






1.MATLAB程序实现
代码如下:
%% 清空环境变量
clear;
clc;
close all;
%% 初始化参数
data = rand(400, 2);
figure;
plot(data(:, 1), data(:, 2), 'ro', 'MarkerSize', 8);
xlabel '横坐标X'; ylabel '纵坐标';
title '样本数据';
K = 4; % 分类个数
maxgen = 100; % 最大迭代次数
alpha = 3; % 指数的次幂
threshold = 1e-6; % 阈值
[data_n, in_n] = size(data); % 行数,即样本个数/列数,即样本维数
% 初始化隶属度矩阵
U = rand(K, data_n);
col_sum = sum(U);
U = U./col_sum(ones(K, 1), :);
%% 迭代
for i = 1:maxgen
% 更新聚类中心
mf = U.^alpha;
center = mf*data./((ones(in_n, 1)*sum(mf'))');
% 更新目标函数值
dist = zeros(size(center, 1), data_n);
for k = 1:size(center, 1)
dist(k, :) = sqrt(sum(((data-ones(data_n, 1)*center(k, :)).^2)', 1));
end
J(i) = sum(sum((dist.^2).*mf));
% 更新隶属度矩阵
tmp = dist.^(-2/(alpha-1));
U = tmp./(ones(K, 1)*sum(tmp));
% 终止条件判断
if i > 1
if abs(J(i) - J(i-1)) < threshold
break;
end
end
end
%% 绘图
[max_vluae, index] = max(U);
index = index';
figure;
for i = 1:K
col = find(index == i); % max(U)返回隶属度列最大值所在行一致的分为一类
plot(data(col, 1), data(col, 2), '*', 'MarkerSize', 8);
hold on
end
grid on
% 画出聚类中心
plot(center(:, 1), center(:, 2), 'p', 'color', 'm', 'MarkerSize', 12);
xlabel '横坐标X'; ylabel '纵坐标Y';
title 'FCM优化后的聚类图';
% 目标函数变化过程
figure;
plot(J, 'r', 'linewidth', 2);
xlabel '迭代次数'; ylabel '目标函数值';
title 'FCM聚类目标函数变化过程';
grid on
FCM优化后的聚类图如图所示
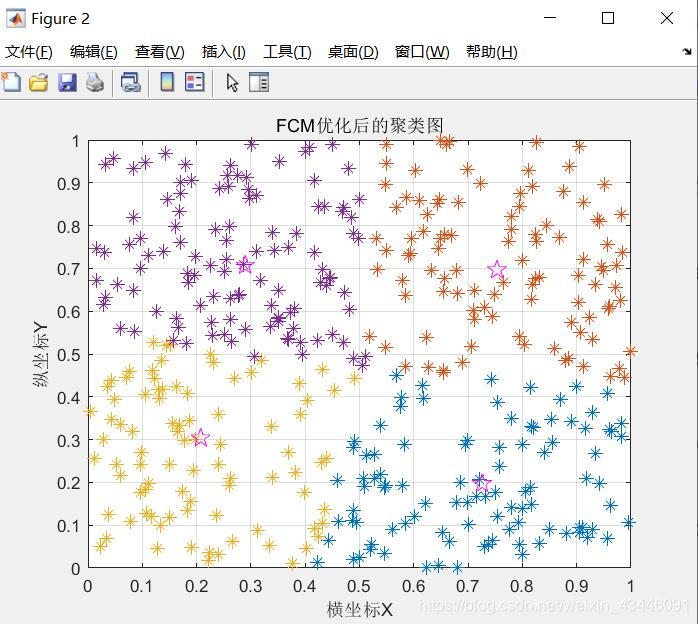 成功聚类
成功聚类
FCM聚类目标函数值变化过程如图所示
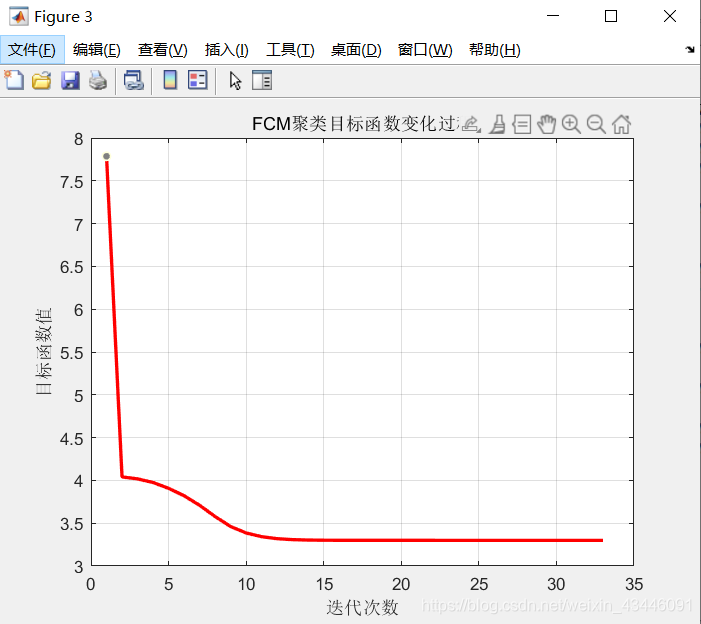
2.基于fcm的图像分割
一个小例子
代码如下:
clc
clear
close all
img = double(imread('lena.jpg'));
subplot(1,2,1),imshow(img,[]);
data = img(:);
%分成4类
[center,U,obj_fcn] = fcm(data,4);
[~,label] = max(U); %找到所属的类
%变化到图像的大小
img_new = reshape(label,size(img));
subplot(1,2,2),imshow(img_new,[]);
