







前言
最近做实验需要统计实验结果的均值,标准差,mark一下,方便查阅!
总体标准差
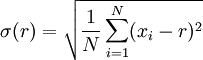
样本标准差
有的也叫无偏样本标准差,就是自由度为 n-1
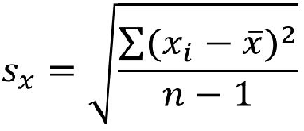
代码
imimport numpy as np
each_acc1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
print("总体标准差:", np.std(each_acc1))
print("样本标准差:", np.std(each_acc1, ddof=1))
样本标准差: 3.0276503540974917
总体标准差: 2.8722813232690143
按列计算均值,总体标准差,样本标准差
imimport numpy as np
each_list = []
each_acc1 = [1.0, 2.323, 3.323, 45.321321, 6.312, 6.312, 8.3123, 99.3232]
each_acc2 = [0.99233, 2.3212, 3.323, 45.321321, 7.312, 7.312, 8.666, 100]
each_acc3 = [1.32323, 1.32, 6.323, 35.321321, 8.312, 7.312, 8.7877, 100.0]
each_list.append(each_acc1)
each_list.append(each_acc2)
each_list.append(each_acc3)
a = np.array(each_list)
print('原始数组:\n', a)
print('每列均值:\n', a.mean(axis=0))
print('每列总体标准差:\n', np.around(a.std(axis=0),decimals=2))
print('每列样本标准差:\n', np.around(a.std(axis=0,ddof=1),decimals=2))
原始数组:
[[ 1. 2.323 3.323 45.321321 6.312 6.312 8.3123 99.3232 ]
[ 0.99233 2.3212 3.323 45.321321 7.312 7.312 8.666 100. ]
[ 1.32323 1.32 6.323 35.321321 8.312 7.312 8.7877 100. ]]
每列均值:
[ 1.10518667 1.98806667 4.323 41.98798767 7.312 6.97866667 8.58866667 99.7744 ]
每列总体标准差:
[0.15 0.47 1.41 4.71 0.82 0.47 0.2 0.32]
每列样本标准差值:
[0.19 0.58 1.73 5.77 1. 0.58 0.25 0.39]














 1623
1623











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









