







安装
官方docker安装说明文档:https://github.com/alibaba/canal/wiki/Docker-QuickStart
组件介绍
canal.adapter
canal 1.1.1版本之后, 增加客户端数据落地的适配及启动功能, 目前支持功能:
客户端启动器
同步管理REST接口
日志适配器, 作为DEMO
关系型数据库的数据同步(表对表同步), ETL功能
HBase的数据同步(表对表同步), ETL功能
(后续支持) ElasticSearch多表数据同步,ETL功能
canal.admin
设计上是为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,方便更多用户快速和安全的操作
canal.deployer
这个就相当于canal的服务端,启动它才可以在客户端接收数据库变更信息。也是本文的重点,上面两个类似与这个的拓展
canal.example
是Canal提供的一个示例工程,用于演示如何整合使用Canal的各个组件。
配置数据库
如何开启mysql的binlog日志可看这个博客:biinlog是什么
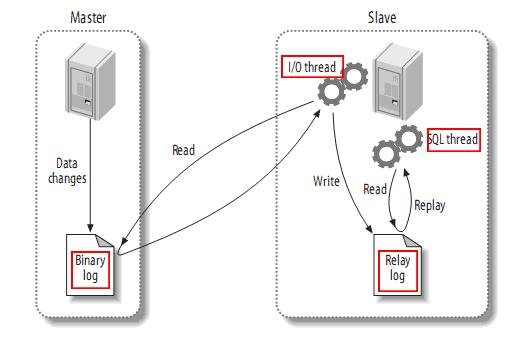
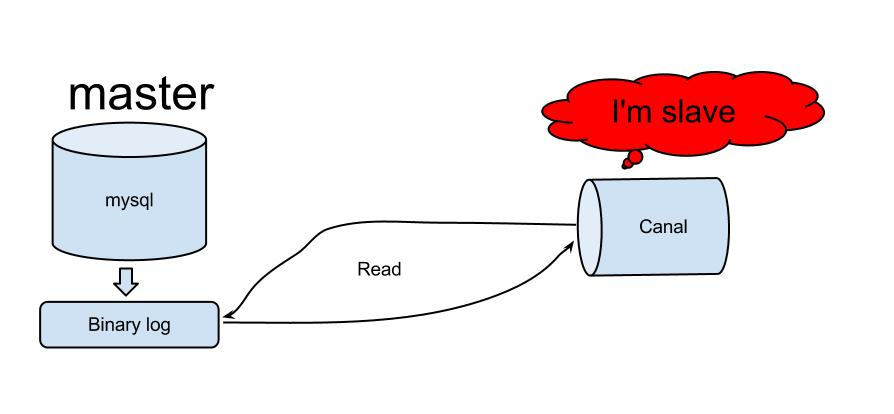
canal原理是伪装成mysql的从节点,并通过读取主库的binlog日志来同步数据的
主从同步原理图:
canal工作原理图:
创建canal用户
# 新建用户 用户名:canal 密码:canal
CREATE USER canal IDENTIFIED by 'canal';
# 授权
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
# 刷新MySQL的系统权限相关表
FLUSH PRIVILEGES;
docker安装
#安装这个镜像就相当于canal.deployer的功能
docker pull canal/canal-server:latest
#创建目录canal挂载的目录
mkdir -p /mydata/canal/conf
#先启动canal的docker
docker run -p 11111:11111 --name canal -d canal/canal-server:latest
#将容器内的配置文件copy到刚建的文件夹中
docker cp canal:/home/admin/canal-server/conf/example/instance.properties /mydata/canal/conf/
#删除刚才启动的容器
docker rm canal
#修改instance.properties配置文件
cd /mydata/canal/conf
vim instance.properties
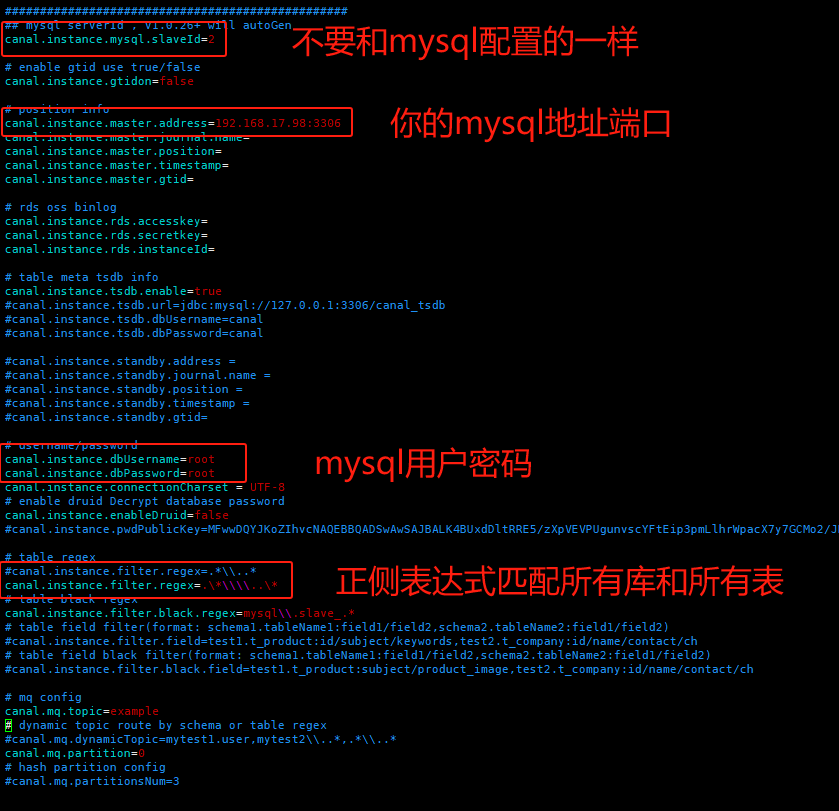
#挂载配置文件并启动
docker run -p 11111:11111 --name canal -v /mydata/canal/conf/instance.properties:/home/admin/canal-server/conf/example/instance.properties -d canal/canal-server:latest
#查看启动情况
docker logs -fn 100 canal
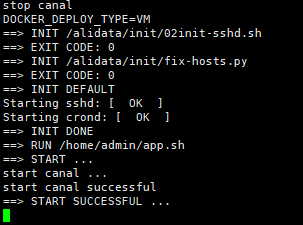
表示启动成功
程序测试
示例代码:https://github.com/alibaba/canal/wiki/ClientExample
账号官方教程引入依赖,编写代码测试,并启动
启动后控制台上
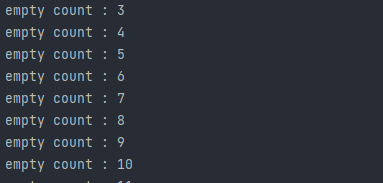
数据库修改数据后
会检测到变动,说明前面部署一切正常,可以开始编写后续逻辑
binlog:binlog文件名
name:库名表名
eventType:操作类型
下面的就是数据了
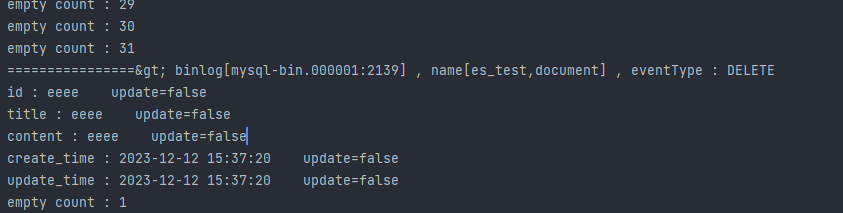
