排序元素 小于 有序序列末尾的元素
if(nums[i] < nums[i - 1])
{
// 将有序序列向后移动,将当前元素插入到合适的位置
// 记录有序序列末尾的元素下标
int j = i - 1;
// 存储待排序元素
int temp = nums[i];
// 移动有序序列(有序序列后移,腾出待插入元素的位置)
while(j >= 0 && nums[j] > temp)
{
// 元素后移
nums[j + 1] = nums[j];
--j;
}
// 将待插入的元素插入到合适的位置
nums[j + 1] = temp;
}
}
}
四、Quick Sort(快排)
分治法
// 双边循环法
int partionV1(vector<int>& vec, int startIndex, int endIndex)
{
// 取第一个元素作为基准元素,也可以取随机位置元素
int pivot = vec[startIndex];
int left = startIndex;
int right = endIndex;
while (left != right)
{
// 如果right指针指向的元素大于或等于pivot,指针左移;否则,指针停止移动,切换到left指针
while (left<right && vec[right] >= pivot)
--right;
// 如果left指针指向的元素小于或等于pivot,指针右移;否则,指针停止移动
while (left < right && vec[left] <= pivot)
++left;
// 交换对应不符合条件的元素
if (left < right)
{
int temp = vec[left];
vec[left] = vec[right];
vec[right] = temp;
}
}
// left==right 跳出while循环
// 将指针重合点元素与基准元素交换,该轮排序结束
vec[startIndex] = vec[left];
vec[left] = pivot;
return left;// 返回最终基准元素的下标
}
// 单边循环法
int partionV2(vector<int>& vec, int startIndex, int endIndex)
{
确定基准元素 选择区间内的随机下标(避免初始序列有序的情况出现,导致时间复杂度降为O(n^2))
//int index = beginIndex + rand() % (endIndex - beginIndex + 1);
将随机选择的元素与区间内首个元素进行交换
//swap(nums[beginIndex], nums[index]);
// 取第一个元素作为基准元素
int pivot = vec[startIndex];
int mark = startIndex;
for (int i = startIndex + 1; i <= endIndex; ++i)
{
// 基准元素左边<=pivot 右边>pivot
if (vec[i] < pivot)
{
++mark;
int temp = vec[i];
vec[i] = vec[mark];
vec[mark] = temp;
}
}
// 将基准元素与mark位置元素进行交换
vec[startIndex] = vec[mark];
vec[mark] = pivot;
return mark;
}
// 快速排序 分治法 左闭右闭区间
void quickSort(vector<int>& vec, int startIndex, int endIndex)
{
// 递归终止条件
if (startIndex >= endIndex)
return;
// 获取基准元素位置 这里可以选择使用双边循环法和单边循环法
// int pivotIndex = partionV1(vec, startIndex, endIndex);
int pivotIndex = partionV2(vec, startIndex, endIndex);
// 确定单层递归的逻辑
quickSort(vec, startIndex, pivotIndex - 1);
quickSort(vec, pivotIndex+1, endIndex);
}
五、计数排序
/*
计数排序是一种线性时间的整数排序算法。如果数组长度为n,整数范围(数组中最大整数与最小整数之间的差值)
为k,对于k远小于n的场景,那么计数排序的时间复杂度优于归并、快排等。
基本思想:先统计数组中每个元素在数组中出现的次数,然后按照从小到大的顺序
将每个元素按照它出现的次数填到数组中
*/
// 计数排序
void numSort(vector<int>& vec)
{
// 记录数组中最大、最小整数
int minValue = INT_MAX;
int maxValue = INT_MIN;
for(int num : vec)
{
minValue = min(minValue, num);
maxValue = max(maxValue, num);
}
// 创建大小为k+1的数组,因为后续要访问到k,所以需要+1
// 该数组统计元素在原数组中出现的次数
int k = maxValue - minValue;
vector<int> counts(k + 1, 0);
for(int num : vec)
{
++counts[num - minValue];
}
// 按从小到大的顺序将每个整数按其出现的次数填到数组中
int i = 0;// 索引
// 这里为排序的顺序,也可以按照某个数组的相对顺序进行排序
for(int num = minValue; num <= maxValue; num++)
{
while(counts[num - minValue] > 0)
{
vec[i++] = num;
--counts[num - minValue];
}
}
// 例如:arr1 = {3,2,1} 按照arr1的相对顺序对原数组进行排序
