






基于Docker的拓扑网络搭建可行性探究
文章目录
摘要:原目的为通过Docker来搭建一个与实际网络类似的大型拓扑网络,经过对Docker网络的实际认知和隔离机制的探究,发现利用Docker至多在单主机上多做一层子网,子网间的通信也存在一定的限制,容器网络本身有一定的局限性。
引入
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的镜像中,然后发布到任何流行的 Linux或Windows操作系统的机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。容器(container):一种软件实体,其将应用程序及运行环境进行打包和虚拟化部署。容器可以共享对操作系统内核的访问,而不需要针对每个应用程序对完整的操作系统进行虚拟化 。镜像(images):是应用程序完整的、静态的可执行版本。镜像与容器之间的关系可以近似理解为类与实例的关系。
由于容器是可以单独运行的应用程序,含有一定的网络协议栈,而容器本身所需的资源远低于虚拟机,因此想要基于此进行大型拓扑网络的构建。本文其余的部分为:Docker环境配置与容器选择,Docker网络,实验1:不同网段通信尝试,容器网络隔离机制探究,实验2:实现不同子网的相互转发,实验3:尝试利用容器中继转发,以及最终的结论。
Docker环境配置与容器选择
本文中的Docker是在基于centos7的Linux系统上运行的,因此使用命令行进行安装。
#!/bin/bash
# 移除掉旧的版本
sudo yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-selinux \
docker-engine-selinux \
docker-engine
# 删除所有旧的数据
sudo rm -rf /var/lib/docker
# 安装依赖包
sudo yum install -y yum-utils \
device-mapper-persistent-data \
lvm2
# 添加源,使用了阿里云镜像
sudo yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 配置缓存
sudo yum makecache fast
# 安装最新稳定版本的docker
sudo yum install -y docker-ce
# 配置镜像加速器
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["http://hub-mirror.c.163.com"]
}
EOF
# 启动docker引擎并设置开机启动
sudo systemctl start docker
sudo systemctl enable docker
# 配置当前用户对docker的执行权限
sudo groupadd docker
sudo gpasswd -a ${USER} docker
sudo systemctl restart docker
本文中可能使用的基本命令为:Docker镜像的拉取,Docker容器的创立与删除等,Docker网络的配制,路由相关的命令。
Image 命令 (镜像相关)
镜像本地查看
docker images: 显示中的Tag表示版本号[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3DglLHXr-1668765312468)(C:\Users\n4198\AppData\Roaming\Typora\typora-user-images\image-20220907224604621.png)]
镜像搜索
docker search image_name: image_name 为搜索镜像名称镜像下载
docker pull image_name(:TAG): 默认下载最新版本(无tag版本),可以在官方网站dockerhub查看版本信息是否支持镜像删除
docker rmi IMAGE_ID: 通过ID进行删除,rmi=remove images镜像全部删除
docker rmi 'docker image -q':docker image -q表示 显示所有镜像id
-q可以显示IMAGE_ID
Container命令(容器相关)
容器运行/容器创建
docker run创建方法1:
docker run (-i -t --name=c1) image:tag:-i表示一直运行,-t表示分配终端,docker run -it --name=c1 centos:7 /bin/bash后台创建容器,并不进入
docker run -id --name=c2 centos:7 进入容器 docker exec -it c2 /bin/bash
查看容器
docker ps (-a):-a添加后出现历史创建容器停止容器
docker stop container_name运行容器
docker start container_name删除容器
docker rm container_name/container_ID删除所有容器:
docker rm 'docker ps -aq'查看容器信息
docker inspect container_name,可以查看网关等
route指令,用于配置路由和观察路由
网络联通测试指令:ping、traceroute
容器选择与配置
本文中实验选取的镜像有两种:Centos镜像与Tomcat镜像,两者本身有一定的网络协议栈,但缺乏一定的网络工具。
对于Centos镜像:docker exec -it c2 yum install net-tools 即为在centos容器中安装route等工具;进入容器调用traceroute发现无此命令,利用yum安装yum install -y traceroute
对于Tomcat镜像:apt update && apt install -y iproute2 && apt install -y net-tools && apt install -y iputils-ping即为在unbunt系统下的tomcat容器安装ping,route等工具,apt install -y traceroute安装traceroute工具
