






1、字节码的加载过程

1.1、加载过程

字节码文件通过类加载器,链接,初始化,完成加载
加载完成之后有组织的在内存里有

每个线程有一个PC Register程序计数器,然后就是栈区间,每个线程有一个栈内存,栈内存里又分栈帧,详见并发编程。
本地方法栈(native method stack),方法区(类的信息,常量,方法信息),堆区(最大的空间,创建的对象放在堆区)

class file ->JVM->DNA元数据模板(放在方法区)->通过构造方法,创造实例放在堆内存
执行引擎
分为解释器,即时编译器,辣鸡回收器

1.2、类的加载

1.3、类的链接
三个阶段,验证----准备----解析
链接的验证
是为了保证字节码文件语法上的正确性,以防止危害到JVM的安全
比如说java字节码文件都是以特定的标识开始的语法,查看字节码文件可以发现

都是以cafebabe开始的
链接的准备阶段

为类变量附上初始值,Integer赋值为0,布尔类型赋值为false,在最后的类初始化完成真正的赋值

解析阶段

1.4、初始化阶段
构造器方法和构造方法不一样,构造器方法在每一个类中都有,他会显示的给类变量和静态代码块里的变量赋值,可以查看字节码文件解释后的clinit方法


类的构造方法就是方法区里面的init,
init时会首先调用父类的构造方法,Object.
在类的clinit方法要被多个线程访问时,只能同步访问,加锁了,只能一个线程访问一次初始化
类加载器的分类
引导类加载器、扩展类加载器、系统类加载器
从与ClassLoader的关系来说分为两类
引导类加载器和自定义加载器
因为扩展加载器和系统加载器都继承ClassLoader

public class ClassLoaderTest {
public static void main(String[] args) {
//获取系统类加载器
ClassLoader systemClassLoader = ClassLoader.getSystemClassLoader();
System.out.println(systemClassLoader);//sun.misc.Launcher$AppClassLoader@18b4aac2
//获取其上层 扩展类加载器
ClassLoader extClassLoader = systemClassLoader.getParent();
System.out.println(extClassLoader);//sun.misc.Launcher$ExtClassLoader@610455d6
//获取其上层 获取不到引导类加载器
ClassLoader bootStrapClassLoader = extClassLoader.getParent();
System.out.println(bootStrapClassLoader);//null
//对于用户自定义类来说:使用系统类加载器进行加载
ClassLoader classLoader = ClassLoaderTest.class.getClassLoader();
System.out.println(classLoader);//sun.misc.Launcher$AppClassLoader@18b4aac2
//String 类使用引导类加载器进行加载的 -->java核心类库都是使用引导类加载器加载的
ClassLoader classLoader1 = String.class.getClassLoader();
System.out.println(classLoader1);//null
}
}
"C:\Program Files\Javaa\jdk1.8.0_131\bin\java.exe"
sun.misc.Launcher$ExtClassLoader@1540e19d
null
sun.misc.Launcher$AppClassLoader@18b4aac2
null
Process finished with exit code 0



import sun.security.ec.CurveDB;
import java.net.URL;
import java.security.Provider;
/**
* 虚拟机自带加载器
*/
public class ClassLoaderTest1 {
public static void main(String[] args) {
System.out.println("********启动类加载器*********");
//获取引导类加载器可以加载的文件路径
URL[] urls = sun.misc.Launcher.getBootstrapClassPath().getURLs();
//获取BootStrapClassLoader能够加载的api路径
for (URL e:urls){
System.out.println(e.toExternalForm());
}
//从上面的路径中随意选择一个类 看看他的类加载器是什么
//Provider位于 /jdk1.8.0_171.jdk/Contents/Home/jre/lib/jsse.jar 下,引导类加载器加载它
ClassLoader classLoader = Provider.class.getClassLoader();
System.out.println(classLoader);//null
System.out.println("********拓展类加载器********");
//获取扩展加载器可以加载的文件路径
String extDirs = System.getProperty("java.ext.dirs");
for (String path : extDirs.split(";")){
System.out.println(path);
}
//从上面的路径中随意选择一个类 看看他的类加载器是什么:拓展类加载器
ClassLoader classLoader1 = CurveDB.class.getClassLoader();
System.out.println(classLoader1);//sun.misc.Launcher$ExtClassLoader@4dc63996
}
}
classLoader的继承关系

