







分布式事务框架seata
1.seata 简介
一、seata是什么
二、seata模块
三、seata四种模式
1、AT 模式
2、TCC 模式
3、Saga 模式
4、Seata XA 模式
一、seata是什么
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
二、seata模块
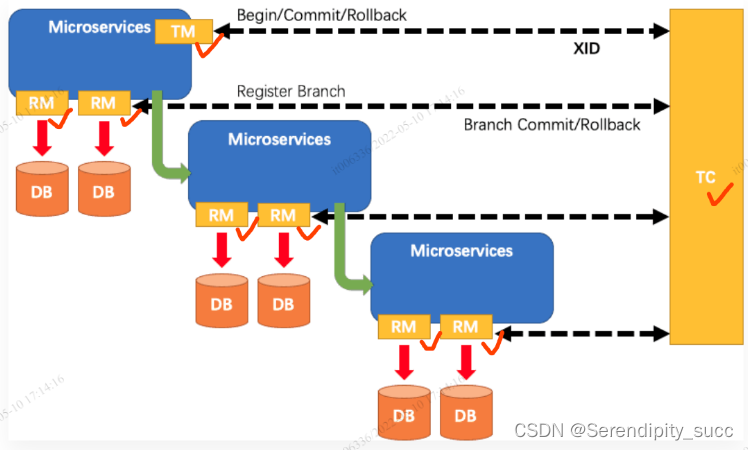
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
在 Seata 中,一个分布式事务的生命周期如下:
TM 请求 TC 开启一个全局事务。TC 会生成一个 XID 作为该全局事务的编号。
XID,会在微服务的调用链路中传播,保证将多个微服务的子事务关联在一起。
RM 请求 TC 将本地事务注册为全局事务的分支事务,通过全局事务的 XID 进行关联。
TM 请求 TC 告诉 XID 对应的全局事务是进行提交还是回滚。
TC 驱动 RM 们将 XID 对应的自己的本地事务进行提交还是回滚。
三、seata四种模式
1、AT 模式
基于 支持本地 ACID 事务 的 关系型数据库:
一阶段 prepare 行为:在本地事务中,一并提交业务数据更新和相应回滚日志记录。
二阶段 commit 行为:马上成功结束,自动 异步批量清理回滚日志。
二阶段 rollback 行为:通过回滚日志,自动 生成补偿操作,完成数据回滚。
2、TCC 模式
不依赖于底层数据资源的事务支持:
一阶段 prepare 行为:调用 自定义 的 prepare 逻辑。
二阶段 commit 行为:调用 自定义 的 commit 逻辑。
二阶段 rollback 行为:调用 自定义 的 rollback 逻辑。
所谓 TCC 模式,是指支持把 自定义 的分支事务纳入到全局事务的管理中。
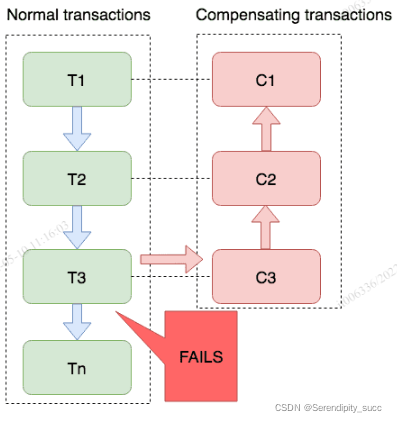
3、Saga 模式
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。
4、Seata XA 模式
支持XA协议 事务的数据库。Java 应用,通过 JDBC 访问数据库。
执行阶段(E xecute):XA start/XA end/XA prepare + SQL + 注册分支
完成阶段(F inish):XA commit/XA rollback
2.seata-saga模式
概述
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。
适用场景:
业务流程长、业务流程多
参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口
优势:
一阶段提交本地事务,无锁,高性能
事件驱动架构,参与者可异步执行,高吞吐
补偿服务易于实现
缺点:
不保证隔离性(应对方案见后面文档)
Saga的实现:
基于状态机引擎的 Saga 实现:
目前SEATA提供的Saga模式是基于状态机引擎来实现的,机制是:
1.通过状态图来定义服务调用的流程并生成 json 状态语言定义文件
2.状态图中一个节点可以是调用一个服务,节点可以配置它的补偿节点
3.状态图 json 由状态机引擎驱动执行,当出现异常时状态引擎反向执行已成功节点对应的补偿节点将事务回滚
注意: 异常发生时是否进行补偿也可由用户自定义决定
可以实现服务编排需求,支持单项选择、并发、子流程、参数转换、参数映射、服务执行状态判断、异常捕获等功能
示例状态图:

最佳实践
Saga 服务设计的实践经验
允许空补偿
- 空补偿:原服务未执行,补偿服务执行了
出现原因:
原服务 超时(丢包)
Saga 事务触发 回滚
未收到 原服务请求,先收到 补偿请求
所以服务设计时需要允许空补偿, 即没有找到要补偿的业务主键时返回补偿成功并将原业务主键记录下来
- 防悬挂控制
悬挂:补偿服务 比 原服务 先执行
出现原因:
原服务 超时(拥堵)
Saga 事务回滚,触发 回滚
拥堵的 原服务 到达
所以要检查当前业务主键是否已经在空补偿记录下来的业务主键中存在,如果存在则要拒绝服务的执行
- 幂等控制
原服务与补偿服务都需要保证幂等性, 由于网络可能超时, 可以设置重试策略,重试发生时要通过幂等控制避免业务数据重复更新
- 缺乏隔离性的应对
由于 Saga 事务不保证隔离性, 在极端情况下可能由于脏写无法完成回滚操作, 比如举一个极端的例子, 分布式事务内先给用户A充值, 然后给用户B扣减余额, 如果在给A用户充值成功, 在事务提交以前, A用户把余额消费掉了, 如果事务发生回滚, 这时则没有办法进行补偿了。这就是缺乏隔离性造成的典型的问题, 实践中一般的应对方法是:
1.业务流程设计时遵循“宁可长款, 不可短款”的原则, 长款意思是客户少了钱机构多了钱, 以机构信誉可以给客户退款, 反之则是短款, 少的钱可能追不回来了。所以在业务流程设计上一定是先扣款。
2.有些业务场景可以允许让业务最终成功, 在回滚不了的情况下可以继续重试完成后面的流程, 所以状态机引擎除了提供“回滚”能力还需要提供“向前”恢复上下文继续执行的能力, 让业务最终执行成功, 达到最终一致性的目的。
- 性能优化
配置客户端参数client.rm.report.success.enable=false,可以在当分支事务执行成功时不上报分支状态到server,从而提升性能。
当上一个分支事务的状态还没有上报的时候,下一个分支事务已注册,可以认为上一个实际已成功
API referance
StateMachineEngine API
public interface StateMachineEngine {
/** * start a state machine instance * @param stateMachineName * @param tenantId * @param startParams * @return * @throws EngineExecutionException */
StateMachineInstance start(String stateMachineName, String tenantId, Map<String, Object> startParams) throws EngineExecutionException;
/** * start a state machine instance with businessKey * @param stateMachineName * @param tenantId * @param businessKey * @param startParams * @return * @throws EngineExecutionException */
StateMachineInstance startWithBusinessKey(String stateMachineName, String tenantId, String businessKey, Map<String, Object> startParams) throws EngineExecutionException;
/** * start a state machine instance asynchronously * @param stateMachineName * @param tenantId * @param startParams * @param callback * @return * @throws EngineExecutionException */
StateMachineInstance startAsync(String stateMachineName, String tenantId, Map<String, Object> startParams, AsyncCallback callback) throws EngineExecutionException;
/** * start a state machine instance asynchronously with businessKey * @param stateMachineName * @param tenantId * @param businessKey * @param startParams * @param callback * @return * @throws EngineExecutionException */