需要自己下载图片转到MATLAB目录下
FCM算法
数据来源网址
http://archive.ics.uci.edu/ml/datasets/seeds#
这个数据库是关于种子分类的,里面共包含3类种子,采集他们的特征,每个种子共有7个特征值来表示它(也就是说在数据里面相当于7维),每类种子又有70个样本,那么整个数据集就是210*7的样本集。从上面那个地方下载完样本集存为txt文件,并放到matlab工作目录下
代码如下:
clc
clear
close all
data = importdata('data.txt');
%data中还有第8列,正确的标签列
subplot(2,2,1);
gscatter(data(:,1),data(:,6),data(:,8)),title('choose:1,6 列')
subplot(2,2,2);
gscatter(data(:,2),data(:,4),data(:,8)),title('choose:2,4 列')
subplot(2,2,3);
gscatter(data(:,3),data(:,5),data(:,8)),title('choose:3,5 列')
subplot(2,2,4);
gscatter(data(:,4),data(:,7),data(:,8)),title('choose:4,7 列')
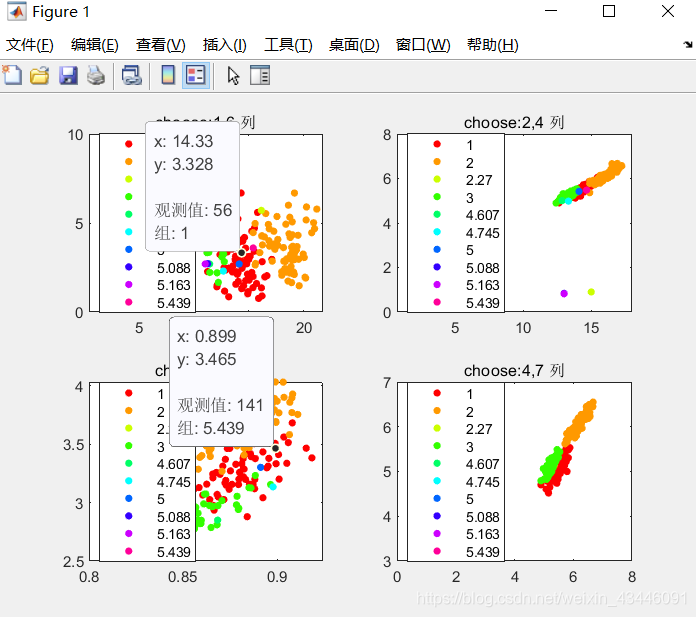
clc
clear
close all
data = importdata('seeds_dataset.txt');
%data中还有第8列,正确的标签列
[center,U,obj_fcn] = fcm(data(:,1:7),3);
[~,label] = max(U); %找到所属的类
subplot(1,2,1);
gscatter(data(:,4),data(:,7),data(:,8)),title('choose:4,7列,理论结果')
% cal accuracy
a_1 = size(find(label(1:70)==1),2);
a_2 = size(find(label(1:70)==2),2);
a_3 = size(find(label(1:70)==3),2);
a = max([a_1,a_2,a_3]);
b_1 = size(find(label(71:140)==1),2);
b_2 = size(find(label(71:140)==2),2);
b_3 = size(find(label(71:140)==3),2);
b = max([b_1,b_2,b_3]);
c_1 = size(find(label(141:210)==1),2);
c_2 = size(find(label(141:210)==2),2);
c_3 = size(find(label(141:210)==3),2);
c = max([c_1,c_2,c_3]);
accuracy = (a+b+c)/210;
% plot answer
subplot(1,2,2);
gscatter(data(:,4),data(:,7),label),title(['实际结果,accuracy=',num2str(accuracy)])
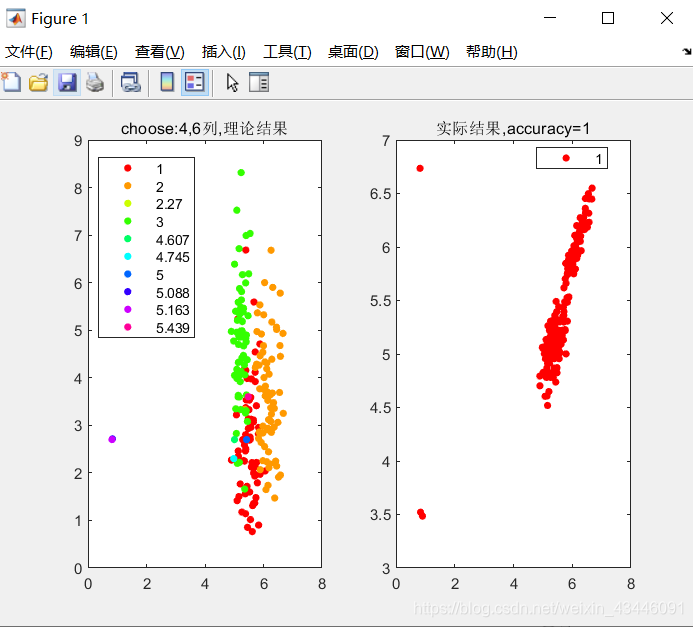
有个问题,我跑出来accuracy=1,按照原作者的说法应该是达不到这样的准确率
与Kmeans算法对比
1.1数据来源
该数据来源于UCI数据库,UCI数据库是加州大学欧文分校(University of CaliforniaIrvine)提出的用于机器学习的数据库,UCI数据集是一个常用的标准测试数据集。