获得类加载器的几种方式,通过线程获取,通过大的clazz实例获取,获取系统的classLoader

双亲委派机制
package com.dsh.jvm.classloader;
public class StringTest {
public static void main(String[] args) {
String s = new String();
System.out.println("hello jvm");
}
}
问题,假如我们手动建立一个String类,那么类加载器会不会加载我们手动建的类
不会,因为有双亲委派机制,不会马上加载而是委托给父类加载器加载,如果父类加载器还有父类加载器则继续向上委托
。这样就避免了由appClassLoaderz加载我们自己的String类,而是由引导类加载器加载java.lang.String 这样可以防止别人的攻击。如果父类无法加载,那么就由子类加载器加载

加载JDBC.jar的过程

由于SPI类型类属于rt包,所以可以由引导类加载器加载,但是里面的一些接口属于第三方的类,于是反向委托
双亲委派机机制的优势

沙箱安全机制
自定义的String类里面没有main方法,从而保护了java核心代码
两个类相等需要他们的包类名和类加载器完全一样,才可以判断相等
如果一个类由用户自定义加载器加载,那么当他被保存在方法区会带上他的加载类的信息
类的主动使用和被动使用
区别在于,加载过程中的最后一步初始化是否执行,因为初始化需要执行clinit
主动使用的加载方式

运行时数据区与线程进程的关系
一个JVM对应一个进程,一个进程只有一组红色区,而一个进程对应多个线程,一个线程有一个灰区,线程共用红区

阿里手册的运行时数据区

程序计数器

PC寄存器存储指向栈帧某行指令的地址,执行引擎通过PC寄存器里面的地址去栈帧里取指令,如果执行的是本地方法,那么地址为undefined,没有垃圾回收也没有OOM
红色框里即为PCRegister里面的地址

为什么需要PC寄存器记录执行指令的地址
因为线程会不断地切换,下次切回来需要知道执行到哪儿了,保证中断和恢复
运行时数据区的栈和堆
栈解决程序运行时得问题,堆解决的是数据的存储 问题
虚拟机栈
一个线程拥有一个栈,一个方法有一个栈帧
public class StackTest {
public static void main(String[] args) {
StackTest test = new StackTest();
test.methodA();
}
public void methodA(){
int i = 10;
int j = 20;
methodB();
}
public void methodB(){
int k = 30;
int m = 40;
}
}
虚拟机栈的基本概述

栈存在OOM但是不存在垃圾回收,可以给栈设置固定的存储大小,但是这个当线程申请比固定大小更大的存储空间的时候,会抛出一个StackOverFlowError,如果不固定大小,动态扩展,当内存溢出的时候就会抛出OOM。
设置固定的栈大小
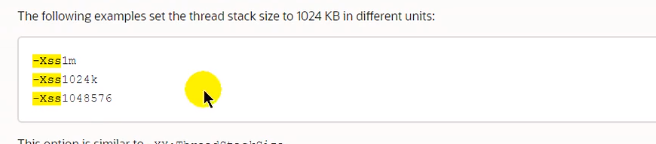

如果有返回值,那么会把返回值传给上一个栈帧,利用dreturn,和ireturn(int return)。如果有异常,也会往下面的栈帧一个个抛出直到有方法处理他的异常,假如没有处理那么这个线程就会非正常结束


其中方法返回地址,动态链接,附加信息,被称为帧数据
1、局部变量表

package com.dsh.jvm.runtimedata;
/**
* 局部变量表
*/
public class LocalVariablesTest {
private int count = 1;
public static void testStatic(){
//编译错误,因为this变量不存在与当前方法的局部变量表中!!!
// System.out.println(this.count);
}
public static void main(String[] args) {
LocalVariablesTest test = new LocalVariablesTest();
int num = 10;
test.test1();
}
private void test1() {
int i = 20;
System.out.println("test1");
this.count = 2;
test2();
}
private void test2() {
int a = 0;
{
int b = 0;
b = a+1;
}
//变量c使用之前以及经销毁的变量b占据的slot位置
int c = a+1;
}
}
反编译之后每个方法有两个和局部变量有关系
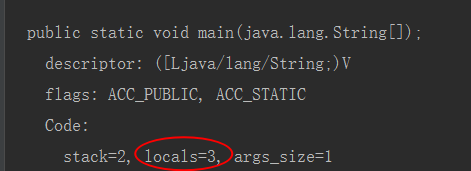
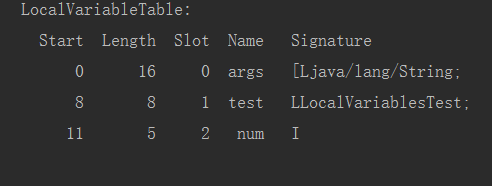
main方法里有三个参数,一个是形参String,一个是对象的引用,一个是num
下面用jclasslib查看




