







3. 语法
本章涵盖了PDF在对象、文件和文档层面的所有语法知识。它为后续章节奠定了基础,后续章节将介绍如何把PDF文件的内容解释为页面描述、交互式导航辅助工具以及应用程序级别的逻辑结构。
PDF语法最好从四个部分来理解,如图3.1所示:
- 对象:PDF文档是一种数据结构,由一组基本数据对象类型构成。3.1节“词法约定”介绍了用于编写对象和其他语法元素的字符集。3.2节“对象”描述了对象的语法和基本属性。3.2.7节“流对象”则详细介绍了最复杂的数据类型——流对象。
- 文件结构:PDF文件结构决定了对象在PDF文件中的存储方式、访问方式以及更新方式。这种结构与对象的语义无关。3.4节“文件结构”描述了文件结构。3.5节“加密”介绍了一种文件级别的机制,用于保护文档内容不被未经授权访问。
- 文档结构:PDF文档结构规定了基本对象类型如何用于表示PDF文档的各个组成部分,如页面、字体、注释等。3.6节“文档结构”描述了整体的文档结构;后续章节将介绍各组成部分的详细语义。
- 内容流:PDF内容流包含一系列指令,用于描述页面或其他图形实体的外观。这些指令虽然也表示为对象,但在概念上与表示文档结构的对象不同,将单独进行介绍。3.7节“内容流和资源”讨论了PDF内容流及其相关资源。
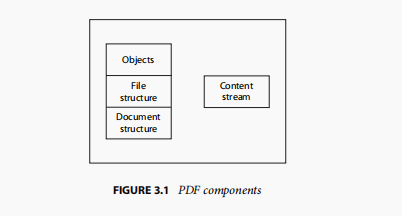
此外,本章还介绍了一些由基本对象构建的数据结构,这些数据结构应用广泛,几乎可被视作独立的基本对象类型。这些对象将在3.8节“常用数据结构”、3.9节“函数”和3.10节“文件规范”中进行介绍。
PDF的对象和文件语法也作为其他文件格式的基础,其中包括8.6.6节“表单数据格式”中介绍的表单数据格式(FDF),以及Adobe技术说明#5620《便携作业传票格式》中描述的便携作业传票格式(PJTF)。
3.1 词法约定
在最基本的层面上,PDF文件是一个8位字节序列。这些字节可以根据以下语法规则组合成标记(token)。一个或多个标记组合在一起,形成更高级别的语法实体,主要是对象(object),这些对象是构建PDF文档的基本数据值。
PDF可以完全使用与ASCII字符集中可见可打印子集对应的字节值来表示,还可以使用空格、制表符、回车符和换行符等空白字符。ASCII是美国信息交换标准代码,是一种广泛使用的将一组特定的128个字符编码为二进制数的约定。不过,PDF文件并不局限于ASCII字符集;它可以包含任意8位字节,但需考虑以下几点:
- 界定对象以及描述PDF文件结构的标记,都使用ASCII字符集书写,标准字典中用作键的所有保留字和名称也是如此。
- 某些类型对象(字符串和流)的数据值可以,但并非必须,完全用ASCII书写。为便于阐述(如在本书中),更倾向于使用ASCII表示法。然而,在实际应用中,诸如采样图像之类的自然二进制数据,为了紧凑和高效,会直接以二进制形式表示。
- 包含二进制数据的PDF文件必须以能忠实保留文件所有字节的方式进行传输和存储,即作为二进制文件而非文本文件。这样的文件无法移植到对保留字符代码、最大行长、行尾约定或其他方面有限制的环境中。
注:在本章中,“字符” 一词与 “字节” 同义,仅指特定的8位值。这种用法与该值在特定上下文中作为数据(如表示人类可读文本或从字体中选择字形)时可能具有的任何逻辑含义完全无关。
3.1.1 字符集
PDF字符集分为三类,即普通字符、定界符和空白字符。这种分类决定了字符如何组合成标记,但在字符串、流和注释中除外,在这些情况下适用不同的规则。
空白字符(见表3.1)用于分隔语法结构,如名称和数字。除在注释、字符串和流中之外,所有空白字符都是等效的。在其他所有上下文中,PDF将任何连续的空白字符序列视为单个字符。
表3.1 空白字符
| 十进制 | 十六进制 | 八进制 | 名称 |
|---|---|---|---|
| 0 | 00 | 000 | 空字符(NUL) |
| 9 | 09 | 011 | 制表符(HT) |
| 10 | 0A | 012 | 换行符(LF) |
| 12 | 0C | 014 | 换页符(FF) |
| 13 | 0D | 015 | 回车符(CR) |
| 32 | 20 | 040 | 空格(SP) |
回车符(CR)和换行符(LF),也称为换行标记,被视为行尾(EOL)标记。紧跟在回车符之后的换行符组合被视为单个行尾标记。在大多数情况下,行尾标记与其他任何空白字符的处理方式相同。然而,有时需要或建议使用行尾标记,即下一个标记必须出现在新的一行开头。
注:本书中的示例展示了一种推荐的将标记排列成行的约定。不过,示例中用于缩进的空白仅为了阐述清晰,实际使用中并不推荐。
定界符(, 、) 、< 、> 、[ 、] 、{ 、} 、/ 和 %)具有特殊意义。它们用于界定字符串、数组、名称和注释等语法实体。这些字符中的任何一个都会终止其前面的实体,并且不包含在该实体中。
除空白字符和定界符之外的所有字符都称为普通字符。这些字符包括ASCII字符集之外的8位二进制字符。连续的普通字符序列构成单个标记。
注:PDF区分大小写,相应的大写字母和小写字母被视为不同的字符。
3.1.2注释
在字符串或流之外,任何出现的百分号(%)都表示引入了一条注释。注释包含从百分号到行尾的所有字符,包括普通字符、定界符、空格和制表符。PDF会忽略注释,将其视为单个空白字符。也就是说,注释将其前面的标记与后面的标记分隔开;因此,PDF片段:
abc% comment { /% ) blah blah blah
123
在语法上等同于仅包含标记abc和123 。
注释(除了3.4节 “文件结构” 中描述的%PDF−n.m和%%EOF注释之外)没有语义。编辑PDF文件的应用程序不一定会保留注释(见附录H中的实现说明2)。特别是,PDF中没有与PostScript文档结构约定(DSC)等效的内容。
3.2 对象
PDF支持八种基本对象类型:
- 布尔值
- 整数和实数
- 字符串
- 名称
- 数组
- 字典
- 流
- 空对象
对象可以被标记,以便其他对象能够引用它们。被标记的对象称为间接对象。
以下各节将描述每种对象类型,以及如何创建和引用间接对象。
3.2.1 布尔对象
PDF提供布尔对象,通过关键字true和false来标识。布尔对象可以作为数组元素和字典条目的值,也可以在PostScript计算器函数中作为布尔和关系运算符的结果,以及条件运算符if和ifelse的操作数(见3.9.4节“类型4(PostScript计算器)函数”)。
3.2.2 数值对象
