







笔记分享内容参考密歇根大学 Charles Russell Severance
开设的PostgreSQL课程:postgresql-for-everybody,网址为:https://www.coursera.org/specializations/postgresql-for-everybody#courses,在B站等也有相关视频分享。
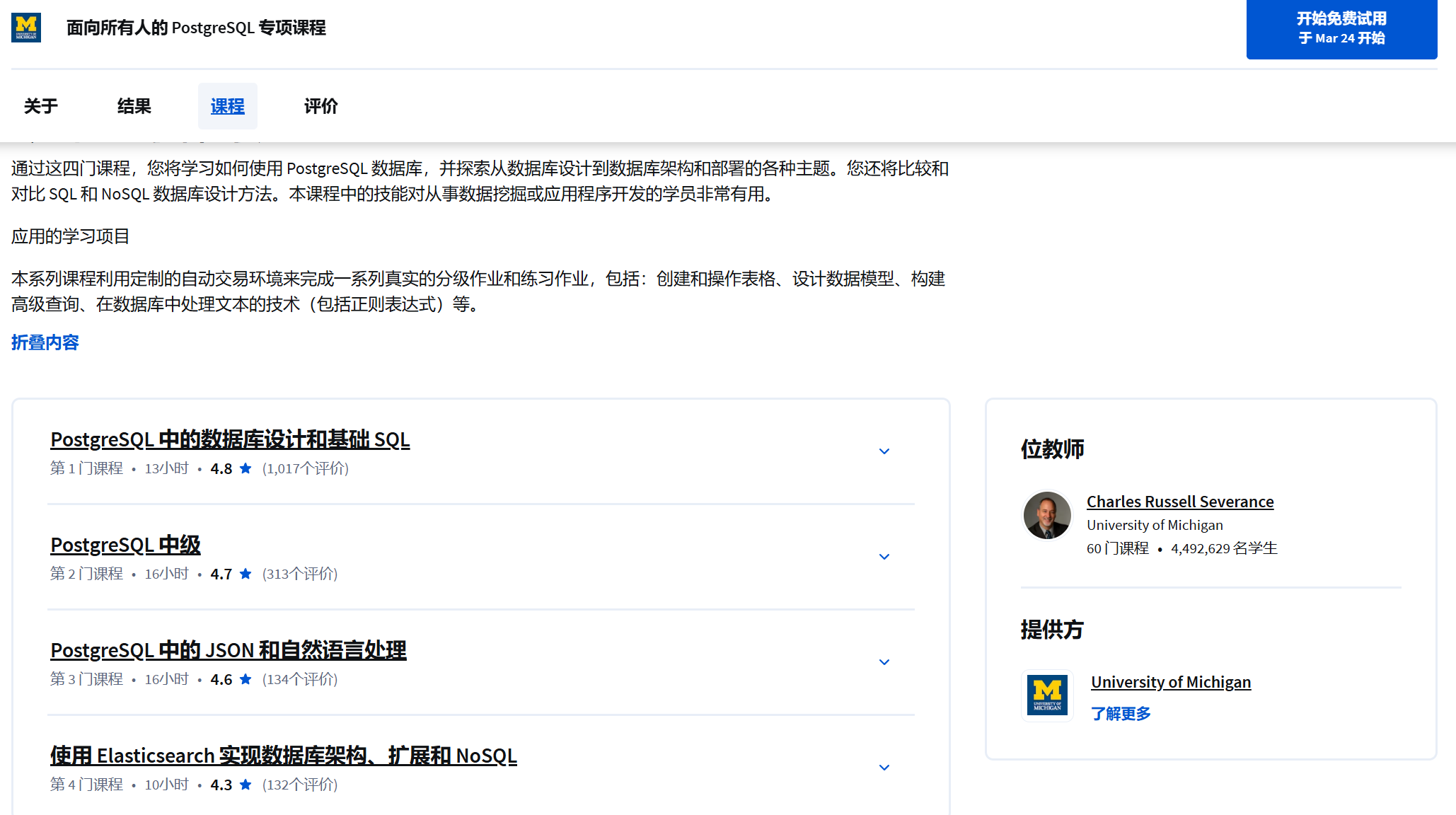
我分享的笔记内容也主要参考postgresql-for-everybody教程,但是我仅仅学习了基础部分,原课程内容更加丰富,但是我后来觉得用不到就没有再学习,原课程的主要内容是包括了以下多个方面:
1、PostgreSQL 中的数据库设计和基础 SQL:利用 psql 和 SQL 命令对 PostgreSQL 数据库中的表格执行 CRUD(创建Create、读取Read、更新Upadte、删除Delete)操作,识别并利用数据库中主键、逻辑键和外键的功能,在 PostgreSQL 中建立并区分一对多和多对多关系,回顾对制定 SQL 标准起重要作用的关键人物、组织和创新成果。
2、PostgreSQL 中级:利用 SQL 命令编辑 PostgreSQL 数据库中的表格,并从 CSV 文件生成正确规范化的表格;适当处理数据库中的文本和日期,并创建存储过程;识别标签算法及其属性;构建正则表达式,选择与模式匹配的行。
3、PostgreSQL 中的 JSON 和自然语言处理:比较 Python、PostgreSQL 和 JSON;索引和检索自然语言文本和 JSON 数据;访问 API 数据并将其存储到数据库中;创建基于 GIN 的 text[] 反向索引和 ts_vector 索引;在 PostgreSQL 中建立搜索引擎。
4、使用 Elasticsearch 实现数据库架构、扩展和 NoSQL:了解 PostgreSQL 架构;分析和比较 SQL 与 NoSQL;对比 ACID 和 BASE 风格的架构和数据库;在不同情况下创建和使用 Elasticsearch 索引。
该课程部分内容与先前分享的PostgreSQL和PostGIS入门笔记有一少部分重复之处,这个教程侧重基础知识学习和基础操作学习,并在基础教学基础上进行了3/4的深入学习,相比先前分享的入门笔记更加的深入。此外,由于是做基础知识分享,这个课程不怎么涉及PG数据库大版本特征,因此尽管教程中所用PG版本相对较老,但是仍适合各个PG版本学习者。
此外, Charles Severance教授也有一个自己的网站:https://www.pg4e.com/ ,该网站提供的免费开放视频与postgresql-for-everybody教程视频相同,需要注册和科学WangLuo。
在先前的笔记中,可能很多操作都是基于命令行实现,在Charles Russell Severance教授的视频教程中,也介绍了使用DBeaver客户端运行PG数据库等。
除了该课程外,B站和Youtube等平台,还有其他相关的课程,例如德哥在B站分享的每天5分钟PG聊通透系列视频:https://space.bilibili.com/310191812/lists/582141?type=series ;PostgreSQL 天天象上培训系列视频:https://space.bilibili.com/310191812/lists/238124?type=series 。
1 PG数据库设计和SQL基础
1.1 关系型数据库的历史
1970年代以前,由于磁带的物理特性,数据是以线性方式记录在其上的,这意味着访问磁带上的特定数据需要从起点开始顺序读取直到找到所需的数据位置。这种访问方式称为顺序访问,与现代硬盘或固态硬盘支持的随机访问形成对比。当时在处理大量数据时,尤其是那些不适合全部加载到内存中的数据集,采用一种叫顺序主更新的技术。
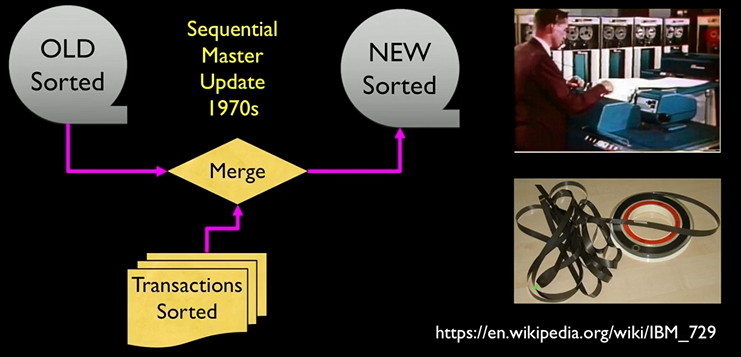
这种方法通常涉及到两个文件:一个主文件和一个事务文件。主文件包含现有的数据记录,而事务文件则包含了对这些记录所做的更改(如新增、修改或删除)。更新过程如下:首先,将主文件和事务文件都按照相同的键值(通常是唯一的标识符)进行排序;然后,通过合并这两个已排序的文件,生成一个新的主文件,其中包含了所有更新后的记录;在合并过程中,如果遇到相同的键值,则根据事务文件中的信息来决定如何更新主文件中的记录。
随着软硬件技术的发展,硬盘等取代了磁带,随机访问取代了顺序访问,关系型数据库相关研究增多,关系型数据库主要是用于在数据中进行正确的跳转。在上世纪70年代后,IBM等公司提出了关系模型的基本概念、引入了SQL(Structured Query Language)作为查询语言的基础等。
在80年代,ANSI(美国国家标准学会)和ISO(国际标准化组织)共同发布了SQL的标准规范,实现了关系型数据库技术走向规范化。
SQL被设计成一种非过程化语言,当使用SQL编写查询时,需要指定要执行的操作(比如选择哪些数据、如何过滤或排序),而不需要详细说明这些操作应该如何具体执行,这种特性使得SQL非常适合用来处理数据库中的数据,因为它允许用户以一种声明式的方式表达他们的需求,而不必关心底层的实现细节。简单来说,SQL是我们与数据库对话的语言。
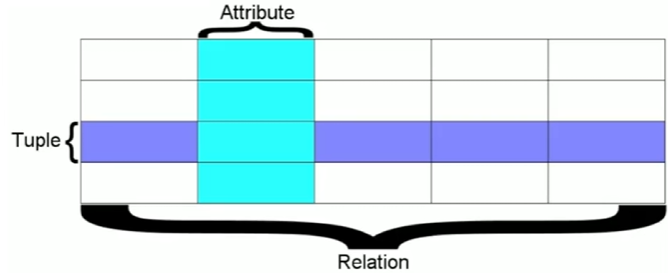
此外,从理论层面和实际操作角度来看,数据库中的“表”有着不同的称谓和理解方式。在关系数据库的理论层面(关系模型),数据库中的表被称为关系(Relation),但是在程序员看来这就是一个表Table;从理论层面,表中的行是元组,表示一个具体实例,表中的列是属性,定义了该列的数据类型;但是从程序员实际操作的角度,表中的单条记录就是行,而定义特定类型信息的就是列。
1.2 SQL 基础解析
在这一章节中,Charles Russell Severance教授介绍的内容与我们以前分享的相似,主要介绍了常用的架构和基础的几个命令。
使用SQL的场景往往是 PG数据库被部署在数据库服务器上,用户使用pgAdmin等可视化工具或者psql命令行,通过SQL语言在本地与数据库服务器上的数据库进行交互。
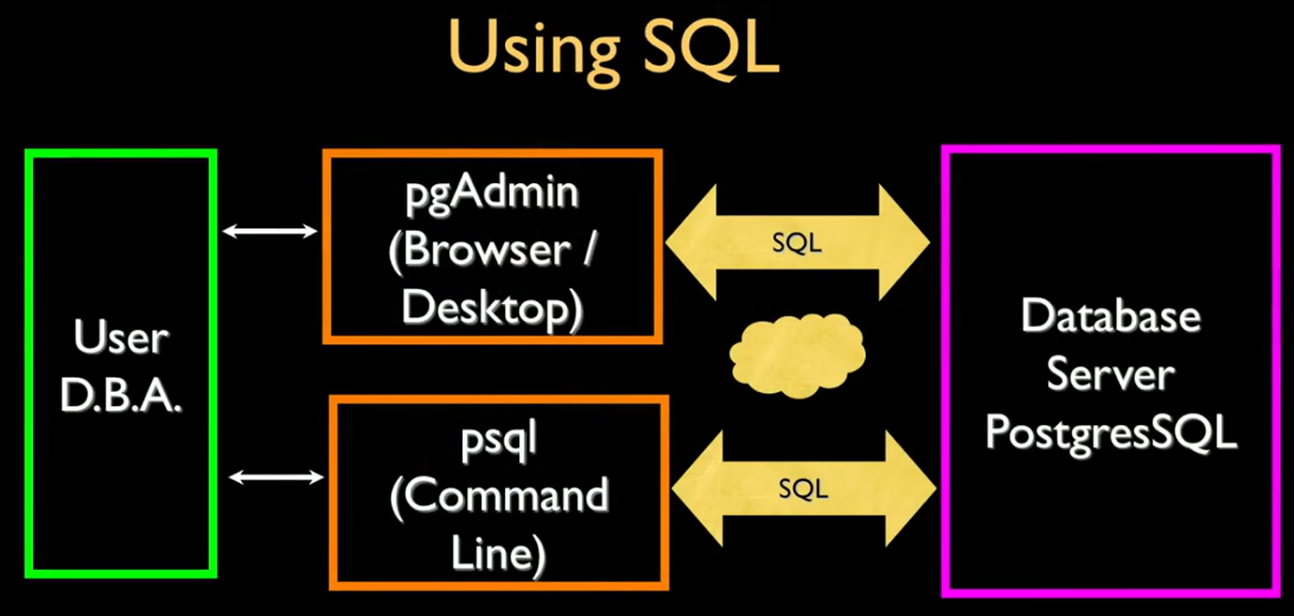
最基础的命令包括psql命令和SQL命令,psql是以\开头的命令,SQL命令是SELCET等。例如:包括在Liunx中连接到 PostgreSQL 数据库的命令行工具 psql 的一个使用实例:psql -U postgres,通过这个实例以超级用户方式链接了PG数据库。