指令位置是变量作用的开始位置 ,可以去代码行号和指令对应关系里面去找作用范围



构造器和实例方法(非静态方法)能使用this的原因是在index0处存储了this,double,index占据两个位置
关于变量槽的重复利用

jclasslib查看后

发现b的作用域从4+4,加起来没有13,说明没有在整个方法作用,当其过了作用域范围这个时候又要定义c了,于是就发生了slot的可重用

类变量和局部变量的区别
类变量由准备阶段和初始化阶段完成赋值,而局部变量没有默认赋值,必须要显示赋值

操作数栈
栈:可以使用数组和链表实现



bipush(由于数值大小为byte,假如800就是ipush)往操作数栈压入byte值,istore_1操作数出栈,把他存入局部变量表,bipush压入操作数栈,然后istore_2存入局部变量表,iload_1取出局部变量表的1位置,入栈操作数栈,iload_2同理,iadd,出栈,相加入操作数栈,出栈存储在局部变量表。
执行引擎翻译指令变成机器指令,操纵操作数栈
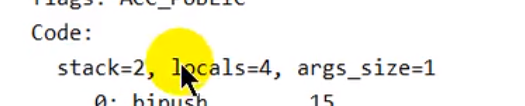
public void testAddOperation(){
//byte short char boolean flaot: 都以int型来保存
byte i = 15;
int j = 8;
int k = i+j;
}
当一个方法返回值的时候,会把返回值压入当前栈aload_0
动态链接
运行时常量池是
在加载过程中,会把class二进制流中的静态数据(全局变量,其他方法),加载到方法区的运行时常量池中

从字节码的角度



方法的调用
分为动态链接和静态链接,这个和他绑定的时间有关系,假如在编译期确定的是静态链接和早期绑定,假如是编译期不能确定的是晚期绑定,绑定就是一个字段、一个类、一个方法在符号引用被替换成直接引用的过程,仅仅发生一次
晚期绑定,比如
Animal可能是猫,或者其他继承了他的子类,所以是晚期绑定


虚函数,调用当前类或者子类(类的多肽性质)函数方法



方法重写的本质和虚方法表
但是每次依次向上找父类很浪费性能,所以为虚方法建立虚方法表

实现和重写的方法指向自己,其他的根据操作数栈地址的实际类型找到谁就是谁,不用一层一层找了。

方法返回地址
当栈帧正常结束是会返回一个返回地址,地址值是当前栈帧保存的PCRegister的地址
非正常结束会有一个异常表

表示从第四行到第八行假如出现异常那么直接跳到11行处理,针对IOException
本地方法

为什么需要用本地方法
- 用来与java外环境语言交互
- 用来与操作系统交互
- sun.java 解释器 底层采用了c的实现


2、堆




方法执行完出栈,在堆里的对象并不会立刻被回收,因为会增加gc的频率,影响用户线程

上图是创建对象,堆空间创建实例变量


逻辑上包括元数据区,但是设置堆空间大小并没有包括它
设置堆空间大小和获得堆空间大小的代码和设置方法
public class XmsXmx {
public static void main(String[] args) {
long Xms=Runtime.getRuntime().totalMemory()/1024/1024;
long Xmx=Runtime.getRuntime().maxMemory()/1024/1024;
System.out.println("开始内存:"+Xms*64);
System.out.println("最大内存:"+Xmx*4);
}
}
设置方法


打印出来的内存大小会小于实际设置的内存大小,因为,新生代的survivor0和survivor1区只能存在一个,因此计算的新生区少了一个survivor区






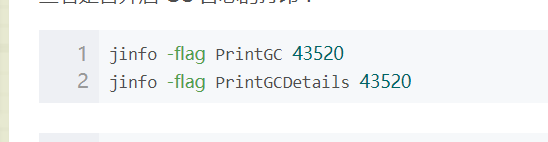
当-Xmn和-XX:NewRatio都被设置了的时候,以-Xmn为准


enden园区满了之后会进行Y/Minor gc,然后会把还要用的对象放入survivor,等eden再满的时候,会重复上次操作,但是会把还要用的对象包括之前的survivor放在一个新的survivor,如此反复知道age的数字达到了16,就会发生promotion上升到Old。。
假如survivor满了,会对survivor进行GC,并且直接promotion