StateMachineInstance startWithBusinessKeyAsync(String stateMachineName, String tenantId, String businessKey, Map<String, Object> startParams, AsyncCallback callback) throws EngineExecutionException;
/** * forward restart a failed state machine instance * @param stateMachineInstId * @param replaceParams * @return * @throws ForwardInvalidException */
StateMachineInstance forward(String stateMachineInstId, Map<String, Object> replaceParams) throws ForwardInvalidException;
/** * forward restart a failed state machine instance asynchronously * @param stateMachineInstId * @param replaceParams * @param callback * @return * @throws ForwardInvalidException */
StateMachineInstance forwardAsync(String stateMachineInstId, Map<String, Object> replaceParams, AsyncCallback callback) throws ForwardInvalidException;
/** * compensate a state machine instance * @param stateMachineInstId * @param replaceParams * @return * @throws EngineExecutionException */
StateMachineInstance compensate(String stateMachineInstId, Map<String, Object> replaceParams) throws EngineExecutionException;
/** * compensate a state machine instance asynchronously * @param stateMachineInstId * @param replaceParams * @param callback * @return * @throws EngineExecutionException */
StateMachineInstance compensateAsync(String stateMachineInstId, Map<String, Object> replaceParams, AsyncCallback callback) throws EngineExecutionException;
/** * skip current failed state instance and forward restart state machine instance * @param stateMachineInstId * @return * @throws EngineExecutionException */
StateMachineInstance skipAndForward(String stateMachineInstId) throws EngineExecutionException;
/** * skip current failed state instance and forward restart state machine instance asynchronously * @param stateMachineInstId * @param callback * @return * @throws EngineExecutionException */
StateMachineInstance skipAndForwardAsync(String stateMachineInstId, AsyncCallback callback) throws EngineExecutionException;
/** * get state machine configurations * @return */
StateMachineConfig getStateMachineConfig();
}
StateMachine Execution Instance API:
tateLogRepository stateLogRepository = stateMachineEngine.getStateMachineConfig().getStateLogRepository();
StateMachineInstance stateMachineInstance = stateLogRepository.getStateMachineInstanceByBusinessKey(businessKey, tenantId);
/** * State Log Repository * * @author lorne.cl */
public interface StateLogRepository {
/** * Get state machine instance * * @param stateMachineInstanceId * @return */
StateMachineInstance getStateMachineInstance(String stateMachineInstanceId);
/** * Get state machine instance by businessKey * * @param businessKey * @param tenantId * @return */
StateMachineInstance getStateMachineInstanceByBusinessKey(String businessKey, String tenantId);
/** * Query the list of state machine instances by parent id * * @param parentId * @return */
List<StateMachineInstance> queryStateMachineInstanceByParentId(String parentId);
/** * Get state instance * * @param stateInstanceId * @param machineInstId * @return */
StateInstance getStateInstance(String stateInstanceId, String machineInstId);
/** * Get a list of state instances by state machine instance id * * @param stateMachineInstanceId * @return */
List<StateInstance> queryStateInstanceListByMachineInstanceId(String stateMachineInstanceId);
}
StateMachine Definition API:
StateMachineRepository stateMachineRepository = stateMachineEngine.getStateMachineConfig().getStateMachineRepository();
StateMachine stateMachine = stateMachineRepository.getStateMachine(stateMachineName, tenantId);
/** * StateMachineRepository * * @author lorne.cl */