PDF提供两种数值对象类型:整数和实数。整数对象表示以0为中心的某个区间内的数学整数。实数对象用于近似数学实数,但范围和精度有限;它们通常以定点形式而非浮点形式表示。数字的范围和精度受运行PDF消费应用程序的计算机内部表示方式的限制;附录C给出了典型实现中的这些限制。
整数的书写形式是由一个或多个十进制数字组成,前面可选择性地加上正负号:
123 43445 +17 −98 0
该值会被解释为有符号十进制整数,并转换为整数对象。如果它超过了整数的实现限制,则会被转换为实数对象。
实数的书写形式是由一个或多个十进制数字组成,可选择性地加上正负号,并且包含前置、后置或嵌入的小数点:
34.5 −3.62 +123.6 4. −.002 0.0
该值会被解释为实数,并转换为实数对象。如果它超过了实数的实现限制,则会出错。
注:PDF不支持PostScript中数字的非十进制表示法(如16#FFFE)或指数表示法(如6.02E23)。
在本书中,术语“数字”指的是类型可以是整数或实数的对象。在需要实数的地方,可以使用整数代替,并且整数会自动转换为等效的实数值。例如,无需将数字1.0写成实数格式,整数1就足够了。
3.2.3 字符串对象
字符串对象由一系列字节组成,这些字节是取值范围在0到255之间的无符号整数值。字符串对象不是整数对象,而是以更紧凑的格式存储。字符串的长度可能会受到实现限制;详见附录C。
字符串对象有两种书写方式:
- 作为括在括号
()中的一系列文字字符,详见下文“文字字符串”。 - 作为括在尖括号
< >中的十六进制数据,详见第56页的“十六进制字符串”。
本节仅描述将字符串写为字节序列的基本语法。字符串有多种用途,并且可以有多种格式化方式。当字符串用于特定目的(例如表示日期)时,采用标准格式会很有用(见3.8.3节“日期”)。这些格式只是解释字符串内容的约定,并非独立的对象类型。使用特定格式的情况会在使用该格式的字符串对象定义中进行描述。
3.8.1节“字符串类型”介绍了用于字符串对象内容的编码方案。
- 文字字符串:文字字符串是由括在括号中的任意数量的字符组成。字符串中可以包含任何字符,除了不匹配的括号和反斜杠,反斜杠必须进行特殊处理。字符串中匹配的括号对无需特殊处理。
以下是有效的文字字符串示例:
( This is a string )
( Strings may contain newlines
and such. )
( Strings may contain balanced parentheses ( ) and
special characters ( * ! & } ^ % and so on ). )
( The following is an empty string. )
( )
( It has zero ( 0 ) length. )
在文字字符串中,反斜杠(\)用作转义字符,用于多种目的,例如在字符串中包含换行符、非打印ASCII字符、不匹配的括号或反斜杠本身。反斜杠后面紧跟的字符决定了其具体的解释(见表3.2)。如果反斜杠后面的字符不在表中,则反斜杠将被忽略。
表3.2 文字字符串中的转义序列
| 序列 | 含义 |
|---|---|
| \n | 换行符(LF) |
| \r | 回车符(CR) |
| \t | 水平制表符(HT) |
| \b | 退格符(BS) |
| \f | 换页符(FF) |
| ( | 左括号 |
| ) | 右括号 |
| |反斜杠 | |
| \ddd | 八进制字符代码ddd |
如果字符串过长,无法方便地写在一行上,可以在一行的末尾使用反斜杠字符来表示字符串延续到下一行。反斜杠和紧跟其后的行尾标记不被视为字符串的一部分。例如:
( These \
two strings \
are the same. )
( These two strings are the same. )
如果行尾标记出现在文字字符串中且前面没有反斜杠,其效果等同于\n(无论行尾标记是回车符、换行符还是两者皆有)。例如:
( This string has an end−of−line at the end of it .
)
( So does this one .\n )
\ddd转义序列提供了一种表示可打印ASCII字符集之外字符的方式。例如:
( This string contains \245two octal characters\307. )
数字ddd可以由一到三位八进制数字组成,高位溢出将被忽略。如果字符串的下一个字符也是数字,则必须使用三位八进制数字,并根据需要添加前导零。例如,文字( \0053 )表示一个包含两个字符的字符串,即\005(控制字符E)和数字3,而( \053 )和( \53 )都表示包含单个字符\053(即加号+)的字符串。
这种表示法提供了一种仅使用ASCII字符来指定7位ASCII字符集之外字符的方式。不过,字符串中可以出现任何8位值。特别是在文档加密时(见3.5节“加密”),文档中的所有字符串都会被加密,并且通常包含任意8位值。请注意,仍然需要使用反斜杠作为转义字符来指定不匹配的括号或反斜杠本身。
- 十六进制字符串:字符串也可以用十六进制形式书写,这在将任意二进制数据包含在PDF文件中时很有用。十六进制字符串是由括在尖括号(
<和>)内的一系列十六进制数字(0 - 9以及A - F或a - f)组成:
< 4E6F762073686D6F7A206B6120706F702E >
每对十六进制数字定义字符串的一个字节。空白字符(如空格、制表符、回车符、换行符和换页符)将被忽略。
如果十六进制字符串的最后一位数字缺失,即数字个数为奇数,则最后一位数字被假定为0。例如:
< 901FA3 >
是一个3字节的字符串,由十六进制代码为90、1F和A3的字符组成,而
< 901FA >
是一个3字节的字符串,包含十六进制代码为90、1F和A0的字符。
3.2.4 名称对象
名称对象是一种原子符号,由一个字符序列唯一确定。“唯一确定”意味着任何两个由相同字符序列构成的名称对象完全相同。“原子”则表示名称没有内部结构,尽管它由字符序列定义,但这些字符并不被视为名称的组成元素。
名称由斜杠字符(/)引入。斜杠并非名称的一部分,而是一个前缀,表明紧随其后的字符序列构成一个名称。斜杠与名称的首字符之间不能有空白字符。名称可包含任何普通字符,但不能包含定界符或空白字符(详见3.1节“词法约定”)。大写字母和小写字母被视为不同字符,例如,/A和/a是不同的名称。以下是一些有效的文字名称示例:
/Name1
/ASomewhatLongerName
/A;Name_With−Various***Characters?
