










面试官问:深度网络中loss除以10和学习率除以10等价吗
面试题
深度网络中loss除以10和学习率除以10等价吗?
标准答案
在讨论深度学习中,调整 loss的尺度与调整 学习率 是否等价时,答案取决于使用的优化器类型。以下是对常见优化器的分析:
第一类:传统优化器(如 SGD 和 Momentum SGD)
-
随机梯度下降(SGD)
随机梯度下降是对每个训练样本就更新一次网络参数,这样使得网络更新参数速度很快,但是问题就是由于训练数据多样,容易朝偏离网络最优点方向训练,网络训练不稳定。
-
Momentum SGD
随机梯度下降的方法很难通过峡谷区域(也就是在一个维度梯度变化很大,另一个维度变化较小),这个很好理解,因为梯度下降是梯度更新最大的反方向,如果这个时候一个维度梯度变化很大,那么就很容易在这个方向上振荡,另一个方向就更新很慢,如下图:
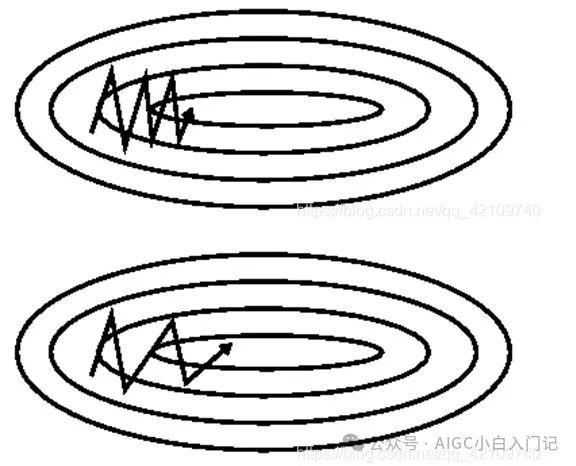
上面上图没有加动量,下图加了动量的方法,可以看到有动量可以在变化小的维度上加快更新使得加快收敛。该方法是通过添加一个参数B构建一个一阶动量m,其中m有下列表达式:
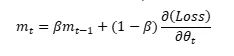
-
对于传统优化器,深度网络中loss除以10和学习率除以10等价吗?
对于这些传统优化器, loss 乘以一个常数会直接影响梯度的计算继而改变参数更新的幅度。因此, loss缩放和学习率缩放是等价的。具体来说,将 loss乘以10等价于将学习率也乘以10,二者对参数更新的影响相同。
第二类:带有二阶动量的优化器(如 Adagrad、RMSprop)
-
Adagrad
对于所有特征,我们的学习率一直没有变。怎么理解呢?假设我们用一批数据训练网络,这个数据中只有少部分数据含有某个特征,另一个特征几乎全部数据都具有,当这些数据通过训练时,对于不同特征我们假设对应于不同的神经元权重,对于都含有的特征,这些神经元对应参数更新很快,但是对于那些只有少部分数据含有的特征,对应神经元权重获得更新机会就少,但是由于学习率一样,这样可能导致神经网络训练的不充分。
adagrad算法就是为了解决这个问题,让学习率学习数据的特征自动调整其大小,adagrad算法引入了二阶动量,其表达式为:
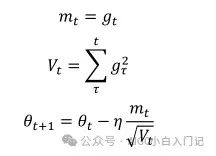
其中g(t)为t时刻参数梯度,下面来讲解为什么adagrad可以实现不同频率特征对其参数学习率改变,首先,我们看到二阶动量V(t),它是梯度平方累加和,对于训练数据少的特征,自然对应的参数更新就缓慢,也就是说他们的梯度变化平方累加和就会比较小,所以对应于上面参数更新方程中的学习速率就会变大,所以对于某个特征数据集少,相应参数更新速度就快。为了防止上述分母为0,所以往往添加一个平滑项参数ε,参数更新方程也就变成:
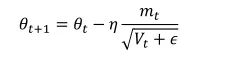
但是adagrad同样也有问题,就是其分母随着训练数增加,也会跟着增加,这样会导致学习速率越来越小,最终变的无限小,从而无法有效更新参数。
-
RMSprop
RMSprop算法由hinton教授提出,它与adadelta算法公式其实是一样的,他们是在相同时间被独立的提出,公式自然也为:
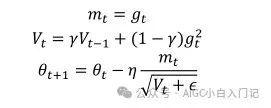
hinton教授建议将v设置为0.9,对于学习率,一个好的固定值为0.001。
-
对于带有二阶动量的优化器(如 Adagrad、RMSprop),深度网络中loss除以10和学习率除以10等价吗?
这类优化器具有自适应学习率的机制。当将 loss 乘以一个常数(如10或0.1),其影响主要在梯度计算过程中,但不会对参数的更新产生直接影响。这意味着对于这类优化器,将 loss缩放与调整学习率并不等价。
第三类:带有自适应学习率的优化器(如 Adam)
-
Adam
Adam(Adaptive Moment Estimation)自适应矩估计,是另一种自适应学习率的算法,它是一种将动量和Adadelta或RMSprop结合起来的算法,也就引入了两个参数B1和B2,其一阶和二阶动量公式为:
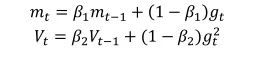
作者发现一阶和二阶动量初始训练时很小,接近为0,因为β值很大,于是作者重新计算一个偏差来校正:
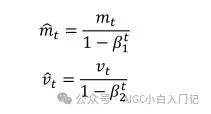
其中t代表其t次方,所以刚开始训练时,通过除于(1-β)就可以很好修正学习速率,当训练多轮时,分母部分也接近1,又回到了原始方程,所以最后总的梯度更新方程为:
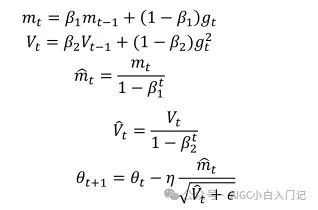
其中B1默认值为0.9,B2默认值为0.999,为10^-8,Adam集合动量和Adadelta两者的优点,从经验中表明Adam在实际中表现很好,同时与其他自适应学习算法相比,更有优势。
-
对于带有自适应学习率的优化器(如 Adam),深度网络中loss除以10和学习率除以10等价吗?
在Adam中,当loss被缩放时,虽然一阶动量与二阶动量都会受影响,但由于该算法对梯度的处理方式,整体更新的影响很小。因此, loss的缩放不会改变Adam的参数更新,而学习率的变化会对更新产生较大影响。
总结
对于带有自适应学习率的优化器(如Adam、RMSprop), loss缩放与学习率调整并不等价。对于经典的SGD和Momentum SGD,将 loss乘以常数等价于将学习率乘以相同的常数。
因此,在不同的优化器中,如何调整 loss和学习率需要具体分析,不能一概而论。#spss统计分析 #数据分析




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









