







 本文档详细介绍了在CDH6.2.1环境中配置Hive on Spark的过程,包括设置动态资源分配、测试SQL查询性能以及通过Hue、Beeline和Java代码执行SQL。通过示例展示了首次执行和后续执行SQL的差异,说明了Sparksession的缓存机制能提高执行效率。此外,还提供了通过Hive JDBC获取SQL执行日志的方法。
本文档详细介绍了在CDH6.2.1环境中配置Hive on Spark的过程,包括设置动态资源分配、测试SQL查询性能以及通过Hue、Beeline和Java代码执行SQL。通过示例展示了首次执行和后续执行SQL的差异,说明了Sparksession的缓存机制能提高执行效率。此外,还提供了通过Hive JDBC获取SQL执行日志的方法。
CDH6.2.1 环境
1、开启hive on spark配置:
在hive配置中搜索 spark ,更改一下配置:
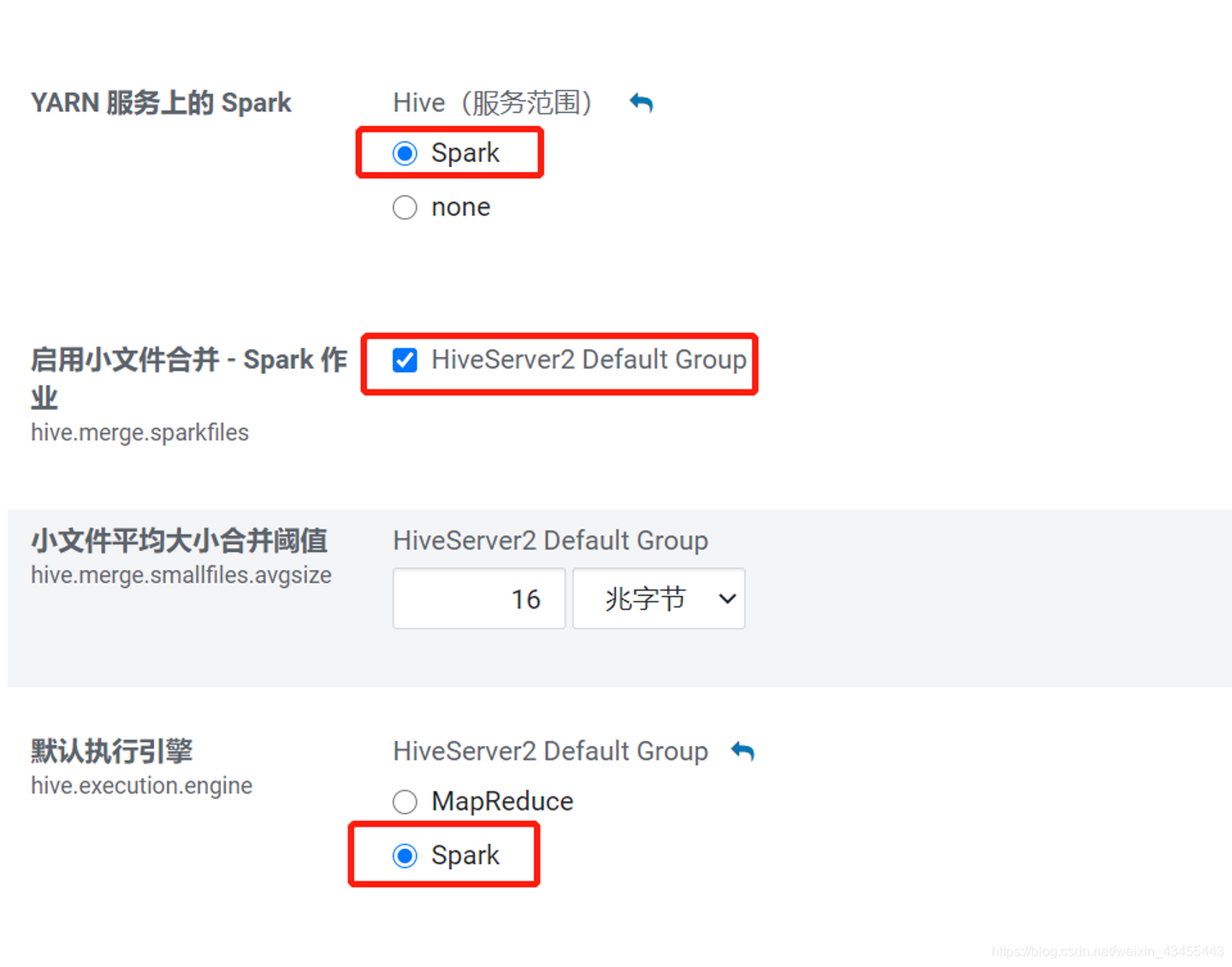
YARN 服务上的 Spark 选择spark
默认执行引擎 hive.execution.engine :spark
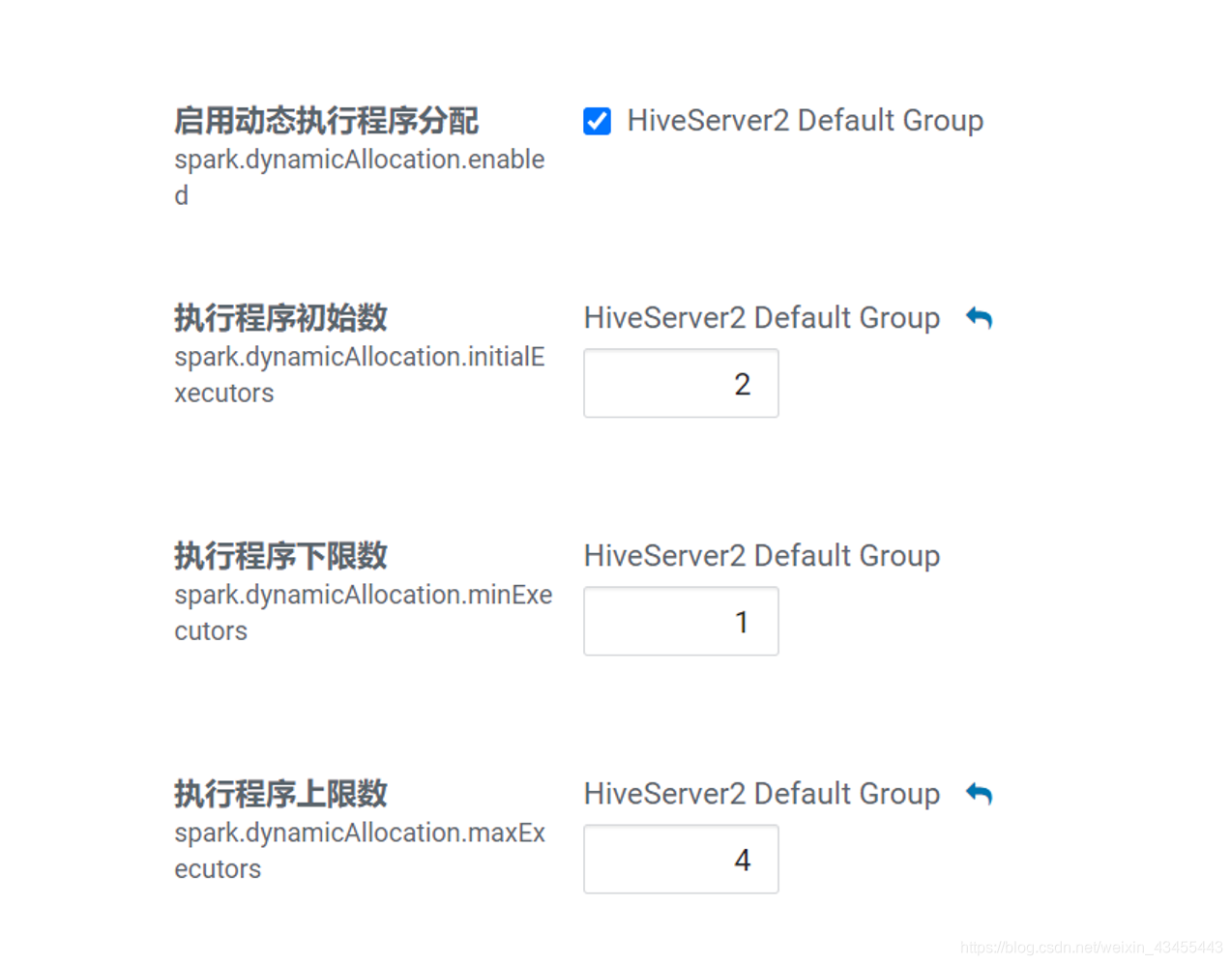
执行程序初始数 spark.dynamicAllocation.initialExecutors :2 ,启动sparksession时,默认初始启动的executor个数,如果配置了 set spark.executor.instances=3 (启动的executor个数),则启动sparksession时,为3个executor。
执行程序下限数 spark.dynamicAllocation.minExecutors :1 ,最少的executor个数,也就是当开启动态资源分配后,移除空闲的executor后,最少剩余1个executor存在。
执行程序上限数 spark.dynamicAllocation.maxExecutors :4 ,最多的executor个数,也就是启动sparksession时,最多扩展的executor个数。