特殊情况

代码举例
import java.util.ArrayList;
import java.util.Random;
public class HeapOOM {
byte[] buffer=new byte[new Random().nextInt(1034*1024)];
public static void main(String[] args) {
ArrayList<HeapOOM> arrayList=new ArrayList<>();
while (true){
arrayList.add(new HeapOOM());
try {
Thread.sleep(20);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}

STW gc的时候会暂停用户线程


问题:在enden和survivor放to区放对象的时候是谁先谁后

测试用-XX:PrintGCDetails 监测辣鸡回收
import java.util.ArrayList;
import java.util.List;
public class _77Gc {
public static void main(String[] args) {
int i=0;
try {
List<String> strings=new ArrayList<>();
String a="liuxiangniubi";
while (true){
a=a+a;
strings.add(a);
i+=1;
}
}catch (Throwable e){
System.out.println(i);
e.printStackTrace();
}
}
}



大对象eden区容纳不下,直接放进老年区。







打开逃逸分析和关闭逃逸分析的区别-XX:+DoEscapeAnalysis
package com.atguigu.java2;
/**
* 栈上分配测试
* -Xmx1G -Xms1G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails
* @author shkstart shkstart@126.com
* @create 2020 10:31
*/
public class StackAllocation {
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
alloc();
}
// 查看执行时间
long end = System.currentTimeMillis();
System.out.println("花费的时间为: " + (end - start) + " ms");
// 为了方便查看堆内存中对象个数,线程sleep
try {
Thread.sleep(1000000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
private static void alloc() {
User user = new User();//未发生逃逸
}
static class User {
}
}
关闭的时候


当减小内存分配,关闭逃逸会进行垃圾回收

开启逃逸则不会进行辣鸡回收
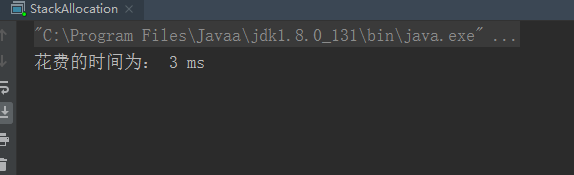
充分说明了在栈上进行对象的内存分配的好处,可以减少辣鸡回收
当JIT发现锁的对象没有发生逃逸不会被其他线程访问的时候,会进行自动的锁消除

标量替换 -XX:-EliminateAllocations

package com.atguigu.java2;
/**
* 标量替换测试
* -Xmx100m -Xms100m -XX:+DoEscapeAnalysis -XX:+PrintGC -XX:-EliminateAllocations
* @author shkstart shkstart@126.com
* @create 2020 12:01
*/
public class ScalarReplace {
public static class User {
public int id;
public String name;
}
public static void alloc() {
User u = new User();//未发生逃逸
u.id = 5;
u.name = "www.atguigu.com";
}
public static void main(String[] args) {
long start = System.currentTimeMillis();
for (int i = 0; i < 10000000; i++) {
alloc();
}
long end = System.currentTimeMillis();
System.out.println("花费的时间为: " + (end - start) + " ms");
}
}
/*
class Customer{
String name;
int id;
Account acct;
}
class Account{
double balance;
}
*/


3、方法区











package com.atguigu.java1;
/**
* 结论:
* 静态引用对应的对象实体始终都存在堆空间
*
* jdk7:
* -Xms200m -Xmx200m -XX:PermSize=300m -XX:MaxPermSize=300m -XX:+PrintGCDetails
* jdk 8:
* -Xms200m -Xmx200m -XX:MetaspaceSize=300m -XX:MaxMetaspaceSize=300m -XX:+PrintGCDetails
* @author shkstart shkstart@126.com
* @create 2020 21:20
*/
public class StaticFieldTest {
private static byte[] arr = new byte[1024 * 1024 * 100];//100MB
public static void main(String[] args) {
System.out.println(StaticFieldTest.arr);
// try {
// Thread.sleep(1000000);
// } catch (InterruptedException e) {
// e.printStackTrace();
// }
}
}