// for(int num : arr1)
// {
// while(counts[num] > 0)
// {
// vec[i++] = num;
// --counts[num];
// }
// }
}
如果数组长度为n,数组整数范围为k,那么计数排序的时间复杂度为O(n + k),需要一个大小为k的辅助数组,故空间复杂度为O(k)
六、桶排序
桶排序思想:
每一个桶(bucket)代表一个区间范围,里面可以承载一个或多个元素
桶是从大到小排列的,并且每一个桶都会有一个数据范围。当把元素放入对应的桶里面的时候,需要对桶内的序列进行排序(保持桶内序列有序)。最后按照桶的序号将桶内的元素打印出来即可得到有序序列。
- 桶的数量过多或者过少都会影响桶排序的效率
- 元素分布极不均匀,在极端的情况下,第一个桶中有n-1个元素,在最后一个桶中有1个元素,时间复杂度将退化为O(nlogn),且浪费了很多空间
算法实现:
- 遍历序列,找到序列中的最大值和最小值(确定数据范围[minVal, maxVal])
- 创建桶,并确定每一个桶的区间范围
- 区间跨度 = (最大值 - 最小值)/(桶的数量 - 1)
- 遍历原始数列,把元素对号入座放入各个桶中
- 对每个桶内部的元素分别进行排序
- 遍历所有的桶,输出所有元素
// 链表节点
struct ListNode{
int val;
ListNode* next;
ListNode() : val(0), next(nullptr) {}
ListNode(int val) : val(val), next(nullptr) {}
ListNode(int val, ListNode* next) : val(val), next(next) {}
};
// 向有序链表中插入节点
ListNode* insert(ListNode* head, int val)
{
// 创建一个虚拟头节点
ListNode* dummyHead = new ListNode(-1);
// 虚拟头节点指向链表头节点
dummyHead->next = head;
// 创建待插入的节点
ListNode* newNode = new ListNode(val);
// 创建双指针
ListNode* pre = dummyHead;
ListNode* cur = dummyHead->next;
// 移动双指针到合适的位置
while(cur != nullptr && val >= cur->val)
{
pre = cur;
cur = cur->next;
}
// 插入节点
newNode->next = cur;
pre->next = newNode;
head = dummyHead->next;
// delete dummyHead;
return head;
}
class comp
{
public:
bool operator()(ListNode* a, ListNode* b)
{
return a->val > b->val;
}
};
// 合并k个有序链表
ListNode* mergeKLists(vector<ListNode*>& lists)
{
// 使用优先队列对合并链表算法时间复杂度进行优化
// 注意:优先队列右边为队首,即return a->val > b->val; 这种方式构造出来的堆为小顶堆,小的元素优先出队
priority_queue<ListNode*, vector<ListNode*>, comp> pri;
// 向队列中添加元素
for(ListNode* l : lists)
{
if(l != nullptr)
pri.push(l);
}
// 创建虚拟头节点
ListNode* dummyHead = new ListNode(-1);
// 创建指针,指向新链表
ListNode* cur = dummyHead;
// 队列非空,不断对队首链表进行挂接、出队操作
while(!pri.empty())
{
// 记录优先队列队首链表元素
ListNode* node = pri.top();
pri.pop();
// 新链表挂接队首链表的头节点
cur->next = node;
// 更新新链表上的指针
cur = cur->next;
// 如果队首链表除头节点外还不为空,需要将剩余的链表重新添加到优先队列中
if(node->next != nullptr)
pri.push(node->next);
}
return dummyHead->next;
}
// 桶排序
// bucketCount为桶排序中桶的数量
void bucketSort(vector<int>& vec, int bucketCount)
{
if(vec.size() == 0) return;
// 每个桶的区间比例:
// 区间跨度 = (最大值 - 最小值)/(桶的数量 - 1)
int minVal = INT_MAX;
int maxVal = INT_MIN;
for(int num : vec)
{
minVal = min(minVal, num);
maxVal = max(maxVal, num);
}
// double size = (maxVal - minVal + bucketCount) / bucketCount;
double d = maxVal - minVal;
// 初始化桶
// 创建bucketCount个桶,每个桶都是一个链表
vector<ListNode*> buckets(bucketCount, nullptr);
// 遍历数组,将每个元素放入对应的桶中
for(int i = 0; i < vec.size(); ++i)
{
// 第一种求当前元素对应桶的索引
// double size = (maxVal - minVal + bucketCount) / bucketCount;
// int index = (int) ((vec[i] - minVal) / size);