Docker网络
实际网络协议栈
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Kt9rDvtU-1668765312469)(C:\Users\n4198\AppData\Roaming\Typora\typora-user-images\image-20221115230523352.png)]
实际关注拓扑网络时,关注的是网络层相关,即IP协议与ICMP协议相关和路由器等设备,但实际过程中也涉及到数据链路层的相关配置和防火墙。本文中实验主要关注路由器的原理,交换机的作用和网卡起到的作用。
网卡,虚拟网卡与veth
网卡是一块被设计用来允许计算机在计算机网络上进行通讯的计算机硬件。由于其拥有MAC地址,因此属于OSI模型的第1层和2层之间。它使得用户可以通过电缆或无线相互连接。网卡的功能主要有两个:一是将电脑的数据封装为帧,并通过网线(对无线网络来说就是电磁波)将数据发送到网络上去;二是接收网络上其它设备传过来的帧,并将帧重新组合成数据,发送到所在的电脑中。
在Linux中, 我们可以通过ifconfig -a或者ip addr看到主机上的所有网络接口,它有两种来源,一种是物理网卡的驱动程序创建的,另一种是内核自己或者用户主动创建的虚拟接口。
注意IP与网卡的关系:IP地址属于主机,但我们配置都是在网卡上配置IP地址。
虚拟网卡:前面提到Linux可以通过内核创建虚拟接口,也提供对应的IP地址,是通过linux上的tun/tap技术实现的。Docker每创建一个子网段和联网的容器都会添加虚拟接口或者虚拟网卡(可以通过ipaddr观察)。
VETH(Virtual Ethernet )是Linux提供的另外一种特殊的网络设备,中文称为虚拟网卡接口。它总是成对出现,要创建就创建一个pair。一个Pair中的veth就像一个网络线缆的两个端点,数据从一个端点进入,必然从另外一个端点流出。每个veth都可以被赋予IP地址,并参与三层网络路由过程,可以实现不同netns之间网络通信。
Docker0网络
Docker0网络是Docker运行容器默认接入的子网,其内容如下
docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:e7:50:a6:c5 brd ff:ff:ff:ff:ff:ff
inet 172.17.0.1/16 brd 172.17.255.255 scope global docker0
valid_lft forever preferred_lft forever
inet6 fe80::42:e7ff:fe50:a6c5/64 scope link
valid_lft forever preferred_lft forever
docker0作为docker桥接模式下的默认子网,其本质是一个Linux网桥,docker则是将这个网桥的创立和容器的链接更进一步的用一行语句实现。
网桥与端口的具体编程实现原理可以参考Linux网桥工作原理与实现(基于 Linux-2.4.0已更新) - Smah - 博客园 (cnblogs.com),简单来说,是通过程序建立一个逻辑上实现的网桥对象,利用前面提到的veth接口将容器端的网卡与网桥进行链接,如下图所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-90LRptw9-1668765312469)(C:\Users\n4198\AppData\Roaming\Typora\typora-user-images\image-20221117230340682.png)]
对于容器而言,eth0是内部的网卡,在生成容器是自动生成对应ip,当然实际运行中也可以指定。对于宿主机而言,创建容器则是多添加了一个veth设备连接在docker0网桥上,在实际数据包传输时则是通过veth建立的对应表的MAC地址进行转发。
若搭建多个子网下的容器相互通信,官方文档提供的最直接的方法是将容器与多个子网相连,则该容器可以访问多个子网。但初始情况下不同子网是隔离的,并且同时有多个ip进行多个子网的访问也与搭建拓扑网络的期望不符,因此进一步探究了docker网络的隔离机制。
Docker网络隔离情况
创建子网和容器的命令如下所示。
创建网段的命令为:
docker network create -d bridge --gateway 172.19.0.1 --subnet 172.19.0.0/16 mynet3,该命令表示创建一个bridge模式的子网段为172.19.0.0,网关为172.19.0.1,名字为mynet3的子网。创建网段下容器命令为:
docker run -id --name net2t1 --net mynet2 tomcat链接网段与容器的命令为:
docker network connect mynet2 c2,断开为docker network disconnect mynet2 c2删除网段/网卡命令为
docker network rm mynet2(需要无容器使用该网关)
实验1:不同网段通信尝试
| 容器名 | 子网名/网段 | 网卡/网关 | 容器对应IP |
|---|---|---|---|
| c3 | c3bridge / 172.17.0.0/16 | docker0 / 172.17.0.1 | 172.17.0.3 |
| net2t1 | mynet2 / 172.18.0.0/16 | br-09399b3a1f36 / 172.18.0.1 | 172.18.0.3 |
| net3t1 | mynet3 / 172.19.0.0/16 | br-eefe58242803 / 172.19.0.1 | 172.19.0.3 |
| c2 | bridge/mynet2/meynt3 | 均有 | 172.**.0.2 |
在创建完不同子网后,尝试进行不同子网间容器的通信,发现一个有趣的现象:利用一个子网中的容器去ping通其他子网的容器是行不通的,即使是试图联通到,但是ping通其他子网的网关是可以的。
[root@localhost ~]# docker exec -it c3 ping 172.19.0.2
PING 172.19.0.2 (172.19.0.2) 56(84) bytes of data.