各应用程序的 Spark 执行程序 spark.executor.instances :2 ,启动sparksession时,指定启动的executor个数。相当于初始化启动的executor个数,该值需介于minExecutors和maxExecutors之间。
2、hue中测试hive on spark
select * from a;
select count(*) from a;
create temporary function pinjie as 'com.topnet.MyUDF' using jar 'hdfs:///user/hive/udf/hiveUDF-1.0.jar';
select pinjie(name) from a;
drop function pinjie;
由于 sql1执行不会在底层创建application,会直接返回数据,所以查询时间很快。
sql2 底层会创建app,向yarn申请资源,由于是初次创建sparksession,时间会比较久,当再次执行count查询时就会很快反回数据,是因为第一次创建完sparksession后,session不会关闭,会驻留在内存中,当再有执行计划来时,省去启动session的时间,直接执行sql语句。
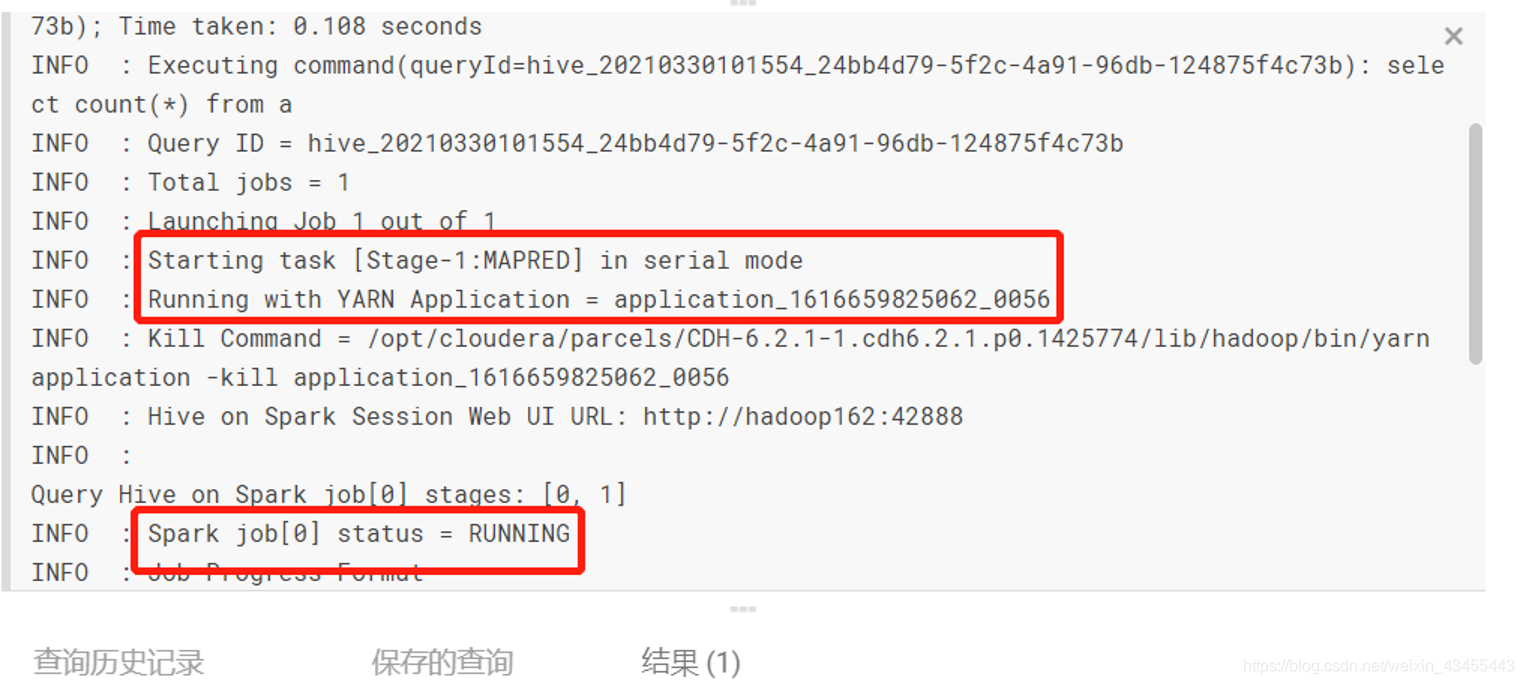
sql3、sql4、sql5 为创建使用删除临时udf函数。
3、通过beeline连接hive
[root@hadoop163 ~]# beeline -u jdbc:hive2://hadoop162:10000 -n hive
0: jdbc:hive2://hadoop162:10000> select * from a;
+-------+---------+
| a.id | a.name |
+-------+---------+
| 1 | 小明 |
+-------+---------+
1 row selected (1.293 seconds)
0: jdbc:hive2://hadoop162:10000> select count(*) from a;
INFO : Compiling command(queryId=hive_20210330102334_8c2258a0-2c5f-42ab-8d47-65f033967bc8): select count(*) from a