在方法区里面保留了类加载器的信息(记录了加载过哪些类)
下面是字节码反编译要放加载进方法区里面的内容




一般的变量,准备的时候隐士赋值,在初始化的时候显示赋值, static final变量在编译的时候就赋值了
初始化的执行顺序
父类静态代码块
子类静态代码块
父类代码块
父类构造方法
子类代码块
子类构造方法!
理论支持:
Java中的静态变量和静态代码块是在类加载的时候就执行的,实例化对象时,先声明并实例化变量再执行构造函数。如果子类继承父类,则先执行父类的静态变量和静态代码块,再执行子类的静态变量和静态代码块。同样,接着再执行父类和子类非静态代码块和构造函数。
注意:(静态)变量和(静态)代码块的也是有执行顺序的,与代码书写的顺序一致。在(静态)代码块中可以使用(静态)变量,但是被使用的(静态)变量必须在(静态)代码块前面声明。




编译后字节码里的常量池会在加载完存储在方法区,但是此时类的引用并不是字面量的符号地址,而是真正类型信息的地址

在Jrockit虚拟机没有永久代,因此整合完就没有永久代了,多了元空间

永久代是属于虚拟机内存的,因此要给永久代设置内存,当类加载过多,会导致永久代容易产生OOM


字符串常量应该经常被回收,但是存储在永久代(java1.7之前)他只发生在fullGC才会被回收,因此1.7把字符串常量池划分到了堆区。在1.8去掉永久代/划分出了元空间,继续把字符串常量池存放在了堆区。

类变量被包括在Class实例里,如上图所示,而class实例被存储在堆里



对于类的垃圾回收比较严格,三点
- Class实例未被使用
- new得对象全部被回收
- 他的加载器全部被回收



创建类的六个步骤

- 为对象分配内存,会根据内存里面域的类型,为对象分配空间,分配空间由两种方式具体方式还是要取决于JVM采用了什么样的垃圾收集器。一种内存分配方式是在规整的空间,放入对象,叫做指针碰撞法。还有一种是对于内存空间分配不规整,这个时候会维护一个表,表里记录者零散的空闲空间的的大小,会从表里找出一块装的下对象的空间,并更新表 。
- 初始化分配到的空间。初始化域变量的过程为:隐士初始化->显示赋值->静态代码块(和显示赋值谁先谁后)->构造器->getset方法




访问定位

句柄访问

直接指针访问



利用反射达到OOM
执行引擎





加粗样式
在方法区可以存储JIT代码缓存,这样以后执行热点代码就可以不用去编译了,可以直接运行机器指令












JIT和解释执行速度对比,超过一万次JIT运行
package com.atguigu.java;
/**
* 测试解释器模式和JIT编译模式
* -Xint : 6520ms
* -Xcomp : 950ms
* -Xmixed : 936ms
* @author shkstart shkstart@126.com
* @create 2020 12:40
*/
public class IntCompTest {
public static void main(String[] args) {
long start = System.currentTimeMillis();
testPrimeNumber(1000000);
long end = System.currentTimeMillis();
System.out.println("花费的时间为:" + (end - start));
}
public static void testPrimeNumber(int count){
for (int i = 0; i < count; i++) {
//计算100以内的质数
label:for(int j = 2;j <= 100;j++){
for(int k = 2;k <= Math.sqrt(j);k++){
if(j % k == 0){
continue label;
}
}
//System.out.println(j);
}
}
}
}



在以前latin和ISO-8859(欧洲码)这些都用了两个字节的char表示,但是他们一个字节就能放下来,用来个字节浪费了很多空间。因此,1.9出现了用byte数据表示String的方法,一个字符对应一个字节,但是汉子等一个字节放不下怎么办,因此加了一个encoding flag,表示使用了哪种编码汉字对应了utf-8



package com.atguigu.java;
/**
* @author shkstart shkstart@126.com
* @create 2020 23:44
*/
public class StringExer {
String str = new String("good");
char[] ch = {'t', 'e', 's', 't'};
public void change(String str, char ch[]) {
str = "test ok";
ch[0] = 'b';
}
public static void main(String[] args) {
StringExer ex = new StringExer();
ex.change(ex.str, ex.ch);
System.out.println(ex.str);//good
System.out.println(ex.ch);//best
}
}
值传递的一个面试题