^Cs
--- 172.19.0.2 ping statistics ---
6 packets transmitted, 0 received, 100% packet loss, time 5029ms
[root@localhost ~]# docker exec -it c3 ping 172.19.0.1
PING 172.19.0.1 (172.19.0.1) 56(84) bytes of data.
64 bytes from 172.19.0.1: icmp_seq=1 ttl=64 time=0.040 ms
理论上这说明不同子网间的沟通是存在可能的,但实际操作中却不行。因此进一步利用traceroute进行探究,发现并没有出现网关之间的转发这一现象,实际过程只有一跳。
[root@localhost ~]# docker exec -it net2t1 traceroute 172.17.0.1
traceroute to 172.17.0.1 (172.17.0.1), 30 hops max, 60 byte packets
1 _gateway (172.17.0.1) 0.041 ms 0.005 ms 0.003 ms
然后我尝试利用跨子网的容器c2作为中介路由进行转发route add -net 172.18.0.0/16 gw 172.19.0.2 ,发现可以连接到c2,该却发现traceroute无法跳转到另一子网下的该容器ip,发送到容器的数据无法进一步传输。
[root@localhost ~]# docker exec -it net3t1 traceroute 172.18.0.2
traceroute to 172.18.0.2 (172.18.0.2), 30 hops max, 60 byte packets
1 172.19.0.1 (172.19.0.1) 0.037 ms 0.004 ms 0.003 ms
2 172.18.0.2 (172.18.0.2) 0.027 ms 0.006 ms 0.005 ms
[root@localhost ~]# docker exec -it net3t1 traceroute 172.18.0.3
traceroute to 172.18.0.3 (172.18.0.3), 30 hops max, 60 byte packets
1 172.19.0.1 (172.19.0.1) 0.034 ms 0.004 ms 0.003 ms
2 c2.mynet3 (172.19.0.2) 0.014 ms 0.005 ms 0.005 ms
3 * * *
一开始我以为是网卡之间无法相互转发,锁死在这一容器内,因此进行查验。 Linux系统的IP转发的意思是,当Linux主机存在多个网卡的时候,允许一个网卡的数据包转发到另外一张网卡;在linux系统中默认禁止IP转发功能,可以打开如下文件查看,如果值为0说明禁止进行IP转发。
[root@localhost ~]# cat /proc/sys/net/ipv4/ip_forward
1
说明允许网卡之间相互转发,这说明问题不在网卡转发上面,而应当是容器内部的路由无法更改,导致容器和作为网关的宿主机之间来回转发造成反复转发的死循环。因此从路由上进行容器转发
容器网络隔离机制探究
为了实现互不影响的运行需要,命名空间(namespace)提供了一种不同的解决方案,只使用一个内核在一台物理计算机上运作,所有全局资源都通过命名空间抽象起来。这使得可以将一组进程放置到容器中,各个容器彼此隔离。