网址:http://archive.ics.uci.edu/ml/datasets/Solar+Flare
1.2数据描述
太阳耀斑数据集:每一类属性统计一个24小时周期太阳耀斑数据集中某一类耀斑的数量
代码如下:FCM算法
m=1389;
n=13;
data=cell(m,n);%定义cell矩阵,存储文件内容
fid=fopen('solar.txt','r');%以只读方式打开文件
for i=1:m
for j=1:n
data{i,j}=fscanf(fid,'%s',[1,1]);%以字符方式读取每个值,遇空格完成每个值的读取
end
end
fclose (fid);
for i=1:m
for j=4:n
data{i,j}=str2double(data{i,j});%将文本格式转为数字格式
end
end
str=cell(m,1); %用于存储data的第1列
for i=1:m
str{i}=data{i,1};
end
str=cell(m,2); %用于存储data的第2列
for i=1:m
str{i}=data{i,2};
end
str=cell(m,3); %用于存储data的第3列
for i=1:m
str{i}=data{i,3};
end
代码如下:Kmeans算法
m=1389;
n=13;
data=cell(m,n);%定义cell矩阵,存储文件内容
fid=fopen('solar.txt','r');%以只读方式打开文件
for i=1:m
for j=1:n
data{i,j}=fscanf(fid,'%s',[1,1]);%以字符方式读取每个值,遇空格完成每个值的读取
end
end
fclose (fid);
for i=1:m
for j=4:n
data{i,j}=str2double(data{i,j});%将文本格式转为数字格式
end
end
str=cell(m,1); %用于存储data的第1列
for i=1:m
str{i}=data{i,1};
end
str=cell(m,2); %用于存储data的第2列
for i=1:m
str{i}=data{i,2};
end
str=cell(m,3); %用于存储data的第3列
for i=1:m
str{i}=data{i,3};
end
两种算法运行时间比较
Kmeans聚类代码如下:
% 簇心数目k
K = 3;
data = importdata('flare1.txt');
x = data(:,1);
y = data(:,2);
% 绘制数据,2维散点图
% x,y: 要绘制的数据点 20:散点大小相同,均为20 'blue':散点颜色为蓝色
s = scatter(x, y, 20, 'blue');
title('原始数据:蓝圈;初始簇心:红点');
% 初始化簇心
sample_num = size(data, 1); % 样本数量
sample_dimension = size(data, 2); % 每个样本特征维度
% 暂且手动指定簇心初始位置
% clusters = zeros(K, sample_dimension);
% 簇心赋初值:计算所有数据的均值,并将一些小随机向量加到均值上
clusters = zeros(K, sample_dimension);
minVal = min(data); % 各维度计算最小值
maxVal = max(data); % 各维度计算最大值
for i=1:K
clusters(i, :) = minVal + (maxVal - minVal) * rand();
end
hold on; % 在上次绘图(散点图)基础上,准备下次绘图
% 绘制初始簇心
scatter(clusters(:,1), clusters(:,2), 'red', 'filled'); % 实心圆点,表示簇心初始位置