/1. 2
/$$
/@pattern
/. notdef
注:标记/(斜杠后无普通字符)是一个有效的名称。
从PDF 1.2版本开始,除空字符(字符代码为0)外,任何字符都可以通过在其2位十六进制代码前加上数字符号(#)的方式包含在名称中;具体可参考附录H中的实现说明3和4。这种语法用于表示定界符、空白字符或数字符号本身;对于代码不在33(!)到126(~)范围内的字符,推荐使用该语法,但并非强制要求。表3.3展示了在PDF 1.2及更高版本中有效的文字名称示例。
表3.3 使用#字符的文字名称示例
| 文字名称 | 结果 |
|---|---|
| /Adobe#20Green | Adobe Green |
| /PANTONE#205757#20CV | PANTONE 5757 CV |
| /paired#28#29parentheses | paired( )parentheses |
| /The_Key_of_F#23_Minor | The_Key_of_F#_Minor |
| /A#42 | AB |
名称的长度受实现限制,详情见附录C。该限制针对名称内部表示中的字符数量。例如,名称/A#20B包含四个字符(/、A、空格、B),而非六个。
如前所述,在PDF文件中,名称对象被当作原子符号处理。通常,构成名称的字节不会被视为要呈现给用户或PDF消费应用程序外部的文本。不过,偶尔也需要将名称对象当作表示文本处理,比如代表字体名称的名称对象(见第413页表5.8中的BaseFont条目)或结构类型(见10.6.2节“结构类型”)。
在这种情况下,建议根据UTF - 8编码解释字节序列(若有#序列,需先展开),UTF - 8是一种可变长度字节编码的Unicode表示形式,其中可打印的ASCII字符与ASCII编码中的表示形式相同。这使得名称对象能够表示任何自然语言的文本,但受名称长度的实现限制(见附录H中的实现说明5)。
注:PDF并未规定将外部指定的文本表示为名称对象时应选用哪种UTF - 8序列。在某些情况下,多个UTF - 8序列可能表示相同的逻辑文本。在PDF中,由不同字节序列定义的名称对象是不同的,即便这些UTF - 8序列的外部解释可能相同。
在PDF中,名称对象始终以斜杠字符(/)开头,这与true、false和obj等关键字不同。本书在正文和表格中遵循一种排版约定,即运行文本中的名称省略开头的斜杠。例如,Type和FullScreen代表在PDF文件(以及本书代码示例)中实际应写为/Type和/FullScreen的名称。
3.2.5 数组对象
数组对象是按顺序排列的一维对象集合。与许多其他计算机语言中的数组不同,PDF数组可以是异构的,也就是说,数组元素可以是数字、字符串、字典或任何其他对象的任意组合,其中也包括其他数组。数组中元素的数量存在实现限制,具体可查阅附录C。
数组的书写形式是将一系列对象括在方括号([和])内,例如:
[ 549 3.14 false ( Ralph ) /SomeName ]
PDF直接支持的仅为一维数组。更高维度的数组可通过将数组作为其他数组的元素来构建,嵌套深度不受限制。
3.2.6 字典对象
字典对象是一种关联表,由一组对象对构成,这些对象对被称作字典的条目。每个条目的第一个元素是键,第二个元素是值。键必须是名称(这与PostScript中的字典键不同,在PostScript里,字典键可以是任意类型的对象)。值可以是任意类型的对象,包括另一个字典。若值为null(详见3.2.8节“空对象”),这样的字典条目等同于不存在(这也与PostScript不同,在PostScript中,null作为字典条目的值时,与其他任何对象的处理方式相同)。字典中条目的数量存在实现限制,具体内容请参考附录C。
注:同一字典中不应出现两个相同的键。若一个键出现多次,其对应的值是未定义的。
字典的书写方式是将一系列键值对括在双尖括号(<< … >>)内。例如:
<< /Type /Example
/Subtype /DictionaryExample
/Version 0.01
/IntegerItem 12
/StringItem ( a string )
/Subdictionary << /Item1 0.4
/Item2 true
/Item3 ( Another string )
>>
/ArrayItem [ 1 2 3 4 5 ]
>>
在上述示例中,/Type、/Subtype、/Version等是键,而/Example、/DictionaryExample、0.01等则是对应的值。字典中的键值对顺序并不重要,因此以下两种表示方式是等价的:
<< /A 1 /B 2 >>
<< /B 2 /A 1 >>
在实际应用中,为了提高可读性,通常会按照一定的逻辑顺序来排列键值对。例如,将相关的键值对放在一起,或者按照键的字母顺序排列。不过,PDF语法本身并不对这种顺序做要求。
字典常用于组织和存储相关的信息。例如,在描述PDF文档中的页面时,会使用一个字典来包含诸如页面大小、旋转角度、内容流以及相关资源等信息。这种结构使得PDF能够清晰地表示复杂的数据关系,同时也便于应用程序进行解析和处理。
3.2.7 流对象
流对象和字符串对象一样,是一个字节序列。然而,PDF应用程序可以增量地读取流,而字符串必须被完整读取。此外,流的长度可以是无限的,而字符串受限于实现上的长度限制。因此,像图像和页面描述这类可能包含大量数据的对象,都被表示为流。
注意:与字符串一样,本节仅描述将流作为字节序列写入的语法。这些字节代表什么,取决于引用该流的上下文。
流由一个字典组成,其后是位于关键字“stream”和“endstream”之间的零个或多个字节:
dictionary
stream
... 零个或多个字节...
