






前言
授人以鱼不如授人以渔,这段时间需要用Node.js爬取数据网页数据,并生成excel表格+定时发送邮箱。接下来就讲解一下这次研究的思路如何。
分析
使用Node.js爬取数据,这一阶段,首先要知道什么是Node.js,知道它是干什么的,接下来就是面向百度编程了。经过简单学习什么是Node.js之后,接下来就是进入实战阶段,学习的路径如下,
学习路径如下:https://www.runoob.com/nodejs/nodejs-tutorial.html 。 
这里只需简单学习一下即可,当然,有一定的前端基础、或者后端基础更好,能够提高“理解度”。
实战
在编写js文件之前,首先电脑要配置好node环境,配置好之后,先附上完整的代码。
var http = require('http'), //Node.js提供了http模块,用于搭建HTTP服务端和客户端
url = 'test.com' //爬取的网址
cheerio = require('cheerio'), // 抓取页面模块。
request = require('superagent'),
fs = require('fs'),
xlsx = require('node-xlsx'),
path = ''
let list = [], start = '',
fetchPage = ()=>{
start();
};
start = ()=>{
request.get(url).end((err,res)=>{
if(!err){ //如果读取过程中没有错误
let html = res.text, //获取到数据
$ = cheerio.load(html), //加载需要的html
$itemMod = $('.list-unstyled.dot').find('li'),
len = $itemMod.length;
console.log(len);
if(len){
//pageNum++, //此处看爬取数据是否页数过多
$itemMod.each((i, e)=> {
let data = [], // 用来存储抓取的数据
$e = $(e); // 缓存
data.push($e.find('a').attr('title'));
data.push(path + $e.find('a').attr('href'));
list.push(data);
});
console.log(list);
// 通过 xlsx 模块将数据转化成 buffer 对象
let buf = xlsx.build([{data: list}]);
// 将 buffer 写入到 my.xlsx 中(导出)
fs.writeFile('test.xlsx', buf, (err)=> {
if(err){
throw err;
}else{
console.log('File is saved!');
// 回调获取下一页数据
start();
}
});
}
}else{
console.log('Get data error !');
}
});
};
fetchPage();
相关知识点
1.在node.js中知识中,有这样一段描述,使用Node.js时,我们不仅仅在实现一个应用,同时还实现了整个HTTP服务器。一个Node.js应用是由哪几部分组成:
1.引入 require模块:我们使用 require指令来载入Node.js模块。
2.创建服务器:服务器可以监听客户端请求,类似于Apache、Nginx等HTTP服务器。
3.接收请求与响应请求:服务器很容创建,客户端可以使用浏览器或终端发送http请求.服务器接收请求后返回响应的数据。
2.上面代码中,先用 require指令来载入Node.js自带的模块,并把它赋值给一个变量。
3.获取页面数据时,可以找到需要爬取的页面,右键查看目的数据,接下来就是需要定位到 该数据处,接下来就是使用编程的观点去看了,都知道 列表数据都是放在
- 标签中,我们只需要按照 取一个数组Array中每个元素的方法,不过在此处是需要用 标签来获取,
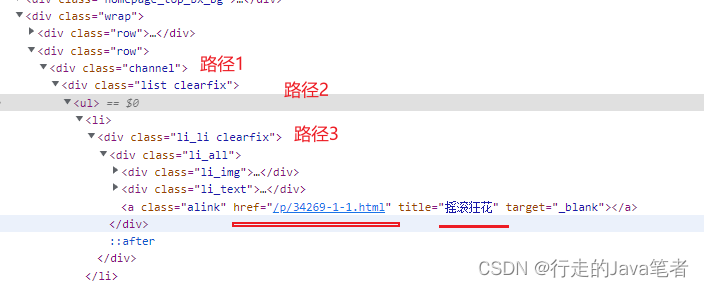
4.获取数据之后,接下来就是要写入excel中,我们使用 require指令引入 node-xlsx、fs等模块,每个模块的具体功能可以下去研究,这里只用所需要的部分,到这一步就可以了,接着是执行该js方法,
5.运行成功以后,会在 该js文件目录下生成一个 excel表格数据,查看数据是我们需要的。到这一步就完成了。接下来是进行第二部分。第二阶段