public interface StateMachineRepository {
/** * Gets get state machine by id. * * @param stateMachineId the state machine id * @return the get state machine by id */
StateMachine getStateMachineById(String stateMachineId);
/** * Gets get state machine. * * @param stateMachineName the state machine name * @param tenantId the tenant id * @return the get state machine */
StateMachine getStateMachine(String stateMachineName, String tenantId);
/** * Gets get state machine. * * @param stateMachineName the state machine name * @param tenantId the tenant id * @param version the version * @return the get state machine */
StateMachine getStateMachine(String stateMachineName, String tenantId, String version);
/** * Register the state machine to the repository (if the same version already exists, return the existing version) * * @param stateMachine */
StateMachine registryStateMachine(StateMachine stateMachine);
/** * registry by resources * * @param resources * @param tenantId */
void registryByResources(Resource[] resources, String tenantId) throws IOException;
}
参考,seata官网:http://seata.io/zh-cn/index.html
3.seata-saga快速上手
一、下载seata-server
二、配置seata-server
1、file.conf
2、registry.conf
3、数据库建表
三、client中的seata相关配置(springboot)
1、依赖
2、application.yml
3、状态机配置类
4、状态机json
5、建表
四、启动demo
一、下载seata-server
从 https://github.com/seata/seata/releases,下载服务器软件包,建议使用1.4.2以上
Usage: sh seata-server.sh(for linux and mac) or cmd seata-server.bat(for windows) [options]
Options:
--host, -h
The host to bind.
Default: 0.0.0.0
--port, -p
The port to listen.
Default: 8091
--storeMode, -m
log store mode : file、db
Default: file
--help
e.g.
sh seata-server.sh -p 8091 -h 127.0.0.1 -m file
二、配置seata-server
- 因为 TC (即seata-server)需要进行全局事务和分支事务的记录,所以需要对应的存储。目前有file、db、redis三种(后续将引入raft,mongodb)存储模式( store.mode ):
file 模式:适合单机模式,全局事务会话信息在内存中读写,并持久化本地文件 root.data,性能较高。
db 模式:适合集群模式,全局事务会话信息通过 db 共享,相对性能差点。
redis模式:Seata-Server 1.3及以上版本支持,性能较高,存在事务信息丢失风险,请提前配置合适当前场景的redis持久化配置.(1.3版本中不建议使用)
- 在seata-server中有两个需要配置的文件
- 1、file.conf
完整的file.conf请参考file.conf.example,如选择db模式,只需修改如下:
store {
## store mode: file、db、redis
mode = "db"
## database store property
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp)/HikariDataSource(hikari) etc.
datasource = "druid"
## mysql/oracle/postgresql/h2/oceanbase etc.
dbType = "oracle"
##driverClassName = "com.mysql.jdbc.Driver"
driverClassName = "oracle.jdbc.OracleDriver"
url = "jdbc:oracle:thin:@ip:port/IBANK"
user = "用户名"
password = "密码"
minConn = 5
maxConn = 30
globalTable = "global_table"
branchTable = "branch_table"
lockTable = "lock_table"
queryLimit = 100
maxWait = 5000
}
}
- 2、registry.conf
如果不使用注册中心,可以直接用file
registry {
type = "file"
file {
name = "file.conf"
}
}
config {
type = "file"
file {
name = "file.conf"
}
}
- 3、数据库建表
SEATA 服务器需要三张表 global_table,branch_table,lock_table
建表的sql脚本可以从源码的script中获取
-- -------------------------------- The script used when storeMode is 'db' --------------------------------
-- the table to store GlobalSession data
CREATE TABLE global_table
(
xid VARCHAR2(128) NOT NULL,
transaction_id NUMBER(19),
status NUMBER(3) NOT NULL,
application_id VARCHAR2(32),
transaction_service_group VARCHAR2(32),
transaction_name VARCHAR2(128),
timeout NUMBER(10),
begin_time NUMBER(19),
application_data VARCHAR2(2000),
gmt_create TIMESTAMP(0),
gmt_modified TIMESTAMP(0),
PRIMARY KEY (xid)
);
CREATE INDEX idx_gmt_modified_status ON global_table (gmt_modified, status);
CREATE INDEX idx_transaction_id ON global_table (transaction_id);
-- the table to store BranchSession data
CREATE TABLE branch_table
(
branch_id NUMBER(19) NOT NULL,
xid VARCHAR2(128) NOT NULL,
transaction_id NUMBER(19),
resource_group_id VARCHAR2(32),
