







目录
整体结构思维导图
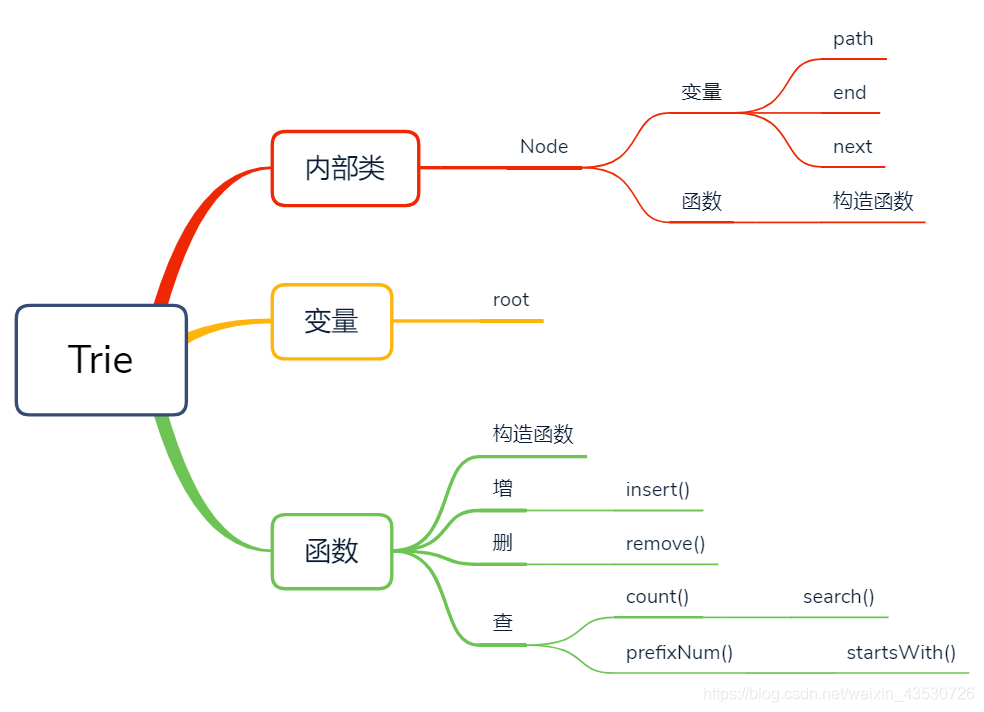
-------------------------------------------------------------------------------- 回到目录
字典树的应用
典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串)。
它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
字典树图示:
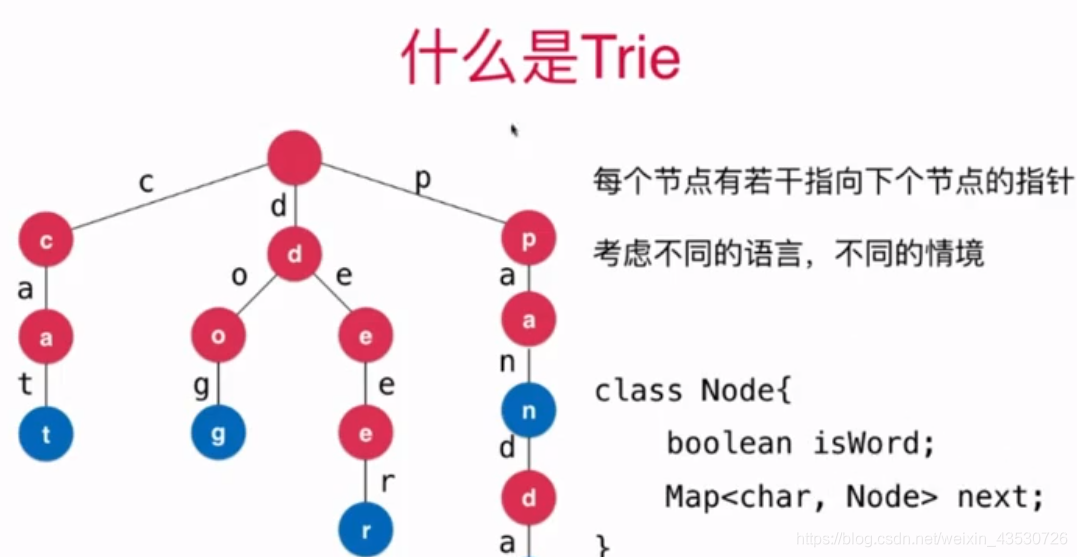
与普通树的比较:

-------------------------------------------------------------------------------- 回到目录
源码详解
存储结构
- path 为经过这个结点的字母的次数。
- end 为统计以这个结点结尾的字符串的数量。
- next 为儿子结点,之所以用数组来存储是因为字母分大小写字母,若只有小写字母,就开辟26个空间,若还包含大写则开52个空间。
该数组存储整数来表示字符,比如存c,则字符的整数转换法:c - ‘a’
public class Trie {
private class Node{
public int path;
public int end;
public Node[] next;
public Node() {
path = 0;
end = 0;
next = new Node[26];
}
}
private Node root;
public Trie() {
root = new Node();
}
}
path 和 end 图示:

上面这棵树包含的字符串有:
cat、dog、deer、pan、panda
-------------------------------------------------------------------------------- 回到目录
字符串的插入
- 对字符串遍历每个字符,算出每个字符对应整数的值(每个字符固定对应一个数字),这个值为数组的索引。
- 若没有该字符则新建一个节点存放。对每个字符,节点的 path 都要 + 1。
- 若遍历完了一个完整的字符串,则让 end + 1。
public void insert(String word){
if(word == null)
return ;
Node cur = root;
int index = 0;
for(int i = 0; i < word.length(); i++){
index = word.charAt(i) - 'a';
if(cur 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