Linux Namespace: Network
在 Linux 中,网络名字空间可以被认为是隔离的拥有单独网络栈(网卡、路由转发表、iptables)的环境。网络名字空间经常用来隔离网络设备和服务,只有拥有同样网络名字空间的设备,才能看到彼此。而Docker就是利用Linux的网络命名空间进行隔离,该种隔离下,docker却又能实现不同网关的转发,说明隔离不再命名空间上,经查询,发现是Docker在创立不同子网时同时对防火墙(iptables管理)进行了配置,使转发失效。
iptables解读
iptables是什么?netfilter/iptables(简称为iptables)组成Linux平台下的包过滤防火墙。传输流程如图所示:当一个数据包进入网卡时,它首先进入PREROUTING链,内核根据数据包目的IP判断是否需要转送出去。
如果判断目的地是本机:沿着图向下移动,到达INPUT链。数据包到了INPUT链后,任何进程都会收到它。本机上运行的程序可以发送数据包,这些数据包会经过OUTPUT链,然后到达POSTROUTING链输出。
如果是转发,并且内核允许转发: 向右移动,经过FORWARD链,然后到达POSTROUTING链输出。
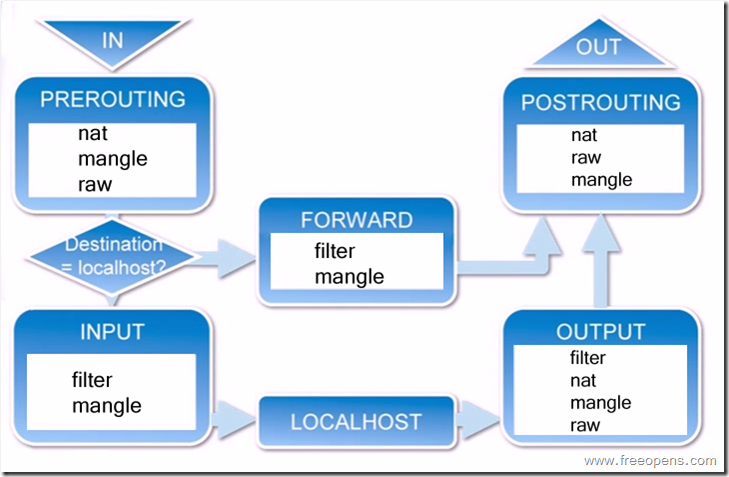
PREROUTING的应用
一般情况下,PREROUTING应用在普通的NAT中(也就是SNAT),如:你用ADSL上网,这样你的网络中只有一个公网IP地址(如:61.129.66.5),但你的局域网中的用户还要上网(局域网IP地址为:192.168.1.0/24),这时你可以使用PREROUTING(SNAT)来将局域网中用户的IP地址转换成61.129.66.5,使他们也可以上网:
iptables -t nat -A PREROUTING -s 192.168.1.0/24 -j SNAT 61.129.66.5
POSTROUTING的应用
POSTROUTING用于将你的服务器放在防火墙之后,作为保护服务器使用,例如:
A.你的服务器IP地址为:192.168.1.2;
B.你的防火墙(Linux & iptables)地址为192.168.1.1和202.96.129.5
Internet上的用户可以正常的访问202.96.129.5,但他们无法访问192.168.1.2,这时在Linux防火墙里可以做这样的设置:
iptables -t nat -A POSTROUTING -d 202.96.129.5 -j DNAT 192.168.1.2
iptables的规则链和表
表(tables):提供特定的功能,iptables内置了4个表,即filter表、nat表、mangle表和raw表,分别用于实现包过滤,网络地址转换、包重构(修改)和数据跟踪处理。
链(chains):是数据包传播的路径,每一条链其实就是众多规则中的一个检查清单,每一条链中可以有一条或数条规则。当一个数据包到达一个链时,iptables就会从链中第一条规则开始检查,看该数据包是否满足规则所定义的条件。如果满足,系统就会根据该条规则所定义的方法处理该数据包;否则iptables将继续检查下一条规则,如果该数据包不符合链中任一条规则,iptables就会根据该链预先定义的默认策略来处理数据包。
规则表优先级: Raw——mangle——nat——filter
1.filter表——三个链:INPUT、FORWARD、OUTPUT
作用:过滤数据包 内核模块:iptables_filter.