resource_id VARCHAR2(256),
branch_type VARCHAR2(8),
status NUMBER(3),
client_id VARCHAR2(64),
application_data VARCHAR2(2000),
gmt_create TIMESTAMP(6),
gmt_modified TIMESTAMP(6),
PRIMARY KEY (branch_id)
);
CREATE INDEX idx_xid ON branch_table (xid);
-- the table to store lock data
CREATE TABLE lock_table
(
row_key VARCHAR2(128) NOT NULL,
xid VARCHAR2(96),
transaction_id NUMBER(19),
branch_id NUMBER(19) NOT NULL,
resource_id VARCHAR2(256),
table_name VARCHAR2(32),
pk VARCHAR2(36),
gmt_create TIMESTAMP(0),
gmt_modified TIMESTAMP(0),
PRIMARY KEY (row_key)
);
CREATE INDEX idx_branch_id ON lock_table (branch_id);
三、client中的seata相关配置(springboot)
1、依赖
注:要求springboot版本在2.2.0以上
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-seata</artifactId>
<version>2.2.0.RELEASE</version>
<exclusions>
<exclusion>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-spring-boot-starter</artifactId>
<version>1.2.0</version>
</dependency>
其他依赖如seata-all在需要的地方导入
oracle数据库的序列化由于Jackson版本问题,需要改成kryo
<dependency>
<groupId>com.esotericsoftware.kryo</groupId>
<artifactId>kryo</artifactId>
<version>2.24.0</version>
</dependency>
<dependency>
<groupId>com.esotericsoftware</groupId>
<artifactId>kryo</artifactId>
<version>4.0.2</version>
</dependency>
<dependency>
<groupId>de.javakaffee</groupId>
<artifactId>kryo-serializers</artifactId>
<version>0.42</version>
</dependency>
2、application.yml
seata:
enabled: true
application-id: ibanking-corporate
tx-service-group: ibanking # 事务群组(可以每个应用独立取名,也可以使用相同的名字)
enable-auto-data-source-proxy: false
use-jdk-proxy: false
client:
undo:
logSerialization: kryo
service:
vgroup-mapping:
seata_group: default # TC 集群(必须与seata-server保持一致) 此处的default必须能在grouplist下找到对应的key
grouplist:
default: seata服务所在虚拟机ip:8091
config:
type: file
registry:
type: file
注意:关闭seata自动代理,因为1.3版本seata的AT模式和SAGA模式有冲突,seata.undo.logSerialization: kryo
3、状态机配置类
@Slf4j
@Configuration
@Component
public class StateMachineEngineConfig {
@Resource(name = "appDataSource")
private DataSource dataSource;
@Bean("stateMachineEngine")
public ProcessCtrlStateMachineEngine getProcessCtrlStateMachineEngine(){
ProcessCtrlStateMachineEngine processCtrlStateMachineEngine = new ProcessCtrlStateMachineEngine();
processCtrlStateMachineEngine.setStateMachineConfig(getDbStateMachineConfig());
return processCtrlStateMachineEngine;
}
@Bean("dbStateMachineConfig")
public DbStateMachineConfig getDbStateMachineConfig(){
DbStateMachineConfig dbStateMachineConfig = new DbStateMachineConfig();
dbStateMachineConfig.setDataSource(dataSource);
dbStateMachineConfig.setTablePrefix("CMBIBANK.seata_");
// dbStateMachineConfig.setSagaBranchRegisterEnable(true);
// dbStateMachineConfig.setDbType("Oracle");
org.springframework.core.io.Resource[] resources = null;
try {
PathMatchingResourcePatternResolver pathMatchingResourcePatternResolver = new PathMatchingResourcePatternResolver();
resources = pathMatchingResourcePatternResolver.getResources("stateMachine/*.json");
}catch (IOException ioe){
log.error("load json file error the message = "+ioe.getMessage());
ioe.printStackTrace();
}
dbStateMachineConfig.setResources(resources);
dbStateMachineConfig.setEnableAsync(true);
dbStateMachineConfig.setThreadPoolExecutor(initThreadPoolExecutorFactoryBean());
// dbStateMachineConfig.setApplicationId("seata_ibank");
dbStateMachineConfig.setApplicationId("ibanking-corporate");
// dbStateMachineConfig.setTxServiceGroup("seata_group");
dbStateMachineConfig.setTxServiceGroup("ibanking");
return dbStateMachineConfig;
}
@Bean("threadExecutor")
public ThreadPoolExecutor initThreadPoolExecutorFactoryBean(){
ThreadPoolExecutorFactoryBean threadPoolExecutorFactoryBean = new ThreadPoolExecutorFactoryBean();