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20210330102334_8c2258a0-2c5f-42ab-8d47-65f033967bc8); Time taken: 0.101 seconds
INFO : Executing command(queryId=hive_20210330102334_8c2258a0-2c5f-42ab-8d47-65f033967bc8): select count(*) from a
INFO : Query ID = hive_20210330102334_8c2258a0-2c5f-42ab-8d47-65f033967bc8
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : Running with YARN Application = application_1616659825062_0057
INFO : Kill Command = /opt/cloudera/parcels/CDH-6.2.1-1.cdh6.2.1.p0.1425774/lib/hadoop/bin/yarn application -kill application_1616659825062_0057
INFO : Hive on Spark Session Web UI URL: http://hadoop161:44976
INFO :
Query Hive on Spark job[0] stages: [0, 1]
INFO : Spark job[0] status = RUNNING
INFO : Job Progress Format
CurrentTime StageId_StageAttemptId: SucceededTasksCount(+RunningTasksCount-FailedTasksCount)/TotalTasksCount
INFO : 2021-03-30 10:24:38,990 Stage-0_0: 0(+1)/1 Stage-1_0: 0/1
INFO : 2021-03-30 10:24:42,005 Stage-0_0: 0(+1)/1 Stage-1_0: 0/1
INFO : 2021-03-30 10:24:43,010 Stage-0_0: 1/1 Finished Stage-1_0: 0/1
INFO : 2021-03-30 10:24:44,013 Stage-0_0: 1/1 Finished Stage-1_0: 1/1 Finished
INFO : Spark job[0] finished successfully in 9.09 second(s)
INFO : Completed executing command(queryId=hive_20210330102334_8c2258a0-2c5f-42ab-8d47-65f033967bc8); Time taken: 69.551 seconds
INFO : OK
+------+
| _c0 |
+------+
| 1 |
+------+
1 row selected (69.711 seconds)
查看yarn,可以看到启动的APP,其type为spark,可以看到使用的相关资源。
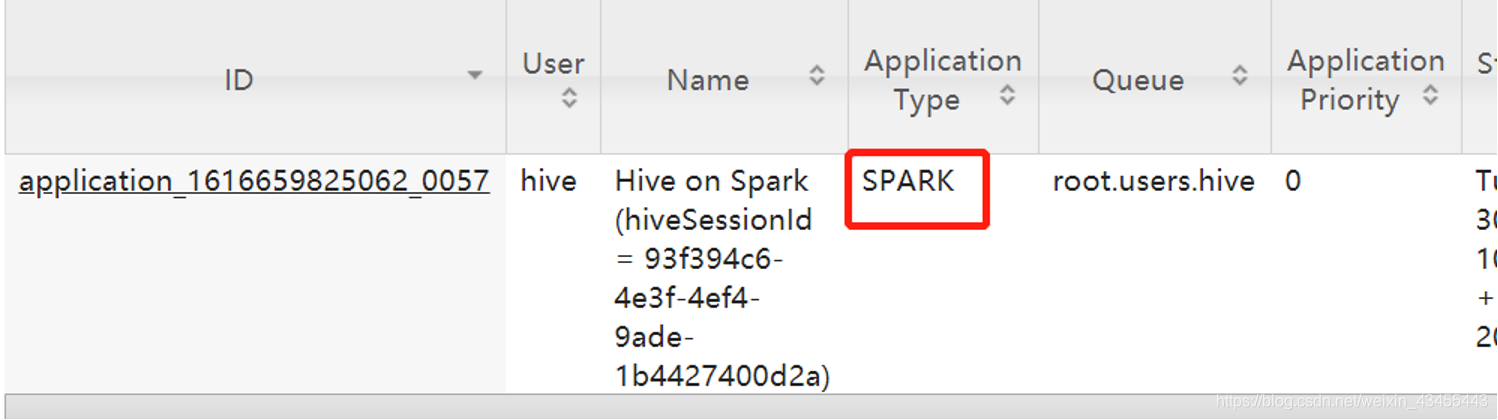
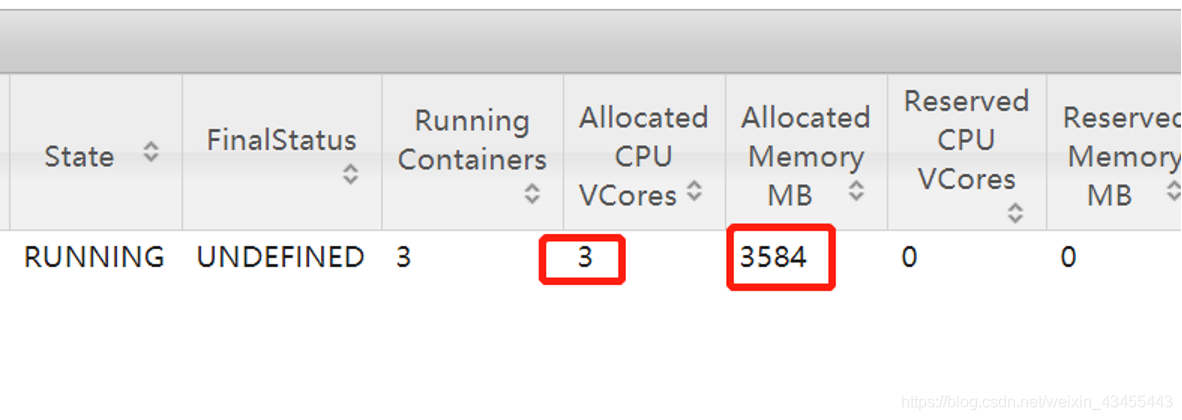
再次运行count语句,只使用了1s多,可以看到省去启动sparksession的时间。
0: jdbc:hive2://hadoop162:10000> select count(*) from a;
INFO : Compiling command(queryId=hive_20210330102952_17ea110d-01c4-4bba-8378-3876fbcf1cb0): select count(*) from a
INFO : Semantic Analysis Completed
INFO : Returning Hive schema: Schema(fieldSchemas:[FieldSchema(name:_c0, type:bigint, comment:null)], properties:null)
