







#shardingsphere# 系列文章目录
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
一、基本概念
1. 什么是shardingsphere及核心概念
1. 简介
1、一套开源的分布式数据库中间件解决方案
2、有三个产品:Sharding-JDBC 和 Sharding-Proxy、ShardingSphere-Sidecar
3、定位为关系型数据库中间件,合理在分布式环境下使用关系型数据库操作
2. 逻辑表
- 水平拆分的数据库(表)的相同逻辑和数据结构表的总称。例:用户数据根据主键尾数拆分为 10 张表,分别是user_0 到 user_9,他们的逻辑表名为 user
3. 真实表
- 在分片的数据库中真实存在的物理表。即上个示例中的 user_0 到 user_9
4. 数据节点
- 数据分片的最小单元。由数据源名称和数据表组成,例:master.user_0
5. 绑定表
-
指分片规则一致的主表和子表。例如:t_order 表和 t_order_item 表,均按照 order_id 分片,则此两张表互为绑定表关系。绑定表之间的多表关联查询不会出现笛卡尔积关联,关联查询效率将大大提升。
-
举例说明,如果 SQL 为:
SELECT i.* FROM t_order o JOIN t_order_item i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
- 在不配置绑定表关系时,假设分片键 order_id 将数值 10 路由至第 0 片,将数值 11 路由至第 1 片,那么路由后的 SQL 应该为 4 条,它们呈现为笛卡尔积:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_0 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
- 在配置绑定表关系后,路由的 SQL 应该为 2 条:
SELECT i.* FROM t_order_0 o JOIN t_order_item_0 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
SELECT i.* FROM t_order_1 o JOIN t_order_item_1 i ON o.order_id=i.order_id WHERE o.order_id in (10, 11);
- 其中 t_order 在 FROM 的最左侧,ShardingSphere 将会以它作为整个绑定表的主表。 所有路由计算将会只使用主表的策略,那么 t_order_item 表的分片计算将会使用 t_order 的条件。故绑定表之间的分区键要完全相同
6. 广播表(公共表)
- 指所有的分片数据源中都存在的表,表结构和表中的数据在每个数据库中均完全一致。适用于数据量不大且需要与海量数据的表进行关联查询的场景,例如:字典表
2. 分库分表
1. 什么是分库分表
1,数据库的切分指的是通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)中,以达到分散单台设备负载的效果,即分库分表。
2. 分库分表的作用
1,分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的
3. 分库分表的方式
1,数据的切分根据其切分规则的类型,可以分为 垂直切分 和水平切分。4. 垂直切分
1,按照业务拆分的方式称为垂直切分,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。 下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案。
2,简单来说垂直切分就是把单一的表拆分成多个表,并分散到不同的数据库(主机)上
3,垂直切分分为:垂直分表和垂直分库
1.垂直切分的优缺点
- 优点:
1,拆分后业务清晰,系统之间进行整合或扩展很容易。
2,按照成本、应用的等级、应用的类型等奖表放到不同的机器上,便于管理,数据维护简单。 - 缺点
1,部分业务表无法关联(Join), 只能通过接口方式解决,提高了系统的复杂度。
2,受每种业务的不同限制,存在单库性能瓶颈,不易进行数据扩展和提升性能。
3,事务处理变得复杂。
4,垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
5. 水平切分
1,水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。

2,与垂直切分对比,水平切分不是将表进行分类,而是将其按照某个字段的某种规则分散到多个库中,在每个表中包含一部分数据,所有表加起来就是全量的数据。简单来说,我们可以将对数据的水平切分理解为按照数据行进行切分,就是将表中的某些行切分到一个数据库表中,而将其他行切分到其他数据库表中。
1.水平切分的优缺点
- 优点:
1,单库单表的数据保持在一定的量级,有助于性能的提高。
2,切分的表的结构相同,应用层改造较少,只需要增加路由规则即可。
3,提高了系统的稳定性和负载能力。 - 缺点:
1,切分后,数据是分散的,很难利用数据库的 Join 操作,跨库 Join 性能较差。
2,分片事务的一致性难以解决,数据扩容的难度和维护量极大。
二、shardingsphere-jdbc
1. shardingsphere-jdbc简介:
ShardingSphere-JDBC 是 Apache ShardingSphere 的第一个产品,也是 Apache ShardingSphere 的前身。 定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。- 适用于任何基于 JDBC 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
- 支持任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
- 支持任意实现 JDBC 规范的数据库。目前支持 MySQL,Oracle,SQLServer,PostgreSQL 以及任何遵循 SQL92 标准的数据库。