2.Nat表——三个链:PREROUTING、POSTROUTING、OUTPUT
作用:用于网络地址转换(IP、端口) 内核模块:iptable_nat
3.Mangle表——五个链:PREROUTING、POSTROUTING、INPUT、OUTPUT、FORWARD
作用:修改数据包的服务类型、TTL、并且可以配置路由实现QOS内核模块:iptable_mangle(别看这个表这么麻烦,咱们设置策略时几乎都不会用到它)
4.Raw表——两个链:OUTPUT、PREROUTING
作用:决定数据包是否被状态跟踪机制处理 内核模块:iptable_raw
规则链
1.INPUT——进来的数据包应用此规则链中的策略
2.OUTPUT——外出的数据包应用此规则链中的策略
3.FORWARD——转发数据包时应用此规则链中的策略
4.PREROUTING——对数据包作路由选择前应用此链中的规则
(记住!所有的数据包进来的时侯都先由这个链处理)
5.POSTROUTING——对数据包作路由选择后应用此链中的规则
(所有的数据包出来的时侯都先由这个链处理)
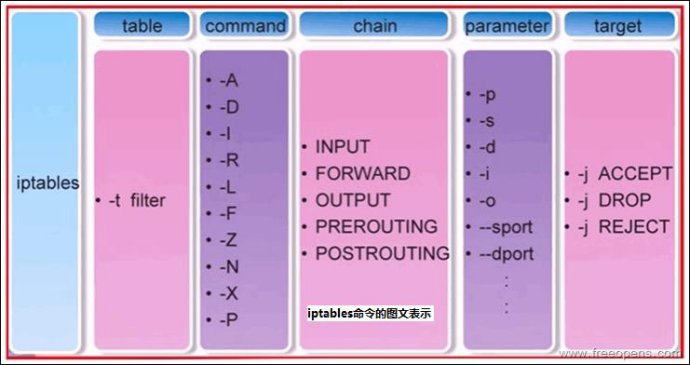
上图表示iptables的命令格式:iptables [-t 表名] 命令选项 [链名] [条件匹配] [-j 目标动作或跳转]

观察解析形式下的iptables规则
iptables -save或者iptables -S : Print the rules in a chain or all chains。Docker在FORWARD链下一跳中,还额外提供了自己的链,以实现bridge网络之间的隔离与通信。
可以看到Docker提供的链:DOCKER,DOCKER-ISOLATION-STAGE-1,DOCKER-ISOLATION-STAGE-2,DOCKER-USER
DOCKER:仅处理从宿主机到docker0的IP数据包。
DOCKER-ISOLATION-STAGE-1:
DOCKER-ISOLATION-STAGE-2:
可以看到,为了隔离在不同的bridge网络之间的容器,Docker提供了两个DOCKER-ISOLATION阶段实现。
DOCKER-ISOLATION-STAGE-1链过滤源地址是bridge网络(默认docker0)的IP数据包,匹配的IP数据包再进入DOCKER-ISOLATION-STAGE-2链处理,不匹配就返回到父链FORWARD。
DOCKER-USER:
Docker启动时,会加载DOCKER链和DOCKER-ISOLATION(现在是DOCKER-ISOLATION-STAGE-1)链中的过滤规则,并使之生效。绝对禁止修改这里的过滤规则。
如果用户要补充Docker的过滤规则,强烈建议追加到DOCKER-USER链。DOCKER-USER链中的过滤规则,将先于Docker默认创建的规则被加载,从而能够覆盖Docker在DOCKER链和DOCKER-ISOLATION链中的默认过滤规则。例如,Docker启动后,默认任何外部source IP都被允许转发,从而能够从该source IP连接到宿主机上的任何Docker容器实例。如果只允许一个指定的IP访问容器实例,可以插入路由规则到DOCKER-USER链中,从而能够在DOCKER链之前被加载。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yrkyuHK3-1668765312471)(C:\Users\n4198\AppData\Roaming\Typora\typora-user-images\image-20221118121929734.png)]
这三条链的插入位置如图所示。但是DOCKER相关的链都提供了对应的RETURN,当不存在符合规则转发时,会依次执行到FORWARD链,如果存在符合规则的转发(ACCEPT或DROP),则会直接执行。
[root@localhost ~]# iptables-save
# Generated by iptables-save v1.4.21 on Wed Nov 9 23:28:33 2022
*security
:INPUT ACCEPT [51:5047]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [18:6044]
COMMIT
# Completed on Wed Nov 9 23:28:33 2022
# Generated by iptables-save v1.4.21 on Wed Nov 9 23:28:33 2022
*mangle #MANGLE表
:PREROUTING ACCEPT [382:41449]
:INPUT ACCEPT [382:41449]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [255:44868]
:POSTROUTING ACCEPT [293:52709]
-A POSTROUTING -o virbr0 -p udp -m udp --dport 68 -j CHECKSUM --checksum-fill
COMMIT
# Completed on Wed Nov 9 23:28:33 2022
# Generated by iptables-save v1.4.21 on Wed Nov 9 23:28:33 2022
*nat #NAT表
:PREROUTING ACCEPT [42:6971]
:INPUT ACCEPT [42:6971]
:OUTPUT ACCEPT [151:11451]
:POSTROUTING ACCEPT [151:11451]
:DOCKER - [0:0]
-A PREROUTING -m addrtype --dst-type LOCAL -j DOCKER #-m表示match 输入的目的地为Local,转入DOCKER链
-A OUTPUT ! -d 127.0.0.0/8 -m addrtype --dst-type LOCAL -j DOCKER # 用于处理本机产生的数据包,非本机的转到Docker?