endstream
所有流都必须是间接对象(见3.2.9节“间接对象”),且流字典必须是直接对象。紧跟流字典的关键字“stream”之后,应是一个由回车符和换行符或仅换行符组成的行尾标记,而不能仅是回车符。建议在数据之后且在“endstream”之前有一个行尾标记;此标记不包含在流长度内。
另外,从PDF 1.2开始,字节可包含在外部文件中,这种情况下流字典指定该文件,“stream”和“endstream”之间的任何字节将被忽略。(见附录H中的实现说明6)。
注意:若不限制关键字“stream”后不能仅跟回车符,就无法区分以回车符作为行尾标记且以换行符作为首个字节数据的流,与以回车 - 换行符序列表示行尾的流。
表3.4列出了所有流字典共有的条目;某些类型的流可能有其他字典条目,在描述这些流的地方会有说明。关于流的过滤器的可选条目,指示在使用流之前,流中的数据是否以及如何被转换(解码)。过滤器在3.3节“过滤器”中有进一步描述。
流范围
每个流字典都有一个“Length(长度)”条目,它指明PDF文件中用于流数据的字节数。(如果流使用了过滤器,“Length”就是已编码数据的字节数。)此外,大多数过滤器被定义为使数据具有自我限制特性;也就是说,它们使用一种编码方案,在该方案中,一个明确的数据结束(EOD)标记界定了数据的范围。最后,流用于表示许多对象,从这些对象的属性中可以推断出长度。所有这些约束条件必须一致。
例如,一个有10行20列、使用单一颜色分量且每个分量为8位的图像,恰好需要200字节的图像数据。如果流使用了过滤器,PDF文件中必须有足够的已编码数据字节来生成这200字节的数据。如果“Length”太小、明确的数据结束标记出现得太早,或者解码后的数据不包含200字节,就会出现错误。
如果流包含的数据过多,这也是一个错误,不过在关键字“endstream”之前的PDF文件中可能存在一个额外的行尾标记,这种情况除外。
表3.4 所有流字典共有的条目
| 键 | 类型 | 值 |
|---|---|---|
Length | 整数 | (必填)从紧跟关键字“stream”的行开始,到关键字“endstream”前的最后一个字节为止的字节数。(在“endstream”之前可能有一个额外的行尾标记,该行尾标记不包含在长度计数中,也不在“流范围”的逻辑讨论范围内。) |
Filter | 名称或数组 | (可选)在处理位于关键字“stream”和“endstream”之间的流数据时要应用的过滤器名称,或此类名称的数组。多个过滤器应按照应用顺序指定。 |
DecodeParms | 字典或数组 | (可选)一个参数字典或此类字典的数组,由Filter指定的过滤器使用。如果只有一个过滤器且该过滤器有参数,DecodeParms必须设置为该过滤器的参数字典,除非该过滤器的所有参数都具有默认值,在这种情况下DecodeParms条目可以省略。如果有多个过滤器且其中任何一个过滤器的参数设置为非默认值,DecodeParms必须是一个数组,每个过滤器对应一个条目:要么是该过滤器的参数字典,要么是该过滤器没有参数字典(如果其所有参数都具有默认值)。如果所有过滤器都没有参数,或者所有参数都具有默认值,DecodeParms条目可以省略。(另见附录H中的实现说明7。) |
F | 文件规范 | (可选;PDF 1.2)包含流数据的文件。如果存在此条目,“stream”和“endstream”之间的字节将被忽略,过滤器由FFilter而不是Filter指定,并且解码参数由FDecodeParms而不是DecodeParms指定。但是,Length条目仍应指定这些字节的数量。(通常,不存在字节且Length为0。)(另见实现说明46,附录H。) |
FFilter | 名称或数组 | (可选;PDF 1.2)在处理流的外部文件中找到的数据时要应用的过滤器名称,或此类名称的数组。适用与Filter相同的规则。 |
FDecodeParms | 字典或数组 | (可选;PDF 1.2)一个参数字典,或此类字典的数组,由FFilter指定的过滤器使用。适用与DecodeParms相同的规则。 |
DL | 整数 | (可选;PDF 1.5)一个非负整数,表示已解码(去除过滤)的流中的字节数。例如,它可用于确定是否有足够的磁盘空间将流写入文件。此值应仅视为一个提示;对于某些流过滤器,可能无法精确确定此值。 |
3.2.8 空对象
空对象的类型和值与其他任何对象的类型和值都不相等。只有一种类型为空的对象,由关键字null表示。对不存在对象的间接对象引用(见3.2.9节“间接对象”)被视为与空对象相同。将空对象指定为字典条目的值(见3.2.6节“字典对象”),其语义完全等同于省略该条目。
3.2.9 间接对象
PDF文件中的任何对象都可以标记为间接对象。这为该对象提供了一个唯一的对象标识符,其他对象可以通过它来引用该对象(例如,作为数组的一个元素或作为字典条目的值)。对象标识符由两部分组成:
- 一个正整数对象编号。间接对象在PDF文件中通常按顺序编号,但这不是必需的;对象编号可以以任意顺序分配。
- 一个非负整数生成编号。在新创建的文件中,所有间接对象的生成编号均为0。当文件在后续更新时,可能会引入非零的生成编号;参见3.4.3节“交叉引用表”和3.4.5节“增量更新”。
对象编号和生成编号的组合唯一地标识一个间接对象。对象在其存在期间保持相同的对象编号和生成编号,即使其值被修改。
PDF文件中间接对象的定义由其对象编号和生成编号组成,后面跟着位于关键字obj和endobj之间的对象值。例如,以下定义:
12 0 obj
(Brillig)
endobj
定义了一个对象编号为12、生成编号为0且值为Brillig的间接字符串对象。
该对象可以在文件的其他位置通过由对象编号、生成编号和关键字R组成的间接引用来引用:
12 0 R
从PDF 1.5开始,间接对象可以驻留在对象流中(见3.4.6节“对象流”)。它们的引用方式相同;但是,它们的定义不包括关键字obj和endobj。
对未定义对象的间接引用不是错误;它仅被视为对空对象的引用。例如,如果一个文件包含间接引用17 0 R,但不包含相应的定义:
17 0 obj
...