threadPoolExecutorFactoryBean.setThreadNamePrefix("SAGA_ASYNC_EXE_");
threadPoolExecutorFactoryBean.setCorePoolSize(1);
threadPoolExecutorFactoryBean.setMaxPoolSize(20);
return (ThreadPoolExecutor)threadPoolExecutorFactoryBean.getObject();
}
@Bean
public StateMachineEngineHolder initStateMachineEngineHolder(){
StateMachineEngineHolder stateMachineEngineHolder = new StateMachineEngineHolder();
stateMachineEngineHolder.setStateMachineEngine(getProcessCtrlStateMachineEngine());
return stateMachineEngineHolder;
}
}
4、状态机json
在resource下建一个文件夹stateMachine(自己命名,与配置类里面统一),放入状态机的json文件
5、建表
ORACLE:
CREATE TABLE seata_state_machine_def
(
id VARCHAR(32) NOT NULL,
name VARCHAR(128) NOT NULL,
tenant_id VARCHAR(32) NOT NULL,
app_name VARCHAR(32) NOT NULL,
type VARCHAR(20),
comment_ VARCHAR(255),
ver VARCHAR(16) NOT NULL,
gmt_create TIMESTAMP(3) NOT NULL,
status VARCHAR(2) NOT NULL,
content CLOB,
recover_strategy VARCHAR(16),
PRIMARY KEY (id)
);
CREATE TABLE seata_state_machine_inst
(
id VARCHAR(128) NOT NULL,
machine_id VARCHAR(32) NOT NULL,
tenant_id VARCHAR(32) NOT NULL,
parent_id VARCHAR(128),
gmt_started TIMESTAMP(3) NOT NULL,
business_key VARCHAR(48),
uni_business_key VARCHAR(128) GENERATED ALWAYS AS (
CASE
WHEN "BUSINESS_KEY" IS NULL
THEN "ID"
ELSE "BUSINESS_KEY"
END),
start_params CLOB,
gmt_end TIMESTAMP(3),
excep BLOB,
end_params CLOB,
status VARCHAR(2),
compensation_status VARCHAR(2),
is_running SMALLINT,
gmt_updated TIMESTAMP(3) NOT NULL,
PRIMARY KEY (id)
);
CREATE UNIQUE INDEX state_machine_inst_unibuzkey ON seata_state_machine_inst (uni_business_key, tenant_id);
CREATE TABLE seata_state_inst
(
id VARCHAR(48) NOT NULL,
machine_inst_id VARCHAR(46) NOT NULL,
name VARCHAR(128) NOT NULL,
type VARCHAR(20),
service_name VARCHAR(128),
service_method VARCHAR(128),
service_type VARCHAR(16),
business_key VARCHAR(48),
state_id_compensated_for VARCHAR(50),
state_id_retried_for VARCHAR(50),
gmt_started TIMESTAMP(3) NOT NULL,
is_for_update SMALLINT,
input_params CLOB,
output_params CLOB,
status VARCHAR(2) NOT NULL,
excep BLOB,
gmt_updated TIMESTAMP(3),
gmt_end TIMESTAMP(3),
PRIMARY KEY (id, machine_inst_id)
);
MYSQL:
-- -------------------------------- The script used for sage --------------------------------
CREATE TABLE IF NOT EXISTS `seata_state_machine_def`
(
`id` VARCHAR(32) NOT NULL COMMENT 'id',
`name` VARCHAR(128) NOT NULL COMMENT 'name',
`tenant_id` VARCHAR(32) NOT NULL COMMENT 'tenant id',
`app_name` VARCHAR(32) NOT NULL COMMENT 'application name',
`type` VARCHAR(20) COMMENT 'state language type',
`comment_` VARCHAR(255) COMMENT 'comment',
`ver` VARCHAR(16) NOT NULL COMMENT 'version',
`gmt_create` DATETIME(3) NOT NULL COMMENT 'create time',
`status` VARCHAR(2) NOT NULL COMMENT 'status(AC:active|IN:inactive)',
`content` TEXT COMMENT 'content',
`recover_strategy` VARCHAR(16) COMMENT 'transaction recover strategy(compensate|retry)',
PRIMARY KEY (`id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
CREATE TABLE IF NOT EXISTS `seata_state_machine_inst`
(
`id` VARCHAR(128) NOT NULL COMMENT 'id',
`machine_id` VARCHAR(32) NOT NULL COMMENT 'state machine definition id',
`tenant_id` VARCHAR(32) NOT NULL COMMENT 'tenant id',
`parent_id` VARCHAR(128) COMMENT 'parent id',
`gmt_started` DATETIME(3) NOT NULL COMMENT 'start time',
`business_key` VARCHAR(48) COMMENT 'business key',
`start_params` TEXT COMMENT 'start parameters',
`gmt_end` DATETIME(3) COMMENT 'end time',
`excep` BLOB COMMENT 'exception',
`end_params` TEXT COMMENT 'end parameters',
`status` VARCHAR(2) COMMENT 'status(SU succeed|FA failed|UN unknown|SK skipped|RU running)',
`compensation_status` VARCHAR(2) COMMENT 'compensation status(SU succeed|FA failed|UN unknown|SK skipped|RU running)',