java的拼接
package com.atguigu.java1;
import org.junit.Test;
/**
* 字符串拼接操作
* @author shkstart shkstart@126.com
* @create 2020 0:59
*/
public class StringTest5 {
@Test
public void test1(){
String s1 = "a" + "b" + "c";//编译期优化:等同于"abc"
String s2 = "abc"; //"abc"一定是放在字符串常量池中,将此地址赋给s2
/*
* 最终.java编译成.class,再执行.class
* String s1 = "abc";
* String s2 = "abc"
*/
System.out.println(s1 == s2); //true
System.out.println(s1.equals(s2)); //true
}
@Test
public void test2(){
String s1 = "javaEE";
String s2 = "hadoop";
String s3 = "javaEEhadoop";
String s4 = "javaEE" + "hadoop";//编译期优化
//如果拼接符号的前后出现了变量,则相当于在堆空间中new String(),具体的内容为拼接的结果:javaEEhadoop
String s5 = s1 + "hadoop";
String s6 = "javaEE" + s2;
String s7 = s1 + s2;
System.out.println(s3 == s4);//true
System.out.println(s3 == s5);//false
System.out.println(s3 == s6);//false
System.out.println(s3 == s7);//false
System.out.println(s5 == s6);//false
System.out.println(s5 == s7);//false
System.out.println(s6 == s7);//false
//intern():判断字符串常量池中是否存在javaEEhadoop值,如果存在,则返回常量池中javaEEhadoop的地址;
//如果字符串常量池中不存在javaEEhadoop,则在常量池中加载一份javaEEhadoop,并返回次对象的地址。
String s8 = s6.intern();
System.out.println(s3 == s8);//true
}
@Test
public void test3(){
String s1 = "a";
String s2 = "b";
String s3 = "ab";
/*
如下的s1 + s2 的执行细节:(变量s是我临时定义的)
① StringBuilder s = new StringBuilder();
② s.append("a")
③ s.append("b")
④ s.toString() --> 约等于 new String("ab")
补充:在jdk5.0之后使用的是StringBuilder,在jdk5.0之前使用的是StringBuffer
*/
String s4 = s1 + s2;//
System.out.println(s3 == s4);//false
}
/*
1. 字符串拼接操作不一定使用的是StringBuilder!
如果拼接符号左右两边都是字符串常量或常量引用,则仍然使用编译期优化,即非StringBuilder的方式。
2. 针对于final修饰类、方法、基本数据类型、引用数据类型的量的结构时,能使用上final的时候建议使用上。
*/
@Test
public void test4(){
final String s1 = "a";
final String s2 = "b";
String s3 = "ab";
String s4 = s1 + s2;
System.out.println(s3 == s4);//true
}
//练习:
@Test
public void test5(){
String s1 = "javaEEhadoop";
String s2 = "javaEE";
String s3 = s2 + "hadoop";
System.out.println(s1 == s3);//false
final String s4 = "javaEE";//s4:常量
String s5 = s4 + "hadoop";
System.out.println(s1 == s5);//true
}
/*
体会执行效率:通过StringBuilder的append()的方式添加字符串的效率要远高于使用String的字符串拼接方式!
详情:① StringBuilder的append()的方式:自始至终中只创建过一个StringBuilder的对象
使用String的字符串拼接方式:创建过多个StringBuilder和String的对象
② 使用String的字符串拼接方式:内存中由于创建了较多的StringBuilder和String的对象,内存占用更大;如果进行GC,需要花费额外的时间。
改进的空间:在实际开发中,如果基本确定要前前后后添加的字符串长度不高于某个限定值highLevel的情况下,建议使用构造器实例化:
StringBuilder s = new StringBuilder(highLevel);//new char[highLevel]
*/
@Test
public void test6(){
long start = System.currentTimeMillis();
// method1(100000);//4014
method2(100000);//7
long end = System.currentTimeMillis();
System.out.println("花费的时间为:" + (end - start));
}
public void method1(int highLevel){
String src = "";
for(int i = 0;i < highLevel;i++){
src = src + "a";//每次循环都会创建一个StringBuilder、String
}
// System.out.println(src);
}
public void method2(int highLevel){
//只需要创建一个StringBuilder
StringBuilder src = new StringBuilder();
for (int i = 0; i < highLevel; i++) {
src.append("a");
}
// System.out.println(src);
}
}

ctral+12可以查看一个类里面的所有方法,并且可以有搜索功能

加上final是常量,编译即赋值


题目:
new String(“ab”)会创建几个对象?看字节码,就知道是两个。
一个对象是:new关键字在堆空间创建的
另一个对象是:字符串常量池中的对象"ab"。 字节码指令:ldc