INFO : Completed compiling command(queryId=hive_20210330102952_17ea110d-01c4-4bba-8378-3876fbcf1cb0); Time taken: 0.108 seconds
INFO : Executing command(queryId=hive_20210330102952_17ea110d-01c4-4bba-8378-3876fbcf1cb0): select count(*) from a
INFO : Query ID = hive_20210330102952_17ea110d-01c4-4bba-8378-3876fbcf1cb0
INFO : Total jobs = 1
INFO : Launching Job 1 out of 1
INFO : Starting task [Stage-1:MAPRED] in serial mode
INFO : 2021-03-30 10:29:54,097 Stage-2_0: 1/1 Finished Stage-3_0: 1/1 Finished
INFO : Spark job[1] finished successfully in 1.00 second(s)
INFO : Completed executing command(queryId=hive_20210330102952_17ea110d-01c4-4bba-8378-3876fbcf1cb0); Time taken: 1.109 seconds
INFO : OK
+------+
| _c0 |
+------+
| 1 |
+------+
1 row selected (1.271 seconds)
0: jdbc:hive2://hadoop162:10000>
4、通过java代码连接hive on spark,使用hive-jdbc
引入pom文件
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.1</version>
</dependency>
import java.sql.*;
import java.util.Scanner;
public class HiveJDBC {
