







一、摘要
本文的主要内容是关于零样本学习中属性选择的研究。零样本学习是一种解决分类问题的方法,其中目标是构建针对一组目标类别的分类模型。然而,以往的研究中往往忽视了属性之间的差异性,将它们等同对待,导致模型受到“噪声”属性的影响而准确性有限。本文提出了一种属性选择的方法,通过联合优化信息量和可预测性的标准,选择对于后续的零样本学习模型最有价值的属性,从而提高模型的准确性。
二、引言
1. 背景:
图像分类是机器学习和计算机视觉领域的研究热点,但对于没有标记样本的目标类别进行分类模型构建是一个实际问题。
2. 过去方案:
以往的工作大多忽视了属性的多样性,将每个属性视为相同,从而受到“噪声”属性的影响,限制了准确性。因为不同的属性,有不同的特性。
3. 动机:
由于以往的零样本学习方法忽视了属性的多样性,本研究旨在通过属性选择优化框架,提高零样本学习模型的性能。
4. 贡献:
-
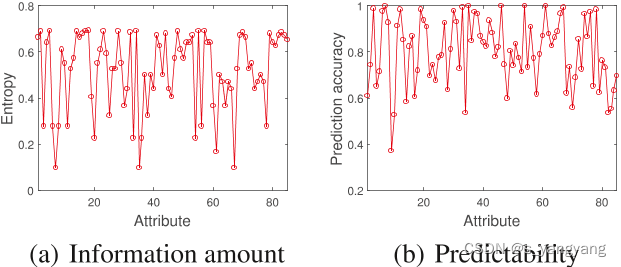
展示了ZSL基准中的属性具有不同的特性,包括信息量和可预测性。之前的ZSL工作忽视了这种多样性,将每个属性等同对待,受到“噪声”属性的影响。因此,它们的准确性受到限制。
-
提出了一种针对ZSL的属性选择框架。通过在联合优化框架中同时考虑每个属性的信息量和可预测性,选择最有价值的属性用于改善后续ZSL分类模型的准确性。
-
将属性选择方法与几种ZSL分类模型结合起来。对四个基准数据集进行实验,展示了最先进的性能,并且确实通过选定的属性以可观的边际改善了ZSL的准确性,验证了提出的属性选择方法的功效和必要性。
三、相关工作
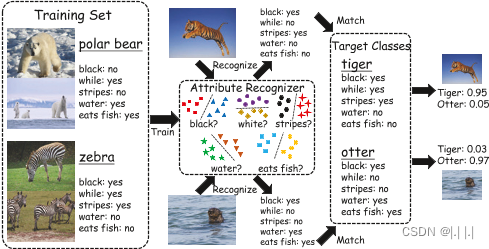
1. 零样本学习通常包含的两个步骤:
1.1 特征嵌入或属性识别:
在特征嵌入或属性识别阶段,通过将输入映射到属性空间中并使用属性识别器进行识别。
1.2 属性匹配:
在属性匹配阶段,将识别的属性与目标类别进行匹配。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