1.我们把excel表格发送到邮箱。通过面向百度可以查到,是使用的如下模块
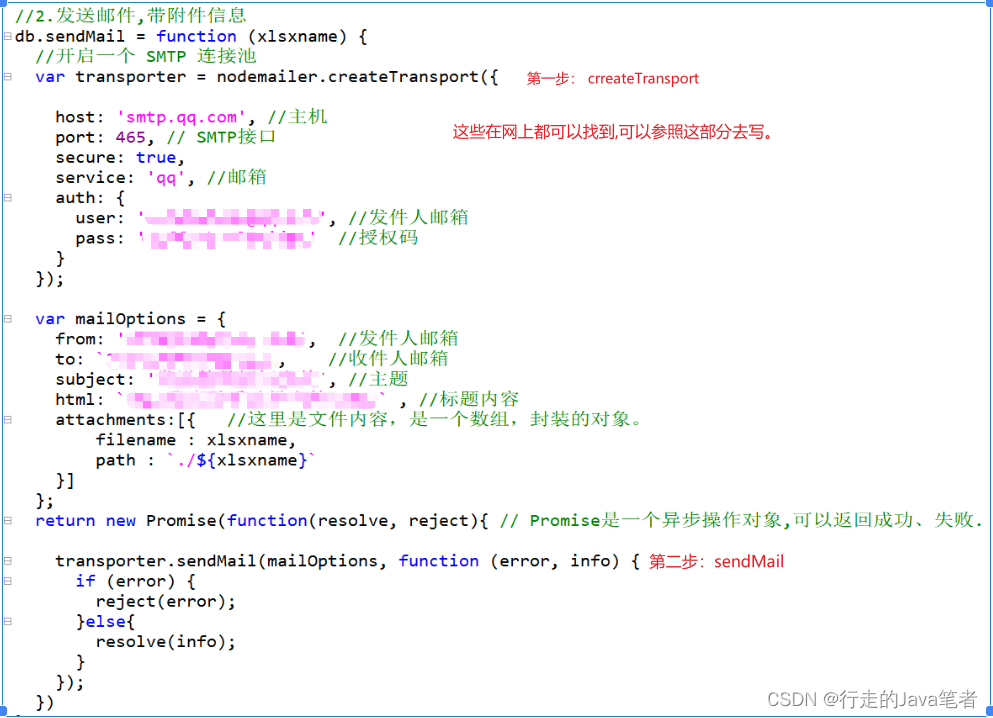
2.找到该方法之后,接下来就是测试阶段,尝试发送邮箱,发现有以下几个问题。
1.你不知道总的数据量有多少,爬取花费的时间有多长,我们要等待全部爬取结束后才可以发送邮箱,因此这里使用了 Promise方法,
2. 这个方法是Node.js自带的一个方法,其代表的是一个操作的结果可能还没有或不知道,无论谁访问这个对象,都能使用 ".then( )"方法加入回调等待操作出现成功结果或失败时的提醒通知。看来就是这个了,使用这个方法之后,可以在 爬取数据结束之后,使用 ".then( )"来进行下一步操作。是比较符合这种爬取数据的操作的,
3. 接下来我们把爬取网页数据的,使用 new promise给进行再次封装,等待爬取结束后,调用 ".then( )"方法,再执行发送邮箱操作。
4. 接下来再进行操作,可以看到,结果就是我们需要的,截图如下。
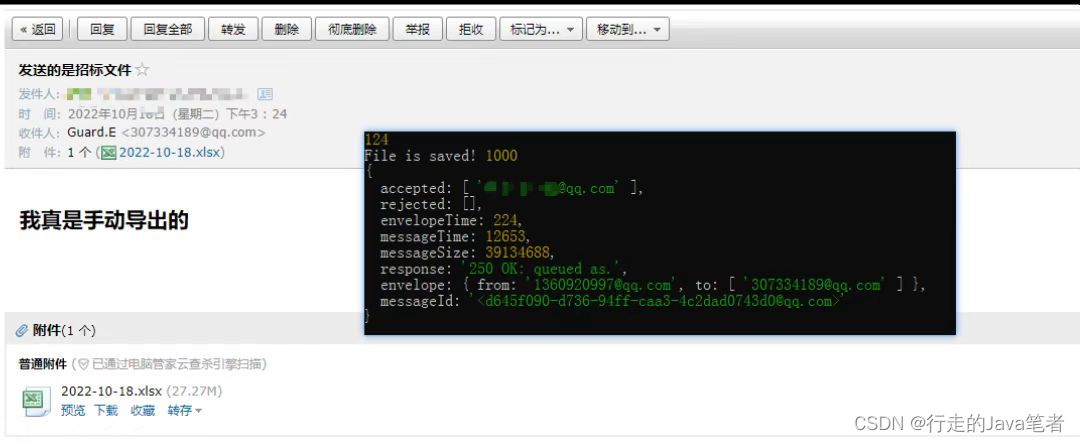
5.代码的源码如下
utils.js/* 2022年10月14日16:59:38 封装3个方法 1.格式化日期 2.发送邮件 3.爬取数据生成excel */ const db = {}, // 定义一个对象 nodemailer = require('nodemailer'), //邮件发送模块, http = require('http'), //Node.js提供了http模块,用于搭建HTTP服务端和客户端 url = 'https://www.cecbid.org.cn/tender/', //输入任何网址都可以 cheerio = require('cheerio'), // 抓取页面模块,为服务器特别定制的,快速、灵活、实施的jQuery核心实现 request = require('superagent'), fs = require('fs'), xlsx = require('node-xlsx'), path = 'https://www.cecbid.org.cn', schedule = require("node-schedule"); // 载入定时任务模块 let pageNum =1, list = [], start = '', fetchPage = ()=>{ start(); }; //0.查询数据 db.query = function(){ var xlsxname = `${db.nowDate().split(' ')[0]}.xlsx`; return new Promise(function(resolve, reject){ start = ()=>{ //爬取网页数据 request.get(url) .end((err,res)=>{ if(!err){ //如果读取过程中没有错误 let html = res.text, //获取到数据 $ = cheerio.load(html), //加载需要的html $itemMod = $('.list-unstyled.dot').find('li'), len = $itemMod.length; console.log(len); if(len){ pageNum++, $itemMod.each((i, e)=> { let data = [], // 用来存储抓取的数据 $e = $(e); // 缓存 data.push($e.find('a').attr('title')); data.push(path + $e.find('a').attr('href')); list.push(data); }); // 通过 xlsx 模块将数据转化成 buffer 对象 var buffer = xlsx.build([{data: list}]); fs.writeFile(xlsxname, buffer, 'binary',function(err){ if (err) { throw new error('创建excel异常'); return; }else{ console.log('File is saved!',pageNum); // 回调获取下一页数据,此处的判断条件应根据爬取页面的不同 if(pageNum == 1000){ resolve(list); return; }else{ start(); } } }) } }else{ resolve(list); } }); }; fetchPage(); }) }; //1.