`is_running` TINYINT(1) COMMENT 'is running(0 no|1 yes)',
`gmt_updated` DATETIME(3) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `unikey_buz_tenant` (`business_key`, `tenant_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
CREATE TABLE IF NOT EXISTS `seata_state_inst`
(
`id` VARCHAR(48) NOT NULL COMMENT 'id',
`machine_inst_id` VARCHAR(128) NOT NULL COMMENT 'state machine instance id',
`name` VARCHAR(128) NOT NULL COMMENT 'state name',
`type` VARCHAR(20) COMMENT 'state type',
`service_name` VARCHAR(128) COMMENT 'service name',
`service_method` VARCHAR(128) COMMENT 'method name',
`service_type` VARCHAR(16) COMMENT 'service type',
`business_key` VARCHAR(48) COMMENT 'business key',
`state_id_compensated_for` VARCHAR(50) COMMENT 'state compensated for',
`state_id_retried_for` VARCHAR(50) COMMENT 'state retried for',
`gmt_started` DATETIME(3) NOT NULL COMMENT 'start time',
`is_for_update` TINYINT(1) COMMENT 'is service for update',
`input_params` TEXT COMMENT 'input parameters',
`output_params` TEXT COMMENT 'output parameters',
`status` VARCHAR(2) NOT NULL COMMENT 'status(SU succeed|FA failed|UN unknown|SK skipped|RU running)',
`excep` BLOB COMMENT 'exception',
`gmt_updated` DATETIME(3) COMMENT 'update time',
`gmt_end` DATETIME(3) COMMENT 'end time',
PRIMARY KEY (`id`, `machine_inst_id`)
) ENGINE = InnoDB
DEFAULT CHARSET = utf8;
四、启动demo
可以去官方的示例仓库:https://github.com/seata/seata-samples下载demo,也可以自己改造,需要将完整的事务流程写成一个状态机json
获得状态机实例,可以从状态机上下文获取状态机执行过程中的参数:
StateMachineInstance inst = stateMachineEngine.start("stateMachineNmae", null, startParams);
ret =inst.getContext().get("ret");
状态机上下文是一个Map,其K-V对包括初始参数startParams以及每个状态的output
通过 ExecutionStatus.SU.equals(inst.getStatus() 可以判断事务是否执行成功
4、Seata-Saga状态机详解
一、“状态机” 属性简介:
二、“状态” 属性简介:
三、"状态机"的属性列表
四、"状态"的属性列表
- ServiceTask:
- Choice:
- Succeed:
- Fail:
- CompensationTrigger:
- SubStateMachine:
- CompensateSubMachine:
五、负责参数的定义
一、“状态机” 属性简介:
Name: 表示状态机的名称,必须唯一
Comment: 状态机的描述
Version: 状态机定义版本
StartState: 启动时运行的第一个"状态"
States: 状态列表,是一个map结构,key是"状态"的名称,在状态机内必须唯一
二、“状态” 属性简介:
Type: “状态” 的类型,比如有:
ServiceTask: 执行调用服务任务
Choice: 单条件选择路由
CompensationTrigger: 触发补偿流程
Succeed: 状态机正常结束
Fail: 状态机异常结束
SubStateMachine: 调用子状态机
CompensateSubMachine: 用于补偿一个子状态机
ServiceName: 服务名称,通常是服务的beanId
ServiceMethod: 服务方法名称
CompensateState: 该"状态"的补偿"状态"
Input: 调用服务的输入参数列表, 是一个数组, 对应于服务方法的参数列表,
.
表
示
使
用
表
达
式
从
状
态
机
上
下
文
中
取
参
数
,
表
达
使
用
的
S
p
r
i
n
g
E
L
,
如
果
是
常
量
直
接
写
值
即
可
O
u
p
u
t
:
将
服
务
返
回
的
参
数
赋
值
到
状
态
机
上
下
文
中
,
是
一
个
m
a
p
结
构
,
k
e
y
为
放
入
到
状
态
机
上
文
时
的
k
e
y
(
状
态
机
上
下
文
也
是
一
个
m
a
p
)
,
v
a
l
u
e
中
.表示使用表达式从状态机上下文中取参数,表达使用的SpringEL, 如果是常量直接写值即可 Ouput: 将服务返回的参数赋值到状态机上下文中, 是一个map结构,key为放入到状态机上文时的key(状态机上下文也是一个map),value中
.表示使用表达式从状态机上下文中取参数,表达使用的SpringEL,如果是常量直接写值即可Ouput:将服务返回的参数赋值到状态机上下文中,是一个map结构,key为放入到状态机上文时的key(状态机上下文也是一个map),value中.是表示SpringEL表达式,表示从服务的返回参数中取值,#root表示服务的整个返回参数
Status: 服务执行状态映射,框架定义了三个状态,SU 成功、FA 失败、UN 未知, 我们需要把服务执行的状态映射成这三个状态,帮助框架判断整个事务的一致性,是一个map结构,key是条件表达式,一般是取服务的返回值或抛出的异常进行判断,默认是SpringEL表达式判断服务返回参数,带$Exception{开头表示判断异常类型。value是当这个条件表达式成立时则将服务执行状态映射成这个值
Catch: 捕获到异常后的路由
Next: 服务执行完成后下一个执行的"状态"
Choices: Choice类型的"状态"里, 可选的分支列表, 分支中的Expression为SpringEL表达式, Next为当表达式成立时执行的下一个"状态"
ErrorCode: Fail类型"状态"的错误码
Message: Fail类型"状态"的错误信息
三、"状态机"的属性列表
{
"Name": "reduceInventoryAndBalance",
"Comment": "reduce inventory then reduce balance in a transaction",
"StartState": "ReduceInventory",
"Version": "0.0.1",
"States": {
}
}
- Name: 表示状态机的名称,必须唯一
- Comment: 状态机的描述
- Version: 状态机定义版本
- StartState: 启动时运行的第一个"状态"
- States: 状态列表,是一个map结构,key是"状态"的名称,在状态机内必须唯一, value是一个map结构表示"状态"的属性列表
四、"状态"的属性列表
- ServiceTask:
"States": {
...