endobj
那么该间接引用被视为引用空对象。
注意:在构成PDF文档的数据结构中,某些值需要指定为间接对象引用。除非另有明确说明,否则任何对象(流除外)都可以直接指定,也可以指定为间接对象引用;其语义完全等效。特别要注意的是,定义文档可见内容的内容流可能不包含间接引用(见3.7.1节“内容流”)。另见附录H中的实现说明8。
示例3.1展示了使用间接对象来指定流的长度。流的Length条目的值是一个在文件中跟随流的整数对象。这允许一次性生成PDF的应用程序在生成流的内容之后再指定流的长度。
示例3.1
7 0 obj
<< /Length 8 0 R >> % 对对象8的间接引用
stream
BT
/F1 12 Tf
72 712 Td
(A stream with an indirect length) Tj
ET
endstream
endobj
8 0 obj
77 % 前一个流的长度
endobj
3.3 过滤器
流过滤器在3.2.7节“流对象”中有所介绍。过滤器是流规范的可选部分,用于指示流中的数据在使用前必须如何解码。例如,如果一个流具有ASCIIHexDecode过滤器,读取流中数据的应用程序会将流中以ASCII十六进制编码的数据转换为二进制数据。
生成PDF文件的应用程序可以对某些信息进行编码(例如,采样图像的数据),以压缩这些信息或将其转换为便于移植的ASCII表示形式。然后,读取(使用)PDF文件的应用程序可以使用相应的解码过滤器将信息转换回其原始形式。
一个流的过滤器由该流字典中的Filter条目指定(如果流是外部的,则由FFilter条目指定)。过滤器可以级联形成一个管道,按顺序传递数据进行一个或多个解码转换。例如,使用LZW和ASCII base - 85编码(按此顺序)编码的数据可以使用流中的以下条目进行解码:
/Filter [/ASCII85Decode /LZWDecode]
一些过滤器可能需要参数来控制其操作方式。这些可选参数由流字典中的DecodeParms条目指定(如果流是外部的,则由FDecodeParms条目指定)。
PDF支持一组标准过滤器,主要分为两类:
- ASCII过滤器:能够对已编码为ASCII文本的任意8位二进制数据进行解码。(有关为何这种编码类型可能有用的解释,请参见3.1节“词法约定”;请注意,ASCII过滤器在PDF文件中除了此目的外几乎没有其他用途。)请参见3.5节“加密”。
- 解压缩过滤器:能够对已压缩的数据进行解码。压缩后的数据始终为8位二进制格式,即使原始数据是ASCII文本。(压缩对于大型采样图像特别有价值,因为它减少了存储要求和传输时间。某些类型的压缩是有损的,这意味着在编码过程中会丢失一些数据,导致解压缩时质量下降。在没有数据丢失的情况下进行的压缩称为无损压缩。)
标准过滤器总结在表3.5中,该表还指出了它们是否接受任何可选参数。以下各节将更详细地描述这些过滤器及其参数(如果有),包括一些过滤器的编码算法规范。(另请参见附录H中的实现说明9和10。)
示例3.2展示了一个流,其中包含页面的标记指令,该流使用LZW压缩方法进行了压缩,并使用ASCII base - 85表示法进行了编码。(流的内容在3.7.1节“内容流”中进行了解释,其中使用的操作符在第5章中进一步描述。)
表3.5 标准过滤器
| 过滤器名称 | 是否需要参数 | 描述 |
|---|---|---|
ASCIIHexDecode | 否 | 解码以ASCII十六进制表示形式编码的数据,重现原始二进制数据。 |
ASCII85Decode | 否 | 解码以ASCII base - 85表示形式编码的数据,重现原始二进制数据。 |
LZWDecode | 是 | 解压缩使用LZW(Lempel - Ziv - Welch)自适应压缩方法编码的数据,重现原始文本或二进制数据。 |
FlateDecode | 是 | (PDF 1.2)解压缩使用zlib/deflate压缩方法编码的数据,重现原始文本或二进制数据。 |
RunLengthDecode | 否 | 解压缩使用面向字节的行程长度编码算法编码的数据,重现原始文本或二进制数据(通常是单色图像数据,或任何包含频繁长字节重复的数据)。 |
CCITTFaxDecode | 是 | 解压缩使用CCITT传真机标准编码的数据,重现原始数据(通常是每像素1位的单色图像数据)。 |
JBIG2Decode | 是 | (PDF 1.4)解压缩使用JBIG2标准编码的数据,重现原始单色(每像素1位)图像数据(或该数据的近似值)。 |
DCTDecode | 是 | 解压缩使用基于JPEG标准的DCT(离散余弦变换)技术编码的数据,重现近似原始数据的图像样本数据。 |
JPXDecode | 否 | (PDF 1.5)解压缩使用基于小波的JPEG2000标准编码的数据,重现原始图像数据。 |
Crypt | 是 | (PDF 1.5)解密由安全处理程序加密的数据,重现加密前的原始数据。 |
示例3.2
1 0 obj
<< /Length 534
/Filter [/ASCII85Decode /LZWDecode]
>>
stream
J,6T7p<&l9%_jumgB'7/Z7KNXbNS'+Q/'&OLTf
LIDk#n"s<*Atf/Vn%b&/c8*A"K/nCVjYf<>c!UrtJ
RM\WJjHG6nc75kHkL5j+cPzKEBPWdP>ffK(j)_R%W_d
&J5juad7h?L#F5jH]3ACk5iOKZ7<jCtq165Xb
Vc3n5uaQ=0#W5#n3UJ,H,MQKfq1?JUpR6n[C2E4
ZN&Udn.p?#X+1>0Ku5bCDF/3FL5Qo)A%lZC2H1
"TOJR7Q;&<5iP$qBXRecDlJUj')0xJO5.9D5
SJhQj@NDB_dQ&CgjnY'C8%&u,uM6Bm%NyfKb1+
"aAaS'V!lgLb<W9K6Y\10McIqKEIeWdP*N9A)J(
a>lG1p&eVok&uJH59%Xomop5KatWRt'Q3qQ!uL,
JD!M5QP|(Kn06flapKcD@q!48!(Sj+7F790m(Vj8
8!8Q_CZ(Gm1%XN1u&FKHMB~>
endstream
endobj
示例3.3
1 0 obj
<< /Length 568 >>
stream
2 J
BT
/F1 12 Tf
0 Tc
0 Tw
72.5 712 TD
[(Unencoded streams can be read easily) 65 (,)] TJ
0 -14 TD
[(b) 20 (ut generally tak) 10 (e more space than \311)] TJ