2.水平分表
1,引入maven依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
<version>2.3.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<version>2.4.2</version>
</dependency>
<!--druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.20</version>
</dependency>
<!--mysql-connector驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.47</version>
</dependency>
<!--shardingsphere-jdbc-->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!--mybatis-plus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<!--junit单元测试-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.1</version>
<scope>test</scope>
</dependency>
</dependencies>
2,创建实体类
- 分别创建user_0,user_1表,表结构相同
- 创建实体类
@Data
public class User {
@TableField("user_id")
@TableId
private Long userId;
private String username;
private Integer age;
private Integer lea;
}
3,编辑配置文件
# 配置数据源,给数据源起名称
spring.shardingsphere.datasource.names=master
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.master.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master.url=jdbc:mysql://localhost:3306/shardingsphere_db_table?characterEncoding=utf-8
spring.shardingsphere.datasource.master.username=root
spring.shardingsphere.datasource.master.password=123
# 指定user表里面主键user_id 生成策略 SNOWFLAKE(雪花算法)
spring.shardingsphere.sharding.tables.user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
#数据分表规则
#指定所需分的表
spring.shardingsphere.sharding.tables.user.actual-data-nodes=master.user_$->{0..1}
#指定主键
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=user_id
#分表规则为主键除以2取模
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{user_id % 2}
#打印sql
spring.shardingsphere.props.sql.show=true
3,编辑测试类测试
package com.zch.dblevsegdatabase;
import com.baomidou.mybatisplus.core.conditions.query.LambdaQueryWrapper;
import com.baomidou.mybatisplus.core.toolkit.Wrappers;
import com.zch.dblevsegdatabase.entity.User;
import com.zch.dblevsegdatabase.mapper.UserMapper;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import javax.annotation.Resource;
import java.util.List;
@SpringBootTest
@RunWith(SpringRunner.class)
public class DbLevSegDatabaseApplicationTests {
@Resource
private UserMapper userMapper;
/**
* 插入
*/
@Test
public void addUser(){
for (int i = 0; i < 10; i++){
User user = new User();
user.setUsername("java"+i);
user.setAge(i);
user.setLea(i);
userMapper.insert(user);
}
}
/**
* userId查询
*/
@Test
public void queryUser(){
LambdaQueryWrapper<User> queryWrapper = Wrappers.lambdaQuery();
queryWrapper.eq(User::getUserId,569178796029116416L);
User users = userMapper.selectOne(queryWrapper);
System.out.println(users);
}
@Test
public void queryUserByUsername(){
LambdaQueryWrapper<User> queryWrapper = Wrappers.lambdaQuery();
queryWrapper.like(User::getUsername,"java");
List<User> users = userMapper.selectList(queryWrapper);
for (User user :users) {
System.out.println(user);
}
}
@Test
public void querUserList(){
List<User> users = userMapper.selectList(null);
for (User user :users) {
System.out.println(user);
}
}
}
3.水平分库和广播表(公共表)
1,引入maven依赖(同上)
2,创建两个不同的库sharding_sphere_database0和sharding_sphere_database1
3,两个库中分别创建user_0和user_1(表结构同上)
4,编辑配置文件
# 配置数据源,给数据源起名称
spring.shardingsphere.datasource.names=master0,master1
# 一个实体类对应两张表,覆盖
spring.main.allow-bean-definition-overriding=true
#配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.master0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master0.url=jdbc:mysql://localhost:3306/sharding_sphere_database0?characterEncoding=utf-8
spring.shardingsphere.datasource.master0.username=root
spring.shardingsphere.datasource.master0.password=123456