"ReduceBalance": {
"Type": "ServiceTask",
"ServiceName": "balanceAction",
"ServiceMethod": "reduce",
"CompensateState": "CompensateReduceBalance",
"IsForUpdate": true,
"IsPersist": true,
"IsAsync": false,
"Input": [
"$.[businessKey]",
"$.[amount]",
{
"throwException" : "$.[mockReduceBalanceFail]"
}
],
"Output": {
"compensateReduceBalanceResult": "$.#root"
},
"Status": {
"#root == true": "SU",
"#root == false": "FA",
"$Exception{java.lang.Throwable}": "UN"
},
"Retry": [
{
"Exceptions": ["io.seata.saga.engine.mock.DemoException"],
"IntervalSeconds": 1.5,
"MaxAttempts": 3,
"BackoffRate": 1.5
},
{
"IntervalSeconds": 1,
"MaxAttempts": 3,
"BackoffRate": 1.5
}
],
"Catch": [
{
"Exceptions": [
"java.lang.Throwable"
],
"Next": "CompensationTrigger"
}
],
"Next": "Succeed"
}
...
}
- ServiceName: 服务名称,通常是服务的beanId
- ServiceMethod: 服务方法名称
- CompensateState: 该"状态"的补偿"状态"
- IsForUpdate: 标识该服务会更新数据, 默认是false, 如果配置了CompensateState则默认是true, 有补偿服务的服务肯定是数据更新类服务
- IsPersist: 执行日志是否进行存储, 默认是true, 有一些查询类的服务可以配置为false, 执行日志不进行存储提高性能, 因为当异常恢复时可以重复执行
- IsAsync: 异步调用服务, 注意: 因为异步调用服务会忽略服务的返回结果, 所以用户定义的服务执行状态映射(下面的Status属性)将被忽略, 默认为服务调用成功, 如果提交异步调用就失败(比如线程池已满)则为服务执行状态为失败
- Input: 调用服务的输入参数列表, 是一个数组, 对应于服务方法的参数列表, $.表示使用表达式从状态机上下文中取参数,表达使用的SpringEL, 如果是常量直接写值即可。复杂的参数如何传入见:复杂参数的Input定义
- Output: 将服务返回的参数赋值到状态机上下文中, 是一个map结构,key为放入到状态机上文时的key(状态机上下文也是一个map),value中$.是表示SpringEL表达式,表示从服务的返回参数中取值,#root表示服务的整个返回参数
- Status: 服务执行状态映射,框架定义了三个状态,SU 成功、FA 失败、UN 未知, 我们需要把服务执行的状态映射成这三个状态,帮助框架判断整个事务的一致性,是一个map结构,key是条件表达式,一般是取服务的返回值或抛出的异常进行判断,默认是SpringEL表达式判断服务返回参数,带$Exception{开头表示判断异常类型。value是当这个条件表达式成立时则将服务执行状态映射成这个值
- Catch: 捕获到异常后的路由
- Retry: 捕获异常后的重试策略, 是个数组可以配置多个规则, Exceptions 为匹配的的异常列表, * IntervalSeconds 为重试间隔, MaxAttempts 为最大重试次数, BackoffRate 下一次重试间隔相对于上一次重试间隔的倍数,比如说上次一重试间隔是2秒, BackoffRate=1.5 则下一次重试间隔是3秒。Exceptions 属性可以不配置, 不配置时表示框架自动匹配网络超时异常。当在重试过程中发生了别的异常,框架会重新匹配规则,并按新规则进行重试,同一种规则的总重试次数不会超过该规则的MaxAttempts
- Next: 服务执行完成后下一个执行的"状态"
当没有配置Status对服务执行状态进行映射, 系统会自动判断状态:
没有异常则认为执行成功,
如果有异常, 则判断异常是不是网路连接超时, 如果是则认为是FA
如果是其它异常, 服务IsForUpdate=true则状态为UN, 否则为FA
整个状态机的执行状态如何判断?是由框架自己判断的, 状态机有两个状态: status(正向执行状态), compensateStatus(补偿状态):
如果所有服务执行成功(事务提交成功)则status=SU, compensateStatus=null
如果有服务执行失败且存在更新类服务执行成功且没有进行补偿(事务提交失败) 则status=UN, compensateStatus=null
如果有服务执行失败且不存在更新类服务执行成功且没有进行补偿(事务提交失败) 则status=FA, compensateStatus=null
如果补偿成功(事务回滚成功)则status=FA/UN, compensateStatus=SU
发生补偿且有未补偿成功的服务(回滚失败)则status=FA/UN, compensateStatus=UN
存在事务提交或回滚失败的情况Seata Sever都会不断发起重试
- Choice:
"ChoiceState":{
"Type": "Choice",
"Choices":[
{
"Expression":"[reduceInventoryResult] == true",
"Next":"ReduceBalance"
}
],
"Default":"Fail"
}
Choice类型的"状态"是单项选择路由 Choices: 可选的分支列表, 只会选择第一个条件成立的分支 Expression: SpringEL表达式 Next: 当Expression表达式成立时执行的下一个"状态"
- Succeed:
"Succeed": {
"Type":"Succeed"
}
运行到"Succeed状态"表示状态机正常结束, 正常结束不代表成功结束, 是否成功要看每个"状态"是否都成功
- Fail:
"Fail": {
"Type":"Fail",
"ErrorCode": "PURCHASE_FAILED",
"Message": "purchase failed"
}
运行到"Fail状态"状态机异常结束, 异常结束时可以配置ErrorCode和Message, 表示错误码和错误信息, 可以用于给调用方返回错误码和消息
- CompensationTrigger:
"CompensationTrigger": {
"Type": "CompensationTrigger",
"Next": "Fail"
}
CompensationTrigger类型的state是用于触发补偿事件, 回滚分布式事务 Next: 补偿成功后路由到的state
- SubStateMachine:
"CallSubStateMachine": {
"Type": "SubStateMachine",
"StateMachineName": "simpleCompensationStateMachine",
"CompensateState": "CompensateSubMachine",
"Input": [
{
"a": "$.1",
"barThrowException": "$.[barThrowException]",
"fooThrowException": "$.[fooThrowException]",
"compensateFooThrowException": "$.[compensateFooThrowException]"
}
],
"Output": {
"fooResult": "$.#root"
},
"Next": "Succeed"