-A POSTROUTING -s 172.17.0.0/16 ! -o docker0 -j MASQUERADE #MASQUERADE用于自动SNAT转换,来自17子网,输出非docker0,进行NAT转换(转换为前往下一跳网关的网卡?)
-A POSTROUTING -s 172.19.0.0/16 ! -o br-eefe58242803 -j MASQUERADE # 同上,问题在于会转化成啥
-A POSTROUTING -s 172.18.0.0/16 ! -o br-09399b3a1f36 -j MASQUERADE
-A POSTROUTING -s 192.168.122.0/24 -d 224.0.0.0/24 -j RETURN
-A POSTROUTING -s 192.168.122.0/24 -d 255.255.255.255/32 -j RETURN
-A POSTROUTING -s 192.168.122.0/24 ! -d 192.168.122.0/24 -p tcp -j MASQUERADE --to-ports 1024-65535
-A POSTROUTING -s 192.168.122.0/24 ! -d 192.168.122.0/24 -p udp -j MASQUERADE --to-ports 1024-65535
-A POSTROUTING -s 192.168.122.0/24 ! -d 192.168.122.0/24 -j MASQUERADE
-A DOCKER -i docker0 -j RETURN #如果输入为docker下子网,均终止调用
-A DOCKER -i br-eefe58242803 -j RETURN
-A DOCKER -i br-09399b3a1f36 -j RETURN
COMMIT
# Completed on Wed Nov 9 23:28:33 2022
# Generated by iptables-save v1.4.21 on Wed Nov 9 23:28:33 2022
*filter #过滤器表
:INPUT ACCEPT [357:36652]
:FORWARD ACCEPT [0:0]
:OUTPUT ACCEPT [226:40774]
:DOCKER - [0:0]
:DOCKER-ISOLATION-STAGE-1 - [0:0]
:DOCKER-ISOLATION-STAGE-2 - [0:0]
:DOCKER-USER - [0:0]
#INPUT表示为目标为本机时处理,下一链为OUTPUT,再下一链为POSTROUTE
-A INPUT -i virbr0 -p udp -m udp --dport 53 -j ACCEPT
-A INPUT -i virbr0 -p tcp -m tcp --dport 53 -j ACCEPT
-A INPUT -i virbr0 -p udp -m udp --dport 67 -j ACCEPT
-A INPUT -i virbr0 -p tcp -m tcp --dport 67 -j ACCEPT
#FORWORD为目标非本机时使用
-A FORWARD -j DOCKER-USER #DOCKER-USER最高优先级
-A FORWARD -j DOCKER-ISOLATION-STAGE-1 #其次为自带的DOCKER-ISOLATION-STAGE-1
#四条基础规则 conntrack:状态跟踪,
-A FORWARD -o docker0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o docker0 -j DOCKER
-A FORWARD -i docker0 ! -o docker0 -j ACCEPT
-A FORWARD -i docker0 -o docker0 -j ACCEPT
-A FORWARD -o br-eefe58242803 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o br-eefe58242803 -j DOCKER
-A FORWARD -i br-eefe58242803 ! -o br-eefe58242803 -j ACCEPT
-A FORWARD -i br-eefe58242803 -o br-eefe58242803 -j ACCEPT
-A FORWARD -o br-09399b3a1f36 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -o br-09399b3a1f36 -j DOCKER
-A FORWARD -i br-09399b3a1f36 ! -o br-09399b3a1f36 -j ACCEPT
-A FORWARD -i br-09399b3a1f36 -o br-09399b3a1f36 -j ACCEPT
-A FORWARD -d 192.168.122.0/24 -o virbr0 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
-A FORWARD -s 192.168.122.0/24 -i virbr0 -j ACCEPT
-A FORWARD -i virbr0 -o virbr0 -j ACCEPT