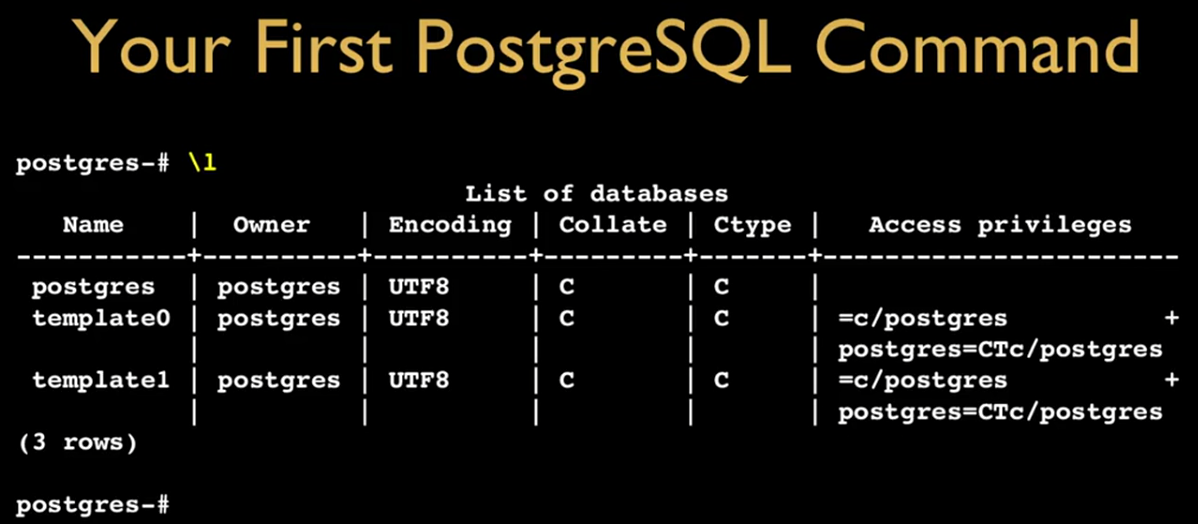
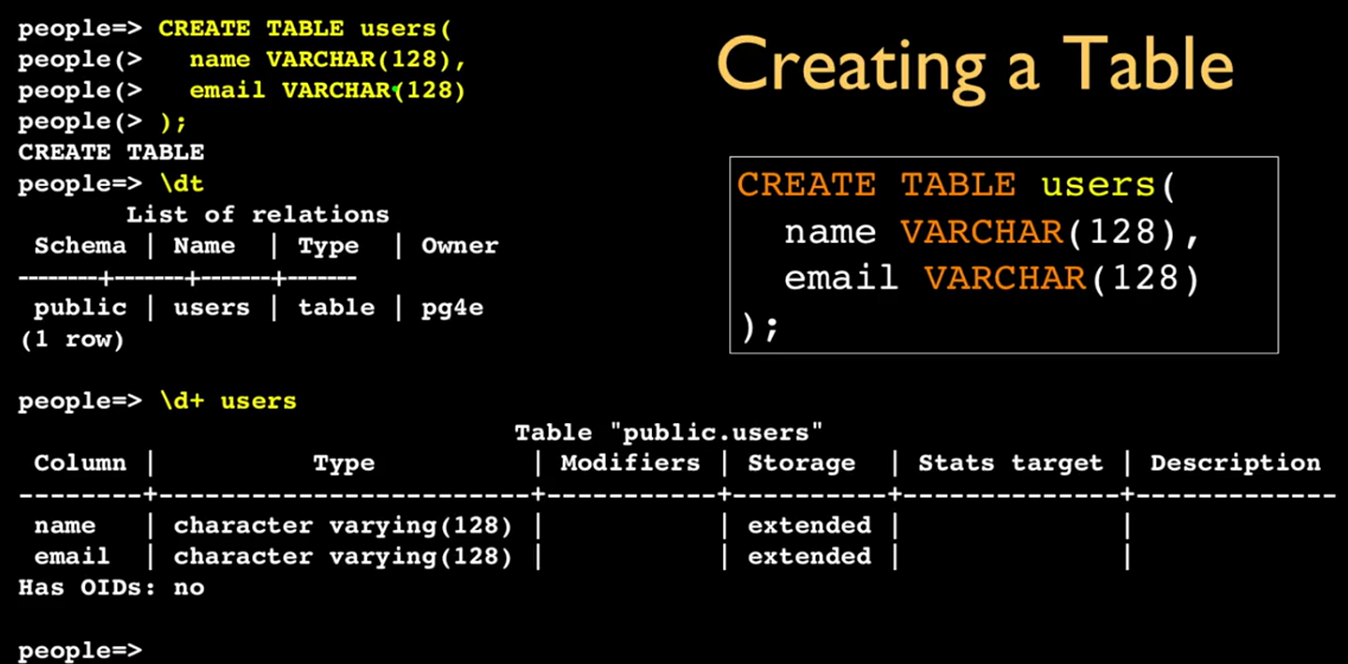
使用 \l 命令列出现在有的数据库及相关信息。
创建用户 CREATE USER pg4e WITH PASSWORD ‘secret’; ,创建数据库 CREATE DATABASE people WITH OWNER 'pg4e'; ,退出jpsql交互式终端 \q 。

使用用户pg4e链接到数据库people,并使用了\dt命令列出当前数据库中的表。

在people数据库中创建users表,包括name和email两个属性;使用 \d+表名 方式显示指定表的详细信息。
1.3 使用PythonAnywhere运行SQL语言
PythonAnywhere 是一个在线平台,它允许用户直接在浏览器中编写和运行 Python 代码,无需进行任何本地设置或服务器配置,提供了一个基于浏览器的集成开发环境(IDE),支持文件编辑、虚拟环境管理等功能,具有从免费到不同层级付费的服务计划。此外,由于所有的代码都在云端运行,因此无论身处何地都可以通过互联网访问和修改项目。
我们可以在网站 https://www.pythonanywhere.com/registration/register/beginner/ 注册一个免费账户,这个账户如果超过3月不使用就会自动注销。
在控制台中,启动一个bash控制台,这里教程又介绍了一些Shell命令,尽管这些命令我在以前也进行过分享,但是我还是做了笔记,内容如下。在该控制台中,支持使用Tab自动补全文件名等。
| 命令 | 功能 |
|---|---|
| pwd | 查看当前工作目录 |
| ls | 查看文件列表 |
| cat 文件名 | 查看某个文件 |
| cd 文件夹 | 进入某个工作目录 |
| cd … | 返回上一级文件夹 |
| cd ~ | 返回主文件夹 |
| clear | 清屏 |
| exit | 关闭并注销当前会话 |
此外,在控制台右侧下拉菜单中,找到file选择在新标签页打开,可以打开文件系统。
在文件系统中,可以新建一个.sql文件,在我们想要使用某个文件中的SQL语言执行命令时可以直接使用。
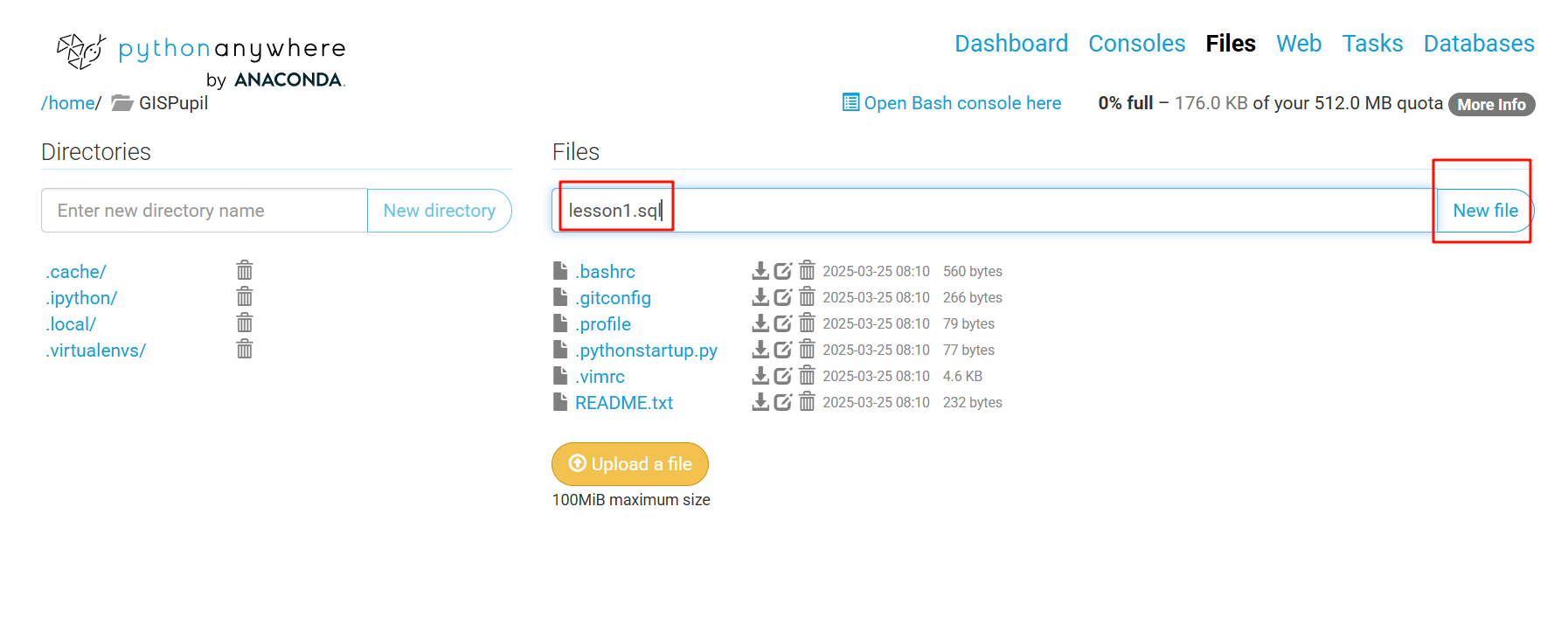
点击New file后会新建文件并打开,在打开的文件中输入相关的命令,这里的示例为:SELECT count(*) From pg4e_debug; ,输入后点击保存。

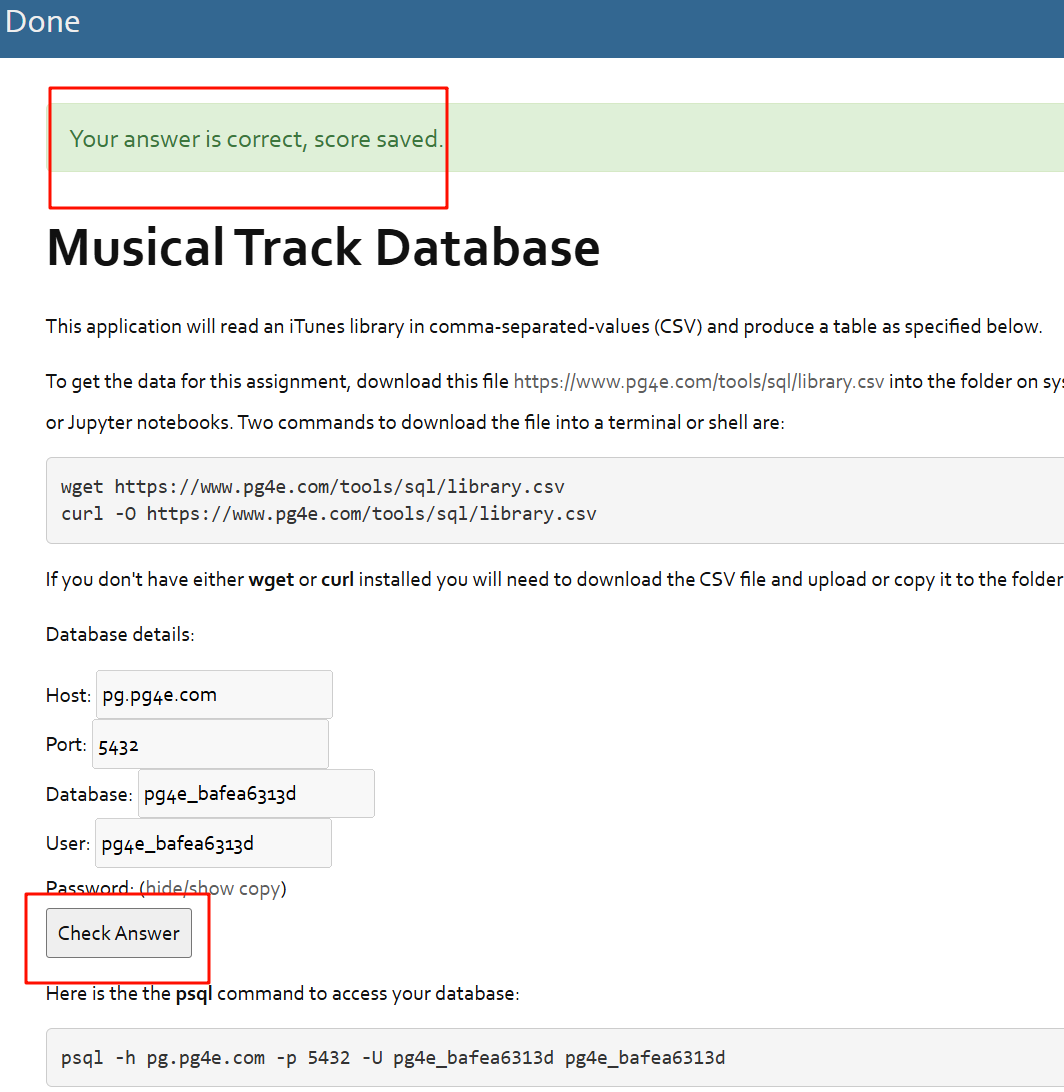
接下来,尝试连接到教程提供的PG数据库,需要注册才能获取相关信息,需要注意的是:每个人注册后的用户和密码均不同,所以需要我们去注册一个才可以正常使用。
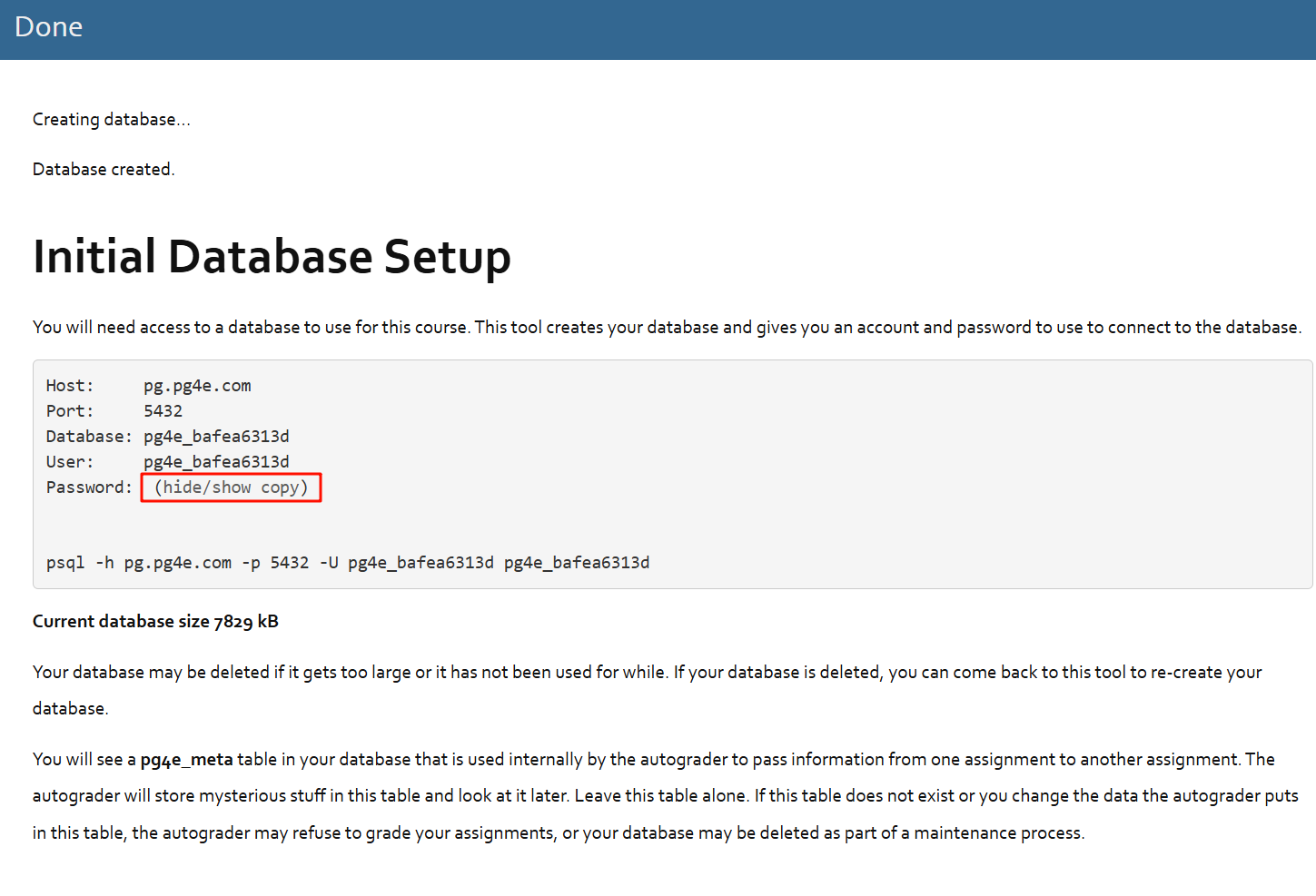
使用SQL命令连接搭配数据库:psql -h pg.pg4e.com -p 5432 -U pg4e_bafea6313d pg4e_bafea6313d ,这样便连接到了教程提供的数据库。

但是我没用进行相关的建库等操作,因此我这个用户下只有用户信息表,所以我没具体运行其他的命令,原教程介绍的其他命令如下图所示:
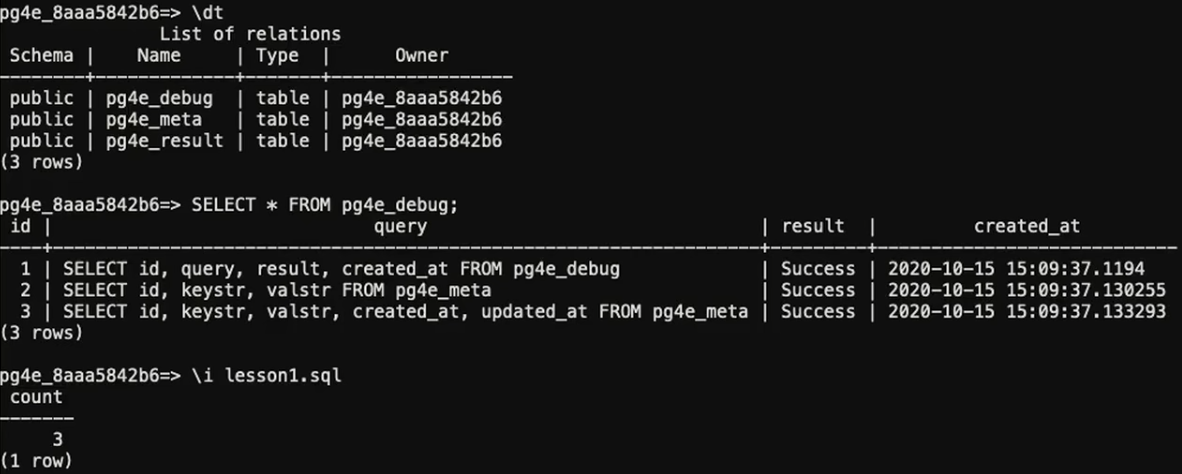
上图最后一行,使用了 \i 直接从文件中读取并执行 SQL 命令。
1.4 使用DBeaver操作PostgreSQL数据库
DBeaver 是一款功能强大的免费、多数据库工具,适用于开发人员、数据库管理员、分析师和任何需要与数据库进行交互的人员,支持广泛的数据库系统,包括关系型数据库(如 MySQL、PostgreSQL、MariaDB、SQLite、Oracle、SQL Server 等)、NoSQL 数据库(如 MongoDB、Cassandra 等)以及云数据库服务(如 Amazon Redshift、Google BigQuery 等),其具有免费的社区版本,直接下载即可:https://dbeaver.io/download/ ,下载安装包后傻瓜式安装即可。当然,目前Navicat也推出了免费的Lite版本,也可以下载安装Navicat Lite学习使用。从学习角度来说,两者区别不大;从企业生产角度可能还是Navicat为主。
下载安装DBeaver后,连接PG数据库:
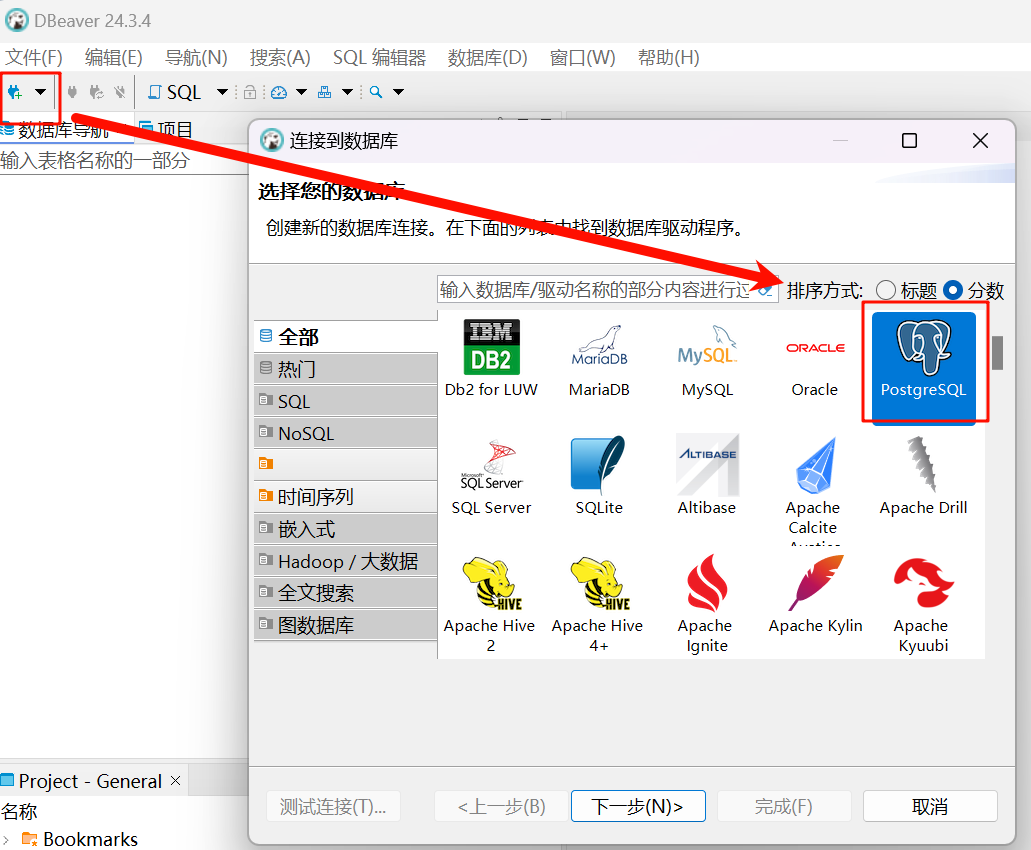
设置 主机、数据库、端口、用户名、密码后,点击完成。
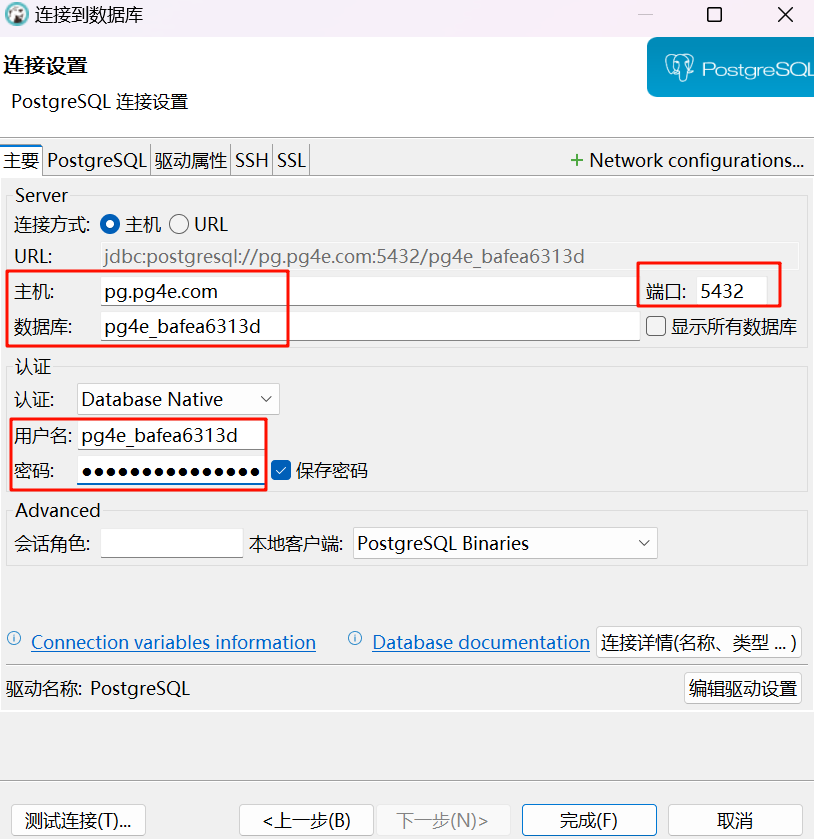
在首次连接数据库完成后,可能会下载相关的驱动。打开数据库,可以看到目前仅有一个存储用户信息的表pg4e_meta,因此创建表pg4e_debug。
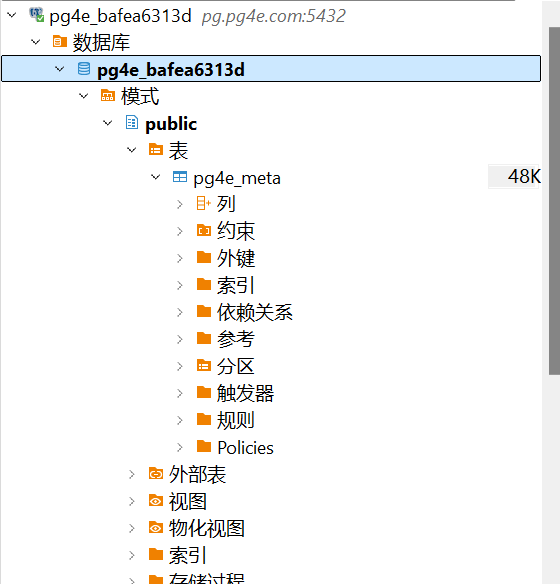
打开SQL编辑器,输入如下代码,点击编辑器左侧的黄色三角按钮运行代码,刷新后可以看到新建的表pg4e_debug。
CREATE TABLE pg4e_debug (
id SERIAL,
query VARCHAR(4096),
result VARCHAR(4096),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY(id)
);
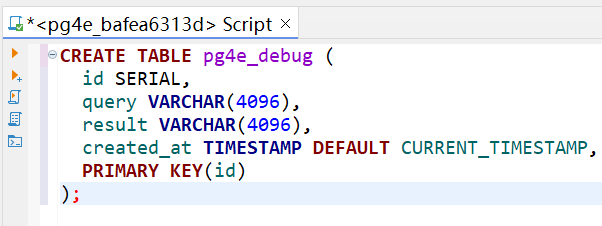
接下来再创建表 pg4e_result,代码如下。
CREATE TABLE pg4e_result (
id SERIAL,
link_id INTEGER UNIQUE,
score FLOAT,
title VARCHAR(4096),
note VARCHAR(4096),
debug_log VARCHAR(8192),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP
);
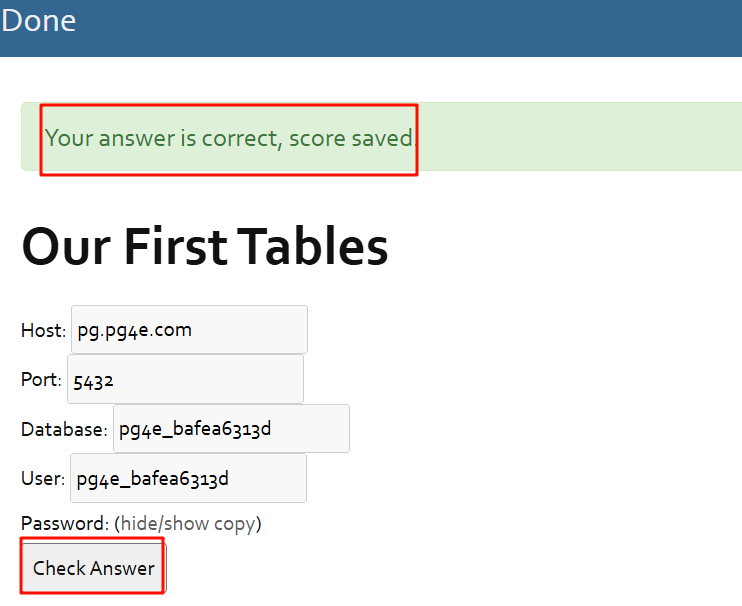
如果你有在pg4e网站上注册,点击 Check Answer,将会检测你是否成功创建了两个表,是否完成了这个学习任务。
1.5 PG表 核心 基础 操作
插入操作:使用INSERT语句在表中插入行
INSERT INTO users (name, email) VALUES ('Chuck', 'csev@umich.edu') ;