// 第二种求当前元素对应桶的索引(书上)
// double d = maxVal - minVal;
int index = (int) ((vec[i] - minVal) * (bucketCount - 1) / d);
// 找到对应的桶,向对应的桶内插入元素
// ListNode* head = buckets[index];
buckets[index] = insert(buckets[index], vec[i]);
}
// 合并k个链表
ListNode* head = mergeKLists(buckets);
// 打印输出排序后的元素或者直接改变原数组vec中的值
for(int i = 0; i < vec.size(); ++i)
{
vec[i] = head->val;
head = head->next;
}
}
int main()
{
vector<int> vec{7, 4, 9, 3, 2, 1, 8, 6, 5, 10};
bucketSort(vec, 10);
for(int n : vec)
{
std::cout << n << " ";// 1 2 3 4 5 6 7 8 9 10
}
return 0;
}
每个桶都是一个链表,便于元素的增删操作。
假设原始序列有n个元素,分成n个桶:桶排序的时间复杂度O(n) 空间复杂度O(n)
注意:在每个桶内部做排序,在元素分布相对均匀的情况下,所有桶的运算量之和为n
七、Merge Sort(归并排序)
// 归并排序:为了排序长度为n的数组,需要先排序两个长度为n/2的子数组,然后合并这两个排序的子数组,整个数组排序完毕
// 左闭右闭区间
// src存放合并之前的数组,tempArr存放合并之后的数组
void merge(vector<int>& src, int startIndex, int mid, int endIndex);
void mergeSort(vector<int>& src, int startIndex, int endIndex)
{
// 递归结束条件
if(startIndex >= endIndex)
return;
int mid = startIndex + (endIndex - startIndex) / 2;// 取区间中间元素下标
mergeSort(src, startIndex, mid);
mergeSort(src, mid + 1, endIndex);
// 将两个有序的数组合并成一个大数组
merge(src, startIndex, mid, endIndex);
}
// 将两个有序数组合并成一个大数组
void merge(vector<int>& src, int startIndex, int mid, int endIndex)
{
// 创建新数组,用来存储合并后的数组
// 注意:新数组长度为endIndex - startIndex + 1,是每个子区间的长度,不应该是src原数组的长度,注意不要乱声明大小
vector<int> tempArr(endIndex - startIndex + 1, 0);
// 进来的两个有序数组区间[startIndex, mid] [mid + 1, endIndex]
int p1 = startIndex;
int p2 = mid + 1;
int p = 0;// 新数组中的索引
// 比较两个有序小数组的元素,并依次放入大数组中
while(p1 <= mid && p2 <= endIndex)
{
if(src[p1] <= src[p2])
{
tempArr[p++] = src[p1++];
}
else
{
tempArr[p++] = src[p2++];
}
}
// 循环结束,判断小数组是否还有剩余元素,这里只可能有一个小数组有剩余元素,即sec长度为奇数的情况
while(p1 <= mid)
tempArr[p++] = src[p1++];
while(p2 <= endIndex)
tempArr[p++] = src[p2++];
// 将合并之后的新数组元素赋值到原数组src中
for(int i = 0; i < tempArr.size(); i++)
{
src[startIndex + i] = tempArr[i];
}
}
八、Heap Sort(堆排序)
堆:完全二叉树 + 所有父节点的值大于子节点的值
将堆用数组表示,第i个节点的 父节点位置 = (i - 1) / 2 孩子节点 c1 = 2i + 1, c2 = 2i + 2
// 确定递归函数参数和返回值 n为堆节点个数,i表示从第i个节点开始进行heapify
// 对有一定顺序的堆,当前第i个节点位置替换为根左右的最大值
void heapify(vector<int>& nums, int n, int i)
{
// 确定递归终止条件
if(i >= n) return;// 索引越界
// 计算当前i节点的左右孩子节点位置
int c1 = 2 * i + 1;
int c2 = 2 * i + 2;
// 记录第i个节点和孩子节点中的最大节点位置
int max = i;
if(c1 < n && nums[c1] > nums[max]) max = c1;
if(c2 < n && nums[c2] > nums[max]) max = c2;
// 将第i个节点和左右孩子节点三个节点中的最大值,交换到i的位置,即作为当前三个节点的堆顶
if(max != i)
{
swap(nums[i], nums[max]);
// 交换后,需要对交换后的位置的节点进行heapify,不断递归,直到全部满足堆的条件
heapify(nums, n, max);
}
// 相等,则说明当前节点就是三个节点的堆顶节点
}
// 创建堆
// nums为堆数组,n为数组大小
void build_heap(vector<int>& nums, int n)