-A FORWARD -o virbr0 -j REJECT --reject-with icmp-port-unreachable
-A FORWARD -i virbr0 -j REJECT --reject-with icmp-port-unreachable
-A OUTPUT -o virbr0 -p udp -m udp --dport 68 -j ACCEPT
#Docker子网通信需要关注的规则,简单来说,非本子网通信本子网所有的包都丢弃
-A DOCKER-ISOLATION-STAGE-1 -i docker0 ! -o docker0 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-eefe58242803 ! -o br-eefe58242803 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -i br-09399b3a1f36 ! -o br-09399b3a1f36 -j DOCKER-ISOLATION-STAGE-2
-A DOCKER-ISOLATION-STAGE-1 -j RETURN
-A DOCKER-ISOLATION-STAGE-2 -o docker0 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -o br-eefe58242803 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -o br-09399b3a1f36 -j DROP
-A DOCKER-ISOLATION-STAGE-2 -j RETURN
-A DOCKER-USER -j RETURN
COMMIT
# Completed on Wed Nov 9 23:28:33 2022
通过分析以上过程和图,可以看到DOCKER-USER和 DOCKER-ISOLATION-STAGE和原本的FORWARD共同替代了原本FORWARD的位置,并且DOCKER相关的命令处理优先级更高。
实验2:实现不同子网的相互转发
了解到这一点后,就可以尝试调整iptables对Docker的转发规则进行修改,注意到隔离机制主要是通过DOCKER-ISOLATION-STAGE的两个链实现,而DOCKER-USER链优先级更高,因此通过修改该链进行配置是较好的方法。
| 容器名 | 子网名/网段 | 网卡/网关 | 容器对应IP |
|---|---|---|---|
| c3 | c3bridge / 172.17.0.0/16 | docker0 / 172.17.0.1 | 172.17.0.3 |
| net2t1 | mynet2 / 172.18.0.0/16 | br-09399b3a1f36 / 172.18.0.1 | 172.18.0.3 |
| net3t1 | mynet3 / 172.19.0.0/16 | br-eefe58242803 / 172.19.0.1 | 172.19.0.3 |
| c2 | bridge/mynet2/meynt3 | 均有 | 172.**.0.2 |
对iptables调整的命令如下:首先删除进入DOCKER-USER后立即返回的指令iptables -D DOCKER-USER -j RETURN,方便后续添加不同网桥转发允许的指令:
iptables -A DOCKER-USER -i docker0 ! -o docker0 -j ACCEPT
iptables -A DOCKER-USER -i br-09399b3a1f36 ! -o br-09399b3a1f36 -j ACCEPT
iptables -A DOCKER-USER -i br-eefe58242803 ! -o br-eefe58242803 -j ACCEPT
最终将iptables -A DOCKER-USER -j RETURN删除掉的指令加上,防止iptables出现逻辑错误。
进行修正后,发现转发符合原本路由指向。
[root@localhost ~]# docker exec -it net3t1 traceroute 172.18.0.3
traceroute to 172.18.0.3 (172.18.0.3), 30 hops max, 60 byte packets
1 172.19.0.1 (172.19.0.1) 0.033 ms 0.004 ms 0.003 ms
2 172.18.0.3 (172.18.0.3) 0.077 ms 0.018 ms 0.005 ms
但是仍有一个有趣的事情,对于mynet2的子网转发,中间并没有172.18.0.1的网关通过,而是直接转入到172.18.0.3的net2t1上,说明仍然完全模拟转发。这一点仍然难以操作。
实验3:尝试利用容器中继进行转发
| 容器名 | 子网名/网段 | 网卡/网关 | 容器对应IP |
|---|---|---|---|
| net2t2 | mynet2 / 172.18.0.0/16 | 172.18.0.3 | 18.0.4 |
| c3 | bridge / 172.17.0.0/16 | docker0 / 172.17.0.1 | 172.17.0.3 |