格式化当前日期 db.nowDate = function(){ var date = new Date(); var fmtTwo = function (number) { return (number < 10 ? '0' : '') + number; } var yyyy = date.getFullYear(); var MM = fmtTwo(date.getMonth() + 1); var dd = fmtTwo(date.getDate()); var HH = fmtTwo(date.getHours()); var mm = fmtTwo(date.getMinutes()); var ss = fmtTwo(date.getSeconds()); return '' + yyyy + '-' + MM + '-' + dd + ' ' + HH + ':' + mm + ':' + ss; } //2.发送邮件,带附件信息 db.sendMail = function (xlsxname) { //开启一个 SMTP 连接池 var transporter = nodemailer.createTransport({ host: 'smtp.qq.com', //主机 port: 465, // SMTP接口 secure: true, //SSL service: 'qq', //邮箱 auth: { user: 'xxx@qq.com', //发件人邮箱,此处改为自己的邮箱 pass: 'vvffynburlqwijgc' //授权码 } }); var mailOptions = { from: 'xxx@qq.com', //发件人邮箱 to: `xxx@qq.com`, //收件人邮箱 subject: '发送的是招标文件', //主题 html: `<h2>我这是手动导的</h2>` , //标题内容 attachments:[{ //这里是文件内容,是一个数组,封装的对象。 filename : xlsxname, path : `./${xlsxname}` }] }; return new Promise(function(resolve, reject){ // Promise是一个异步操作对象,可以返回成功、失败. transporter.sendMail(mailOptions, function (error, info) { if (error) { reject(error); }else{ resolve(info); } }); }) }; module.exports = db;sendEmail.js文件
var excel = require('./utils2'), // 引入其他模块 schedule = require("node-schedule"), xlsxname = ''; var auto = function(){ excel.query() .then(function(datas){ return Promise.resolve(datas); // 等待爬取页面数据结束之后,接着执行下面的方法,返回的excel }) .then(function(datas){//发送邮件 var xlsxname = `${excel.nowDate().split(' ')[0]}.xlsx`; return excel.sendMail(xlsxname); }) .then(function(info){ console.log(info); }) .catch(function(e){ //捕捉未处理的异常 console.log(e); }); } // 下方代码是添加了定时任务,可以注释掉相关代码。这部分作为额外补充。 var rule = new schedule.RecurrenceRule(); var t = []; for (var i = 0; i <= 86400; i++) { t.push(i); } var times = t; rule.second = times; schedule.scheduleJob(rule, function(){ auto(); });
















 9209
9209











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