对应的字节码指令

toString对应的字节码指令,里面没有ldc,因此没有在字符串常量池里生成对象

一个比较难的题
inter
package com.atguigu.java2;
import org.junit.Test;
/**
* 如何保证变量s指向的是字符串常量池中的数据呢?
* 有两种方式:
* 方式一: String s = "shkstart";//字面量定义的方式
* 方式二: 调用intern()
* String s = new String("shkstart").intern();
* String s = new StringBuilder("shkstart").toString().intern();
*
* @author shkstart shkstart@126.com
* @create 2020 18:49
*/
public class StringIntern {
public static void main(String[] args) {
String s = new String("1");
s.intern();//调用此方法之前,字符串常量池中已经存在了"1"
String s2 = "1";
System.out.println(s == s2);//jdk6:false jdk7/8:false
String s3 = new String("1") + new String("1");//s3变量记录的地址为:new String("11")
//执行完上一行代码以后,字符串常量池中,是否存在"11"呢?答案:不存在!!
s3.intern();//在字符串常量池中生成"11"。如何理解:jdk6:创建了一个新的对象"11",也就有新的地址。
// jdk7:此时常量中并没有创建"11",而是创建一个指向堆空间中new String("11")的地址
String s4 = "11";//s4变量记录的地址:使用的是上一行代码代码执行时,在常量池中生成的"11"的地址
System.out.println(s3 == s4);//jdk6:false jdk7/8:true
}
}

"string"字面量它返回的地址指向常量池
package com.atguigu.java2;
/**
* @author shkstart shkstart@126.com
* @create 2020 20:17
*/
public class StringExer1 {
public static void main(String[] args) {
String x = "ab";
String s = new String("a") + new String("b");//new String("ab")
//在上一行代码执行完以后,字符串常量池中并没有"ab"
String s2 = s.intern();//jdk6中:在串池中创建一个字符串"ab"
//jdk8中:串池中没有创建字符串"ab",而是创建一个引用,指向new String("ab"),将此引用返回
System.out.println(s2 == "ab");//jdk6:true jdk8:true
System.out.println(s == "ab");//jdk6:false jdk8:true
}
}
String.valueOf(j).intern();空间占用效率低,因为会进行辣鸡回收
package com.atguigu.java3;
/**
* String的垃圾回收:
* -Xms15m -Xmx15m -XX:+PrintStringTableStatistics -XX:+PrintGCDetails
*
* @author shkstart shkstart@126.com
* @create 2020 21:27
*/
public class StringGCTest {
public static void main(String[] args) {
for (int j = 0; j < 100000; j++) {
String.valueOf(j).intern();
}
}
}









垃圾回收



package com.atguigu.java;
/**
* -XX:+PrintGCDetails
* 证明:java使用的不是引用计数算法
* @author shkstart
* @create 2020 下午 2:38
*/
public class RefCountGC {
//这个成员属性唯一的作用就是占用一点内存
private byte[] bigSize = new byte[5 * 1024 * 1024];//5MB
Object reference = null;
public static void main(String[] args) {
RefCountGC obj1 = new RefCountGC();
RefCountGC obj2 = new RefCountGC();
obj1.reference = obj2;
obj2.reference = obj1;
obj1 = null;
obj2 = null;
//显式的执行垃圾回收行为
//这里发生GC,obj1和obj2能否被回收?
System.gc();
try {
Thread.sleep(1000000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}









finalize()方法使对象复活的代码实现
package com.atguigu.java;
/**
* 测试Object类中finalize()方法,即对象的finalization机制。
*
* @author shkstart
* @create 2020 下午 2:57
*/
public class CanReliveObj {
public static CanReliveObj obj;//类变量,属于 GC Root
//此方法只能被调用一次
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("调用当前类重写的finalize()方法");
obj = this;//当前待回收的对象在finalize()方法中与引用链上的一个对象obj建立了联系
}
public static void main(String[] args) {
try {
obj = new CanReliveObj();
// 对象第一次成功拯救自己
obj = null;
System.gc();//调用垃圾回收器
System.out.println("第1次 gc");
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
System.out.println("第2次 gc");
// 下面这段代码与上面的完全相同,但是这次自救却失败了
obj = null;
System.gc();
// 因为Finalizer线程优先级很低,暂停2秒,以等待它
Thread.sleep(2000);
if (obj == null) {
System.out.println("obj is dead");
} else {
System.out.println("obj is still alive");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}















 2786
2786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