public static void main(String[] args) throws ClassNotFoundException, SQLException, InterruptedException {
String driverName = "org.apache.hive.jdbc.HiveDriver";
String url = "jdbc:hive2://hadoop162:10000";
String dbName = "default";
Connection con = null;
Statement state = null;
ResultSet res = null;
Class.forName(driverName);
//这里必须指定用户名和密码,密码可以为空字符串,如果不指定则或报错启动sparksession失败
con= DriverManager.getConnection(url+"/"+dbName,"hive","");
state = con.createStatement();
Scanner scan = new Scanner(System.in);
String sql=null;
//创建临时udf,可以不创建
state.execute("create temporary function pinjie as 'com.topnet.MyUDF' using jar 'hdfs:///user/hive/udf/hiveUDF-1.0.jar'");
while (true){
System.out.println("亲输入sql:");
if(scan.hasNext()){
sql=scan.nextLine();
}
System.out.println(sql);
res = state.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
Thread.sleep(100);
}
}
}

5、运行sql的执行日志获取
使用hive-jdbc运行时,如果想获取sql的执行日志,则可以通过这几个方法获取运行的日志信息。List<String> getQueryLog(),List<String> getQueryLog(boolean incremental, int fetchSize)和boolean hasMoreLogs()三个方法,在进行hive的sql查询时,有时一个sql可能需要运行很长时间,借助这三个方法,还可以实时显示sql 的查询进度。
想要实时的显示sql查询进度,则需要再开启一个线程进行日志获取打印。
public class HiveJDBC {
public static void main(String[] args) throws ClassNotFoundException, SQLException, InterruptedException {
Logger log = LoggerFactory.getLogger(HiveJDBC.class);
String driverName = "org.apache.hive.jdbc.HiveDriver";
String url = "jdbc:hive2://hadoop162:10000";
String dbName = "default";
Connection con = null;
Statement state = null;
ResultSet res = null;
Class.forName(driverName);
//这里必须指定用户名和密码,密码可以为空字符串,如果不指定则或报错启动sparksession失败
con = DriverManager.getConnection(url + "/" + dbName, "hive", "");
state = con.createStatement();
Scanner scan = new Scanner(System.in);
String sql = null;
//开启线程获取sql执行日志
Thread logThread = new Thread(new HiveLog((HiveStatement) state));
logThread.setDaemon(true);
logThread.start();
//注册临时udf函数,可以不创建