spring.shardingsphere.datasource.master1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master1.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master1.url=jdbc:mysql://localhost:3306/sharding_sphere_database1?characterEncoding=utf-8
spring.shardingsphere.datasource.master1.username=root
spring.shardingsphere.datasource.master1.password=123456
# 指定user表里面主键user_id 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
#数据分表规则
#指定所需分的库和表
spring.shardingsphere.sharding.tables.user.actual-data-nodes=master$->{0..1}.user_$->{0..1}
# 指定表分片策略
#指定主键
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=user_id
#分表规则为主键除以2取模
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{user_id % 2}
#指定库分片策略
#指定主键
spring.shardingsphere.sharding.tables.user.database-strategy.inline.sharding-column=lea
#根据lea分库
spring.shardingsphere.sharding.tables.user.database-strategy.inline.algorithm-expression=master$->{lea % 2}
#打印sql
spring.shardingsphere.props.sql.show=true
5,除此之外我们还可以配置公共表
- 公共表属于系统中数据量较小,变动少,而且属于高频联合查询的依赖表。参数表、数据字典
表等属于此类型。可以将这类表在每个数据库都保存一份,所有更新操作都同时发送到所有分
库执行 - 实现公共表只需在每个库中都创建一个同样的公共表如(udict表)
- 实体类和表结构
@Data
public class Udict {
@TableId
private Long udictId;
private String status;
private String des;
}
- 创建完公共表和公共表实体类后只需要在水平分库的配置文件基础上添加一下配置即可
# 配置公共表
spring.shardingsphere.sharding.broadcast-tables=udict
# 指定公共表的主键和主键生成策略
spring.shardingsphere.sharding.tables.udict.key-generator.column=udict_id
spring.shardingsphere.sharding.tables.udict.key-generator.type=SNOWFLAKE
6,编辑测试类测试
@Resource
private UserMapper userMapper;
@Resource
private UdictMapper udictMapper;
/**
* 插入
*/
@Test
public void insertUser(){
for (int i = 0; i <10 ; i++) {
User user = new User();
user.setUsername("java"+i);
user.setLea(i);
user.setAge(i);
userMapper.insert(user);
}
}
@Test
public void query(){
List<User> users = userMapper.selectList(null);
for (User user :users) {
System.out.println(user);
}
}
/**
* 公共表添加测试
*/
@Test
public void insertBroadCastTable(){
Udict udict = new Udict();
udict.setDes("我是描述...");
udict.setStatus("我的状态很好...");
int insert = udictMapper.insert(udict);
System.out.println(insert);
}
/**
* 公共表修改测试
*/
@Test
public void modifyBroadCastTable(){
Udict udict = new Udict();
udict.setDes("我是描述修改");
udict.setStatus("我的状态修改...");
udict.setUdictId(569537668975689729L);
int insert = udictMapper.updateById(udict);
System.out.println(insert);
}
4.垂直分库
1,垂直分库是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。接下来看一下如何使用Sharding-JDBC实现垂直分库。
2,创建数据库sharding_sphere_vertical_db和实体类user
3,编辑配置文件
# 配置数据源,给数据源起名称
spring.shardingsphere.datasource.names=master0
#配置数据源具体内容,包含连接池,驱动,地址,用户名和密码
spring.shardingsphere.datasource.master0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.master0.driver-class-name=com.mysql.jdbc.Driver
spring.shardingsphere.datasource.master0.url=jdbc:mysql://localhost:3306/sharding_sphere_vertical_db?characterEncoding=utf-8
spring.shardingsphere.datasource.master0.username=root
spring.shardingsphere.datasource.master0.password=123
# 指定user表里面主键user_id 生成策略 SNOWFLAKE
spring.shardingsphere.sharding.tables.user.key-generator.column=user_id
spring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE
#配置指定数据库中的表
spring.shardingsphere.sharding.tables.user.actual-data-nodes=master$->{0}.user
# 指定表分片策略
#指定主键
spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=user_id
#分表规则 (专库专表)
spring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user
#打印sql
spring.shardingsphere.props.sql.show=true
5.读写分离
1,面对日益增加的系统访问量,数据库的吞吐量面临着巨大瓶颈。 对于同一时刻有大量并发读操作和较少写操作类型的应用系统来说,将数据库拆分为主库和从库,主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。
通过一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 使用多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
与将数据根据分片键打散至各个数据节点的水平分片不同,读写分离则是根据SQL语义的分析,将读操作和写操作分别路由至主库与从库。