canal监听mysql数据同步elasticsearch
上文说到canal.adapter的功能中有同步es的功能所以这一步就需要使用到这个模块实现mysql数据同步es的功能
安装canal-adapter
在浏览量docker hub后发现官方没有发布该功能的容器,搜到的都是别人自己创建的容器(可能不是最新的)
所以这一步就直接使用压缩包来安装。
下载安装包
下载地址:https://github.com/alibaba/canal/releases/download/canal-1.1.7/canal.adapter-1.1.7.tar.gz
官方指导文档:https://github.com/alibaba/canal/wiki/Sync-ES
配置java环境
略
启动canal-adapter
#解压
tar -zxvf canal.adapter-1.1.7.tar.gz
#修改applincation.yml
vim application.yml
#未注释的改成和下面一样
###################################分割线###################################
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ
flatMessage: true
zookeeperHosts:
syncBatchSize: 1000
retries: -1
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer 这个改成你canal-server的地址,我这里是本机
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer 这里可以不用配置,原来的也不用删,不影响
kafka.bootstrap.servers: 127.0.0.1:9092
kafka.enable.auto.commit: false
kafka.auto.commit.interval.ms: 1000
kafka.auto.offset.reset: latest
kafka.request.timeout.ms: 40000
kafka.session.timeout.ms: 30000
kafka.isolation.level: read_committed
kafka.max.poll.records: 1000
# rocketMQ consumer 同上
rocketmq.namespace:
rocketmq.namesrv.addr: 127.0.0.1:9876
rocketmq.batch.size: 1000
rocketmq.enable.message.trace: false
rocketmq.customized.trace.topic:
rocketmq.access.channel:
rocketmq.subscribe.filter:
# rabbitMQ consumer 同上
rabbitmq.host:
rabbitmq.virtual.host:
rabbitmq.username:
rabbitmq.password:
rabbitmq.resource.ownerId:
#这里注意,原先是被注释掉的,这里是配置数据源,就是mysql的地址
srcDataSources:
defaultDS:
url: jdbc:mysql://192.168.17.98:3306/es_test?useUnicode=true
username: root
password: root
canalAdapters:
- instance: example # canal instance Name or mq topic name
groups:
- groupId: g1
outerAdapters:
- name: logger
#在conf目录下有三个文件夹,分别是es6、es7、es8,因为我使用es版本是7,所以我这里写es7
- name: es7
hosts: http://127.0.0.1:9200 # 127.0.0.1:9200 for rest mode