INSERT INTO users (name, email) VALUES ('Somesh', 'somesh@umich.edu') ;
INSERT INTO users (name, email) VALUES ('Caitlin', 'cait@umich.edu') ;
INSERT INTO users (name, email) VALUES ('Ted', 'ted@umich.edu') ;
INSERT INTO users (name, email) VALUES ('Sally', 'sally@umich.edu') ;
删除操作:DELETE FROM语句
DELETE FROM users WHERE email='ted@umich.edu';
更新操作:Updata语句,会更新所有符合WHERE子句要求的行
UPDATE users SET name='Charles' WHERE email='csev@umich.edu';
检索操作:SELECT语句
SELECT * FROM users;
SELECT * FROM users WHERE email='csev@umich.edu';
排序操作:在SELECT语句中添加ORDER BY子句,以按升序或降序对结果进行排序
SELECT * FROM users ORDER BY email;
LIKE 通配符 %%:在WHERE子句中使用LIKE运算符进行通配符匹配
SELECT * FROM users WHERE name LIKE '%e%';
LIMIT/OFFSET 语句:只请求前 n 行,或者跳过一些行后的n 行,应用在WHERE和ORDER BY子句之后,OFFSET 偏移从第0行开始。
SELECT * FROM users ORDER BY email DESC LIMIT 2;
SELECT * FROM users ORDER BY email OFFSET 1 LIMIT 2;
计数语句:COUNT统计符合要求的行数
SELECT COUNT(*) FROM users;
SELECT COUNT(*) FROM users WHERE email='csev@umich.edu';
1.6 PG数据类型
PG数据库支持大量的数据类型,主要使用的数据类型包括:
- 字符串类型:
CHAR(n)、VARCHAR(n)、TEXT - 二进制类型:
BYTEA - 整数类型:
SMALLINT、INTEGER、BIGINT - 浮点数类型:
REAL、DOUBLE PRECISION - 精确数值类型:
NUMERIC(accuracy, decimal),现在写为了:NUMERIC(precision, scale)) - 日期时间类型:
TIMESTAMP、DATE、TIME
详细的用法如下所示:
字符串类型
| 类型名 | 用法与特点 | 示例 |
|---|---|---|
CHAR(n) | 固定长度字符串,存储长度为n的字符,不足时补空格,超过则截断。 | CHAR(5):存储'Hello','Hi'会被填充为'Hi '。 |
VARCHAR(n) | 可变长度字符串,最大长度为n,不补空格,超过长度则报错。 | VARCHAR(10):存储'World',但'12345678901'会因超长报错。 |
TEXT | 无长度限制的字符串,适合存储长文本(如文章、评论)。 | TEXT:存储'这是一个很长的文本,没有长度限制'。 |
二进制类型
| 类型名 | 用法与特点 | 示例 |
|---|---|---|
BYTEA | 存储二进制数据(如图片、文件),无长度限制,但较少被使用。 | BYTEA:存储E'\\xDEADBEEF'(十六进制表示的二进制数据)。 |
整数类型
| 类型名 | 用法与特点 | 示例 |
|---|---|---|
SMALLINT | 2字节整数,取值范围:-32768 ~ 32767。 | SMALLINT:存储-10000或30000。 |
INTEGER | 4字节整数,取值范围:-2147483648 ~ 2147483647。 | INTEGER:存储1000000。 |
BIGINT | 8字节整数,取值范围:-9223372036854775808 ~ 9223372036854775807。 | BIGINT:存储123456789012345。 |
浮点数类型
| 类型名 | 用法与特点 | 示例 |
|---|---|---|
REAL | 单精度浮点数(4字节),精度约6-7位小数。 | REAL:存储3.14159(可能四舍五入为3.1416)。 |
DOUBLE PRECISION | 双精度浮点数(8字节),精度约15-17位小数。 | DOUBLE PRECISION:存储3.141592653589793。 |
精确数值类型
| 类型名 | 用法与特点 | 示例 |
|---|---|---|
NUMERIC(precision, scale) | 精确十进制数,precision表示总位数,scale表示小数位数,适合货币、财务计算。 | NUMERIC(10,2):存储123456.78(总10位,小数2位)。 |
日期时间类型
| 类型名 | 用法与特点 | 示例 |
|---|---|---|
DATE | 存储日期(如YYYY-MM-DD)。 | DATE:存储'2023-10-01'。 |
TIME | 存储时间(如HH:MM:SS)。 | TIME:存储'14:30:00'。 |
TIMESTAMP | 存储日期和时间(如YYYY-MM-DD HH:MM:SS)。 | TIMESTAMP:存储'2023-10-01 14:30:00'。 |
总结表格
| 类型名 | 用法与特点 | 示例 |
|---|---|---|
CHAR(n) | 固定长度字符串,补空格。 | CHAR(5):'Hello' → 'Hello','Hi' → 'Hi '。 |
VARCHAR(n) | 可变长度字符串,最大长度n。 | VARCHAR(10):'World'。 |
TEXT | 无长度限制的文本。 | TEXT:长文章内容。 |
BYTEA | 二进制数据,如图片或文件。 | E'\\xDEADBEEF'。 |
SMALLINT | 2字节整数,范围-32768~32767。 | -10000。 |
INTEGER | 4字节整数,范围-21亿~21亿。 | 1000000。 |
BIGINT | 8字节整数,范围-9e18~9e18。 | 123456789012345。 |