T* (Encoded streams.) TJ
0 -28 TD
[(Se) 25 (v) 15 (eral encoding methods are) 20 (v) 25 (ailable in PDF) 80 (.)] TJ
0 -14 TD
(Some are used for compression and others simply)
T* [(to represent binary data in an) 55 (ASCII format.)] TJ
T* (Some of the compression encoding methods are\
suitable) TJ
T* (for both data and images, while others are\
suitable only) TJ
T* (for continuous - tone images.) TJ
ET
endstream
endobj
3.3.1 ASCII十六进制解码过滤器
ASCII十六进制解码过滤器对以ASCII十六进制形式编码的数据进行解码。ASCII十六进制编码和ASCII base - 85编码(在下一节中描述)将二进制数据(如图像数据)转换为7位ASCII字符。一般来说,ASCII base - 85编码比ASCII十六进制编码更受青睐,因为它更紧凑:它将数据扩展为原来的4.5倍,而ASCII十六进制编码将数据扩展为原来的2倍。
ASCII十六进制解码过滤器为每对ASCII十六进制数字(0 - 9和A - F或a - f)生成一个字节的二进制数据。所有空白字符(见3.1节“词法约定”)将被忽略。右尖括号字符(>)表示数据结束(EOD)。任何其他字符都会导致错误。如果过滤器在读取奇数个十六进制数字后遇到EOD标记,它的行为就好像最后一位数字后面跟着一个0。
3.3.2 ASCII base - 85解码过滤器
ASCII base - 85解码过滤器对以ASCII base - 85编码的数据进行解码并生成二进制数据。以下段落描述了将二进制数据编码为ASCII base - 85的过程;ASCII base - 85解码过滤器将此过程反向进行。
ASCII base - 85编码使用从!到u的字符以及字符z,以2字符序列~>作为其EOD标记。ASCII base - 85解码过滤器忽略所有空白字符(见3.1节“词法约定”)。任何其他字符,以及在ASCII base - 85编码中表示不可能组合的任何字符序列,都会导致错误。
具体来说,ASCII base - 85编码每4个字节的二进制数据生成5个ASCII字符。每组4个二进制输入字节
(
b
1
b
2
b
3
b
4
)
(b_1 b_2 b_3 b_4)
(b1b2b3b4),使用以下关系转换为一组5个输出字节
(
c
1
c
2
c
3
c
4
c
5
)
(c_1 c_2 c_3 c_4 c_5)
(c1c2c3c4c5):
(
b
1
×
25
6
3
)
+
(
b
2
×
25
6
2
)
+
(
b
3
×
25
6
1
)
+
b
4
=
(
c
1
×
8
5
4
)
+
(
c
2
×
8
5
3
)
+
(
c
3
×
8
5
2
)
+
(
c
4
×
8
5
1
)
+
c
5
(b_1\times256^3)+(b_2\times256^2)+(b_3\times256^1)+b_4 = (c_1\times85^4)+(c_2\times85^3)+(c_3\times85^2)+(c_4\times85^1)+c_5
(b1×2563)+(b2×2562)+(b3×2561)+b4=(c1×854)+(c2×853)+(c3×852)+(c4×851)+c5
换句话说,4个字节的二进制数据被解释为一个256进制数,然后转换为一个85进制数。85进制数的5个字节再通过每个字节加上33(字符!的ASCII码)转换为ASCII字符。由此产生的编码数据仅包含可打印的ASCII字符,其代码在33(!)到117(u)的范围内。作为一种特殊情况,如果所有5个字节都为0,它们将由代码为122(z)的字符而不是由5个感叹号(!!!)表示。
如果要编码的二进制数据的长度不是4字节的倍数,最后一组不足4字节的部分将用于生成最后一组不足5个字符的输出。给定n(1、2或3)字节的二进制数据,编码器首先附加4 - n个零字节,以形成一个4字节的组。然后,它像往常一样对该组进行编码,但不应用特殊的z情况。最后,它只写入生成的5个字符组中的前n + 1个字符。这些字符后面紧接着是~> EOD标记。
以下情况(在正确编码的字节序列中永远不会出现)在解码过程中会导致错误:
- 一组5个字符所表示的值大于 2 32 − 1 2^{32}-1 232−1。
- 在一组中间出现z字符。
- 最后一组不足部分仅包含一个字符。
3.3.3 LZWDecode和FlateDecode过滤器
LZWDecode过滤器以及(在PDF 1.2中引入的)FlateDecode过滤器有很多共同之处,本节将一并讨论它们。它们对分别使用LZW或Flate数据压缩方法编码的数据进行解码,具体如下:
- LZW(Lempel - Ziv - Welch) 是一种可变长度的自适应压缩方法,已被采纳为标签图像文件格式(TIFF)标准中的标准压缩方法之一。LZW编码的详细信息将在下一节介绍。
- Flate方法 基于公共领域的zlib/deflate压缩方法,这是一种可变长度的Lempel - Ziv自适应压缩方法,与自适应哈夫曼编码级联。它在互联网RFC 1950《ZLIB压缩数据格式规范》和1951《DEFLATE压缩数据格式规范》中有详细定义(参见参考书目)。
这两种方法都可以压缩二进制数据或ASCII文本,但(和所有压缩方法一样)始终生成二进制数据,即使原始数据是文本。
LZW和Flate压缩方法能够发现并利用输入数据中的许多模式,无论这些数据是文本还是图像。如后文所述,这两种过滤器都支持通过预测函数进行可选的转换,这提高了采样图像数据的压缩效果。由于其级联的自适应哈夫曼编码,Flate编码的输出通常比LZW编码的输出更紧凑。Flate和LZW的解码速度相当,但Flate编码的速度明显比LZW编码慢。
通常,Flate和LZW编码都会大幅压缩其输入数据。然而,在最坏的情况下(其中没有相邻字符对出现两次),Flate编码会将其输入扩展到至少11字节或1.003倍(以较大者为准),再加上PNG预测器添加的算法标签的影响。对于LZW编码,最佳情况(全零)提供接近1:365的压缩比;对于长文件,最坏情况的扩展系数为1.125,在某些实现中可能会增加到近1.5,再加上与Flate编码中类似的PNG标签的影响。