- 主从复制:当主服务器有写入(insert/update/delete)语句时候,从服务器自动获取
- 读写分离:insert/update/delete语句操作一台服务器,select操作另一个服务器

Sharding-JDBC读写分离则是根据SQL语义的分析,将读操作和写操作分别路由至主库与从库。它提供透明化读写分离,让使用方尽量像使用一个数据库一样使用主从数据库集群。
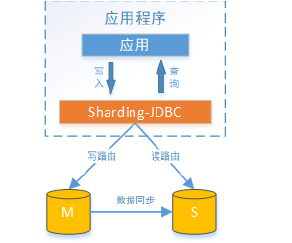
Sharding-JDBC提供一主多从的读写分离配置,可独立使用,也可配合分库分表使用,同一线程且同一数据库连接内,如有写入操作,以后的读操作均从主库读取,用于保证数据一致性。Sharding-JDBC不提供主从数据库的数据同步功能,需要采用其他机制支持。
三.shardingsphere-proxy
1.简介
Sharding-Proxy是ShardingSphere的第二个产品。 它定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供MySQL/PostgreSQL版本,它可以使用任何兼容MySQL/PostgreSQL协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat等)操作数据,对DBA更加友好。
- 向应用程序完全透明,可直接当做MySQL/PostgreSQL使用。
- 适用于任何兼容MySQL/PostgreSQL协议的的客户端

2. shardingsphere-proxy简单使用
1.下载shardingshpere-proxy解压
2. 导入数据库驱动到lib中

3.修改config文件夹中的server.yaml文件
authentication:
users:
root: # 用户名
password: root # 密码
sharding:
password: sharding
authorizedSchemas: sharding_db
props:
max-connections-size-per-query: 1
acceptor-size: 16 # The default value is available processors count * 2.
executor-size: 16 # Infinite by default.
proxy-frontend-flush-threshold: 128 # The default value is 128.
# LOCAL: Proxy will run with LOCAL transaction.
# XA: Proxy will run with XA transaction.
# BASE: Proxy will run with B.A.S.E transaction.
proxy-transaction-type: LOCAL
proxy-opentracing-enabled: false
proxy-hint-enabled: false
query-with-cipher-column: true
sql-show: false
check-table-metadata-enabled: false
4.修改config-sharding.yaml文件配置
schemaName: sharding_db
dataSourceCommon:
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
maintenanceIntervalMilliseconds: 30000
dataSources:
ds_0:
url: jdbc:mysql://127.0.0.1:3306/sharding_sphere_database0?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
ds_1:
url: jdbc:mysql://127.0.0.1:3306/sharding_sphere_database1?characterEncoding=utf-8&serverTimezone=Asia/Shanghai
rules:
- !SHARDING
tables:
user:
actualDataNodes: ds_${0..1}.user_${0..1}
tableStrategy: #表格策略
standard:
shardingColumn: lea #分片列
shardingAlgorithmName: user_inline #分片算法名称
keyGenerateStrategy:
column: user_id
keyGeneratorName: snowflake
bindingTables:
- user
defaultDatabaseStrategy: #默认数据库策略
standard: #标准,水准
shardingColumn: user_id
shardingAlgorithmName: database_inline
defaultTableStrategy: #默认数据库表策略
none:
shardingAlgorithms: # 分片算法
database_inline:
type: INLINE
props:
algorithm-expression: ds_${user_id % 2}
user_inline:
type: INLINE
props:
algorithm-expression: user_${lea % 2}
5. 启动shardingsphere-proxy服务
- 点击start.bat文件启动服务

6.连接代理数据库
1.通过cmd控制台连接
mysql -h127.0.0.1 -uroot -P3307 -proot
2.通过Navicat
















 1684
1684











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