REAL | 单精度浮点数,约6位小数。 | 3.14159。 |
DOUBLE PRECISION | 双精度浮点数,约15位小数。 | 3.141592653589793。 |
NUMERIC(precision, scale) | 精确十进制,precision总位数,scale小数位数。 | NUMERIC(10,2):123456.78。 |
DATE | 日期(YYYY-MM-DD)。 | '2023-10-01'。 |
TIME | 时间(HH:MM:SS)。 | '14:30:00'。 |
TIMESTAMP | 日期+时间(YYYY-MM-DD HH:MM:SS)。 | '2023-10-01 14:30:00'。 |
此外,PostgreSQL还支持TIMESTAMPTZ(带时区的TIMESTAMP)和INTERVAL(时间间隔),还可以使用NOW()函数。
1.7 键和索引
键用来表示定义和标识每个记录的属性或一组属性,类似于系统管理中的句柄。当我们需要创建多个表并将他们联系在一起时,需要为每一行创建一个整数主键,这样便于有效的对其他表中的某一行引用添加外键。关于主键与外键的概念,我们在先前的教程中也有过分享,主要是用为唯一标识和跨表标识。
在下面的代码中,首先删除了先前创建的表, 又新建了用户表,设置了id是主键,主键坚持非空原则。设置了email属性唯一,不会重复。
DROP TABLE users;
CREATE TABLE users (
id SERIAL,
name VARCHAR(128),
email VARCHAR(128) UNIQUE,
PRIMARY KEY(id)
);
当我们复制整个磁盘或数据库时,往往需要很长的时间,但是当仅仅检索某一个文件时却很快,这是因为索引的存在。索引的存在使得检索不是线性进行的,而我们复制文件是全局线性的。索引提供了捷径。
常见的索引有B-trees和哈希索引。B树代表分叉或者分支,当你需要检索数据时,是通过某个索引范围到另一个索引范围,从另一个范围再缩小索引范围,进行对数方式的读取。如果有百万数据,使用对数方式,可能仅仅需要访问6个磁盘上的数据块就能访问到最终的数据。
在一个简单的两层树中,索引记录了下面数据块的开始和结束值,当需要检索某个值时,通过上方的索引便可以快速找到下面某个数据块,而不是采用顺序主更新的方式,按顺序检索所有的数据。在实际的B树中可能是具有很多层的, 结构更加复杂,帮助进行范围查找。
哈希索引通常用于整数键,哈希是一种计算方式,使用不同的哈希函数来计算哈希相比B树更短,常用于精确匹配,主要是擅长对主键或GUID类型的查找。
数据库会实现自动设置索引,我们仅仅需要了解简单的原理,具体如何实现仅仅需要数据库自己去实现。
1.8 创建音乐曲目数据库
在这个演练中,复制了一个CSV文件到PG数据库,构建了一个音乐曲目数据库。仍旧是使用的pythonanywhere提供的liunx平台,首先使用wget或curl命令将CSV文件下载到平台中。
wget https://www.pg4e.com/tools/sql/library.csv
curl -O https://www.pg4e.com/tools/sql/library.cs
在下载完成后,链接访问数据库,使用pqsl命令:
psql -h pg.pg4e.com -p 5432 -U pg4e_bafea6313d pg4e_bafea6313d
在输入密码并进入数据库后,创建本次练习所需要的表格结构:
CREATE TABLE track_raw
(title TEXT, artist TEXT, album TEXT,
count INTEGER, rating INTEGER, len INTEGER);
接下来,使用psql的\copy命令,将 track_raw 表复制到数据库内,复制完成后,会有一个copy 296的输出,表示复制成功。在如下代码中,使用的\copy命令是一个psql命令,而不是SQL命令;track_raw(title,artist,album,count,rating,len)指定了目标表名和该表中的列名,表示将向这几列导入数据,**FROM ‘library.csv’**指定了要从中读取数据的文件路径;**WITH DELIMITER ‘,’**表示CSV文件中的字段由逗号分隔。
\copy track_raw(title,artist,album,count,rating,len) FROM 'library.csv' WITH DELIMITER ',' CSV;
还可以执行查询操作或者查看操作等,例如查询title, album两列,且仅仅输出前3行。
SELECT title, album FROM track_raw ORDER BY title LIMIT 3;
输出结果如下所示:

所有操作结束后,仍可以通过检查答案的方式,检查练习内容。
2 数据关系
2.1 关系型数据库设计
数据库设计的目的是得到一张关系图表,使用线、框等表示,然后将这个图表转为数据库结构和命令,来创建数据库。大型的项目可能会创建大型的数据模型图,数据模型就是存储数据的方式。构建数据模型的基本规则是不能总是按照顺序读取文件,而是要在数据间跳跃式访问。

数据库的强大之处就是在于即使面对海量数据时,其速度也会很快。构建数据库模型时,首先要考虑的是 应用程序组织中的单一事物是什么?而不是非要把用户放在数据模型正中去链接其他组成部分。例如在一个音乐曲目系统中,曲目是单一的事物,所以要创建一个基本的包含曲目信息的表。这个表中可以包含曲目的标题、作者、时长等属性。除了曲目外,还有专辑,曲目属于某一个专辑;还有作曲家,一个作曲家可能有多个专辑和多个曲目;此外,不同的作曲家属于不同的流派和风格,最终需要把曲目、作曲家、专辑、流派等连接起来。
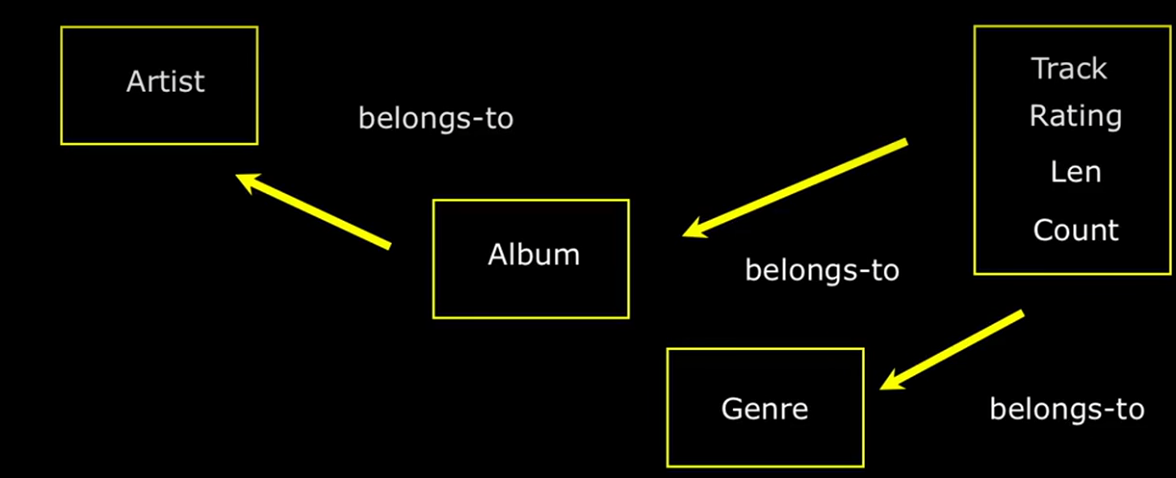
数据模型需要多次修改、简化等,最终构建一个真正适合高效的数据模型。
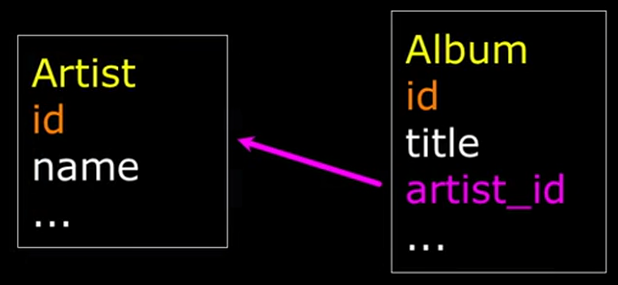
当构建数据模型和表格后,需要使用Keys去连接不同的表或行。使用键将一行连接到另一行,或者使用键在表中查询。键包括主键,主键是类似于ID的单一的字符串等;逻辑键可能是邮箱地址等类似的信息,是与客观实际相联系的键,当在搜索框搜索时,输入搜索的内容就是逻辑键;外键是一个表中的整数指向外部的另一个表。
键的命名有不同的规范,很多规范下,都会将主键命名为id,逻辑键可以是任何形式,外键往往是xxx_id的形式,例如artist_id是执行artist的外键,指向artist的某一行。主键和外键尽可能的是整数,这样能够便于处理,更加高效的匹配。
