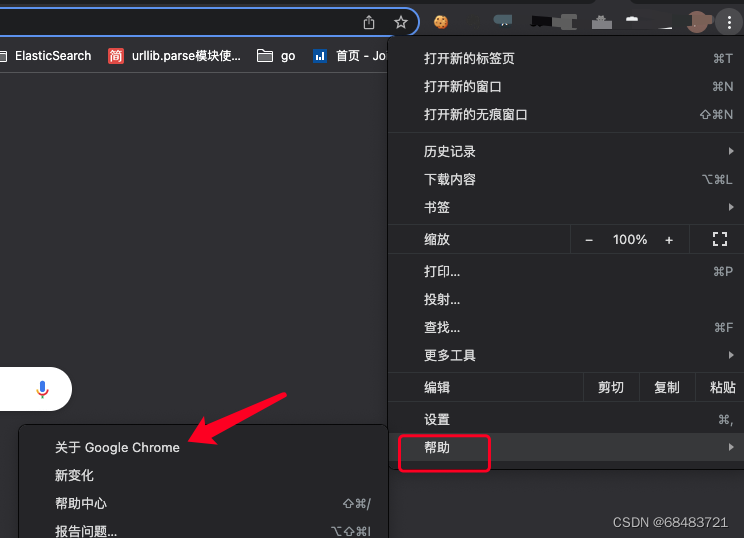
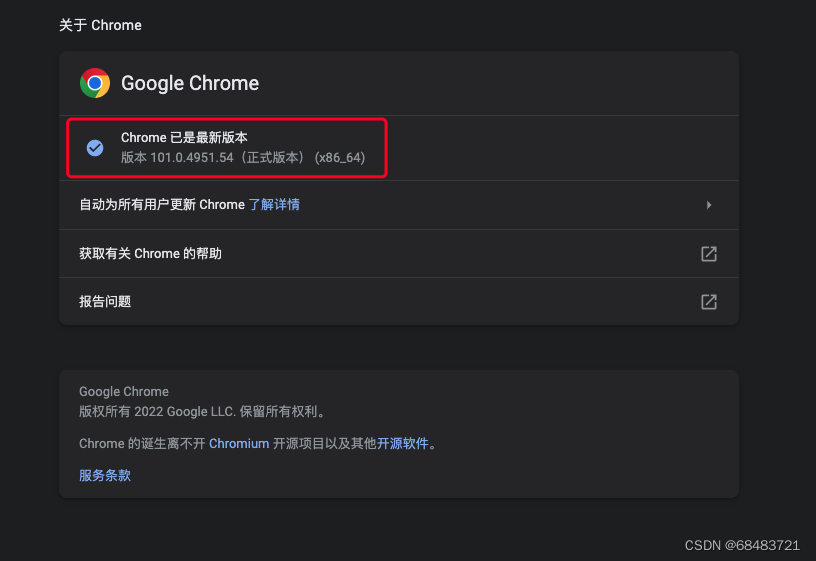
爬虫:查看Chrome版本







于 2022-05-07 22:10:58 首次发布
 1541
1651
3563
3万+
1541
1651
3563
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言