c = zeros(sample_num, 1); % 每个样本所属簇的编号
PRECISION = 0.001;
iter = 100; % 假定最多迭代100次
% Stochastic Gradient Descendant 随机梯度下降(SGD)的K-means,也就是Competitive Learning版本
basic_eta = 1; % learning rate
for i=1:iter
pre_acc_err = 0; % 上一次迭代中,累计误差
acc_err = 0; % 累计误差
for j=1:sample_num
x_j = data(j, :); % 取得第j个样本数据,这里体现了stochastic性质
% 所有簇心和x计算距离,找到最近的一个(比较簇心到x的模长)
gg = repmat(x_j, K, 1);
gg = gg - clusters;
tt = arrayfun(@(n) norm(gg(n,:)), (1:K)');
[minVal, minIdx] = min(tt);
% 更新簇心:把最近的簇心(winner)向数据x拉动。 eta为学习率.
eta = basic_eta/i;
delta = eta*(x_j-clusters(minIdx,:));
clusters(minIdx,:) = clusters(minIdx,:) + delta;
acc_err = acc_err + norm(delta);
c(j)=minIdx;
end
if(rem(i,10) ~= 0)
continue
end
figure;
f = scatter(x, y, 20, 'blue');
hold on;
scatter(clusters(:,1), clusters(:,2), 'filled'); % 实心圆点,表示簇心初始位置
title(['第', num2str(i), '次迭代']);
if (abs(acc_err-pre_acc_err) < PRECISION)
disp(['收敛于第', num2str(i), '次迭代']);
break;
end
disp(['累计误差:', num2str(abs(acc_err-pre_acc_err))]);
pre_acc_err = acc_err;
end
disp('done');
参考文献
[1]丁震,胡钟山,杨静宇,唐振民,邬永革.一种基于模糊聚类的图象分割方法[J].计算机研究与发展,1997(07):58-63.
https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CJFD&dbname=CJFD9697&filename=JFYZ707.010&v=w6SVTbw2DI2U34NVEeHDiFy05S7tiJCXLSfhjzv1%25mmd2FMSAC%25mmd2B9EffWET8YmGo7%25mmd2BGjxA
[2]聚类之详解FCM算法原理及应用.CSDN
本文链接:https://blog.csdn.net/on2way/article/details/47087201
[3]FCM聚类与K-means聚类的实现和对比分析.CSDN
本文链接:https://blog.csdn.net/weixin_45583603/article/details/102773689
[4]基于FCM算法的聚类算法.CSDN
本文链接:https://blog.csdn.net/weixin_43821559/article/details/113616617















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









