







Centos之Hadoop伪分布模式部署配置
Hadoop伪分布必须在已配置好Hadoop单机模式的基础上进行配置
Hadoop单机模式部署教程:Hadoop单机模式
配置好Hadoop单机模式后,开始配置伪分布
1、进入命令行界面,通过yum安装openssh
先通过命令:rpm -qa openssh 查询是否安装openssh,有结果则已安装,
没有结果则没有安装,需要通过命令 yum install openssh安装
yum install openssh安装不成功,则说明无yum源,先去配置yum源,再来安装openssh
2、命令行界面,通过cd命令,来到hadoop安装目录下的etc/hadoop/ 文件下,vim打开core-site.xml文件
修改内容,wq保存退出
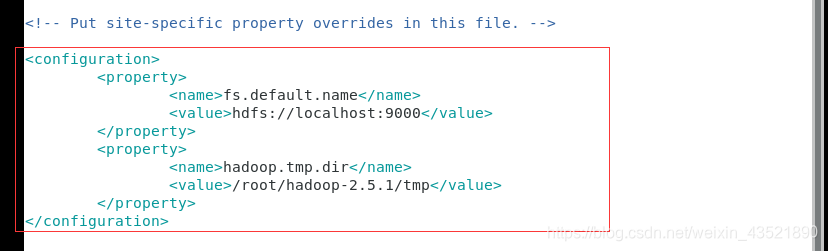
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop-2.5.1/tmp</value>
</property>
</configuration>
3、在该目录下(hadoop安装目录下的etc/hadoop/),用vim打开hdfs-site.xml文件

修改内容,wq保存退出
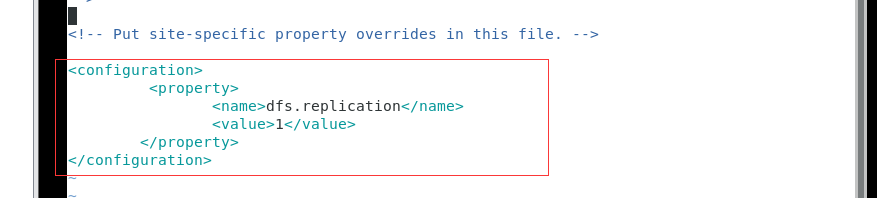
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
4、在该目录下(hadoop安装目录下的etc/hadoop/),用vim打开yarn-site.xml文件

修改内容,wq保存退出
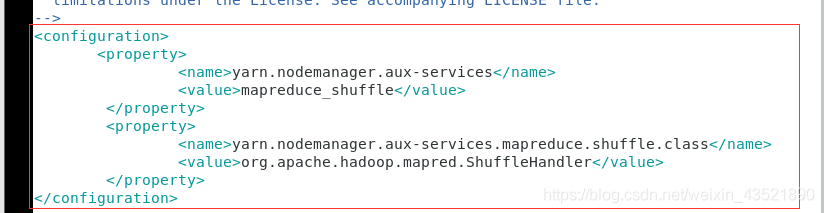
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
5、在该目录下(hadoop安装目录下的etc/hadoop/),找到mapred-site.xml.template文件,复制并重命名该文件在当前目录(文件名:mapred-site.xml),vim打开mapred-site.xml
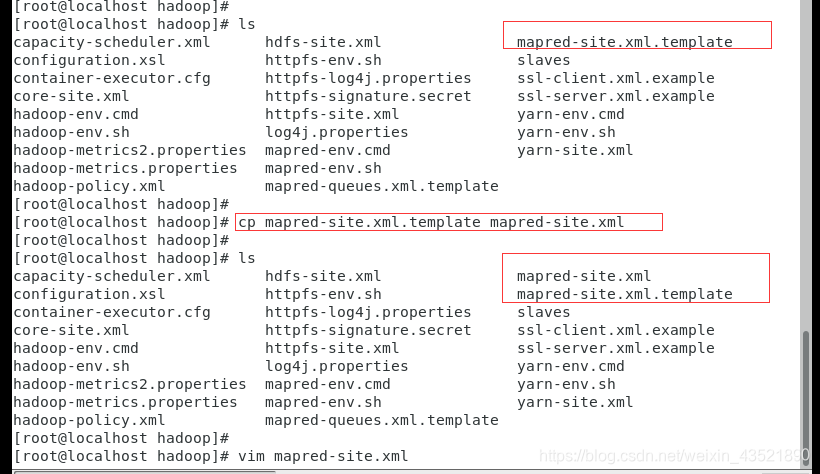
修改内容,wq保存退出
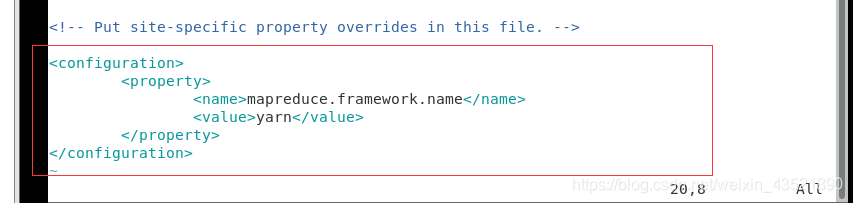
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6、在该目录下(hadoop安装目录下的etc/hadoop/),vim打开hadoop-env.sh修改JAVA_HOME的值,该值为自己JDK的路径

