







一:yarn出现损坏的nodemanger
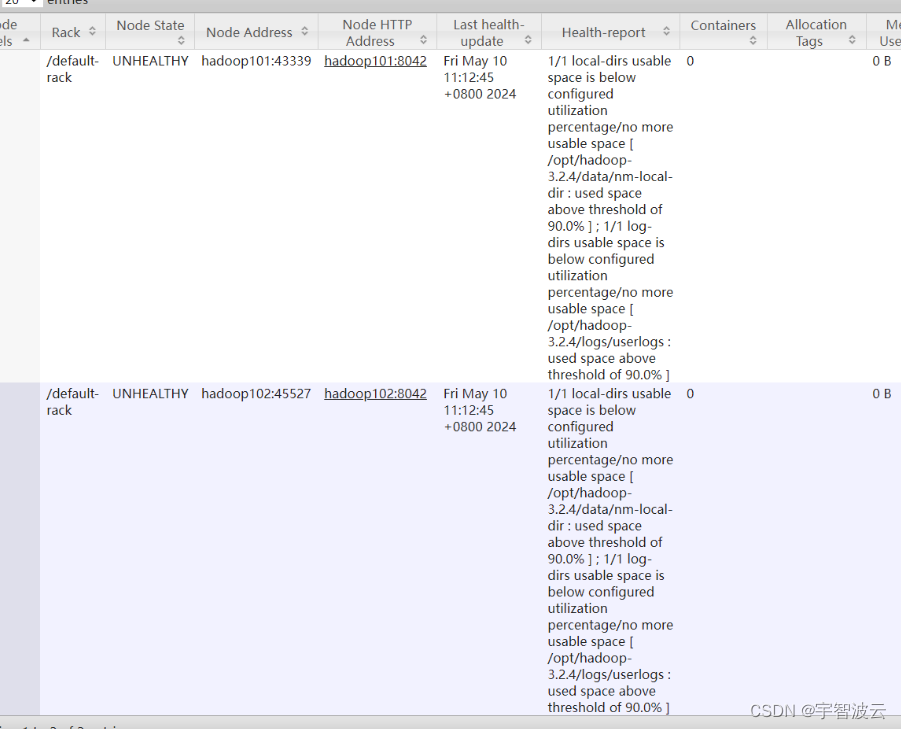
报错现象
日志:1/1 local-dirs usable space is below configured utilization percentage/no more usable space [ /opt/hadoop-3.2.4/data/nm-local-dir : used space above threshold of 90.0% ] ; 1/1 log-dirs usable space is below configured utilization percentage/no more usable space [ /opt/hadoop-3.2.4/logs/userlogs : used space above threshold of 90.0% ]
问题解析
yarn在启动服务的时候,需要加载文件资源到本地目录,目前显示本地目录资源使用百分之九十,没有办法在继续写入。
解决方案
- 在路径下增加磁盘资源
- 重新定位新的目录
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nodemanagerlog</value>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/log_dirs</value>
</property>
二:yarn资源配置
三个节点
内存 64g,80g,80g
核数 16,20,20
增加yarn资源调整参数
每个节点的参数可以设置不同
<!-- 这台服务器可以提供给yarn的核数 -->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>20</value>
</property>
<!-- 这台服务器可以提供给yarn的内存 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>61440</value>
</property>
<!-- 容器可以配置的最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!-- 容器可以配置的最大内存 -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>60000</value>
</property>
<!-- 容器可以配置的最大核数 -->
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>40</value>
</property>

/opt/flink-1.13.6/bin/flink run -m yarn-cluster -ys 20 -yjm 60000 -ytm 60000 -d -c com.shds.platform.cyberspace.CyberspaceParseJob /root/collection-cyberspace-1.0-SNAPSHOT.jar
三:插入hbase出现反压
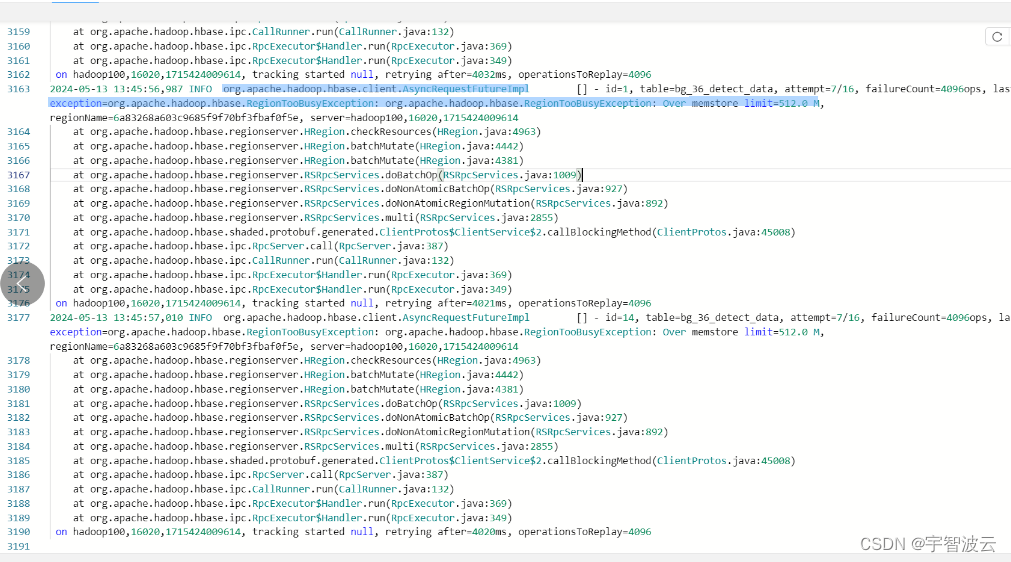
报错信息
org,apache.hadoop.hbase.client,AsyncRequestFutureImplexception=org.apache,hadoop.hbase.RegionTooBusyException: org.apache,hadoop.hbase,RegionTooBusvException: Over memstore limit=512.8 M
报错原因
问题出现在刷盘的时候,当menstore满了的时候,会将数据存储到hfile。当插入的时候是不能写入的。所以导致了这个问题。
解决方案
很多方案,最笼统的直接增加regionserver的资源大小进行重启。
vim hbase-env.sh
export HBASE_REGIONSERVER_OPTS="-Xms4G -Xmx8G"














 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