另一个内容是命名的规范,选择哪种规范不重要,重要的是在一个系统内使用相同的命名规范。基本规范包含以下的规则:不要使用逻辑键作为主键,例如不要使用学号、电子邮件地址等作为主键,即使学号它们是一组整数;逻辑键可以被更改,尽管邮件地址等作为逻辑键很少会被更改,但是是可以去更改,不要过于相信邮箱地址不会变化;邮件地址等字符串可以作为逻辑键,逻辑键可以整数或字符串,主键是整数,但是在关系中,字符串的处理速度远不如整数高效。
在了解主键、逻辑键、外键后,需要开始使用它们,使用数据库规范化的方式将主键和外键连接起来。我们工作的目标是能够跟踪各个表格,数据库规范化是一个复杂的内容,甚至需要很长的时间才能去了解,有太多复杂的理论,但是在实际工作中,规范化教会我们如何真的使用数据库。
3NF范式要求我们:不要复制字符串数据,而是引用数据和指向数据;使用整数键作为主键和引用,并将主键放入每一列中。
通过一定的范式,构建一个概念模型,按照该图如进一步创建表和插入数据等。
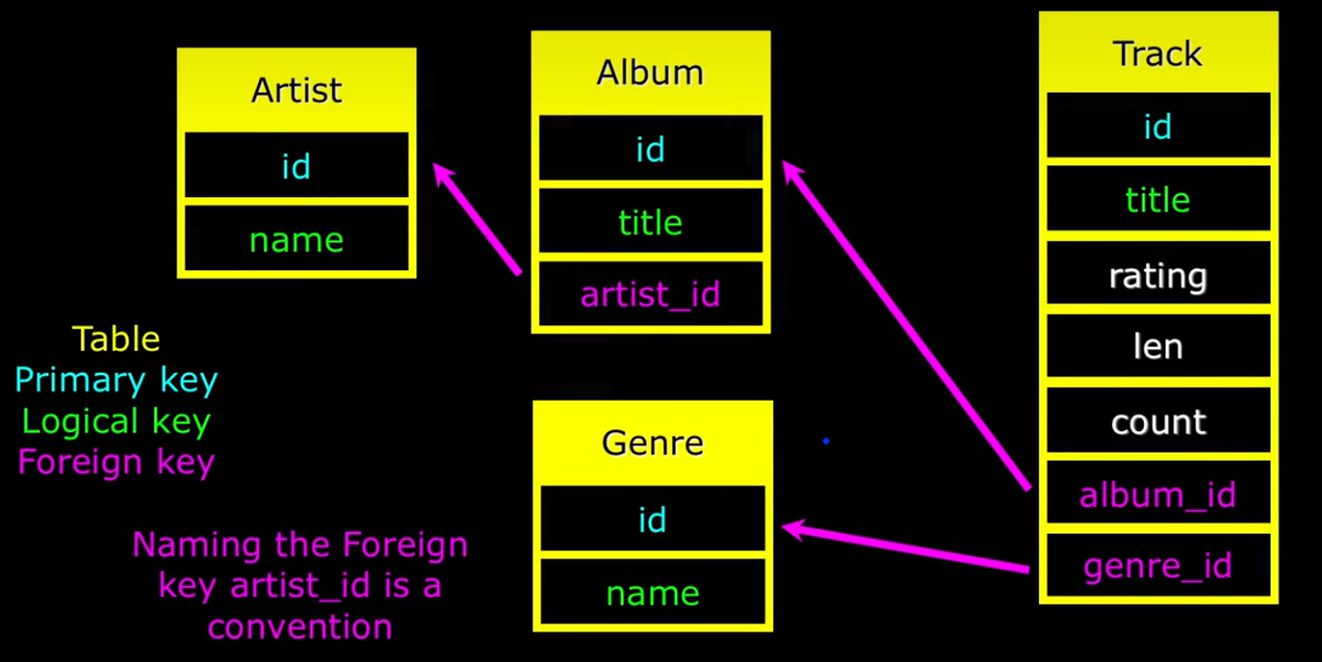
2.2 数据表的实现
在获得概念模型后,需要进一步创建表、插入数据等,最终实现表。首先需要创建一个音乐数据库,使用的代码如下:
sudo -u postgres psql postgres
普通的Linux发行版下,先切换超级用户,再创建数据库。
CREATE DATABASE music
WITH OWNER 'pg4e' ENCODING 'UTF8';
接下来使用如下代码创建具体的表,在代码中设置了主键、使用UNIQUE标识了逻辑键,使用INTERGER REFERENCES设置了外键;此外,使用ON DELETE CASCAD作为外键的约束,用于定义当父表中的记录被删除时,数据库应如何自动处理相关子表中的数据。具体来说,如果在定义外键时使用了 ON DELETE CASCADE,那么当父表中的一条记录被删除时,所有在子表中引用该记录的关联行也会自动被删除。
CREATE TABLE artist (
id SERIAL,
name VARCHAR(128) UNIQUE,
PRIMARY_KEY(id)
);
CREATE TABLE album (
id SERIAL,
title VARCHAR(128) UNIQUE,
artist_id INTEGER REFERENCES artist(id) ON DELETE CASCADE,
PRIMARY KEY(id)
);
CREATE TABLE genre (
id SERIAL,
name VARCHAR(128) UNIQUE,
PRIMARY_KEY(id)
);
CREATE TABLE track (
id SERIAL,
title VARCHAR(128),
len INTEGER,
rating INTEGER,
count INTEGER,
album_id INTEGER REFERENCES genre(id) ON DELETE CASCADE,
genre_id INTEGER REFERENCES album(id) ON DELETE CASCADE,
UNIQUE(title, album_id),
PRIMARY KEY(id)
);
在上面的代码中,最后一段使用了UNIQUE(title, album_id),,这个约束用来表示当title和album_id组合在一起时,这个组合要唯一,也就是一个专辑里面不会有重复的歌曲名,尽管可能在其他专辑中存在与该专辑中某个歌曲重名的歌曲。
在创建表后,需要进一步插入数据。在music数据库中,为artist、album、genre、track四个表插入数据的代码与插入时的输出,如下:
music=> INSERT INTO artist (name) VALUES ('Led Zeppelin');
INSERT 0 1
music=> INSERT INTO artist (name) VALUES ('AC/DC');
INSERT 0 1
music=> SELECT * FROM artist;
id | name
----+-------------
1 | Led Zeppelin
2 | AC/DC
(2 rows)
music=> INSERT INTO album (title, artist_id) VALUES ('Who Made Who', 2);
INSERT 0 1
music=> INSERT INTO album (title, artist_id) VALUES ('IV', 1);
INSERT 0 1
music=> SELECT * FROM album;
id | title | artist_id
----+--------------+-----------
1 | Who Made Who | 2
2 | IV | 1
(2 rows)
music=> INSERT INTO genre (name) VALUES ('Rock');
INSERT 0 1
music=> INSERT INTO genre (name) VALUES ('Metal');
INSERT 0 1
music=> SELECT * FROM genre;
id | name
----+-------
1 | Rock
2 | Metal
(2 rows)
music=> INSERT INTO track (title, rating, len, count, album_id, genre_id)
music-> VALUES ('Black Dog', 5, 297, 0, 2, 1) ;
INSERT 0 1
music=> INSERT INTO track (title, rating, len, count, album_id, genre_id)
music-> VALUES ('Stairway', 5, 482, 0, 2, 1) ;
INSERT 0 1
music=> INSERT INTO track (title, rating, len, count, album_id, genre_id)
music-> VALUES ('About to Rock', 5, 313, 0, 1, 2) ;
INSERT 0 1
music=> INSERT INTO track (title, rating, len, count, album_id, genre_id)