{
int last_node = n - 1;
// 找到最后一个节点的父节点
int parent = (last_node - 1) / 2;
// 从最后一个节点的父节点开始,不断进行heapify
// 3 - 2 - 1 - 0
for(int i = parent; i >= 0; --i)
{
heapify(nums, n, i);
}
}
// 进行堆排序
void heapSort(vector<int>& nums, int n)
{
// 首先根据数组创建堆
build_heap(nums, n);
// 交换堆顶节点与堆最后一个节点,将堆顶最大节点交换到最后一个节点位置
// 然后截掉最后一个节点,就是弹出最大值,接着需要对堆重新进行heapify(每次都需要从根节点开始,因为将小节点交换到了根节点位置)
for(int i = n - 1; i >= 0; --i)
{
swap(nums[0], nums[i]);
// 注意此时需要进行heapify的堆的节点个数为i (相当于不考虑弹出的最大值节点)
heapify(nums, i, 0);
}
}
int main()
{
vector<int> nums{3, 44, 5, 27, 2};
heapSort(nums, nums.size());
return 0;
}
九、希尔排序
希尔排序可以说是插入排序的一种变种。无论是插入排序还是冒泡排序,如果数组的最大值刚好是在第
一位,要将它挪到正确的位置就需要 n - 1 次移动。也就是说,原数组的一个元素如果距离它正确的位
置很远的话,则需要与相邻元素交换很多次才能到达正确的位置,这样是相对比较花时间了。
希尔排序就是为了加快速度简单地改进了插入排序,交换不相邻的元素以对数组的局部进行排序。
希尔排序的思想是采用插入排序的方法,先让数组中任意间隔为 h 的元素有序,刚开始 h 的大小可以是
h = n / 2,接着让 h = n / 4,让 h 一直缩小,当 h = 1 时,也就是此时数组中任意间隔为1的元素有序,此时
的数组就是有序的了。
希尔排序 非稳定排序 时间复杂度O((nlogn)^2) 空间复杂度O(1)
void shellSortCore(vector<int>& nums, int gap, int i) {
int inserted = nums[i];
int j;
// 插入的时候按组进行插入
for (j = i - gap; j >= 0 && inserted < nums[j]; j -= gap)
{
nums[j + gap] = nums[j];
}
nums[j + gap] = inserted;
}
void shellSort(vector<int>& nums) {
int len = nums.size();
//进行分组,最开始的时候,gap为数组长度一半
for (int gap = len / 2; gap > 0; gap /= 2)
{
//对各个分组进行插入分组
for (int i = gap; i < len; ++i)
{
//将nums[i]插入到所在分组正确的位置上
shellSortCore(nums,gap,i);
}
}
}
十、基数排序
对数组中所有数依次按由低到高的位数进行多次排序; 每次排序都基于上次排序的结果。 (相对位置顺序保持不变)
class Solution
{
private:
void radixSort(vector<int>& nums, vector<int>& tmp, int divisor)
{
int n = nums.size();
vector<int> counts(10, 0);
// 统计对应个十百千万上对应数字出现的次数
for (int i = 0; i < n; ++i)
{
int x = (nums[i] / divisor) % 10;
if (x != 9) ++counts[x + 1];
}
// 前缀和
for (int i = 1; i <= 9; ++i)
{
counts[i] += counts[i - 1];
}
// 从前向后赋值
for (int i = 0; i < n; ++i)
{
int x = (nums[i] / divisor) % 10;
tmp[counts[x]++] = nums[i];
}
}
public:
vector<int> sortArray(vector<int>& nums) {
// RadixSort 基数排序
int n = nums.size();
// 预处理,让所有的数都大于等于0 -5 * 10^4 <= nums[i] <= 5 * 10^4
for (int i = 0; i < n; ++i)
{
nums[i] += 50000; // 50000为最小可能的数组大小
}
// 找出最大的数字,并获得其最大位数
int maxNum = nums[0];
for (int i = 0; i < n; ++i)
{
if (nums[i] > maxNum)
{
maxNum = nums[i];
}
}
int num = maxNum, maxLen = 0;
while (num)
{
++maxLen;
num /= 10;
}
// 基数排序,低位优先
int divisor = 1;
vector<int> tmp(n, 0);
for (int i = 0; i < maxLen; ++i)
{
radixSort(nums, tmp, divisor);
swap(tmp, nums);
divisor *= 10;
}
// 减去预处理量
for (int i = 0; i < n; ++i) {
nums[i] -= 50000;
}
return nums;
}
};
总结
提示:这里对文章进行总结:















 262
262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









