







串匹配问题
一 定义
串匹配问题的定义很简单,就是要在一般很长的文本中找和我手中的文本一样的串,就好像现在屏蔽词的机制,就得识别出文本中需要屏蔽的词的位置。
二 专业术语
模式串P:查找的目标,长度一般记作m
文本串T:待查找的文本长度一般记作n
有效偏移s:等价于模式串在文本串的s+1位置开始出现
后缀: 】
前缀:【
三 算法
1.BF算法
最简单粗暴的算法:每一个可能为开头的字符都要考虑一下,时间复杂度为O(mn)

2.RK算法
添加了预处理的部分,对模式串可能出现的n-m个位置,赋予其一个值,既要考虑让伪命中点少,又要使得计算过程简化,最好算第一个以后可以通过常数时间算出后面的。
直接用d进制数表示(d为字母集的大小),然后改进为模一个数q,算出第一个位置的p值以后,用以下递归式算后续的:
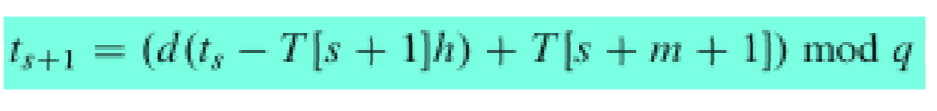
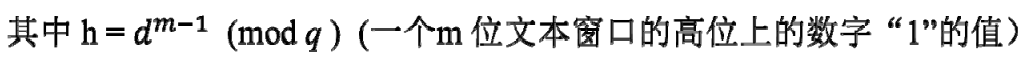
关于h,看一个例子(高糊):

这里模式串长为5,10的四次方mod13为3.
关于q的缺陷:

算法伪代码:

3.有限状态机算法
五元组:
状态集
初始状态
接受(终止)状态
字母表
状态转移函数
3个函数:
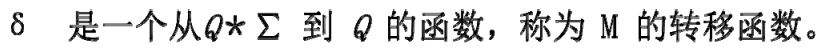


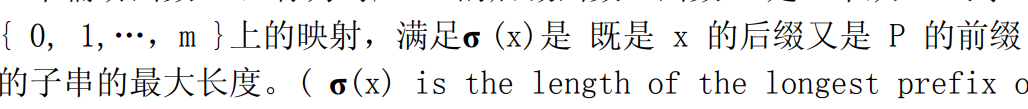
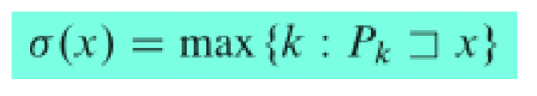
我们为了方便,就把状态定为数字,其数值即σ函数。
状态转移表和具体的状态转移例子如下:

有限状态机算法的匹配时间为O(n),但是预处理时间为O(m^3|∑|)


4.KMP算法
有限状态机算法的扩展,目标是更简化的求状态转移函数,我们用Π数组来代替状态转移表。
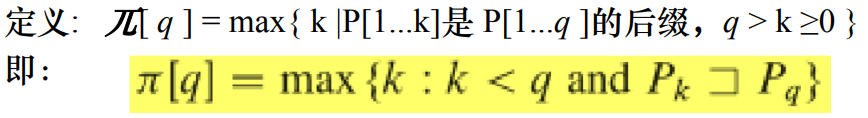
例1:
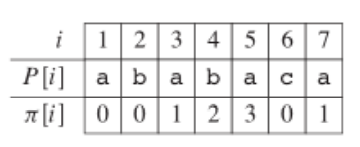
记得:Π[q]永远比q小
计算Π数组:
利用预处理得到的Π数组匹配字符串:
















 1341
1341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