music-> VALUES ('Who Made Who', 5, 207, 0, 1, 2) ;
INSERT 0 1
music=> SELECT * FROM track;
id | title | len | rating | count | album_id | genre_id
----+---------------+-----+--------+-------+----------+----------
1 | Black Dog | 297 | 5 | 0 | 2 | 1
2 | Stairway | 482 | 5 | 0 | 2 | 1
3 | About to Rock | 313 | 5 | 0 | 1 | 2
4 | Who Made Who | 207 | 5 | 0 | 1 | 2
(4 rows)
在初试阶段,插入时可能需要你记下来外键和主键的对应关系,以避免对应的关系是错误的。但是实际工作中,可能会采用更加方便的方法。最终实现的各个表和它们之间的联系如下:

现已经将数据分散表中,创建了主键,通过外键将他们连接在了一起,现在需要进一步认识并使用这些数据。尽管实际的项目中是百万等级别的数据,但是实际学习中可能仅有几条记录。接下来通过遍历外键来浏览整个信息网络,实现跨表连接查询等。
连接查询,也就是JOIN,是SELECT的一部分,连接了多个表,是一个跨多个表的SECLET。JOIN时必须要使用ON子句,以便于提供一个连接时的条件。如下图所示,我们有了如下表,但是在展示时,我们想要展示标题和姓名,而不是标题和ID,通过id我们不容易直观的看出来作者是谁。
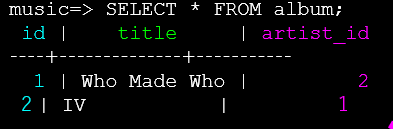
因此可以通过JOIN的方式,实现查询。在如下代码中,展示了album表中的标题,artist表中的姓名,使用JOIN连接了album和artist两个表,需要注意JOIN的顺序,在ON子句中设置了条件。这样我们就直观的选择出来了标题和作者信息,清楚的看到来我们关注的内容。
SELECT album.title, artist.name
FROM album JOIN artist
ON album.artist_id = artist.id;
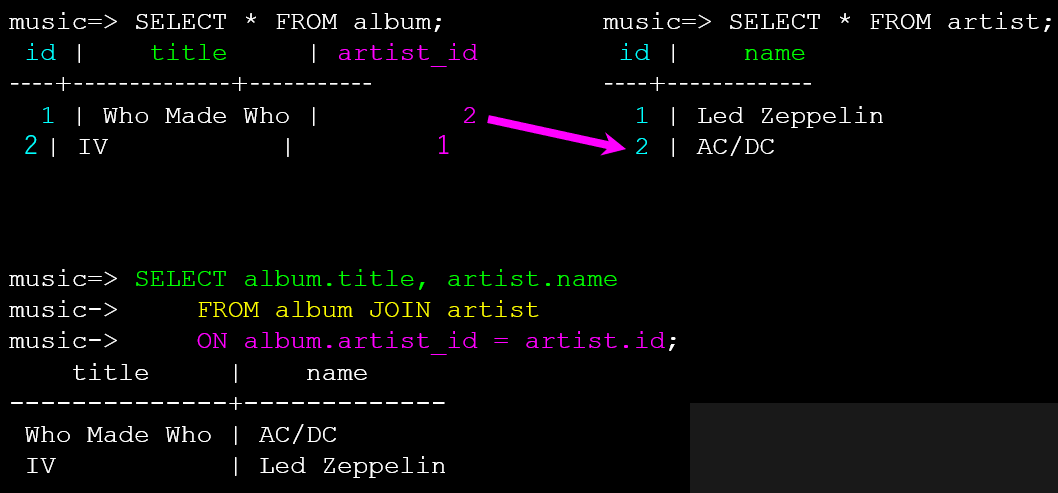
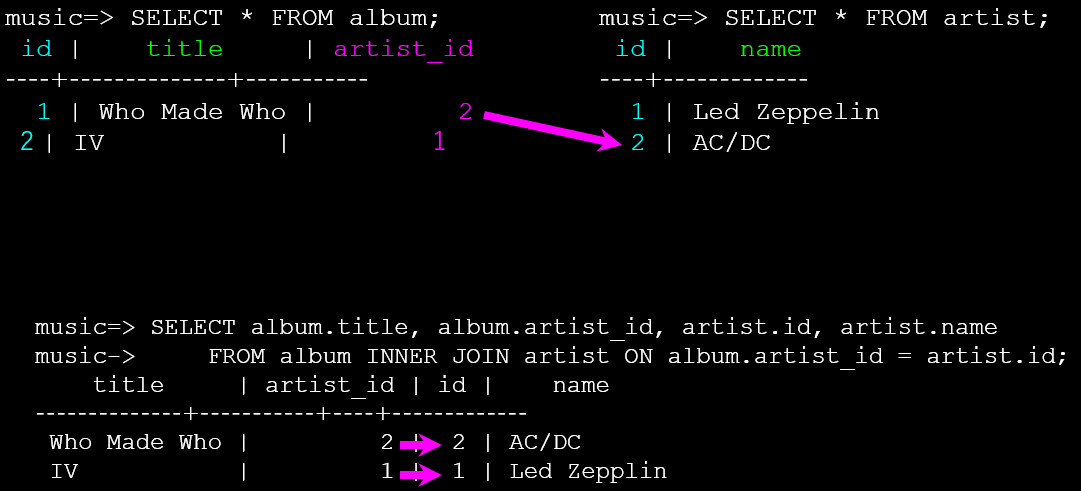
如果我们想要看到更多的信息,可以使用INNER JOIN进行连接。INNER JOIN 是一种用于从多个表中获取数据的SQL操作,它只返回那些在被连接的两个或多个表中都存在匹配记录的数据行。换句话说,只有当连接条件在所有参与的表中都能找到对应的数据时,才会返回结果。
SELECT album.title, album.artist_id, artist.id, artist.name
FROM album INNER JOIN artist ON album.artist_id = artist.id;
CROSS JOIN,也称为笛卡尔积(Cartesian Product),是SQL中一种用于连接两个或多个表的操作。与INNER JOIN、LEFT JOIN等不同的是,CROSS JOIN不基于任何关联条件来匹配行。相反,它将第一个表中的每一行与第二个表中的每一行进行组合,结果集的大小等于两个表行数的乘积。它与INNER JOIN正好相反,一个是全部匹配,另一个会仅仅选择显示符合ON子句条件的记录。
SELECT track.title, track.genre_id, genre.id, genre.name
FROM track CROSS JOIN genre;
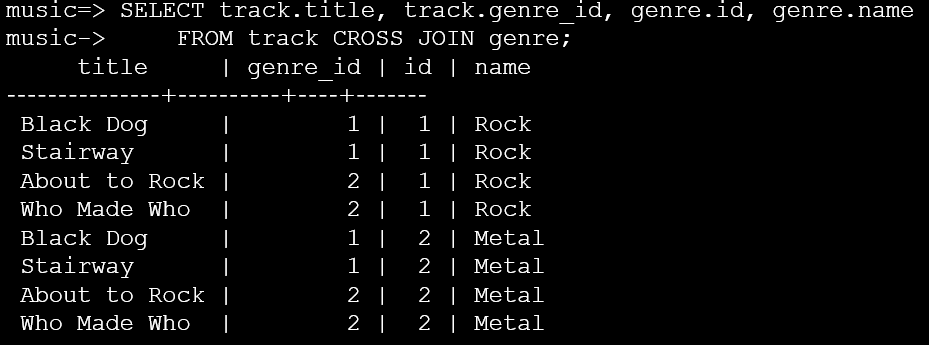
很多情况下,可能使用的就是普通的JOIN,这也是用户界面需要的。
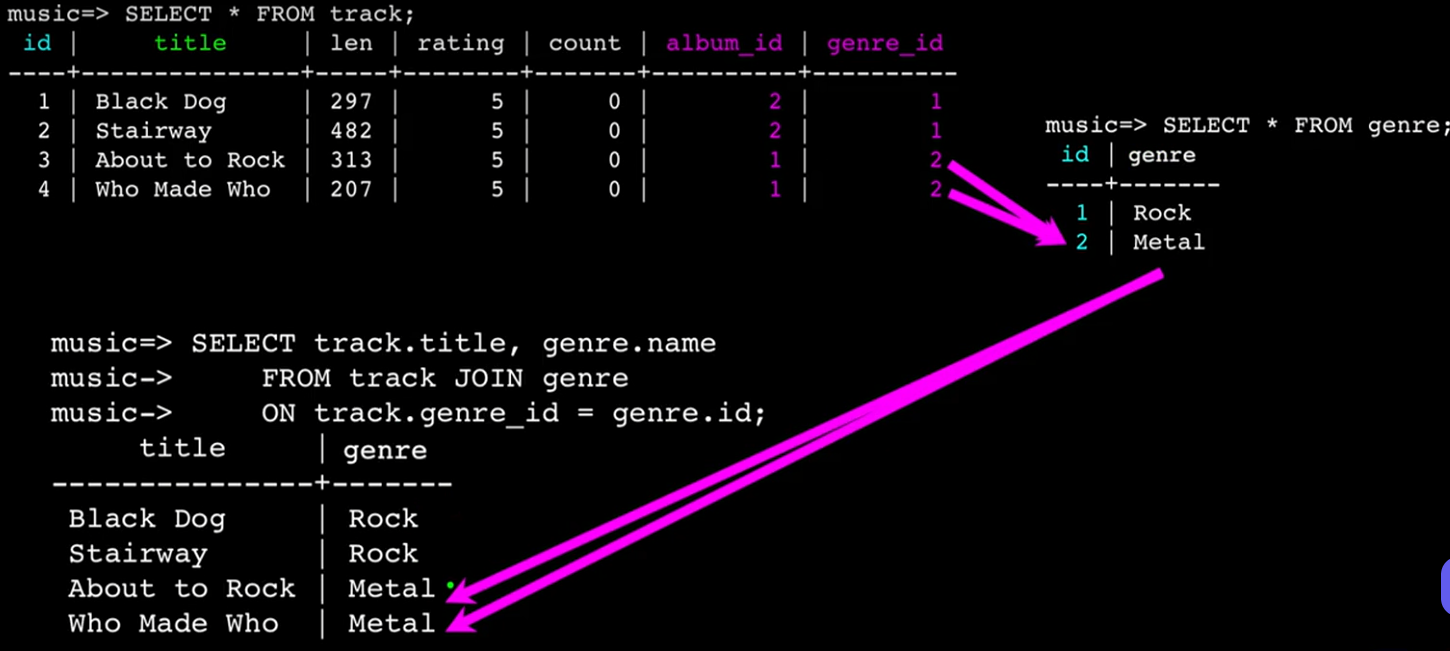
JOIN也可以更加复杂,如下所示:
music=> SELECT track.title, artist.name, album.title, genre.name
music-> FROM track
music-> JOIN genre ON track.genre_id = genre.id
music-> JOIN album ON track.album_id = album.id
music-> JOIN artist ON album.artist_id = artist.id;
title | name | title | genre
---------------+--------------+--------------+-------
Black Dog | Led Zeppelin | IV | Rock
Stairway | Led Zeppelin | IV | Rock
About to Rock | AC/DC | Who Made Who | Metal
Who Made Who | AC/DC | Who Made Who | Metal
在创建表的过程中,我们设置了级联删除 ON DELETE CASCADE,还可以设置其他的选择:Default或RESTRICT表示在我们尝试在父级进行删除操作时,由于有外键连接到了子表,因此这个删除操作将不被允许;SET NULL 将设置子表中的外键列值为null。这几个选项是我们在创建时必须考虑的事情。
2.3 多对多关系
现实世界中,更多存在的是多对多关系,所以多对多关系对于数据库很重要,但是这也较为难以理解,因为它不是那么简单直观。在先前的案例中,是一对多关系,如下所示:

一个简单的多对多关系如下所示,一个书可能多个作者,一个作者可能写了多个书,甚至更加复杂。
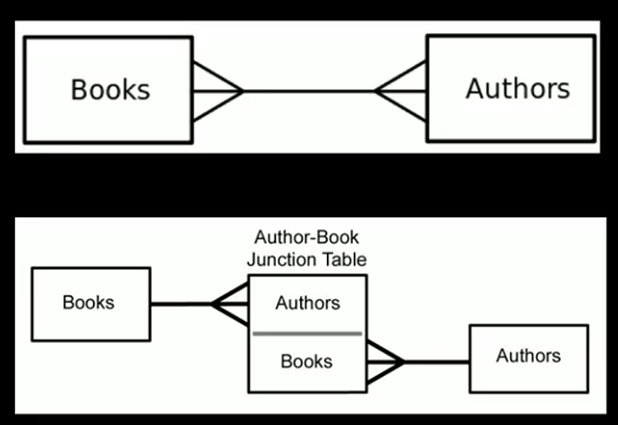
上图中,使用了一个中间连接表的方式实现了将多对多转为了一对多。还有一个常见的案例是课程与学生,学生选了多个课,每个课都有多个学生,所以在两者之间构建一个桥梁。
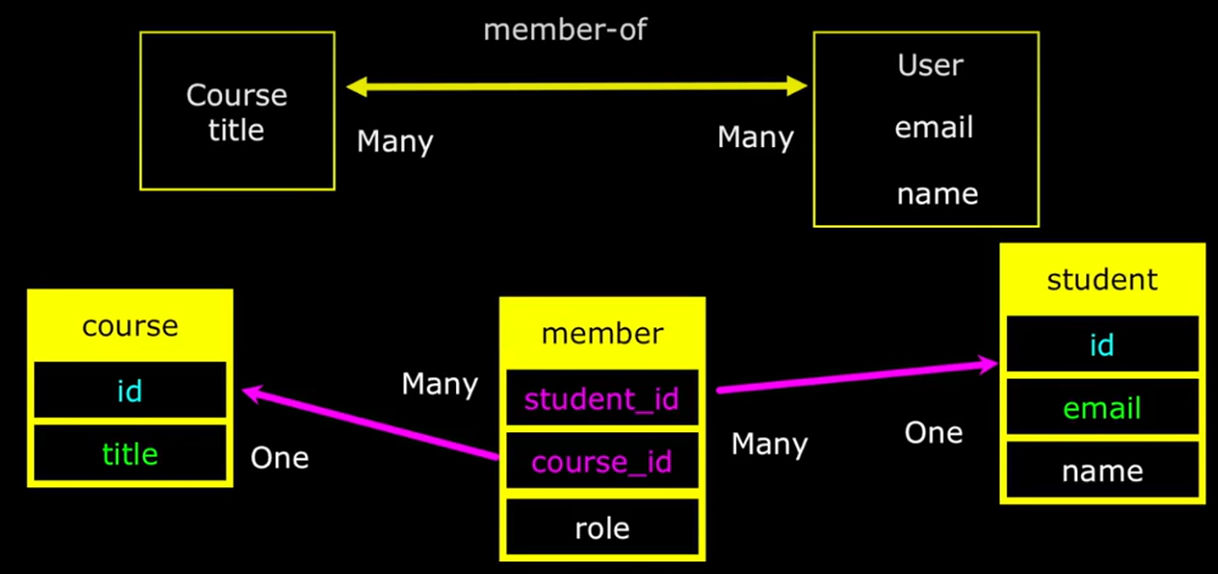
我们实际更多要对中间的桥梁进行操作,第一件事是首先构建课程和课程表,然后创建一个成员表,这个成员表就是桥梁。有趣的是,这个中间表的主键是通过外键引用的学生表和课程表,并且主键是两个的组合,而不是一个列。
CREATE TABLE student (
id SERIAL,
name VARCHAR(128),
email VARCHAR(128) UNIQUE,
PRIMARY KEY(id)