}
SubStateMachine类型的"状态"是调用子状态机 StateMachineName: 要调用的子状态机名称 CompensateState: 子状态机的补偿state, 可以不配置, 系统会自动创建它的补偿state, 子状态机的补偿实际就是调用子状态机的compensate方法, 所以用户并不需要自己实现一个对子状态机的补偿服务。当配置这个属性时, 可以里利用Input属性自定义传入一些变量, 见下面的CompensateSubMachine
- CompensateSubMachine:
"CompensateSubMachine": {
"Type": "CompensateSubMachine",
"Input": [
{
"compensateFooThrowException": "$.[compensateFooThrowException]"
}
]
}
CompensateSubMachine类型的state是专门用于补偿一个子状态机的state,它会调用子状态机的compensate方法,可以利用Input属性传入一些自定义的变量, Status属性自定判断补偿是否成功
五、负责参数的定义
"FirstState": {
"Type": "ServiceTask",
"ServiceName": "demoService",
"ServiceMethod": "complexParameterMethod",
"Next": "ChoiceState",
"ParameterTypes" : ["java.lang.String", "int", "io.seata.saga.engine.mock.DemoService$People", "[Lio.seata.saga.engine.mock.DemoService$People;", "java.util.List", "java.util.Map"],
"Input": [
"$.[people].name",
"$.[people].age",
{
"name": "$.[people].name",
"age": "$.[people].age",
"childrenArray": [
{
"name": "$.[people].name",
"age": "$.[people].age"
},
{
"name": "$.[people].name",
"age": "$.[people].age"
}
],
"childrenList": [
{
"name": "$.[people].name",
"age": "$.[people].age"
},
{
"name": "$.[people].name",
"age": "$.[people].age"
}
],
"childrenMap": {
"lilei": {
"name": "$.[people].name",
"age": "$.[people].age"
}
}
},
[
{
"name": "$.[people].name",
"age": "$.[people].age"
},
{
"name": "$.[people].name",
"age": "$.[people].age"
}
],
[
{
"@type": "io.seata.saga.engine.mock.DemoService$People",
"name": "$.[people].name",
"age": "$.[people].age"
}
],
{
"lilei": {
"@type": "io.seata.saga.engine.mock.DemoService$People",
"name": "$.[people].name",
"age": "$.[people].age"
}
}
],
"Output": {
"complexParameterMethodResult": "$.#root"
}
}
实例演示:
{
"Name": "TRANS_INPUT",
"Comment": "trans input transaction",
"StartState": "basicStateInput",
"Version": "0.0.1",
"States": {
"basicStateInput": {
"Type": "ServiceTask",
"ServiceName": "transFactory",
"ServiceMethod": "inputBusinessProcess",
"CompensateState": "inputBusinessProcessCompensation",
"Next": "inputSaveDB",
"Input": [
"$.[obj]"
],
"Output": {
"ret": "$.#root"
},
"Catch": [
{
"Exceptions": [
"java.lang.Throwable"
],
"Next": "CompensationTrigger"
}
]
},
"inputSaveDB": {
"Type": "ServiceTask",
"ServiceName": "transFactory",
"ServiceMethod": "inputSaveTrans",
"CompensateState": "inputSaveTransCompensation",
"Next": "inputExtend",
"Input": [
"$.[obj]"
],
"Catch": [
{
"Exceptions": [
"java.lang.Throwable"
],
"Next": "CompensationTrigger"
}
]
},
"inputExtend": {
"Type": "ServiceTask",
"ServiceName": "transFactory",
"ServiceMethod": "inputExtend",
"CompensateState": "inputExtendCompensation",
"Next": "Succeed",
"Input": [
"$.[obj]"
],
"Output": {
"extendRet": "$.#root"
},
"Catch": [
{
"Exceptions": [
"java.lang.Throwable"
],
"Next": "CompensationTrigger"
}
]
},
"inputBusinessProcessCompensation": {
"Type": "ServiceTask",
"ServiceName": "transFactory",
"ServiceMethod": "inputBusinessProcessCompensation",
"Input": [
"$.[obj]"
]
},
"inputSaveTransCompensation": {
"Type": "ServiceTask",
"ServiceName": "transFactory",
"ServiceMethod": "inputSaveTransCompensation",
"Input": [
"$.[obj]"
]
},
"inputExtendCompensation": {
"Type": "ServiceTask",
"ServiceName": "transFactory",
"ServiceMethod": "inputExtendCompensation",
"Input": [
"$.[obj]"
]
},
"CompensationTrigger": {
"Type": "CompensationTrigger",
"Next": "Fail"
},
"Succeed": {
"Type": "Succeed"
},
"Fail": {
"Type": "Fail",
"ErrorCode": "TRANS_INPUT_FAILED",
"Message": "TRANS_INPUT_FAILED"
}
}
}














 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