| net2t1 | mynet2,mynet3 | br-09399b3a1f36 / 172.18.0.1 | 172.18.0.3/19.0.4 |
| net3t1 | mynet3 / 172.19.0.0/16 | br-eefe58242803 / 172.19.0.1 | 172.19.0.3 |
| c2 | bridge/mynet2/meynt3 | 均有 | 172.**.0.2 |
针对进入到容器内发现难以修改路由这一点,创建root权限的容器尝试进行中转。 docker run -it --privileged=true -u=root --name=net2t2 --net=mynet2 tomcat /bin/bash
通过配置容器路由,使该容器不直接向默认网关发送转发 docker exec -it net2t2 route add -net 172.19.0.0/16 gw 172.18.0.3。但如此配置后,在容器内试图进行转发到mynet3子网网关,结果如下:
[root@localhost ~]# docker exec -it net2t2 traceroute 172.19.0.1
traceroute to 172.19.0.1 (172.19.0.1), 30 hops max, 60 byte packets
1 net2t1.mynet2 (172.18.0.3) 0.081 ms 0.007 ms 0.005 ms
2 * * *
3 * * *
#net2t1为18子网下的容器
[root@localhost ~]# docker exec -it net2t1 traceroute 172.19.0.2
traceroute to 172.19.0.2 (172.19.0.2), 30 hops max, 60 byte packets
1 172.18.0.1 (172.18.0.1) 0.044 ms 0.005 ms 0.003 ms
2 172.19.0.2 (172.19.0.2) 0.031 ms 0.008 ms 0.007 ms
仍然无法实现转发,进入到net2t1容器内进行对应iptables查询和网卡转发查询,均发现无障碍设置,因此推测存在其他难以发现的底层操作。
考虑到容器无法作为中继,将容器net2t1与mynet3解除链接,查看默认发往宿主机情况下的中继。
[root@localhost ~]# docker exec -it net2t2 traceroute 172.19.0.3
traceroute to 172.19.0.3 (172.19.0.3), 30 hops max, 60 byte packets
1 net2t1.mynet2 (172.18.0.3) 0.061 ms 0.014 ms 0.013 ms
2 172.18.0.1 (172.18.0.1) 0.018 ms 0.012 ms 0.013 ms
3 172.19.0.3 (172.19.0.3) 0.062 ms 0.020 ms 0.039 ms
若恢复宿主机的隔离情况,则失败情况如下:
[root@localhost ~]# iptables -D DOCKER-USER -i br-09399b3a1f36 ! -o br-09399b3a1f36 -j ACCEPT
[root@localhost ~]# docker exec -it net2t2 traceroute 172.19.0.3
traceroute to 172.19.0.3 (172.19.0.3), 30 hops max, 60 byte packets
1 net2t1.mynet2 (172.18.0.3) 0.102 ms 0.009 ms 0.007 ms
2 172.18.0.1 (172.18.0.1) 0.023 ms 0.007 ms 0.005 ms
3 * * *
结论
不同子网间至多做到相互联系,宿主机像是一台交换机,含有不同的网卡,经调整iptables后,可以相互转发。
但容器无法做到相互转发,至多借助解除隔离的宿主机进行一次跳转转发,考虑到这点至多借助Docker做一个简单的一层子网,无法借助容器跨越隔离的子网。
参考:
1.iptables详解及一些常用规则 - 简书 (jianshu.com)
2.Linux prerouting和postrouting的区别 - Dus - 博客园 (cnblogs.com)
3.(12条消息) Linux iptables命令详解_一口Linux的博客-CSDN博客_iptable命令
4.【Docker】关于Docker网络隔离与通信详解 - 踏雪无痕SS - 博客园 (cnblogs.com)
5.iptables规则执行顺序 - 简书 (jianshu.com)
6.iptables conntrack - 扫驴 - 博客园 (cnblogs.com)
7.(13条消息) 虚拟网卡接口VETH(Virtual Ethernet )创建使用和绑定关系_Turbock的博客-CSDN博客_veth接口
8.(13条消息) Docker详解(十二)——Docker容器权限问题_永远是少年啊的博客-CSDN博客















 94
94











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