) ;
CREATE TABLE course (
id SERIAL,
title VARCHAR(128) UNIQUE,
PRIMARY KEY(id)
) ;
CREATE TABLE member (
student_id INTEGER REFERENCES student(id) ON DELETE CASCADE,
course_id INTEGER REFERENCES course(id) ON DELETE CASCADE,
role INTEGER,
PRIMARY KEY (student_id, course_id)
) ;
接下来就是需要插入数据,首先插入成员和课程数据。
music=> INSERT INTO student (name, email) VALUES ('Jane', 'jane@tsugi.org');
music=> INSERT INTO student (name, email) VALUES ('Ed', 'ed@tsugi.org');
music=> INSERT INTO student (name, email) VALUES ('Sue', 'sue@tsugi.org');
music=> SELECT * FROM student;
id | name | email
----+------+----------------
1 | Jane | jane@tsugi.org
2 | Ed | ed@tsugi.org
3 | Sue | sue@tsugi.org
music=> INSERT INTO course (title) VALUES ('Python');
music=> INSERT INTO course (title) VALUES ('SQL');
music=> INSERT INTO course (title) VALUES ('PHP');
music=> SELECT * FROM COURSE;
id | title
----+--------
1 | Python
2 | SQL
3 | PHP
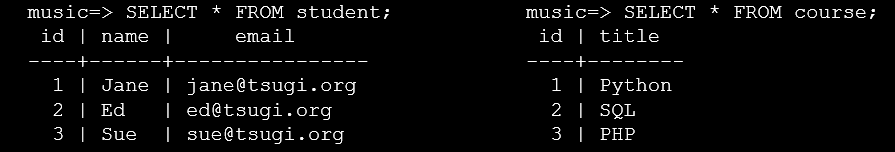
在为用户和课程插入数据后,就需要插入成员数据,这里使用了第三个参数role作为角色,这里是用1表示是老师,0表示学生,可能这个老师在这个课程是老师,在另一个课程是学生,所以关系会更加复杂。
INSERT INTO member (student_id, course_id, role) VALUES (1, 1, 1);
INSERT INTO member (student_id, course_id, role) VALUES (2, 1, 0);
INSERT INTO member (student_id, course_id, role) VALUES (3, 1, 0);
INSERT INTO member (student_id, course_id, role) VALUES (1, 2, 0);
INSERT INTO member (student_id, course_id, role) VALUES (2, 2, 1);
INSERT INTO member (student_id, course_id, role) VALUES (2, 3, 1);
INSERT INTO member (student_id, course_id, role) VALUES (3, 3, 0);
最终得到如下的结构:
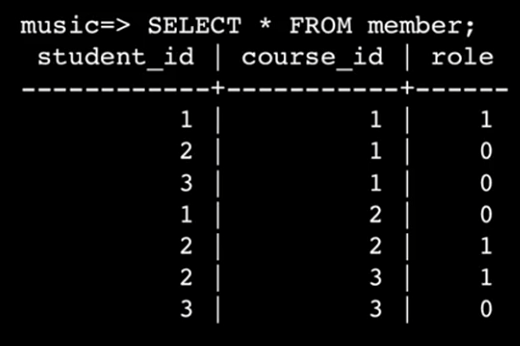
在实际使用中,我们还需要使用JOIN操作重建内容进行显示,因为这些ID代码太不直观了。这里使用了member.role DESC用来依据member.role进行降序排列,让老师显示在某个课程的最前面。
music=> SELECT student.name, member.role, course.title
music-> FROM student
music-> JOIN member ON member.student_id = student.id
music-> JOIN course ON member.course_id = course. id
music-> ORDER BY course.title, member.role DESC, student.name;
name | role | title
------+------+--------
Ed | 1 | PHP
Sue | 0 | PHP
Jane | 1 | Python
Ed | 0 | Python
Sue | 0 | Python
Ed | 1 | SQL
Jane | 0 | SQL
(7 rows)
上面仅仅是一个简单的示例,一个更加复杂真实的结构如下所示:
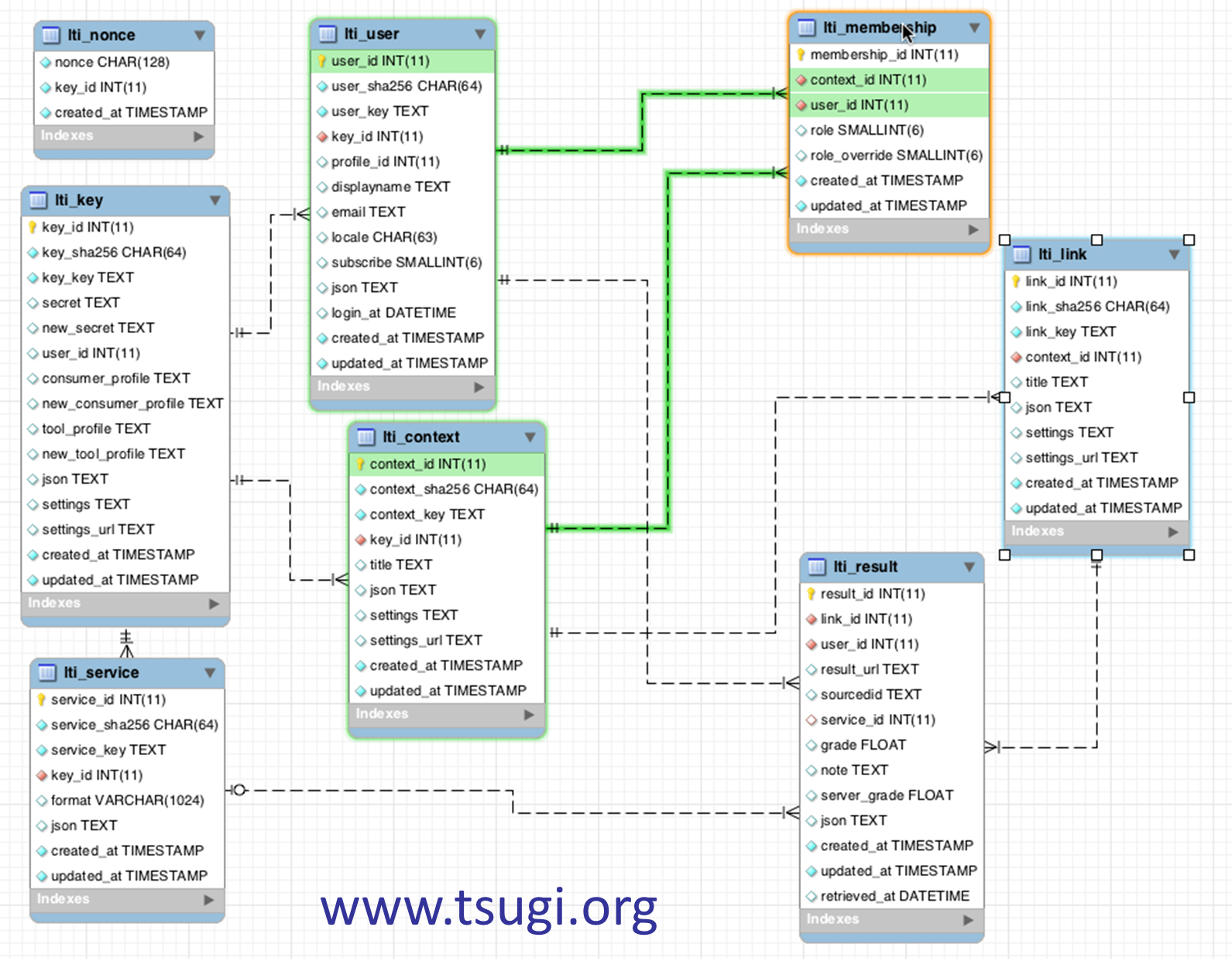
2.4 章节回顾
在了解了数据库设计与多对多关系后,需要进一步的操作练习。这一部分是对前面内容的总结与练习。代码如下:
CREATE DATABASE music WITH OWNER 'pg4e' ENCODING 'UTF8';
CREATE TABLE artist (
id SERIAL,
name VARCHAR(128) UNIQUE,
PRIMARY KEY(id)
);
CREATE TABLE album (
id SERIAL,
title VARCHAR(128) UNIQUE,
artist_id INTEGER REFERENCES artist(id) ON DELETE CASCADE,
PRIMARY KEY(id)
);
CREATE TABLE genre (
id SERIAL,
name VARCHAR(128) UNIQUE,
PRIMARY KEY(id)
);
CREATE TABLE track (
id SERIAL,
title VARCHAR(128),
len INTEGER, rating INTEGER, count INTEGER,
album_id INTEGER REFERENCES album(id) ON DELETE CASCADE,
genre_id INTEGER REFERENCES genre(id) ON DELETE CASCADE,
UNIQUE(title, album_id),
PRIMARY KEY(id)
);