properties:
mode: rest # or rest
# security.auth: test:123456 # only used for rest mode
cluster.name: elasticsearch
###################################分割线###################################
#修改完application.yml需要修改es7目录下的配置,如果你的版本不是7请进入对应目录
cd es7
#修改mytest_user.yml
vim mytest_user.yml
###################################分割线###################################
# 源数据源的key, 对应上面配置的srcDataSources中的值
dataSourceKey: defaultDS
# cannal的instance或者MQ的topic
destination: example
# 对应MQ模式下的groupId, 只会同步对应groupId的数据
groupId: g1
esMapping:
# es 的索引名称,这等下可以手动创建索引
_index: documentv1
# es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
_id: _id
# upsert: true
# pk: id # 如果不需要_id, 则需要指定一个属性为主键属性
# sql映射,这里就是查询全表的sql
sql: "select a.id as _id, a.title as title , a.content as content , a.create_time as create_time, a.update_time as update_time from document a"
# objFields:
# _labels: array:;
# etl 的条件参数,adapter 的 ETL 接口为:/etl/{type}/{task} curl -X POST http://127.0.0.1:8081/etl/es7/sys_user.yml?params=更新时间
#默认web端口为 8081
#type 为类型(hbase/es7/rdb)
#task 为任务名对应配置文件名,如sys_user.yml
#etlCondition: "where a.update_time>={0}"
# 提交批大小
commitBatch: 3000
###################################分割线###################################
#配置完后进到bin目录下,启动
sh start.sh
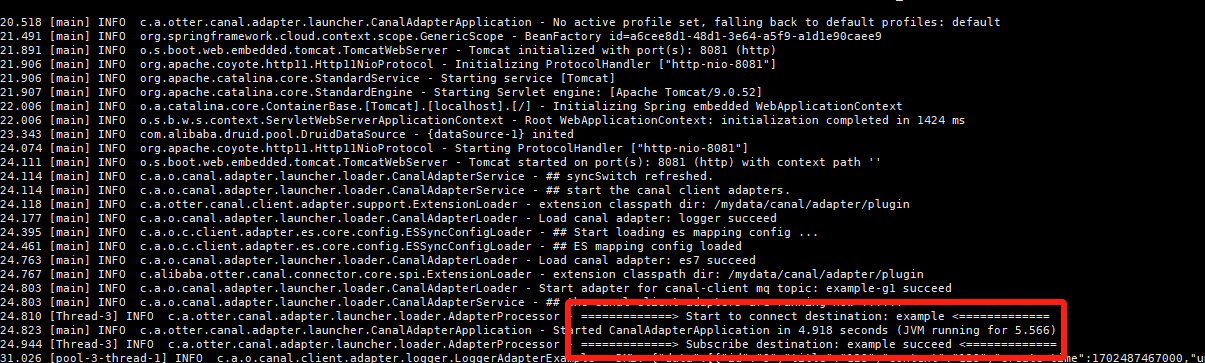
#查看日志,日志在logs/adapter目录下
启动截图
给es创建索引
//这个索引名称要和上面mytest_user.yml文件中配置的一样
PUT /documentv1
{
"mappings": {
"properties": {
"content": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"create_time": {
"type": "date"
},
"id": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"update_time": {
"type": "date"
}
}
}
}
在mysql中增、删、改一条数据观察日志
我修改了一条数据,日志中就会有一条信息

至此canal-server监听mysql然后通过canal-adapter同步到elasticsearch全链路已经完成。
















 1893
1893

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