state.execute("create temporary function pinjie as 'com.topnet.MyUDF' using jar 'hdfs:///user/hive/udf/hiveUDF-1.0.jar'");
while (true) {
System.out.println("亲输入sql:");
if (scan.hasNext()) {
sql = scan.nextLine();
}
log.error("打印日志sql语句:" + sql);
res = state.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1));
}
Thread.sleep(100);
}
}
static class HiveLog extends Thread {
private final HiveStatement state;
HiveLog(HiveStatement state) {
this.state = state;
}
private void updateQueryLog() {
try {
List<String> queryLogs = state.getQueryLog();
for (String log : queryLogs) {
System.out.println("进度信息-->" + log);
}
} catch (Exception e) {
}
}
@Override
public void run() {
try {
//循环不断的获取sql执行的日志
while (true) {
if (state.hasMoreLogs()) {
updateQueryLog();
}
Thread.sleep(100);
}
} catch (InterruptedException e) {
e.getStackTrace();
}
}
}
}
查看sql运行日志信息
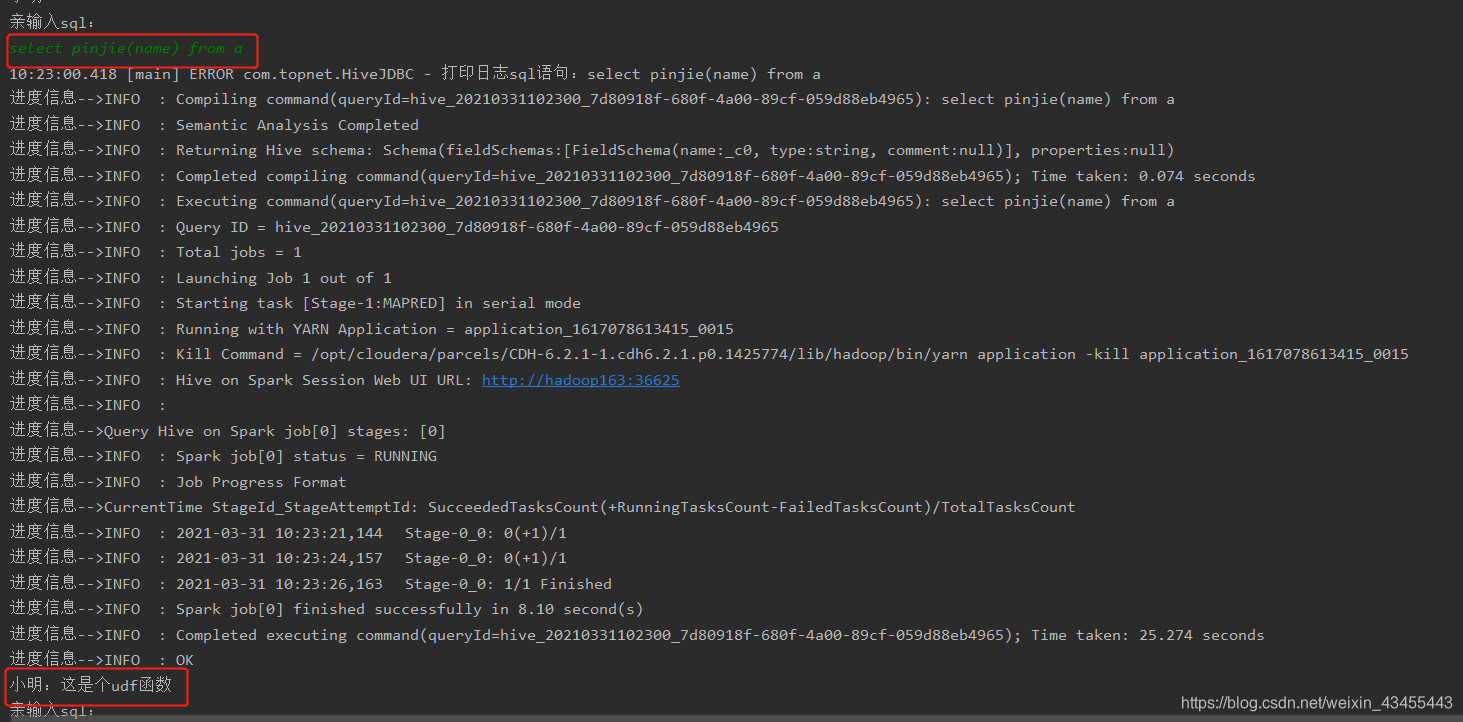
查看yarn管理界面:

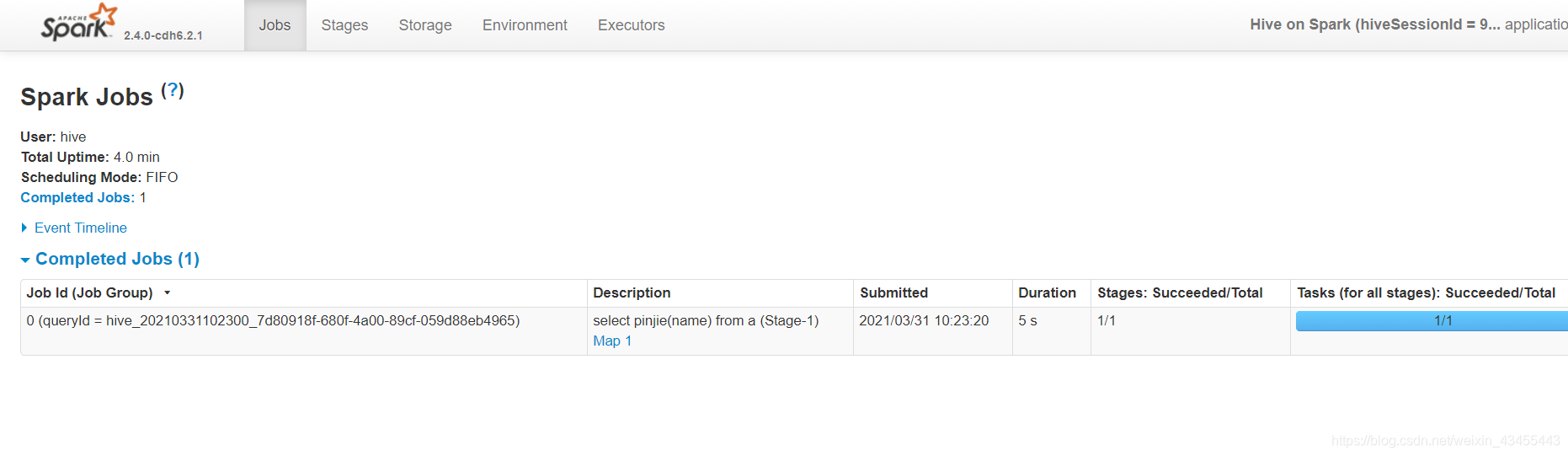
查看sparkUI:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