INSERT INTO artist (name) VALUES ('Led Zeppelin');
INSERT INTO artist (name) VALUES ('AC/DC');
INSERT INTO album (title, artist_id) VALUES ('Who Made Who', 2);
INSERT INTO album (title, artist_id) VALUES ('IV', 1);
INSERT INTO genre (name) VALUES ('Rock');
INSERT INTO genre (name) VALUES ('Metal');
INSERT INTO track (title, rating, len, count, album_id, genre_id)
VALUES ('Black Dog', 5, 297, 0, 2, 1) ;
INSERT INTO track (title, rating, len, count, album_id, genre_id)
VALUES ('Stairway', 5, 482, 0, 2, 1) ;
INSERT INTO track (title, rating, len, count, album_id, genre_id)
VALUES ('About to Rock', 5, 313, 0, 1, 2) ;
INSERT INTO track (title, rating, len, count, album_id, genre_id)
VALUES ('Who Made Who', 5, 207, 0, 1, 2) ;
SELECT album.title, artist.name FROM album JOIN artist
ON album.artist_id = artist.id;
SELECT album.title, album.artist_id, artist.id, artist.name
FROM album INNER JOIN artist ON album.artist_id = artist.id;
SELECT track.title, track.genre_id, genre.id, genre.name
FROM track CROSS JOIN genre;
SELECT track.title, genre.name FROM track JOIN genre
ON track.genre_id = genre.id;
SELECT track.title, artist.name, album.title, genre.name
FROM track
JOIN genre ON track.genre_id = genre.id
JOIN album ON track.album_id = album.id
JOIN artist ON album.artist_id = artist.id;
DELETE FROM genre WHERE name='Metal';
多对多关系练习代码如下:
CREATE TABLE student (
id SERIAL,
name VARCHAR(128),
email VARCHAR(128) UNIQUE,
PRIMARY KEY(id)
) ;
CREATE TABLE course (
id SERIAL,
title VARCHAR(128) UNIQUE,
PRIMARY KEY(id)
) ;
-- We could put 'id SERIAL' in this table, but it is not essential
CREATE TABLE member (
student_id INTEGER REFERENCES student(id) ON DELETE CASCADE,
course_id INTEGER REFERENCES course(id) ON DELETE CASCADE,
role INTEGER,
PRIMARY KEY (student_id, course_id)
) ;
INSERT INTO student (name, email) VALUES ('Jane', 'jane@tsugi.org');
INSERT INTO student (name, email) VALUES ('Ed', 'ed@tsugi.org');
INSERT INTO student (name, email) VALUES ('Sue', 'sue@tsugi.org');
INSERT INTO course (title) VALUES ('Python');
INSERT INTO course (title) VALUES ('SQL');
INSERT INTO course (title) VALUES ('PHP');
INSERT INTO member (student_id, course_id, role) VALUES (1, 1, 1);
INSERT INTO member (student_id, course_id, role) VALUES (2, 1, 0);
INSERT INTO member (student_id, course_id, role) VALUES (3, 1, 0);
INSERT INTO member (student_id, course_id, role) VALUES (1, 2, 0);
INSERT INTO member (student_id, course_id, role) VALUES (2, 2, 1);
INSERT INTO member (student_id, course_id, role) VALUES (2, 3, 1);
INSERT INTO member (student_id, course_id, role) VALUES (3, 3, 0);
SELECT student.name, member.role, course.title
FROM student
JOIN member ON member.student_id = student.id
JOIN course ON member.course_id = course.id
ORDER BY course.title, member.role DESC, student.name;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