修改内容,wq保存退出

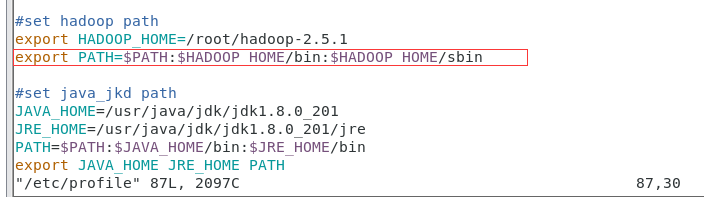
7、vim打开/etc/profile修改环境变量

在export PATH= P A T H : PATH: PATH:HADOOP_HOME/bin 这一行后添加 :$HADOOP_HOME/sbin,添加完成后,wq保存退出,命令source /etc/profile立即生效一下环境变量(亦可重启)
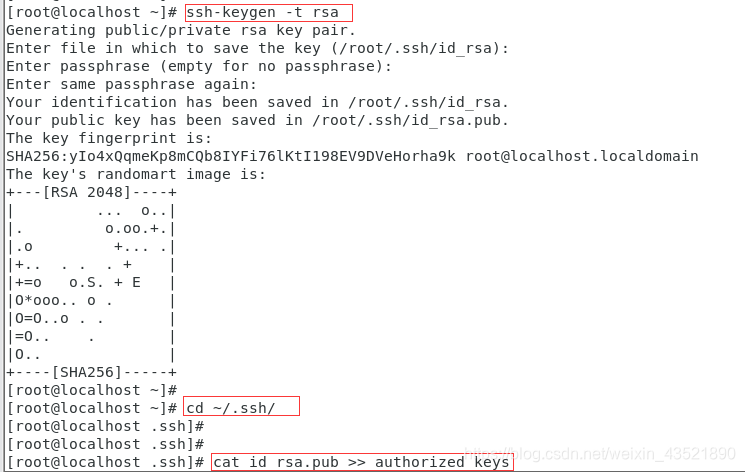
8、配置hadoop免密登陆
输入:ssh-keygen -t rsa(一路回车)
cd到~/.ssh目录
输入命令: cat id_rsa.pub >> authorized_keys
9、格式化hadoop
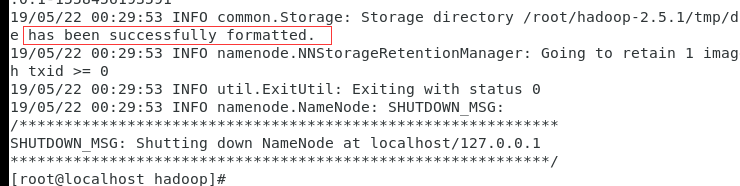
命令:hadoop namenode -format

出现“has been successfully formatted”才表示成功配置,否则重来
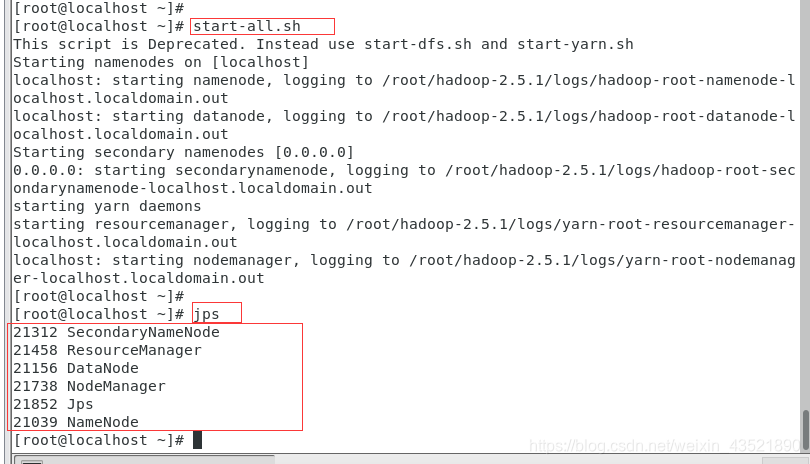
10、输入start-all.sh启动,出现提示输入yes/no,一律yes
启动完成后,输入jps,可以看到六个输出结果,代表hadoop伪分布搭建成功















 548
548











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