LZW编码详情
使用LZW压缩方法编码的数据由一系列9到12位长的代码组成。每个代码表示输入数据(0 - 255)中的单个字符、清除表标记(256)、数据结束标记(257),或者是输入中表示多字符序列的表项(258或更大)。
最初,代码长度为9位,LZW表仅包含258个固定代码的条目。随着编码的进行,条目会附加到表中,将新代码与越来越长的输入字符序列相关联。编码器和解码器维护此表的相同副本。
每当编码器和解码器各自独立(但同步)地意识到当前表长度不再足以表示表中的条目数时,它们会将每个代码的位数增加1。第一个长度为10位的输出代码是在创建表项511之后的那个;类似地,条目1023和12047的位长分别为11位和12位。LZW表中的代码长度从不超过12位;因此,条目4095是最后一个可能的表条目。
编码器执行以下步骤序列以生成每个输出代码:
- 累积一个或多个与表中已有序列匹配的输入字符序列。为了实现最大压缩,编码器寻找最长的此类序列。
- 发出与该序列对应的代码。
- 为第一个未使用的代码创建一个新的表条目。其值是在步骤1中找到的序列,后面跟着下一个输入字符。
例如,假设输入由以下ASCII字符代码序列组成:
45 45 45 45 45 65 45 45 45 66
从一个空表开始,编码器的处理过程如表3.6所示。
表3.6 典型的LZW编码序列
| 输入代码序列 | 输出代码 | 添加到表中的代码 | 新代码表示的序列 |
|---|---|---|---|
| - | 256(清除表) | - | - |
| 45 | 45 | 258 | 45 45 |
| 45 45 | 258 | 259 | 45 45 45 |
| 45 45 45 | 258 | 260 | 45 45 65 |
| 65 | 65 | 261 | 65 45 |
| 45 45 45 | 259 | 262 | 45 45 45 66 |
| 66 | 66 | - | - |
| - | 257(EOD) | - | - |
代码被打包成连续的位流,高位在前。然后这个流被分成8位字节,高位在前。因此,代码可以任意跨越字节边界。在数据结束标记(代码值257)之后,最终字节中的任何剩余位都将被设置为0。
在上面的示例中,所有输出代码都是9位长;它们将按如下方式打包成字节(以十六进制表示):
80 08 60 50 22 0C 0C 85 01
为了适应不断变化的输入序列,编码器可以在任何时候发出清除表代码,这会导致编码器和解码器都使用初始表和9位代码长度重新开始。按照惯例,编码器开始时会发出清除表代码。当表已满时,它必须发出清除表代码;它也可以尽早发出。
LZWDecode和FlateDecode参数
LZWDecode和FlateDecode过滤器接受可选参数来控制解码过程。这些参数中的大多数与减小压缩采样图像(颜色值的矩形数组,如4.8节“采样图像”中所述)大小的技术相关。对于矩形采样图像,图像数据通常在样本之间变化很小。因此,减去相邻样本的值(一个称为求差的过程),并对差值而不是原始样本值进行编码,可以减小输出数据的大小。此外,当图像数据每个样本包含几个颜色分量(红 - 绿 - 蓝或青 - 品红 - 黄 - 黑)时,取相邻样本中对应颜色分量之间的差值,而不是同一样本中不同颜色分量之间的差值,通常会减小输出数据量。
表3.7显示了可为LZWDecode和FlateDecode过滤器可选指定的参数。除非另有说明,为任何可选参数提供给解码过滤器的值必须与数据编码时使用的值匹配。
表3.7 LZWDecode和FlateDecode过滤器的可选参数
| 键 | 类型 | 值 |
|---|---|---|
Predictor | 整数 | 一个代码,用于选择预测器算法(如果有)。如果此条目的值为1,过滤器假定使用正常算法对数据进行编码,没有进行预测。如果该值大于1,过滤器假定在编码之前对数据进行了求差处理,并且Predictor选择预测算法。有关更多信息,请参阅下面的“LZW和Flate预测器函数”。默认值:1。 |
Colors | 整数 | (仅在Predictor大于1时使用)交错颜色分量的数量。有效值在PDF 1.2或更早版本中为1或大于1;在PDF 1.3及更高版本中为1到4。默认值:1。 |
BitsPerComponent | 整数 | (仅在Predictor大于1时使用)用于表示样本中每个颜色分量的位数。有效值为1、2、4、8,以及(在PDF 1.5中)16。默认值:8。 |
Columns | 整数 | (仅在Predictor大于1时使用)每行的样本数量。默认值:1。 |
EarlyChange | 整数 | (仅LZWDecode)指示何时增加代码长度。如果此条目的值为0,代码长度增加尽可能推迟。如果值为1,代码长度每增加一个代码就会增加。如果包含此参数,则LZW样本代码分布更均匀。此参数比必要的情况提前一个代码增加代码长度。默认值:1。 |
LZW和Flate预测器函数
如果LZW和Flate编码的输入数据具有高度可预测性,它们可以更紧凑地压缩数据。提高许多连续色调采样图像可预测性的一种方法是用该样本与更早相邻样本之间的差值替换每个样本。如果预测器函数效果良好,预测后的数据会向0聚集。
支持两组预测器函数。第一组是TIFF组,由TIFF标准中Predictor为2时应用的单个函数组成(它也适用于LZW压缩,在此也应用于Flate压缩)。TIFF预测器2预测样本的每个颜色分量与左侧样本的相应颜色分量相同。
第二组支持的预测器函数是PNG组,由万维网联盟的便携式网络图形建议(见参考书目)中记录的过滤器组成。这里使用术语“预测器”而不是“过滤器”以避免混淆。有五个基本的PNG预测器算法用于每行;还有第六个算法,它为每行分别选择最佳预测器函数:
- None:不进行预测。
- Sub:预测与左侧样本相同。
- Up:预测与上方样本相同。
- Average:预测为左侧样本和上方样本的平均值。
- Paeth:上方样本、左侧样本和左上方样本的非线性函数。
如果要使用预测器算法,由Predictor过滤器参数指示(见表3.7),该参数可以具有表3.8中列出的任何值。
对于LZWDecode和FlateDecode,Predictor值大于或等于10仅表示正在使用PNG预测器;实际使用的特定预测器函数在传入数据中明确编码。如果解码过滤器提供的Predictor值与数据编码时使用的值都大于或等于10,则它们无需匹配。
表3.8 预测器值
| 值 | 含义 |
|---|---|
| 1 | 无预测(默认值) |
| 2 | TIFF预测器2 |
| 10 | PNG预测(编码时,所有行均为PNG None) |
| 11 | PNG预测(编码时,所有行均为PNG Sub) |
| 12 | PNG预测(编码时,所有行均为PNG Up) |
| 13 | PNG预测(编码时,所有行均为PNG Average) |
| 14 | PNG预测(编码时,所有行均为PNG Paeth) |
| 15 | PNG预测(编码时,PNG最优) |
两组预测器函数有一些共性。它们都做出以下假设:
- 数据按顺序呈现,从上到下逐行排列,在一行内从左到右排列。
- 一行占用整数个字节,必要时向上取整。
- 样本及其分量从高位到低位打包成字节。
- 图像外样本的所有颜色分量(这对于边界附近的预测是必要的)为0。
预测器函数组也有显著差异:
- 每个PNG预测行的预测后数据以一个显式算法标签开头;因此,不同的行可以用不同的算法进行预测;而相同的算法应用于所有行。
- TIFF函数组根据前一个实例预测每个颜色分量,同时考虑每个分量的位数和每个样本的分量数。相比之下,PNG函数组将每个数据字节作为一个或多个先前图像样本的相应字节的函数进行预测,而不管一个字节中是否有多个颜色分量,或者单个颜色分量是否跨越多个字节。这可以在一定程度上以牺牲压缩质量为代价显著提高速度。
3.3.4 行程长度解码过滤器
行程长度解码过滤器(RunLengthDecode filter)对以基于行程长度的简单字节格式编码的数据进行解码。编码后的数据是一个行程序列,其中每个行程由一个长度字节和1到128个数据字节组成。如果长度字节在0到127的范围内,则接下来的长度 + 1(1到128)个字节在解压缩过程中按字面复制。如果长度在129到255的范围内,则接下来的单个字节在解压缩过程中要复制257 - 长度(2到128)次。
行程长度编码实现的压缩效果取决于输入数据。在最佳情况下(全为零),对于长文件可实现约64:1的压缩比。最坏的情况(十六进制序列00与FF交替)会导致127:1的扩展。
3.3.5 CCITTFaxDecode过滤器
CCITTFaxDecode过滤器对使用ITU - T(国际电信联盟,前身为国际电报电话咨询委员会,即CCITT)的第3组或第4组传真编码方式编码的图像数据进行解码。CCITT编码旨在实现高效压缩,适用于相对低分辨率的单色(每像素1位)图像数据,仅对位图图像数据有用,不适用于彩色图像、灰度图像或一般数据。
CCITT编码标准由国际电信联盟(ITU)定义。本书中未详细描述编码算法,但可在ITU建议T.4和T.6中找到(见参考书目)。出于历史原因,我们将这些文档称为CCITT标准。
CCITT编码是面向位的,而非面向字节的。因此,原则上,编码或解码的数据可能不会在字节边界结束。通过以下方式处理此问题:
- 未编码的数据被视为完整的扫描行,在每行扫描线的末尾插入未使用的位以填充最后一个字节。这种方法与PDF中采样图像数据的惯例兼容。
- 编码数据通常被视为连续、不间断的位流。EncodedByteAlign参数(见表3.9)可用于使每个编码扫描线填充到字节边界。尽管CCITT标准未规定此操作,且传真机从不这样做,但一些软件包会发现按此方式对数据进行编码和解码很方便。
- 当过滤器到达数据结束(EOD)时,它总是跳到编码数据之后的下一个字节边界。
如果CCITTFaxDecode过滤器遇到编码不正确的源数据,将发生错误。除了DamagedRowsBeforeError参数中注明的情况外,过滤器不执行任何错误纠正或重新同步操作。
表3.9列出了可用于控制解码的可选参数。除非另有说明,由任何这些参数提供给解码过滤器的值必须与数据编码时使用的值匹配。
表3.9 CCITTFaxDecode过滤器的可选参数
| 键 | 类型 | 值 |
|---|---|---|
| K | 整数 | 一个标识所用编码方案的代码: - <0:纯二维编码(第4组) - 0:纯一维编码(第3组,1 - D) - >0:混合一维和二维编码(第3组,3 - 2D),其中一行可以用一维编码,随后最多K - 1行用二维编码 过滤器区分负、零和正的值以确定如何解释编码数据;但是,它不区分不同的正K值。默认值:0。 |
| EndOfLine | 布尔值 | 一个标志,指示编码中是否需要存在行尾位模式。CCITTFaxDecode过滤器总是接受行尾位模式,但仅当EndOfLine为true时才需要它们。默认值:false。 |
| EncodedByteAlign | 布尔值 | 一个标志,指示过滤器是否期望在每个编码行之前有额外的0位,以便该行从字节边界开始。如果为true,过滤器在开始解码每一行之前跳过这些位。如果为false,过滤器不期望编码数据中的字节边界表示。默认值:false。 |
| Columns | 整数 | 图像的宽度(以像素为单位)。如果该值不是8的倍数,过滤器将未编码图像的宽度调整为下一个8的倍数,以便每行从字节边界开始。默认值:1728。 |
| Rows | 整数 | 图像的扫描线高度。如果该值为0或不存在,则图像的高度未预先确定,编码数据必须由结束块位模式或文件结束来终止。默认值:无。 |
| EndOfBlock | 布尔值 | 一个标志,指示过滤器是否期望编码数据由结束块位模式终止。如果为true,过滤器在解码了Rows参数指示的行数或数据用尽时(以先发生者为准)寻找结束块模式。结束块模式是CCITT端 - 传真文件(EOFB)或返回控制(RTC),适用于K参数。默认值:true。 |
| BlackIs1 | 布尔值 | 一个标志,指示1位应解释为黑色像素,0位应解释为白色像素,这与PDF图像数据的正常惯例相反。默认值:false。 |
| DamagedRowsBeforeError | 整数 | 在发生错误之前可以容忍的数据损坏行数。仅当EndOfLine为true且K为非负时,此参数才适用。容忍损坏的行意味着在编码数据中搜索EndOfLine模式,然后用前一行的EndOfLine模式替换损坏的行(如果前一行未损坏),或者如果前一行也损坏,则用白色扫描线替换。默认值:0。 |
使用CCITT编码实现的压缩效果取决于数据以及各种可选参数的值。对于第3组一维编码,在最佳情况(全为零)下,每条扫描线最多4字节,压缩因子取决于扫描线的长度。如果扫描线为300字节长,可实现约75:1的压缩比。在最坏情况(图像由交替的1和0组成)下,会产生2:9的扩展。
本内容为AI生成,请谨慎使用,有不对的地方欢迎指正
根据此书版权申明,可能涉及到版权问题,该博客只展示部分章节翻译内容,后续不再更新

















 7869
7869

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









